Compare commits
386 Commits
v2026.01.0
...
v2026.01.2
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
30cde9e871 | ||
|
|
ac50cd249a | ||
|
|
927db6dbaa | ||
|
|
376c398ac7 | ||
|
|
a167a3cf83 | ||
|
|
c51e7dfdf7 | ||
|
|
1d4d13b34b | ||
|
|
18e8775f38 | ||
|
|
813b019653 | ||
|
|
b0b1542939 | ||
|
|
15f19d8b8d | ||
|
|
82253b114c | ||
|
|
e0bfbf6dd4 | ||
|
|
4689e80e7a | ||
|
|
556e6c1c67 | ||
|
|
3ab84a526d | ||
|
|
bdce96f912 | ||
|
|
4811b99a4b | ||
|
|
fb2a64c07a | ||
|
|
e023e4f2e2 | ||
|
|
0b16b1e0f4 | ||
|
|
59073ad7ac | ||
|
|
8248644c45 | ||
|
|
f38e6394c9 | ||
|
|
0aaa529c6b | ||
|
|
b81a6562a1 | ||
|
|
c5b10db23a | ||
|
|
d16e444643 | ||
|
|
8202468099 | ||
|
|
766e8bd20f | ||
|
|
1214ab5a8c | ||
|
|
ebddbb25f8 | ||
|
|
59545e1110 | ||
|
|
500e090b11 | ||
|
|
a75ee555fa | ||
|
|
6a8c2164cd | ||
|
|
7f7efa325a | ||
|
|
9ba6cb08fc | ||
|
|
1872271a2d | ||
|
|
813b50864a | ||
|
|
b18cefe320 | ||
|
|
a54c359fcf | ||
|
|
8d83221a4a | ||
|
|
1879000720 | ||
|
|
ba92649a98 | ||
|
|
d2276dcaae | ||
|
|
25c9d20f3d | ||
|
|
0d853577df | ||
|
|
f91f3d8692 | ||
|
|
0f7cad8dfa | ||
|
|
db1a1e7ef0 | ||
|
|
e7de80a059 | ||
|
|
0d8c4e048e | ||
|
|
014a5a9d1f | ||
|
|
a6dd970859 | ||
|
|
aac730f5b1 | ||
|
|
ff95d9328e | ||
|
|
afe1d8cf52 | ||
|
|
67b819f3de | ||
|
|
9b6acb6b95 | ||
|
|
a9a59e1e34 | ||
|
|
5b05397356 | ||
|
|
7a7dbc0cfa | ||
|
|
6ac0ba6efe | ||
|
|
d3d008efb4 | ||
|
|
4f1528128a | ||
|
|
93c4326206 | ||
|
|
0fca7fe524 | ||
|
|
afdcab10c6 | ||
|
|
f8cc5eabe6 | ||
|
|
f304eb7633 | ||
|
|
827204e082 | ||
|
|
641d7ee8c8 | ||
|
|
3b11537b5e | ||
|
|
e51d87ae80 | ||
|
|
f16e7c996c | ||
|
|
55eb295c12 | ||
|
|
4767351c5e | ||
|
|
1d2502eb3f | ||
|
|
94540cc131 | ||
|
|
71bef146c8 | ||
|
|
87e47fd4b2 | ||
|
|
2da600838c | ||
|
|
4ee34c1dc6 | ||
|
|
9a854c33d3 | ||
|
|
ae19653a8f | ||
|
|
caf0acf2e1 | ||
|
|
b503ad6fd2 | ||
|
|
357e869a15 | ||
|
|
3035c79d91 | ||
|
|
a5e5e178a0 | ||
|
|
d20081d3ed | ||
|
|
e2d94ba5b5 | ||
|
|
49a19242a4 | ||
|
|
c26d3b30e5 | ||
|
|
60e681042d | ||
|
|
842d65b887 | ||
|
|
ff5cecca1c | ||
|
|
b447143a50 | ||
|
|
e4cbf231a6 | ||
|
|
8868b28a84 | ||
|
|
c4df24d2c2 | ||
|
|
70a96d0754 | ||
|
|
ab0daba80d | ||
|
|
505fb6ca96 | ||
|
|
385ee71bc8 | ||
|
|
cfa28e2c9a | ||
|
|
d08bede60e | ||
|
|
b686db353c | ||
|
|
2b543d51ff | ||
|
|
e8d09d79ec | ||
|
|
cdb544f891 | ||
|
|
3eff93e8c9 | ||
|
|
cdb03fce90 | ||
|
|
c1cecf0dbb | ||
|
|
08ecba3ee1 | ||
|
|
3b82f2364e | ||
|
|
a7b2032b20 | ||
|
|
3bc683dbf5 | ||
|
|
2a8065e80c | ||
|
|
ab60641265 | ||
|
|
9e88decc44 | ||
|
|
076598ba07 | ||
|
|
4f0c50db0f | ||
|
|
499690e30f | ||
|
|
12a531b9ae | ||
|
|
3a0e2ecc6e | ||
|
|
14954b03bf | ||
|
|
6f874db000 | ||
|
|
16cc45c0d5 | ||
|
|
ab96719ec4 | ||
|
|
e2be1b25b1 | ||
|
|
700a7fc27a | ||
|
|
06cc48bab1 | ||
|
|
498e433ed3 | ||
|
|
4e915ea7a9 | ||
|
|
825ea07f4b | ||
|
|
1a731c181b | ||
|
|
c59ba5e501 | ||
|
|
e21e3e2ffa | ||
|
|
d2abaa138e | ||
|
|
3843ae5bc7 | ||
|
|
02c7a87c63 | ||
|
|
1e59025535 | ||
|
|
46195791b6 | ||
|
|
85b6bcece1 | ||
|
|
fece7d9898 | ||
|
|
d41822911c | ||
|
|
7b1180a1c8 | ||
|
|
6d5c3f1415 | ||
|
|
f8157f92fc | ||
|
|
fa2e9f5344 | ||
|
|
9c37955cf2 | ||
|
|
261f74efe8 | ||
|
|
83727bdab1 | ||
|
|
3b1a8d795f | ||
|
|
f650c64ffe | ||
|
|
6000c880de | ||
|
|
048fbb26d7 | ||
|
|
a88eda62cc | ||
|
|
957fb2dfb7 | ||
|
|
d2be5109ad | ||
|
|
80fdc52598 | ||
|
|
2b90ead3cf | ||
|
|
2aa5d77586 | ||
|
|
2b1b1ef939 | ||
|
|
4e21e06617 | ||
|
|
82ce1cef29 | ||
|
|
533eace74e | ||
|
|
83b3dcda65 | ||
|
|
e89373e0ed | ||
|
|
4b66a2bb1c | ||
|
|
59ba23da63 | ||
|
|
f8a89e222c | ||
|
|
096568f3e6 | ||
|
|
e10e12ebc9 | ||
|
|
c4df5eba47 | ||
|
|
0da3d3d881 | ||
|
|
6f4a62d1bc | ||
|
|
5d71c2a4d3 | ||
|
|
097707c168 | ||
|
|
8f4cfceb50 | ||
|
|
4ab5fab7d0 | ||
|
|
0e293be8bc | ||
|
|
182c12f81a | ||
|
|
1337a90911 | ||
|
|
2f0a347ab3 | ||
|
|
4eda286512 | ||
|
|
0fead8158d | ||
|
|
031bef563a | ||
|
|
04c3fd2bf9 | ||
|
|
cbbf6118b5 | ||
|
|
4c529369ce | ||
|
|
797dea0d77 | ||
|
|
a91aee31de | ||
|
|
8511b7df80 | ||
|
|
afd1e7a444 | ||
|
|
34b2c3d6cf | ||
|
|
d5c099dd15 | ||
|
|
8810223693 | ||
|
|
84974a2fb9 | ||
|
|
af847293af | ||
|
|
a44e80ce5b | ||
|
|
c2815e13e9 | ||
|
|
56bfa3a3ef | ||
|
|
a13c915f27 | ||
|
|
fb2d35237e | ||
|
|
3f19ecfd20 | ||
|
|
2fd96f07aa | ||
|
|
a1c1ed9840 | ||
|
|
c63701d05f | ||
|
|
863805dc68 | ||
|
|
98f7dff458 | ||
|
|
08c0dd984c | ||
|
|
e870ad8823 | ||
|
|
d687fffdb5 | ||
|
|
d534d8b319 | ||
|
|
d5c5158726 | ||
|
|
888026876f | ||
|
|
06e8d30900 | ||
|
|
cbf2ff7f93 | ||
|
|
abbe3fb248 | ||
|
|
7e44dde979 | ||
|
|
3649d75539 | ||
|
|
d3b4219a9a | ||
|
|
9e98d55e11 | ||
|
|
4b8515f682 | ||
|
|
d2f35ce396 | ||
|
|
f479f23b38 | ||
|
|
51048f9e5d | ||
|
|
1118ae34c4 | ||
|
|
7a5e1a4e12 | ||
|
|
8e377e1794 | ||
|
|
d66360b02d | ||
|
|
1ece648006 | ||
|
|
a262a716a3 | ||
|
|
06fdfee182 | ||
|
|
7085e794a3 | ||
|
|
a9cae535eb | ||
|
|
bdbd0d98be | ||
|
|
51612ea783 | ||
|
|
baf364a85f | ||
|
|
f78e703a99 | ||
|
|
aabb24c9cd | ||
|
|
ef34cc326c | ||
|
|
5fa56ba88d | ||
|
|
b71df8ef43 | ||
|
|
8c6fe6784e | ||
|
|
29fa5bae29 | ||
|
|
dab465d924 | ||
|
|
77c0defe93 | ||
|
|
80cf2b5a52 | ||
|
|
96638d8092 | ||
|
|
21ad55ae55 | ||
|
|
530a6cd463 | ||
|
|
8615773b67 | ||
|
|
16eaec64b7 | ||
|
|
8558077dfe | ||
|
|
a15353ea52 | ||
|
|
5b44e3e688 | ||
|
|
a4b3628e01 | ||
|
|
bbb7db3878 | ||
|
|
dec2bbb4bf | ||
|
|
6a241b0ae0 | ||
|
|
51c53e0ed0 | ||
|
|
8cb6382e72 | ||
|
|
5889471e82 | ||
|
|
ca2e0b4fba | ||
|
|
10d24fbfa2 | ||
|
|
322bd6e167 | ||
|
|
3cc4478dd9 | ||
|
|
59f6f2ba97 | ||
|
|
172d9e0b41 | ||
|
|
de7086c9e1 | ||
|
|
5f63e8d1e2 | ||
|
|
3da0b894fd | ||
|
|
ad2d26aa16 | ||
|
|
a09f3e0bdb | ||
|
|
3a0faf27df | ||
|
|
cd3e7309a8 | ||
|
|
54cc10bb41 | ||
|
|
24e7d34524 | ||
|
|
a58ce9e99e | ||
|
|
4a42dcf8de | ||
|
|
5903ea0e40 | ||
|
|
6d7a5b45cf | ||
|
|
10433d38b3 | ||
|
|
bf2bc80b22 | ||
|
|
1e0f5fb65a | ||
|
|
7d5a696106 | ||
|
|
cf86012d4d | ||
|
|
961c1cbca6 | ||
|
|
7fb5c243fa | ||
|
|
f845281b72 | ||
|
|
0b2c6a2d36 | ||
|
|
245c37b2c3 | ||
|
|
d2a915a514 | ||
|
|
ae731f9bd6 | ||
|
|
2a8a8c5805 | ||
|
|
deb1272f62 | ||
|
|
51c41b8628 | ||
|
|
37893ded00 | ||
|
|
38fe50a898 | ||
|
|
1c731e70dc | ||
|
|
a55aa4d8fd | ||
|
|
6c79cb2f11 | ||
|
|
ba7943bd6f | ||
|
|
6eb09c3eaa | ||
|
|
63c5257162 | ||
|
|
a2422262b5 | ||
|
|
4f49b111fd | ||
|
|
1d066fc1f0 | ||
|
|
e960c40351 | ||
|
|
96284a3652 | ||
|
|
ad2f38ec1f | ||
|
|
87fc34d505 | ||
|
|
2aafd3cef7 | ||
|
|
afec54c4e0 | ||
|
|
905a9e67ca | ||
|
|
ce56815e77 | ||
|
|
2684098be1 | ||
|
|
57ebf24c75 | ||
|
|
9375df709f | ||
|
|
255e48bd33 | ||
|
|
18993c7fbe | ||
|
|
f3cf2b52fd | ||
|
|
856f76cd27 | ||
|
|
28bb9000d8 | ||
|
|
d0b9e46b74 | ||
|
|
a0a4d31715 | ||
|
|
d5f394f5f1 | ||
|
|
a477d2baad | ||
|
|
8471680efe | ||
|
|
4d44b72dab | ||
|
|
88e14d251a | ||
|
|
e446b6474d | ||
|
|
a2eda6e5af | ||
|
|
fe80c8bee3 | ||
|
|
133315d0c6 | ||
|
|
3907644282 | ||
|
|
d8cde2115f | ||
|
|
0ce63b548f | ||
|
|
06e81c0194 | ||
|
|
3763e6501d | ||
|
|
5911f75641 | ||
|
|
f936181a37 | ||
|
|
a7651f33a4 | ||
|
|
45ddf5092b | ||
|
|
61294e90e4 | ||
|
|
8619405802 | ||
|
|
f0017ffacd | ||
|
|
65fe16e185 | ||
|
|
136e7e9021 | ||
|
|
c1a660a2a1 | ||
|
|
53f04debaf | ||
|
|
4b9790df00 | ||
|
|
58452a8441 | ||
|
|
e104161007 | ||
|
|
6de0d6fbe4 | ||
|
|
28d55c1469 | ||
|
|
59933e9361 | ||
|
|
7cbd0e2920 | ||
|
|
88038b35cc | ||
|
|
1fd7d90284 | ||
|
|
aee9c93bfb | ||
|
|
3951f7f91d | ||
|
|
3680fcf39f | ||
|
|
593a9ce22b | ||
|
|
fe497cccb7 | ||
|
|
88aa7e156a | ||
|
|
dbfce27986 | ||
|
|
9be6fe08fa | ||
|
|
782378eed8 | ||
|
|
4e59bb6518 | ||
|
|
3e73fcb3f0 | ||
|
|
c460337c43 | ||
|
|
e775b23503 | ||
|
|
b3cdb8e26e | ||
|
|
0e6f902d16 | ||
|
|
c15c73897f | ||
|
|
035439ce02 | ||
|
|
b84ff4a3a2 | ||
|
|
e22744abd0 | ||
|
|
54c90238f7 | ||
|
|
40d77121bd | ||
|
|
3795976a79 |
30
.agent/rules/plugin_standards.md
Normal file
30
.agent/rules/plugin_standards.md
Normal file
@@ -0,0 +1,30 @@
|
||||
---
|
||||
description: Standards for OpenWebUI Plugin Development, specifically README formatting.
|
||||
globs: plugins/**
|
||||
always_on: true
|
||||
---
|
||||
# Plugin Development Standards
|
||||
|
||||
## README Documentation
|
||||
|
||||
All plugins MUST follow the standard README template.
|
||||
|
||||
**Reference Template**: @docs/PLUGIN_README_TEMPLATE.md
|
||||
|
||||
### Language Requirements
|
||||
- **English Version (`README.md`)**: The primary documentation source. Must follow the template strictly.
|
||||
- **Chinese Version (`README_CN.md`)**: MUST be translated based on the English version (`README.md`) to ensure consistency in structure and content.
|
||||
|
||||
### Metadata Requirements
|
||||
The metadata line must follow this format:
|
||||
`**Author:** [Name](Link) | **Version:** [X.Y.Z] | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT`
|
||||
|
||||
### Structure Checklist
|
||||
1. **Title & Description**
|
||||
2. **Metadata Line** (Author, Version, Project, License)
|
||||
3. **Preview** (Screenshots/GIFs)
|
||||
4. **What's New** (Keep last 3 versions)
|
||||
5. **Key Features**
|
||||
6. **How to Use**
|
||||
7. **Configuration (Valves)**
|
||||
8. **Troubleshooting** (Must include link to GitHub Issues)
|
||||
@@ -25,6 +25,12 @@ Every plugin **MUST** have bilingual versions for both code and documentation:
|
||||
- **Valves**: Use `pydantic` for configuration.
|
||||
- **Database**: Re-use `open_webui.internal.db` shared connection.
|
||||
- **User Context**: Use `_get_user_context` helper method.
|
||||
- **Chat Context**: Use `_get_chat_context` helper method for `chat_id` and `message_id`.
|
||||
- **Debugging**: Use `_emit_debug_log` for frontend console logging (requires `SHOW_DEBUG_LOG` valve).
|
||||
- **Chat API**: For message updates, follow the "OpenWebUI Chat API 更新规范" in `.github/copilot-instructions.md`.
|
||||
- Use Event API for immediate UI updates
|
||||
- Use Chat Persistence API for database storage
|
||||
- Always update both `messages[]` and `history.messages`
|
||||
|
||||
### Commit Messages
|
||||
- **Language**: **English ONLY**. Do not use Chinese in commit messages.
|
||||
@@ -35,8 +41,8 @@ Every plugin **MUST** have bilingual versions for both code and documentation:
|
||||
When adding or updating a plugin, you **MUST** update the following documentation files to maintain consistency:
|
||||
|
||||
### Plugin Directory
|
||||
- `README.md`: Update version, description, and usage.
|
||||
- `README_CN.md`: Update version, description, and usage.
|
||||
- `README.md`: Update version, description, and usage. **Explicitly describe new features in a prominent position at the beginning.**
|
||||
- `README_CN.md`: Update version, description, and usage. **Explicitly describe new features in a prominent position at the beginning.**
|
||||
|
||||
### Global Documentation (`docs/`)
|
||||
- **Index Pages**:
|
||||
@@ -55,9 +61,13 @@ When adding or updating a plugin, you **MUST** update the following documentatio
|
||||
Reference: `.github/workflows/release.yml`
|
||||
|
||||
### Version Bumping
|
||||
- **Rule**: Any change to plugin logic **MUST** be accompanied by a version bump in the docstring.
|
||||
- **Rule**: Version bump is required **ONLY when the user explicitly requests a release**. Regular code changes do NOT require version bumps.
|
||||
- **Format**: Semantic Versioning (e.g., `1.0.0` -> `1.0.1`).
|
||||
- **Consistency**: Update version in **ALL** locations:
|
||||
- **When to Bump**: Only update the version when:
|
||||
- User says "发布" / "release" / "bump version"
|
||||
- User explicitly asks to prepare for release
|
||||
- **Agent Initiative**: After completing significant changes (new features, bug fixes, or multiple code modifications), the agent **SHOULD proactively ask** the user if they want to release a new version. If confirmed, update all version-related files.
|
||||
- **Consistency**: When bumping, update version in **ALL** locations:
|
||||
1. English Code (`.py`)
|
||||
2. Chinese Code (`.py`)
|
||||
3. English README (`README.md`)
|
||||
@@ -74,6 +84,15 @@ Reference: `.github/workflows/release.yml`
|
||||
- Generates release notes based on changes.
|
||||
- Creates a GitHub Release tag (e.g., `v2024.01.01-1`).
|
||||
- Uploads individual `.py` files of **changed plugins only** as assets.
|
||||
4. **Market Publishing**:
|
||||
- Workflow: `.github/workflows/publish_plugin.yml`
|
||||
- Trigger: Release published.
|
||||
- Action: Automatically updates the plugin code and metadata on OpenWebUI.com using `scripts/publish_plugin.py`.
|
||||
- **Auto-Sync**: If a local plugin has no ID but matches an existing published plugin by **Title**, the script will automatically fetch the ID, update the local file, and proceed with the update.
|
||||
- Requirement: `OPENWEBUI_API_KEY` secret must be set.
|
||||
- **README Link**: When announcing a release, always include the GitHub README URL for the plugin:
|
||||
- Format: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/{type}/{name}/README.md`
|
||||
- Example: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/README.md`
|
||||
|
||||
### Pull Request Check
|
||||
- Workflow: `.github/workflows/plugin-version-check.yml`
|
||||
@@ -91,3 +110,9 @@ Before committing:
|
||||
- [ ] `docs/` index and detail pages are updated?
|
||||
- [ ] Root `README.md` is updated?
|
||||
- [ ] All version numbers match exactly?
|
||||
|
||||
## 5. Git Operations (Agent Rules)
|
||||
|
||||
Strictly follow the rules defined in `.github/copilot-instructions.md` → **Git Operations (Agent Rules)** section.
|
||||
|
||||
|
||||
|
||||
56
.all-contributorsrc
Normal file
56
.all-contributorsrc
Normal file
@@ -0,0 +1,56 @@
|
||||
{
|
||||
"files": [
|
||||
"README.md"
|
||||
],
|
||||
"imageSize": 100,
|
||||
"commit": false,
|
||||
"commitType": "docs",
|
||||
"commitConvention": "angular",
|
||||
"contributors": [
|
||||
{
|
||||
"login": "rbb-dev",
|
||||
"name": "rbb-dev",
|
||||
"avatar_url": "https://avatars.githubusercontent.com/u/37469229?v=4",
|
||||
"profile": "https://github.com/rbb-dev",
|
||||
"contributions": [
|
||||
"ideas",
|
||||
"code"
|
||||
]
|
||||
},
|
||||
{
|
||||
"login": "dhaern",
|
||||
"name": "Raxxoor",
|
||||
"avatar_url": "https://avatars.githubusercontent.com/u/7317522?v=4",
|
||||
"profile": "https://trade.xyz/?ref=BZ1RJRXWO",
|
||||
"contributions": [
|
||||
"bug",
|
||||
"ideas"
|
||||
]
|
||||
},
|
||||
{
|
||||
"login": "i-iooi-i",
|
||||
"name": "ZOLO",
|
||||
"avatar_url": "https://avatars.githubusercontent.com/u/1827701?v=4",
|
||||
"profile": "https://github.com/i-iooi-i",
|
||||
"contributions": [
|
||||
"bug",
|
||||
"ideas"
|
||||
]
|
||||
},
|
||||
{
|
||||
"login": "nahoj",
|
||||
"name": "Johan Grande",
|
||||
"avatar_url": "https://avatars.githubusercontent.com/u/469017?v=4",
|
||||
"profile": "https://perso.crans.org/grande/",
|
||||
"contributions": [
|
||||
"ideas"
|
||||
]
|
||||
}
|
||||
],
|
||||
"contributorsPerLine": 7,
|
||||
"skipCi": true,
|
||||
"repoType": "github",
|
||||
"repoHost": "https://github.com",
|
||||
"projectName": "awesome-openwebui",
|
||||
"projectOwner": "Fu-Jie"
|
||||
}
|
||||
1400
.github/copilot-instructions.md
vendored
1400
.github/copilot-instructions.md
vendored
File diff suppressed because it is too large
Load Diff
129
.github/workflows/community-stats.yml
vendored
Normal file
129
.github/workflows/community-stats.yml
vendored
Normal file
@@ -0,0 +1,129 @@
|
||||
# OpenWebUI 社区统计报告自动生成
|
||||
# 智能检测:只在有意义的变更时才 commit
|
||||
# - 新增插件 (total_posts)
|
||||
# - 插件版本变更 (version)
|
||||
# - 积分增加 (total_points)
|
||||
# - 粉丝增加 (followers)
|
||||
|
||||
name: Community Stats
|
||||
|
||||
on:
|
||||
# 每小时整点运行
|
||||
schedule:
|
||||
- cron: '0 * * * *'
|
||||
# 手动触发
|
||||
workflow_dispatch:
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
|
||||
jobs:
|
||||
update-stats:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install requests python-dotenv
|
||||
|
||||
- name: Capture existing stats (before update)
|
||||
id: old_stats
|
||||
run: |
|
||||
if [ -f docs/community-stats.json ]; then
|
||||
echo "total_posts=$(jq -r '.total_posts // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
echo "total_points=$(jq -r '.user.total_points // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
echo "followers=$(jq -r '.user.followers // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
# 提取所有插件的版本号,生成一个排序后的字符串用于比较
|
||||
echo "versions=$(jq -r '[.posts[].version] | sort | join(",")' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "total_posts=0" >> $GITHUB_OUTPUT
|
||||
echo "total_points=0" >> $GITHUB_OUTPUT
|
||||
echo "followers=0" >> $GITHUB_OUTPUT
|
||||
echo "versions=" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Generate stats report
|
||||
env:
|
||||
OPENWEBUI_API_KEY: ${{ secrets.OPENWEBUI_API_KEY }}
|
||||
OPENWEBUI_USER_ID: ${{ secrets.OPENWEBUI_USER_ID }}
|
||||
run: |
|
||||
python scripts/openwebui_stats.py
|
||||
|
||||
- name: Capture new stats (after update)
|
||||
id: new_stats
|
||||
run: |
|
||||
echo "total_posts=$(jq -r '.total_posts // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
echo "total_points=$(jq -r '.user.total_points // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
echo "followers=$(jq -r '.user.followers // 0' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
echo "versions=$(jq -r '[.posts[].version] | sort | join(",")' docs/community-stats.json)" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: Check for significant changes
|
||||
id: check_changes
|
||||
run: |
|
||||
OLD_POSTS="${{ steps.old_stats.outputs.total_posts }}"
|
||||
NEW_POSTS="${{ steps.new_stats.outputs.total_posts }}"
|
||||
OLD_POINTS="${{ steps.old_stats.outputs.total_points }}"
|
||||
NEW_POINTS="${{ steps.new_stats.outputs.total_points }}"
|
||||
OLD_FOLLOWERS="${{ steps.old_stats.outputs.followers }}"
|
||||
NEW_FOLLOWERS="${{ steps.new_stats.outputs.followers }}"
|
||||
OLD_VERSIONS="${{ steps.old_stats.outputs.versions }}"
|
||||
NEW_VERSIONS="${{ steps.new_stats.outputs.versions }}"
|
||||
|
||||
SHOULD_COMMIT="false"
|
||||
CHANGE_REASON=""
|
||||
|
||||
# 检查新增插件
|
||||
if [ "$NEW_POSTS" -gt "$OLD_POSTS" ]; then
|
||||
SHOULD_COMMIT="true"
|
||||
CHANGE_REASON="new plugin added ($OLD_POSTS -> $NEW_POSTS)"
|
||||
echo "📦 New plugin detected: $OLD_POSTS -> $NEW_POSTS"
|
||||
fi
|
||||
|
||||
# 检查版本变更
|
||||
if [ "$OLD_VERSIONS" != "$NEW_VERSIONS" ]; then
|
||||
SHOULD_COMMIT="true"
|
||||
CHANGE_REASON="${CHANGE_REASON:+$CHANGE_REASON, }plugin version updated"
|
||||
echo "🔄 Plugin version changed"
|
||||
fi
|
||||
|
||||
# 检查积分增加
|
||||
if [ "$NEW_POINTS" -gt "$OLD_POINTS" ]; then
|
||||
SHOULD_COMMIT="true"
|
||||
CHANGE_REASON="${CHANGE_REASON:+$CHANGE_REASON, }points increased ($OLD_POINTS -> $NEW_POINTS)"
|
||||
echo "⭐ Points increased: $OLD_POINTS -> $NEW_POINTS"
|
||||
fi
|
||||
|
||||
# 检查粉丝增加
|
||||
if [ "$NEW_FOLLOWERS" -gt "$OLD_FOLLOWERS" ]; then
|
||||
SHOULD_COMMIT="true"
|
||||
CHANGE_REASON="${CHANGE_REASON:+$CHANGE_REASON, }followers increased ($OLD_FOLLOWERS -> $NEW_FOLLOWERS)"
|
||||
echo "👥 Followers increased: $OLD_FOLLOWERS -> $NEW_FOLLOWERS"
|
||||
fi
|
||||
|
||||
echo "should_commit=$SHOULD_COMMIT" >> $GITHUB_OUTPUT
|
||||
echo "change_reason=$CHANGE_REASON" >> $GITHUB_OUTPUT
|
||||
|
||||
if [ "$SHOULD_COMMIT" = "false" ]; then
|
||||
echo "ℹ️ No significant changes detected, skipping commit"
|
||||
else
|
||||
echo "✅ Significant changes detected: $CHANGE_REASON"
|
||||
fi
|
||||
|
||||
- name: Commit and push changes
|
||||
if: steps.check_changes.outputs.should_commit == 'true'
|
||||
run: |
|
||||
git config --local user.email "github-actions[bot]@users.noreply.github.com"
|
||||
git config --local user.name "github-actions[bot]"
|
||||
git add docs/community-stats.zh.md docs/community-stats.md docs/community-stats.json docs/badges README.md README_CN.md
|
||||
git diff --staged --quiet || git commit -m "chore: update community stats - ${{ steps.check_changes.outputs.change_reason }}"
|
||||
git push
|
||||
68
.github/workflows/publish_new_plugin.yml
vendored
Normal file
68
.github/workflows/publish_new_plugin.yml
vendored
Normal file
@@ -0,0 +1,68 @@
|
||||
name: Publish New Plugin
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
plugin_dir:
|
||||
description: 'Plugin directory (e.g., plugins/actions/deep-dive)'
|
||||
required: true
|
||||
type: string
|
||||
dry_run:
|
||||
description: 'Dry run mode (preview only)'
|
||||
required: false
|
||||
type: boolean
|
||||
default: false
|
||||
|
||||
jobs:
|
||||
publish:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.x'
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install requests
|
||||
|
||||
- name: Validate plugin directory
|
||||
run: |
|
||||
if [ ! -d "${{ github.event.inputs.plugin_dir }}" ]; then
|
||||
echo "❌ Error: Directory '${{ github.event.inputs.plugin_dir }}' does not exist"
|
||||
exit 1
|
||||
fi
|
||||
echo "✅ Found plugin directory: ${{ github.event.inputs.plugin_dir }}"
|
||||
ls -la "${{ github.event.inputs.plugin_dir }}"
|
||||
|
||||
- name: Publish Plugin
|
||||
env:
|
||||
OPENWEBUI_API_KEY: ${{ secrets.OPENWEBUI_API_KEY }}
|
||||
run: |
|
||||
if [ "${{ github.event.inputs.dry_run }}" = "true" ]; then
|
||||
echo "🔍 Dry run mode - previewing..."
|
||||
python scripts/publish_plugin.py --new "${{ github.event.inputs.plugin_dir }}" --dry-run
|
||||
else
|
||||
echo "🚀 Publishing plugin..."
|
||||
python scripts/publish_plugin.py --new "${{ github.event.inputs.plugin_dir }}"
|
||||
fi
|
||||
|
||||
- name: Commit changes (if ID was added)
|
||||
if: ${{ github.event.inputs.dry_run != 'true' }}
|
||||
run: |
|
||||
git config user.name "github-actions[bot]"
|
||||
git config user.email "github-actions[bot]@users.noreply.github.com"
|
||||
|
||||
# Check if there are changes to commit
|
||||
if git diff --quiet; then
|
||||
echo "No changes to commit"
|
||||
else
|
||||
git add "${{ github.event.inputs.plugin_dir }}"
|
||||
git commit -m "feat: add openwebui_id to ${{ github.event.inputs.plugin_dir }}"
|
||||
git push
|
||||
echo "✅ Committed and pushed openwebui_id changes"
|
||||
fi
|
||||
33
.github/workflows/publish_plugin.yml
vendored
Normal file
33
.github/workflows/publish_plugin.yml
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
name: Publish Plugins to OpenWebUI Market
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- 'plugins/**/*.py'
|
||||
release:
|
||||
types: [published]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
publish:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.x'
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install requests
|
||||
|
||||
- name: Publish Plugins
|
||||
env:
|
||||
OPENWEBUI_API_KEY: ${{ secrets.OPENWEBUI_API_KEY }}
|
||||
run: python scripts/publish_plugin.py
|
||||
139
.github/workflows/release.yml
vendored
139
.github/workflows/release.yml
vendored
@@ -54,6 +54,9 @@ permissions:
|
||||
jobs:
|
||||
check-changes:
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
LANG: en_US.UTF-8
|
||||
LC_ALL: en_US.UTF-8
|
||||
outputs:
|
||||
has_changes: ${{ steps.detect.outputs.has_changes }}
|
||||
changed_plugins: ${{ steps.detect.outputs.changed_plugins }}
|
||||
@@ -65,6 +68,12 @@ jobs:
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Configure Git
|
||||
run: |
|
||||
git config --global core.quotepath false
|
||||
git config --global i18n.commitencoding utf-8
|
||||
git config --global i18n.logoutputencoding utf-8
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
@@ -131,6 +140,7 @@ jobs:
|
||||
|
||||
echo "changed_plugins<<EOF" >> $GITHUB_OUTPUT
|
||||
cat changed_files.txt >> $GITHUB_OUTPUT
|
||||
echo "" >> $GITHUB_OUTPUT
|
||||
echo "EOF" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
@@ -138,6 +148,7 @@ jobs:
|
||||
{
|
||||
echo 'release_notes<<EOF'
|
||||
cat changes.md
|
||||
echo ""
|
||||
echo 'EOF'
|
||||
} >> $GITHUB_OUTPUT
|
||||
|
||||
@@ -145,6 +156,10 @@ jobs:
|
||||
needs: check-changes
|
||||
if: needs.check-changes.outputs.has_changes == 'true' || github.event_name == 'workflow_dispatch' || startsWith(github.ref, 'refs/tags/v')
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
LANG: en_US.UTF-8
|
||||
LC_ALL: en_US.UTF-8
|
||||
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
@@ -152,6 +167,12 @@ jobs:
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Configure Git
|
||||
run: |
|
||||
git config --global core.quotepath false
|
||||
git config --global i18n.commitencoding utf-8
|
||||
git config --global i18n.logoutputencoding utf-8
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
@@ -159,14 +180,34 @@ jobs:
|
||||
|
||||
- name: Determine version
|
||||
id: version
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
if [ "${{ github.event_name }}" = "workflow_dispatch" ] && [ -n "${{ github.event.inputs.version }}" ]; then
|
||||
VERSION="${{ github.event.inputs.version }}"
|
||||
elif [[ "${{ github.ref }}" == refs/tags/v* ]]; then
|
||||
VERSION="${GITHUB_REF#refs/tags/}"
|
||||
else
|
||||
# Auto-generate version based on date and run number
|
||||
VERSION="v$(date +'%Y.%m.%d')-${{ github.run_number }}"
|
||||
# Auto-generate version based on date and daily release count
|
||||
TODAY=$(date +'%Y.%m.%d')
|
||||
TODAY_PREFIX="v${TODAY}-"
|
||||
|
||||
# Count existing releases with today's date prefix
|
||||
# grep -c returns 1 if count is 0, so we use || true to avoid script failure
|
||||
EXISTING_COUNT=$(gh release list --limit 100 2>/dev/null | grep -c "^${TODAY_PREFIX}" || true)
|
||||
|
||||
# Clean up output (handle potential newlines or fallback issues)
|
||||
EXISTING_COUNT=$(echo "$EXISTING_COUNT" | tr -cd '0-9')
|
||||
if [ -z "$EXISTING_COUNT" ]; then EXISTING_COUNT=0; fi
|
||||
|
||||
NEXT_NUM=$((EXISTING_COUNT + 1))
|
||||
|
||||
VERSION="${TODAY_PREFIX}${NEXT_NUM}"
|
||||
|
||||
# Final fallback to ensure VERSION is never empty
|
||||
if [ -z "$VERSION" ]; then
|
||||
VERSION="v$(date +'%Y.%m.%d-%H%M%S')"
|
||||
fi
|
||||
fi
|
||||
echo "version=$VERSION" >> $GITHUB_OUTPUT
|
||||
echo "Release version: $VERSION"
|
||||
@@ -205,6 +246,63 @@ jobs:
|
||||
echo "=== Collected Files ==="
|
||||
find release_plugins -name "*.py" -type f | head -20
|
||||
|
||||
- name: Update plugin icon URLs
|
||||
run: |
|
||||
echo "Updating icon_url in plugins to use absolute GitHub URLs..."
|
||||
# Base URL for raw content using the release tag
|
||||
REPO_URL="https://raw.githubusercontent.com/${{ github.repository }}/${{ steps.version.outputs.version }}"
|
||||
|
||||
find release_plugins -name "*.py" | while read -r file; do
|
||||
# $file is like release_plugins/plugins/actions/infographic/infographic.py
|
||||
# Remove release_plugins/ prefix to get the path in the repo
|
||||
src_file="${file#release_plugins/}"
|
||||
src_dir=$(dirname "$src_file")
|
||||
base_name=$(basename "$src_file" .py)
|
||||
|
||||
# Check if a corresponding png exists in the source repository
|
||||
png_file="${src_dir}/${base_name}.png"
|
||||
|
||||
if [ -f "$png_file" ]; then
|
||||
echo "Found icon for $src_file: $png_file"
|
||||
TARGET_ICON_URL="${REPO_URL}/${png_file}"
|
||||
|
||||
# Use python for safe replacement
|
||||
python3 -c "
|
||||
import sys
|
||||
import re
|
||||
|
||||
file_path = '$file'
|
||||
icon_url = '$TARGET_ICON_URL'
|
||||
|
||||
try:
|
||||
with open(file_path, 'r', encoding='utf-8') as f:
|
||||
content = f.read()
|
||||
|
||||
# Replace icon_url: ... with new url
|
||||
# Matches 'icon_url: ...' and replaces it
|
||||
new_content = re.sub(r'^icon_url:.*$', f'icon_url: {icon_url}', content, flags=re.MULTILINE)
|
||||
|
||||
with open(file_path, 'w', encoding='utf-8') as f:
|
||||
f.write(new_content)
|
||||
print(f'Successfully updated icon_url in {file_path}')
|
||||
except Exception as e:
|
||||
print(f'Error updating {file_path}: {e}', file=sys.stderr)
|
||||
sys.exit(1)
|
||||
"
|
||||
fi
|
||||
done
|
||||
|
||||
- name: Debug Filenames
|
||||
run: |
|
||||
python3 -c "import sys; print(f'Filesystem encoding: {sys.getfilesystemencoding()}')"
|
||||
ls -R release_plugins
|
||||
|
||||
- name: Upload Debug Artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: debug-plugins
|
||||
path: release_plugins/
|
||||
|
||||
- name: Get commit messages
|
||||
id: commits
|
||||
if: github.event_name == 'push'
|
||||
@@ -220,8 +318,9 @@ jobs:
|
||||
{
|
||||
echo 'commits<<EOF'
|
||||
echo "$COMMITS"
|
||||
echo ""
|
||||
echo 'EOF'
|
||||
} >> $GITHUB_OUTPUT
|
||||
} >> "$GITHUB_OUTPUT"
|
||||
|
||||
- name: Generate release notes
|
||||
id: notes
|
||||
@@ -292,19 +391,51 @@ jobs:
|
||||
echo "=== Release Notes ==="
|
||||
cat release_notes.md
|
||||
|
||||
- name: Create Git Tag
|
||||
run: |
|
||||
VERSION="${{ steps.version.outputs.version }}"
|
||||
|
||||
if [ -z "$VERSION" ]; then
|
||||
echo "Error: Version is empty!"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if ! git rev-parse "$VERSION" >/dev/null 2>&1; then
|
||||
echo "Creating tag $VERSION"
|
||||
git tag "$VERSION"
|
||||
git push origin "$VERSION"
|
||||
else
|
||||
echo "Tag $VERSION already exists"
|
||||
fi
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Create GitHub Release
|
||||
uses: softprops/action-gh-release@v2
|
||||
with:
|
||||
tag_name: ${{ steps.version.outputs.version }}
|
||||
target_commitish: ${{ github.sha }}
|
||||
name: ${{ github.event.inputs.release_title || steps.version.outputs.version }}
|
||||
body_path: release_notes.md
|
||||
prerelease: ${{ github.event.inputs.prerelease || false }}
|
||||
make_latest: true
|
||||
files: |
|
||||
plugin_versions.json
|
||||
release_plugins/**/*.py
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Upload Release Assets
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
# Check if there are any .py files to upload
|
||||
if [ -d release_plugins ] && [ -n "$(find release_plugins -type f -name '*.py' 2>/dev/null)" ]; then
|
||||
echo "Uploading plugin files..."
|
||||
find release_plugins -type f -name "*.py" -print0 | xargs -0 gh release upload ${{ steps.version.outputs.version }} --clobber
|
||||
else
|
||||
echo "No plugin files to upload. Skipping asset upload."
|
||||
fi
|
||||
|
||||
- name: Summary
|
||||
run: |
|
||||
echo "## 🚀 Release Created Successfully!" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
@@ -1,87 +1,16 @@
|
||||
# 贡献指南 (Contributing Guide)
|
||||
# Contributing Guide
|
||||
|
||||
感谢你对 **OpenWebUI Extras** 感兴趣!我们非常欢迎社区贡献更多的插件、提示词和创意。
|
||||
Thank you for your interest in **OpenWebUI Extras**!
|
||||
|
||||
## 🤝 如何贡献
|
||||
## 🚀 How to Contribute
|
||||
|
||||
### 1. 分享提示词 (Prompts)
|
||||
1. **Fork** this repository.
|
||||
2. **Add/Modify** the plugin file in the `plugins/` directory.
|
||||
3. **Submit PR**: We will review and merge it.
|
||||
|
||||
如果你有一个好用的提示词:
|
||||
1. 在 `prompts/` 目录下找到合适的分类(如 `coding/`, `writing/`)。如果没有合适的,可以新建一个文件夹。
|
||||
2. 创建一个新的 `.md` 或 `.json` 文件。
|
||||
3. 提交 Pull Request (PR)。
|
||||
## 💡 Important
|
||||
|
||||
### 2. 开发插件 (Plugins)
|
||||
- Ensure your plugin includes complete metadata (title, author, version, description).
|
||||
- If updating an existing plugin, please **increment the version number** (e.g., `0.1.0` -> `0.1.1`) to trigger the auto-update.
|
||||
|
||||
如果你开发了一个新的 OpenWebUI 插件 (Function/Tool):
|
||||
1. 确保你的插件代码包含完整的元数据(Frontmatter):
|
||||
```python
|
||||
"""
|
||||
title: 插件名称
|
||||
author: 你的名字
|
||||
version: 0.1.0
|
||||
description: 简短描述插件的功能
|
||||
"""
|
||||
```
|
||||
2. 将插件文件放入 `plugins/` 目录下的合适位置:
|
||||
- `plugins/actions/`: 用于添加按钮或修改消息的 Action 插件。
|
||||
- `plugins/filters/`: 用于拦截请求或响应的 Filter 插件。
|
||||
- `plugins/pipes/`: 用于自定义模型或 API 的 Pipe 插件。
|
||||
- `plugins/tools/`: 用于 LLM 调用的 Tool 插件。
|
||||
3. 建议在 `docs/` 下添加一个简单的使用说明。
|
||||
|
||||
### 3. 改进文档
|
||||
|
||||
如果你发现文档有错误或可以改进的地方,直接提交 PR 即可。
|
||||
|
||||
## 🛠️ 开发规范
|
||||
|
||||
- **代码风格**:Python 代码请遵循 PEP 8 规范。
|
||||
- **注释**:关键逻辑请添加注释,方便他人理解。
|
||||
- **测试**:提交前请在本地 OpenWebUI 环境中测试通过。
|
||||
|
||||
## 📝 提交 PR
|
||||
|
||||
1. Fork 本仓库。
|
||||
2. 创建一个新的分支 (`git checkout -b feature/AmazingFeature`)。
|
||||
3. 提交你的修改 (`git commit -m 'Add some AmazingFeature'`)。
|
||||
4. 推送到分支 (`git push origin feature/AmazingFeature`)。
|
||||
5. 开启一个 Pull Request。
|
||||
|
||||
## 📦 版本更新与发布
|
||||
|
||||
当你更新插件时,请遵循以下流程:
|
||||
|
||||
### 1. 更新版本号
|
||||
|
||||
在插件文件的 docstring 中更新版本号(遵循[语义化版本](https://semver.org/lang/zh-CN/)):
|
||||
|
||||
```python
|
||||
"""
|
||||
title: 我的插件
|
||||
version: 0.2.0 # 更新此处
|
||||
...
|
||||
"""
|
||||
```
|
||||
|
||||
### 2. 更新更新日志
|
||||
|
||||
在 `CHANGELOG.md` 的 `[Unreleased]` 部分添加你的更改:
|
||||
|
||||
```markdown
|
||||
### Added / 新增
|
||||
- 新功能描述
|
||||
|
||||
### Fixed / 修复
|
||||
- Bug 修复描述
|
||||
```
|
||||
|
||||
### 3. 发布流程
|
||||
|
||||
维护者会通过以下方式发布新版本:
|
||||
- 手动触发 GitHub Actions 中的 "Plugin Release" 工作流
|
||||
- 或创建版本标签 (`v*`)
|
||||
|
||||
详细说明请参阅 [发布工作流文档](docs/release-workflow.zh.md)。
|
||||
|
||||
再次感谢你的贡献!🚀
|
||||
Thank you! 🚀
|
||||
|
||||
16
CONTRIBUTING_CN.md
Normal file
16
CONTRIBUTING_CN.md
Normal file
@@ -0,0 +1,16 @@
|
||||
# 贡献指南
|
||||
|
||||
感谢你对 **OpenWebUI Extras** 感兴趣!
|
||||
|
||||
## 🚀 贡献流程
|
||||
|
||||
1. **Fork** 本仓库。
|
||||
2. **修改/添加** `plugins/` 目录下的插件文件。
|
||||
3. **提交 PR**: 我们会尽快审核并合并。
|
||||
|
||||
## 💡 注意事项
|
||||
|
||||
- 请确保插件包含完整的元数据(title, author, version, description)。
|
||||
- 如果是更新已有插件,请记得**增加版本号**(如 `0.1.0` -> `0.1.1`),这样系统会自动同步更新。
|
||||
|
||||
再次感谢你的贡献!🚀
|
||||
88
README.md
88
README.md
@@ -1,10 +1,40 @@
|
||||
# OpenWebUI Extras
|
||||
<!-- ALL-CONTRIBUTORS-BADGE:START - Do not remove or modify this section -->
|
||||
[](#contributors-)
|
||||
<!-- ALL-CONTRIBUTORS-BADGE:END -->
|
||||
|
||||
English | [中文](./README_CN.md)
|
||||
|
||||
A collection of enhancements, plugins, and prompts for [OpenWebUI](https://github.com/open-webui/open-webui), developed and curated for personal use to extend functionality and improve experience.
|
||||
|
||||
[Contributing](./CONTRIBUTING.md)
|
||||
<!-- STATS_START -->
|
||||
## 📊 Community Stats
|
||||
|
||||
> 🕐 Auto-updated: 2026-01-27 02:13
|
||||
|
||||
| 👤 Author | 👥 Followers | ⭐ Points | 🏆 Contributions |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **162** | **157** | **33** |
|
||||
|
||||
| 📝 Posts | ⬇️ Downloads | 👁️ Views | 👍 Upvotes | 💾 Saves |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| **19** | **2438** | **28054** | **141** | **188** |
|
||||
|
||||
### 🔥 Top 6 Popular Plugins
|
||||
|
||||
> 🕐 Auto-updated: 2026-01-27 02:13
|
||||
|
||||
| Rank | Plugin | Version | Downloads | Views | Updated |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 639 | 5682 | 2026-01-17 |
|
||||
| 🥈 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 415 | 3740 | 2026-01-25 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 262 | 1067 | 2026-01-07 |
|
||||
| 4️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 235 | 1872 | 2026-01-17 |
|
||||
| 5️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.2 | 232 | 2499 | 2026-01-21 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 169 | 2708 | 2026-01-17 |
|
||||
|
||||
*See full stats in [Community Stats Report](./docs/community-stats.md)*
|
||||
<!-- STATS_END -->
|
||||
|
||||
## 📦 Project Contents
|
||||
|
||||
@@ -13,23 +43,27 @@ A collection of enhancements, plugins, and prompts for [OpenWebUI](https://githu
|
||||
Located in the `plugins/` directory, containing Python-based enhancements:
|
||||
|
||||
#### Actions
|
||||
|
||||
- **Smart Mind Map** (`smart-mind-map`): Generates interactive mind maps from text.
|
||||
- **Smart Infographic** (`infographic`): Transforms text into professional infographics using AntV.
|
||||
- **Knowledge Card** (`knowledge-card`): Creates beautiful flashcards for learning.
|
||||
- **Flash Card** (`flash-card`): Quickly generates beautiful flashcards for learning.
|
||||
- **Deep Dive** (`deep-dive`): A comprehensive thinking lens that dives deep into any content.
|
||||
- **Export to Excel** (`export_to_excel`): Exports chat history to Excel files.
|
||||
- **Export to Word** (`export_to_docx`): Exports chat history to Word documents.
|
||||
- **Summary** (`summary`): Text summarization tool.
|
||||
|
||||
#### Filters
|
||||
|
||||
- **Async Context Compression** (`async-context-compression`): Optimizes token usage via context compression.
|
||||
- **Context Enhancement** (`context_enhancement_filter`): Enhances chat context.
|
||||
- **Gemini Manifold Companion** (`gemini_manifold_companion`): Companion filter for Gemini Manifold.
|
||||
|
||||
- **Folder Memory** (`folder-memory`): Automatically extracts project rules from conversations and injects them into the folder's system prompt.
|
||||
- **Markdown Normalizer** (`markdown_normalizer`): Fixes common Markdown formatting issues in LLM outputs.
|
||||
|
||||
#### Pipes
|
||||
- **Gemini Manifold** (`gemini_mainfold`): Pipeline for Gemini model integration.
|
||||
|
||||
- **GitHub Copilot SDK** (`github-copilot-sdk`): Official GitHub Copilot SDK integration. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions.
|
||||
|
||||
#### Pipelines
|
||||
|
||||
- **MoE Prompt Refiner** (`moe_prompt_refiner`): Refines prompts for Mixture of Experts (MoE) summary requests to generate high-quality comprehensive reports.
|
||||
|
||||
### 🎯 Prompts
|
||||
@@ -60,14 +94,48 @@ This project is a collection of resources and does not require a Python environm
|
||||
|
||||
### Using Plugins
|
||||
|
||||
1. Browse the `/plugins` directory and download the plugin file (`.py`) you need.
|
||||
2. Go to OpenWebUI **Admin Panel** -> **Settings** -> **Plugins**.
|
||||
3. Click the upload button and select the `.py` file you just downloaded.
|
||||
4. Once uploaded, refresh the page to enable the plugin in your chat settings or toolbar.
|
||||
1. **Install from OpenWebUI Community (Recommended)**:
|
||||
- Visit my profile: [Fu-Jie's Profile](https://openwebui.com/u/Fu-Jie)
|
||||
- Browse the plugins and select the one you like.
|
||||
- Click "Get" to import it directly into your OpenWebUI instance.
|
||||
|
||||
2. **Manual Installation**:
|
||||
- Browse the `/plugins` directory and download the plugin file (`.py`) you need.
|
||||
- Go to OpenWebUI **Admin Panel** -> **Settings** -> **Plugins**.
|
||||
- Click the upload button and select the `.py` file you just downloaded.
|
||||
- Once uploaded, refresh the page to enable the plugin in your chat settings or toolbar.
|
||||
|
||||
### Contributing
|
||||
|
||||
If you have great prompts or plugins to share:
|
||||
|
||||
1. Fork this repository.
|
||||
2. Add your files to the appropriate `prompts/` or `plugins/` directory.
|
||||
3. Submit a Pull Request.
|
||||
|
||||
[Contributing](./CONTRIBUTING.md)
|
||||
|
||||
## Contributors ✨
|
||||
|
||||
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
|
||||
|
||||
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
|
||||
<!-- prettier-ignore-start -->
|
||||
<!-- markdownlint-disable -->
|
||||
<table>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://github.com/rbb-dev"><img src="https://avatars.githubusercontent.com/u/37469229?v=4?s=100" width="100px;" alt="rbb-dev"/><br /><sub><b>rbb-dev</b></sub></a><br /><a href="#ideas-rbb-dev" title="Ideas, Planning, & Feedback">🤔</a> <a href="https://github.com/Fu-Jie/awesome-openwebui/commits?author=rbb-dev" title="Code">💻</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://trade.xyz/?ref=BZ1RJRXWO"><img src="https://avatars.githubusercontent.com/u/7317522?v=4?s=100" width="100px;" alt="Raxxoor"/><br /><sub><b>Raxxoor</b></sub></a><br /><a href="https://github.com/Fu-Jie/awesome-openwebui/issues?q=author%3Adhaern" title="Bug reports">🐛</a> <a href="#ideas-dhaern" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://github.com/i-iooi-i"><img src="https://avatars.githubusercontent.com/u/1827701?v=4?s=100" width="100px;" alt="ZOLO"/><br /><sub><b>ZOLO</b></sub></a><br /><a href="https://github.com/Fu-Jie/awesome-openwebui/issues?q=author%3Ai-iooi-i" title="Bug reports">🐛</a> <a href="#ideas-i-iooi-i" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://perso.crans.org/grande/"><img src="https://avatars.githubusercontent.com/u/469017?v=4?s=100" width="100px;" alt="Johan Grande"/><br /><sub><b>Johan Grande</b></sub></a><br /><a href="#ideas-nahoj" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
<!-- markdownlint-restore -->
|
||||
<!-- prettier-ignore-end -->
|
||||
|
||||
<!-- ALL-CONTRIBUTORS-LIST:END -->
|
||||
|
||||
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!
|
||||
|
||||
100
README_CN.md
100
README_CN.md
@@ -2,28 +2,69 @@
|
||||
|
||||
[English](./README.md) | 中文
|
||||
|
||||
OpenWebUI 增强功能集合。包含个人开发与收集的### 🧩 插件 (Plugins)
|
||||
OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词等资源。
|
||||
|
||||
<!-- STATS_START -->
|
||||
## 📊 社区统计
|
||||
|
||||
> 🕐 自动更新于 2026-01-27 02:13
|
||||
|
||||
| 👤 作者 | 👥 粉丝 | ⭐ 积分 | 🏆 贡献 |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **162** | **157** | **33** |
|
||||
|
||||
| 📝 发布 | ⬇️ 下载 | 👁️ 浏览 | 👍 点赞 | 💾 收藏 |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| **19** | **2438** | **28054** | **141** | **188** |
|
||||
|
||||
### 🔥 热门插件 Top 6
|
||||
|
||||
> 🕐 自动更新于 2026-01-27 02:13
|
||||
|
||||
| 排名 | 插件 | 版本 | 下载 | 浏览 | 更新日期 |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 639 | 5682 | 2026-01-17 |
|
||||
| 🥈 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 415 | 3740 | 2026-01-25 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 262 | 1067 | 2026-01-07 |
|
||||
| 4️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 235 | 1872 | 2026-01-17 |
|
||||
| 5️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.2 | 232 | 2499 | 2026-01-21 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 169 | 2708 | 2026-01-17 |
|
||||
|
||||
*完整统计请查看 [社区统计报告](./docs/community-stats.zh.md)*
|
||||
<!-- STATS_END -->
|
||||
|
||||
## 📦 项目内容
|
||||
|
||||
### 🧩 插件 (Plugins)
|
||||
|
||||
位于 `plugins/` 目录,包含各类 Python 编写的功能增强插件:
|
||||
|
||||
#### Actions (交互增强)
|
||||
|
||||
- **Smart Mind Map** (`smart-mind-map`): 智能分析文本并生成交互式思维导图。
|
||||
- **Smart Infographic** (`infographic`): 基于 AntV 的智能信息图生成工具。
|
||||
- **Knowledge Card** (`knowledge-card`): 快速生成精美的学习记忆卡片。
|
||||
- **Flash Card** (`flash-card`): 快速生成精美的学习记忆卡片。
|
||||
- **Deep Dive** (`deep-dive`): 深度思考透镜,从背景、逻辑、洞察到行动路径的全方位分析。
|
||||
- **Export to Excel** (`export_to_excel`): 将对话内容导出为 Excel 文件。
|
||||
- **Export to Word** (`export_to_docx`): 将对话内容导出为 Word 文档。
|
||||
- **Summary** (`summary`): 文本摘要生成工具。
|
||||
|
||||
#### Filters (消息处理)
|
||||
|
||||
- **Async Context Compression** (`async-context-compression`): 异步上下文压缩,优化 Token 使用。
|
||||
- **Context Enhancement** (`context_enhancement_filter`): 上下文增强过滤器。
|
||||
- **Folder Memory** (`folder-memory`): 自动从对话中提取项目规则并注入到文件夹系统提示词中。
|
||||
- **Gemini Manifold Companion** (`gemini_manifold_companion`): Gemini Manifold 配套增强。
|
||||
|
||||
- **Gemini Multimodal Filter** (`web_gemini_multimodel_filter`): 为任意模型提供多模态能力(PDF、Office、视频等),支持智能路由和字幕精修。
|
||||
- **Markdown Normalizer** (`markdown_normalizer`): 修复 LLM 输出中常见的 Markdown 格式问题。
|
||||
- **Multi-Model Context Merger** (`multi_model_context_merger`): 自动合并并注入多模型回答的上下文。
|
||||
|
||||
#### Pipes (模型管道)
|
||||
|
||||
- **GitHub Copilot SDK** (`github-copilot-sdk`): GitHub Copilot SDK 官方集成。支持动态模型、多轮对话、流式输出、图片输入及无限会话。
|
||||
- **Gemini Manifold** (`gemini_mainfold`): 集成 Gemini 模型的管道。
|
||||
|
||||
#### Pipelines (工作流管道)
|
||||
|
||||
- **MoE Prompt Refiner** (`moe_prompt_refiner`): 优化多模型 (MoE) 汇总请求的提示词,生成高质量的综合报告。
|
||||
|
||||
### 🎯 提示词 (Prompts)
|
||||
@@ -31,40 +72,10 @@ OpenWebUI 增强功能集合。包含个人开发与收集的### 🧩 插件 (Pl
|
||||
位于 `prompts/` 目录,包含精心调优的 System Prompts:
|
||||
|
||||
- **Coding**: 编程辅助类提示词。
|
||||
- **Marketing**: 营销文案类提示词。(`/prompts/marketing`): 内容创作、品牌策划、市场分析相关的提示词
|
||||
- **Marketing**: 营销文案类提示词。
|
||||
|
||||
每个提示词都独立保存为 Markdown 文件,可直接在 OpenWebUI 中使用。
|
||||
|
||||
### 🔧 插件 (Plugins)
|
||||
|
||||
{{ ... }}
|
||||
|
||||
[贡献指南](./CONTRIBUTING.md) | [更新日志](./CHANGELOG.md)
|
||||
|
||||
## 📦 项目内容
|
||||
|
||||
### 🎯 提示词 (Prompts)
|
||||
|
||||
位于 `/prompts` 目录,包含针对不同领域的优质提示词模板:
|
||||
|
||||
- **编程类** (`/prompts/coding`): 代码生成、调试、优化相关的提示词
|
||||
- **营销类** (`/prompts/marketing`): 内容创作、品牌策划、市场分析相关的提示词
|
||||
|
||||
每个提示词都独立保存为 Markdown 文件,可直接在 OpenWebUI 中使用。
|
||||
|
||||
### 🔧 插件 (Plugins)
|
||||
|
||||
位于 `/plugins` 目录,提供三种类型的插件扩展:
|
||||
|
||||
- **过滤器 (Filters)** - 在用户输入发送给 LLM 前进行处理和优化
|
||||
- 异步上下文压缩:智能压缩长上下文,优化 token 使用效率
|
||||
|
||||
- **动作 (Actions)** - 自定义功能,从聊天中触发
|
||||
- 思维导图生成:快速生成和导出思维导图
|
||||
|
||||
- **管道 (Pipes)** - 对 LLM 响应进行处理和增强
|
||||
- 各类响应处理和格式化插件
|
||||
|
||||
## 📖 开发文档
|
||||
|
||||
位于 `docs/zh/` 目录:
|
||||
@@ -73,7 +84,7 @@ OpenWebUI 增强功能集合。包含个人开发与收集的### 🧩 插件 (Pl
|
||||
- **[从问一个AI到运营一支AI团队](./docs/zh/从问一个AI到运营一支AI团队.md)** - 深度运营经验分享。
|
||||
|
||||
更多示例请查看 `docs/examples/` 目录。
|
||||
|
||||
|
||||
## 🚀 快速开始
|
||||
|
||||
本项目是一个资源集合,无需安装 Python 环境。你只需要下载对应的文件并导入到你的 OpenWebUI 实例中即可。
|
||||
@@ -87,14 +98,23 @@ OpenWebUI 增强功能集合。包含个人开发与收集的### 🧩 插件 (Pl
|
||||
|
||||
### 使用插件 (Plugins)
|
||||
|
||||
1. 在 `/plugins` 目录中浏览并下载你需要的插件文件 (`.py`)。
|
||||
2. 打开 OpenWebUI 的 **管理员面板 (Admin Panel)** -> **设置 (Settings)** -> **插件 (Plugins)**。
|
||||
3. 点击上传按钮,选择刚才下载的 `.py` 文件。
|
||||
4. 上传成功后,刷新页面,你就可以在聊天设置或工具栏中启用该插件了。
|
||||
1. **从 OpenWebUI 社区安装 (推荐)**:
|
||||
- 访问我的主页: [Fu-Jie's Profile](https://openwebui.com/u/Fu-Jie)
|
||||
- 浏览插件列表,选择你喜欢的插件。
|
||||
- 点击 "Get" 按钮,将其直接导入到你的 OpenWebUI 实例中。
|
||||
|
||||
2. **手动安装**:
|
||||
- 在 `/plugins` 目录中浏览并下载你需要的插件文件 (`.py`)。
|
||||
- 打开 OpenWebUI 的 **管理员面板 (Admin Panel)** -> **设置 (Settings)** -> **插件 (Plugins)**。
|
||||
- 点击上传按钮,选择刚才下载的 `.py` 文件。
|
||||
- 上传成功后,刷新页面,你就可以在聊天设置或工具栏中启用该插件了。
|
||||
|
||||
### 贡献代码
|
||||
|
||||
如果你有优质的提示词或插件想要分享:
|
||||
|
||||
1. Fork 本仓库。
|
||||
2. 将你的文件添加到对应的 `prompts/` 或 `plugins/` 目录。
|
||||
3. 提交 Pull Request。
|
||||
|
||||
[贡献指南](./CONTRIBUTING_CN.md) | [更新日志](./CHANGELOG.md)
|
||||
|
||||
44
docs/PLUGIN_README_TEMPLATE.md
Normal file
44
docs/PLUGIN_README_TEMPLATE.md
Normal file
@@ -0,0 +1,44 @@
|
||||
<!--
|
||||
NOTE: This template is for the English version (README.md).
|
||||
The Chinese version (README_CN.md) MUST be translated based on this English version to ensure consistency in structure and content.
|
||||
-->
|
||||
# [Plugin Name] [Optional Emoji]
|
||||
|
||||
[Brief description of what the plugin does. Keep it concise and engaging.]
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie) | **Version:** 1.0.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
## What's New
|
||||
|
||||
<!-- Keep the changelog for the last 3 versions here. Remove this section for the initial release. -->
|
||||
|
||||
### v1.0.0
|
||||
- **Initial Release**: Released the first version of the plugin.
|
||||
- **[Feature Name]**: [Brief description of the feature].
|
||||
|
||||
## Key Features 🔑
|
||||
|
||||
- **[Feature 1]**: [Description of feature 1].
|
||||
- **[Feature 2]**: [Description of feature 2].
|
||||
- **[Feature 3]**: [Description of feature 3].
|
||||
|
||||
## How to Use 🛠️
|
||||
|
||||
1. **Install**: Add the plugin to your OpenWebUI instance.
|
||||
2. **Configure**: Adjust settings in the Valves menu (optional).
|
||||
3. **[Action Step]**: Describe how to trigger or use the plugin.
|
||||
4. **[Result Step]**: Describe the expected outcome.
|
||||
|
||||
## Configuration (Valves) ⚙️
|
||||
|
||||
| Valve | Default | Description |
|
||||
|-------|---------|-------------|
|
||||
| `VALVE_NAME` | `Default Value` | Description of what this setting does. |
|
||||
| `ANOTHER_VALVE` | `True` | Another setting description. |
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
- **Plugin not working?**: Check if the filter/action is enabled in the model settings.
|
||||
- **Debug Logs**: Enable `SHOW_DEBUG_LOG` in Valves and check the browser console (F12) for detailed logs.
|
||||
- **Error Messages**: If you see an error, please copy the full error message and report it.
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
7
docs/badges/downloads.json
Normal file
7
docs/badges/downloads.json
Normal file
@@ -0,0 +1,7 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "downloads",
|
||||
"message": "2.4k",
|
||||
"color": "blue",
|
||||
"namedLogo": "openwebui"
|
||||
}
|
||||
6
docs/badges/followers.json
Normal file
6
docs/badges/followers.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "followers",
|
||||
"message": "162",
|
||||
"color": "blue"
|
||||
}
|
||||
6
docs/badges/plugins.json
Normal file
6
docs/badges/plugins.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "plugins",
|
||||
"message": "19",
|
||||
"color": "green"
|
||||
}
|
||||
6
docs/badges/points.json
Normal file
6
docs/badges/points.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "points",
|
||||
"message": "157",
|
||||
"color": "orange"
|
||||
}
|
||||
6
docs/badges/upvotes.json
Normal file
6
docs/badges/upvotes.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "upvotes",
|
||||
"message": "141",
|
||||
"color": "brightgreen"
|
||||
}
|
||||
333
docs/community-stats.json
Normal file
333
docs/community-stats.json
Normal file
@@ -0,0 +1,333 @@
|
||||
{
|
||||
"total_posts": 19,
|
||||
"total_downloads": 2438,
|
||||
"total_views": 28054,
|
||||
"total_upvotes": 141,
|
||||
"total_downvotes": 2,
|
||||
"total_saves": 188,
|
||||
"total_comments": 37,
|
||||
"by_type": {
|
||||
"pipe": 1,
|
||||
"action": 14,
|
||||
"unknown": 3,
|
||||
"filter": 1
|
||||
},
|
||||
"posts": [
|
||||
{
|
||||
"title": "Smart Mind Map",
|
||||
"slug": "turn_any_text_into_beautiful_mind_maps_3094c59a",
|
||||
"type": "action",
|
||||
"version": "0.9.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Intelligently analyzes text content and generates interactive mind maps to help users structure and visualize knowledge.",
|
||||
"downloads": 639,
|
||||
"views": 5682,
|
||||
"upvotes": 17,
|
||||
"saves": 38,
|
||||
"comments": 11,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a"
|
||||
},
|
||||
{
|
||||
"title": "Smart Infographic",
|
||||
"slug": "smart_infographic_ad6f0c7f",
|
||||
"type": "action",
|
||||
"version": "1.4.9",
|
||||
"author": "Fu-Jie",
|
||||
"description": "AI-powered infographic generator based on AntV Infographic. Supports professional templates, auto-icon matching, and SVG/PNG downloads.",
|
||||
"downloads": 415,
|
||||
"views": 3740,
|
||||
"upvotes": 18,
|
||||
"saves": 27,
|
||||
"comments": 10,
|
||||
"created_at": "2025-12-28",
|
||||
"updated_at": "2026-01-25",
|
||||
"url": "https://openwebui.com/posts/smart_infographic_ad6f0c7f"
|
||||
},
|
||||
{
|
||||
"title": "Export to Excel",
|
||||
"slug": "export_mulit_table_to_excel_244b8f9d",
|
||||
"type": "action",
|
||||
"version": "0.3.7",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Extracts tables from chat messages and exports them to Excel (.xlsx) files with smart formatting.",
|
||||
"downloads": 262,
|
||||
"views": 1067,
|
||||
"upvotes": 4,
|
||||
"saves": 6,
|
||||
"comments": 0,
|
||||
"created_at": "2025-05-30",
|
||||
"updated_at": "2026-01-07",
|
||||
"url": "https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d"
|
||||
},
|
||||
{
|
||||
"title": "Export to Word (Enhanced)",
|
||||
"slug": "export_to_word_enhanced_formatting_fca6a315",
|
||||
"type": "action",
|
||||
"version": "0.4.3",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Export current conversation from Markdown to Word (.docx) with Mermaid diagrams rendered client-side (Mermaid.js, SVG+PNG), LaTeX math, real hyperlinks, improved tables, syntax highlighting, and blockquote support.",
|
||||
"downloads": 235,
|
||||
"views": 1872,
|
||||
"upvotes": 8,
|
||||
"saves": 21,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-03",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315"
|
||||
},
|
||||
{
|
||||
"title": "Async Context Compression",
|
||||
"slug": "async_context_compression_b1655bc8",
|
||||
"type": "action",
|
||||
"version": "1.2.2",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.",
|
||||
"downloads": 232,
|
||||
"views": 2499,
|
||||
"upvotes": 9,
|
||||
"saves": 27,
|
||||
"comments": 0,
|
||||
"created_at": "2025-11-08",
|
||||
"updated_at": "2026-01-21",
|
||||
"url": "https://openwebui.com/posts/async_context_compression_b1655bc8"
|
||||
},
|
||||
{
|
||||
"title": "Flash Card",
|
||||
"slug": "flash_card_65a2ea8f",
|
||||
"type": "action",
|
||||
"version": "0.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Quickly generates beautiful flashcards from text, extracting key points and categories.",
|
||||
"downloads": 169,
|
||||
"views": 2708,
|
||||
"upvotes": 11,
|
||||
"saves": 13,
|
||||
"comments": 2,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/flash_card_65a2ea8f"
|
||||
},
|
||||
{
|
||||
"title": "Markdown Normalizer",
|
||||
"slug": "markdown_normalizer_baaa8732",
|
||||
"type": "action",
|
||||
"version": "1.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.",
|
||||
"downloads": 153,
|
||||
"views": 2810,
|
||||
"upvotes": 10,
|
||||
"saves": 20,
|
||||
"comments": 5,
|
||||
"created_at": "2026-01-12",
|
||||
"updated_at": "2026-01-19",
|
||||
"url": "https://openwebui.com/posts/markdown_normalizer_baaa8732"
|
||||
},
|
||||
{
|
||||
"title": "Deep Dive",
|
||||
"slug": "deep_dive_c0b846e4",
|
||||
"type": "action",
|
||||
"version": "1.0.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.",
|
||||
"downloads": 93,
|
||||
"views": 850,
|
||||
"upvotes": 4,
|
||||
"saves": 8,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-08",
|
||||
"updated_at": "2026-01-08",
|
||||
"url": "https://openwebui.com/posts/deep_dive_c0b846e4"
|
||||
},
|
||||
{
|
||||
"title": "导出为 Word (增强版)",
|
||||
"slug": "导出为_word_支持公式流程图表格和代码块_8a6306c0",
|
||||
"type": "action",
|
||||
"version": "0.4.3",
|
||||
"author": "Fu-Jie",
|
||||
"description": "将对话导出为 Word (.docx),支持 Mermaid 图表 (客户端渲染 SVG+PNG)、LaTeX 数学公式、真实超链接、增强表格格式、代码高亮和引用块。",
|
||||
"downloads": 87,
|
||||
"views": 1635,
|
||||
"upvotes": 11,
|
||||
"saves": 4,
|
||||
"comments": 4,
|
||||
"created_at": "2026-01-04",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0"
|
||||
},
|
||||
{
|
||||
"title": "📊 智能信息图 (AntV Infographic)",
|
||||
"slug": "智能信息图_e04a48ff",
|
||||
"type": "action",
|
||||
"version": "1.4.9",
|
||||
"author": "Fu-Jie",
|
||||
"description": "基于 AntV Infographic 的智能信息图生成插件。支持多种专业模板,自动图标匹配,并提供 SVG/PNG 下载功能。",
|
||||
"downloads": 47,
|
||||
"views": 792,
|
||||
"upvotes": 6,
|
||||
"saves": 0,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-28",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/智能信息图_e04a48ff"
|
||||
},
|
||||
{
|
||||
"title": "📂 Folder Memory – Auto-Evolving Project Context",
|
||||
"slug": "folder_memory_auto_evolving_project_context_4a9875b2",
|
||||
"type": "filter",
|
||||
"version": "0.1.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Automatically extracts project rules from conversations and injects them into the folder's system prompt.",
|
||||
"downloads": 27,
|
||||
"views": 760,
|
||||
"upvotes": 4,
|
||||
"saves": 5,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-20",
|
||||
"updated_at": "2026-01-20",
|
||||
"url": "https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2"
|
||||
},
|
||||
{
|
||||
"title": "思维导图",
|
||||
"slug": "智能生成交互式思维导图帮助用户可视化知识_8d4b097b",
|
||||
"type": "action",
|
||||
"version": "0.9.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "智能分析文本内容,生成交互式思维导图,帮助用户结构化和可视化知识。",
|
||||
"downloads": 27,
|
||||
"views": 457,
|
||||
"upvotes": 4,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-31",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b"
|
||||
},
|
||||
{
|
||||
"title": "异步上下文压缩",
|
||||
"slug": "异步上下文压缩_5c0617cb",
|
||||
"type": "action",
|
||||
"version": "1.2.2",
|
||||
"author": "Fu-Jie",
|
||||
"description": "通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。",
|
||||
"downloads": 22,
|
||||
"views": 502,
|
||||
"upvotes": 5,
|
||||
"saves": 2,
|
||||
"comments": 0,
|
||||
"created_at": "2025-11-08",
|
||||
"updated_at": "2026-01-21",
|
||||
"url": "https://openwebui.com/posts/异步上下文压缩_5c0617cb"
|
||||
},
|
||||
{
|
||||
"title": "闪记卡 (Flash Card)",
|
||||
"slug": "闪记卡生成插件_4a31eac3",
|
||||
"type": "action",
|
||||
"version": "0.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "快速将文本提炼为精美的学习记忆卡片,支持核心要点提取与分类。",
|
||||
"downloads": 19,
|
||||
"views": 514,
|
||||
"upvotes": 6,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/闪记卡生成插件_4a31eac3"
|
||||
},
|
||||
{
|
||||
"title": "精读",
|
||||
"slug": "精读_99830b0f",
|
||||
"type": "action",
|
||||
"version": "1.0.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。",
|
||||
"downloads": 9,
|
||||
"views": 311,
|
||||
"upvotes": 3,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-08",
|
||||
"updated_at": "2026-01-08",
|
||||
"url": "https://openwebui.com/posts/精读_99830b0f"
|
||||
},
|
||||
{
|
||||
"title": "GitHub Copilot Official SDK Pipe",
|
||||
"slug": "github_copilot_official_sdk_pipe_ce96f7b4",
|
||||
"type": "pipe",
|
||||
"version": "0.1.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Integrate GitHub Copilot SDK. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions (context compaction).",
|
||||
"downloads": 2,
|
||||
"views": 81,
|
||||
"upvotes": 2,
|
||||
"saves": 0,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-26",
|
||||
"updated_at": "2026-01-26",
|
||||
"url": "https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4"
|
||||
},
|
||||
{
|
||||
"title": "🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager",
|
||||
"slug": "open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e",
|
||||
"type": "unknown",
|
||||
"version": "",
|
||||
"author": "",
|
||||
"description": "",
|
||||
"downloads": 0,
|
||||
"views": 401,
|
||||
"upvotes": 6,
|
||||
"saves": 6,
|
||||
"comments": 3,
|
||||
"created_at": "2026-01-25",
|
||||
"updated_at": "2026-01-25",
|
||||
"url": "https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e"
|
||||
},
|
||||
{
|
||||
"title": "Review of Claude Haiku 4.5",
|
||||
"slug": "review_of_claude_haiku_45_41b0db39",
|
||||
"type": "unknown",
|
||||
"version": "",
|
||||
"author": "",
|
||||
"description": "",
|
||||
"downloads": 0,
|
||||
"views": 95,
|
||||
"upvotes": 1,
|
||||
"saves": 0,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-14",
|
||||
"updated_at": "2026-01-14",
|
||||
"url": "https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39"
|
||||
},
|
||||
{
|
||||
"title": " 🛠️ Debug Open WebUI Plugins in Your Browser",
|
||||
"slug": "debug_open_webui_plugins_in_your_browser_81bf7960",
|
||||
"type": "unknown",
|
||||
"version": "",
|
||||
"author": "",
|
||||
"description": "",
|
||||
"downloads": 0,
|
||||
"views": 1278,
|
||||
"upvotes": 12,
|
||||
"saves": 8,
|
||||
"comments": 2,
|
||||
"created_at": "2026-01-10",
|
||||
"updated_at": "2026-01-10",
|
||||
"url": "https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960"
|
||||
}
|
||||
],
|
||||
"user": {
|
||||
"username": "Fu-Jie",
|
||||
"name": "Fu-Jie",
|
||||
"profile_url": "https://openwebui.com/u/Fu-Jie",
|
||||
"profile_image": "https://community.s3.openwebui.com/uploads/users/b15d1348-4347-42b4-b815-e053342d6cb0/profile_d9510745-4bd4-4f8f-a997-4a21847d9300.webp",
|
||||
"followers": 162,
|
||||
"following": 3,
|
||||
"total_points": 157,
|
||||
"post_points": 139,
|
||||
"comment_points": 18,
|
||||
"contributions": 33
|
||||
}
|
||||
}
|
||||
45
docs/community-stats.md
Normal file
45
docs/community-stats.md
Normal file
@@ -0,0 +1,45 @@
|
||||
# 📊 OpenWebUI Community Stats Report
|
||||
|
||||
> 📅 Updated: 2026-01-27 02:13
|
||||
|
||||
## 📈 Overview
|
||||
|
||||
| Metric | Value |
|
||||
|------|------|
|
||||
| 📝 Total Posts | 19 |
|
||||
| ⬇️ Total Downloads | 2438 |
|
||||
| 👁️ Total Views | 28054 |
|
||||
| 👍 Total Upvotes | 141 |
|
||||
| 💾 Total Saves | 188 |
|
||||
| 💬 Total Comments | 37 |
|
||||
|
||||
## 📂 By Type
|
||||
|
||||
- **pipe**: 1
|
||||
- **action**: 14
|
||||
- **unknown**: 3
|
||||
- **filter**: 1
|
||||
|
||||
## 📋 Posts List
|
||||
|
||||
| Rank | Title | Type | Version | Downloads | Views | Upvotes | Saves | Updated |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 639 | 5682 | 17 | 38 | 2026-01-17 |
|
||||
| 2 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 415 | 3740 | 18 | 27 | 2026-01-25 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 262 | 1067 | 4 | 6 | 2026-01-07 |
|
||||
| 4 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 235 | 1872 | 8 | 21 | 2026-01-17 |
|
||||
| 5 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.2 | 232 | 2499 | 9 | 27 | 2026-01-21 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 169 | 2708 | 11 | 13 | 2026-01-17 |
|
||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 153 | 2810 | 10 | 20 | 2026-01-19 |
|
||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 93 | 850 | 4 | 8 | 2026-01-08 |
|
||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 87 | 1635 | 11 | 4 | 2026-01-17 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 47 | 792 | 6 | 0 | 2026-01-17 |
|
||||
| 11 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 27 | 760 | 4 | 5 | 2026-01-20 |
|
||||
| 12 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 457 | 4 | 1 | 2026-01-17 |
|
||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.2 | 22 | 502 | 5 | 2 | 2026-01-21 |
|
||||
| 14 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 514 | 6 | 1 | 2026-01-17 |
|
||||
| 15 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 9 | 311 | 3 | 1 | 2026-01-08 |
|
||||
| 16 | [GitHub Copilot Official SDK Pipe](https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4) | pipe | 0.1.1 | 2 | 81 | 2 | 0 | 2026-01-26 |
|
||||
| 17 | [🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager](https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e) | unknown | | 0 | 401 | 6 | 6 | 2026-01-25 |
|
||||
| 18 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 95 | 1 | 0 | 2026-01-14 |
|
||||
| 19 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1278 | 12 | 8 | 2026-01-10 |
|
||||
45
docs/community-stats.zh.md
Normal file
45
docs/community-stats.zh.md
Normal file
@@ -0,0 +1,45 @@
|
||||
# 📊 OpenWebUI 社区统计报告
|
||||
|
||||
> 📅 更新时间: 2026-01-27 02:13
|
||||
|
||||
## 📈 总览
|
||||
|
||||
| 指标 | 数值 |
|
||||
|------|------|
|
||||
| 📝 发布数量 | 19 |
|
||||
| ⬇️ 总下载量 | 2438 |
|
||||
| 👁️ 总浏览量 | 28054 |
|
||||
| 👍 总点赞数 | 141 |
|
||||
| 💾 总收藏数 | 188 |
|
||||
| 💬 总评论数 | 37 |
|
||||
|
||||
## 📂 按类型分类
|
||||
|
||||
- **pipe**: 1
|
||||
- **action**: 14
|
||||
- **unknown**: 3
|
||||
- **filter**: 1
|
||||
|
||||
## 📋 发布列表
|
||||
|
||||
| 排名 | 标题 | 类型 | 版本 | 下载 | 浏览 | 点赞 | 收藏 | 更新日期 |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 639 | 5682 | 17 | 38 | 2026-01-17 |
|
||||
| 2 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 415 | 3740 | 18 | 27 | 2026-01-25 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 262 | 1067 | 4 | 6 | 2026-01-07 |
|
||||
| 4 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 235 | 1872 | 8 | 21 | 2026-01-17 |
|
||||
| 5 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.2 | 232 | 2499 | 9 | 27 | 2026-01-21 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 169 | 2708 | 11 | 13 | 2026-01-17 |
|
||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 153 | 2810 | 10 | 20 | 2026-01-19 |
|
||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 93 | 850 | 4 | 8 | 2026-01-08 |
|
||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 87 | 1635 | 11 | 4 | 2026-01-17 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 47 | 792 | 6 | 0 | 2026-01-17 |
|
||||
| 11 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 27 | 760 | 4 | 5 | 2026-01-20 |
|
||||
| 12 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 457 | 4 | 1 | 2026-01-17 |
|
||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.2 | 22 | 502 | 5 | 2 | 2026-01-21 |
|
||||
| 14 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 514 | 6 | 1 | 2026-01-17 |
|
||||
| 15 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 9 | 311 | 3 | 1 | 2026-01-08 |
|
||||
| 16 | [GitHub Copilot Official SDK Pipe](https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4) | pipe | 0.1.1 | 2 | 81 | 2 | 0 | 2026-01-26 |
|
||||
| 17 | [🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager](https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e) | unknown | | 0 | 401 | 6 | 6 | 2026-01-25 |
|
||||
| 18 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 95 | 1 | 0 | 2026-01-14 |
|
||||
| 19 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1278 | 12 | 8 | 2026-01-10 |
|
||||
150
docs/development/frontend-console-debugging.md
Normal file
150
docs/development/frontend-console-debugging.md
Normal file
@@ -0,0 +1,150 @@
|
||||
# 🛠️ Debugging Python Plugins with Frontend Console
|
||||
|
||||
When developing plugins for Open WebUI, debugging can be challenging. Standard `print()` statements or server-side logging might not always be accessible, especially in hosted environments or when you want to see the data flow in real-time alongside the UI interactions.
|
||||
|
||||
This guide introduces a powerful technique: **Frontend Console Debugging**. By injecting JavaScript from your Python plugin, you can print structured logs directly to the browser's Developer Tools console (F12).
|
||||
|
||||
## Why Frontend Debugging?
|
||||
|
||||
* **Real-time Feedback**: See logs immediately as actions happen in the browser.
|
||||
* **Rich Objects**: Inspect complex JSON objects (like `body` or `messages`) interactively, rather than reading massive text dumps.
|
||||
* **No Server Access Needed**: Debug issues even if you don't have SSH/Console access to the backend server.
|
||||
* **Clean Output**: Group logs using `console.group()` to keep your console organized.
|
||||
|
||||
## The Core Mechanism
|
||||
|
||||
Open WebUI plugins (both Actions and Filters) support an event system. We can leverage the `__event_call__` (or sometimes `__event_emitter__`) to send a special event of type `execute`. This tells the frontend to run the provided JavaScript code.
|
||||
|
||||
### The Helper Method
|
||||
|
||||
To make this easy to use, we recommend adding a helper method `_emit_debug_log` to your plugin class.
|
||||
|
||||
```python
|
||||
import json
|
||||
from typing import List
|
||||
|
||||
async def _emit_debug_log(
|
||||
self,
|
||||
__event_call__,
|
||||
title: str,
|
||||
data: dict
|
||||
):
|
||||
"""
|
||||
Emit debug log to browser console via JS execution.
|
||||
|
||||
Args:
|
||||
__event_call__: The event callable passed to action/outlet.
|
||||
title: A title for the log group.
|
||||
data: A dictionary of data to log.
|
||||
"""
|
||||
# 1. Check if debugging is enabled (recommended)
|
||||
if not getattr(self.valves, "show_debug_log", True) or not __event_call__:
|
||||
return
|
||||
|
||||
try:
|
||||
# 2. Construct the JavaScript code
|
||||
# We use an async IIFE (Immediately Invoked Function Expression)
|
||||
# to ensure a clean scope and support await if needed.
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ Plugin Debug: {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
# 3. Send the execute event
|
||||
await __event_call__(
|
||||
{
|
||||
"type": "execute",
|
||||
"data": {"code": js_code},
|
||||
}
|
||||
)
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
```
|
||||
|
||||
## Implementation Steps
|
||||
|
||||
### 1. Add a Valve for Control
|
||||
|
||||
It's best practice to make debugging optional so it doesn't clutter the console for normal users.
|
||||
|
||||
```python
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class Filter:
|
||||
class Valves(BaseModel):
|
||||
show_debug_log: bool = Field(
|
||||
default=False,
|
||||
description="Print debug logs to browser console (F12)"
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
```
|
||||
|
||||
### 2. Inject `__event_call__`
|
||||
|
||||
Ensure your `action` (for Actions) or `outlet` (for Filters) method accepts `__event_call__`.
|
||||
|
||||
**For Filters (`outlet`):**
|
||||
|
||||
```python
|
||||
async def outlet(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: Optional[dict] = None,
|
||||
__event_call__=None, # <--- Add this
|
||||
__metadata__: Optional[dict] = None,
|
||||
) -> dict:
|
||||
```
|
||||
|
||||
**For Actions (`action`):**
|
||||
|
||||
```python
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__=None,
|
||||
__event_call__=None, # <--- Add this
|
||||
__request__=None,
|
||||
):
|
||||
```
|
||||
|
||||
### 3. Call the Helper
|
||||
|
||||
Now you can log anything, anywhere in your logic!
|
||||
|
||||
```python
|
||||
# Inside your logic...
|
||||
new_content = self.process_content(content)
|
||||
|
||||
# Log the before and after
|
||||
await self._emit_debug_log(
|
||||
__event_call__,
|
||||
"Content Normalization",
|
||||
{
|
||||
"original": content,
|
||||
"processed": new_content,
|
||||
"changes": diff_list
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Use `json.dumps`**: Always serialize your Python dictionaries to JSON strings before embedding them in the f-string. This handles escaping quotes and special characters correctly.
|
||||
2. **Async IIFE**: Wrapping your JS in `(async function() { ... })();` is safer than raw code. It prevents variable collisions with other scripts and allows using `await` inside your debug script if you ever need to check DOM elements.
|
||||
3. **Check for None**: Always check if `__event_call__` is not None before using it, as it might not be available in all contexts (e.g., when running tests or in older Open WebUI versions).
|
||||
|
||||
## Example Output
|
||||
|
||||
When enabled, your browser console will show:
|
||||
|
||||
```text
|
||||
> 🛠️ Plugin Debug: Content Normalization
|
||||
> {original: "...", processed: "...", changes: [...]}
|
||||
```
|
||||
|
||||
You can expand the object to inspect every detail of your data. Happy debugging!
|
||||
64
docs/development/mermaid-syntax-standards.md
Normal file
64
docs/development/mermaid-syntax-standards.md
Normal file
@@ -0,0 +1,64 @@
|
||||
# Mermaid Syntax Standards & Best Practices
|
||||
|
||||
This document summarizes the official syntax standards for Mermaid flowcharts, focusing on node labels, quoting rules, and special character handling. It serves as a reference for the `markdown_normalizer` plugin logic.
|
||||
|
||||
## 1. Node Shapes & Syntax
|
||||
|
||||
Mermaid supports various node shapes defined by specific wrapping characters.
|
||||
|
||||
| Shape | Syntax | Example |
|
||||
| :--- | :--- | :--- |
|
||||
| **Rectangle** (Default) | `id[Label]` | `A[Start]` |
|
||||
| **Rounded** | `id(Label)` | `B(Process)` |
|
||||
| **Stadium** (Pill) | `id([Label])` | `C([End])` |
|
||||
| **Subroutine** | `id[[Label]]` | `D[[Subroutine]]` |
|
||||
| **Cylinder** (Database) | `id[(Label)]` | `E[(Database)]` |
|
||||
| **Circle** | `id((Label))` | `F((Point))` |
|
||||
| **Double Circle** | `id(((Label)))` | `G(((Endpoint)))` |
|
||||
| **Asymmetric** | `id>Label]` | `H>Flag]` |
|
||||
| **Rhombus** (Decision) | `id{Label}` | `I{Decision}` |
|
||||
| **Hexagon** | `id{{Label}}` | `J{{Prepare}}` |
|
||||
| **Parallelogram** | `id[/Label/]` | `K[/Input/]` |
|
||||
| **Parallelogram Alt** | `id[\Label\]` | `L[\Output\]` |
|
||||
| **Trapezoid** | `id[/Label\]` | `M[/Trap/]` |
|
||||
| **Trapezoid Alt** | `id[\Label/]` | `N[\TrapAlt/]` |
|
||||
|
||||
## 2. Quoting Rules (Critical)
|
||||
|
||||
### Why Quote?
|
||||
Quoting node labels is **highly recommended** and sometimes **mandatory** to prevent syntax errors.
|
||||
|
||||
### Mandatory Quoting Scenarios
|
||||
You **MUST** enclose labels in double quotes `"` if they contain:
|
||||
1. **Special Characters**: `()`, `[]`, `{}`, `;`, `"`, etc.
|
||||
2. **Keywords**: Words like `end`, `subgraph`, etc., if used in specific contexts.
|
||||
3. **Unicode/Emoji**: While often supported without quotes, quoting ensures consistent rendering across different environments.
|
||||
4. **Markdown**: If you want to use Markdown formatting (bold, italic) inside a label.
|
||||
|
||||
### Best Practice: Always Quote
|
||||
To ensure robustness, especially when processing LLM-generated content which may contain unpredictable characters, **always enclosing labels in double quotes is the safest strategy**.
|
||||
|
||||
**Examples:**
|
||||
* ❌ Risky: `id(Start: 15:00)` (Colon might be interpreted as style separator)
|
||||
* ✅ Safe: `id("Start: 15:00")`
|
||||
* ❌ Broken: `id(Func(x))` (Nested parentheses break parsing)
|
||||
* ✅ Safe: `id("Func(x)")`
|
||||
|
||||
## 3. Escape Characters
|
||||
|
||||
Inside a quoted string:
|
||||
* Double quotes `"` must be escaped as `\"`.
|
||||
* HTML entities (e.g., `#35;` for `#`) can be used.
|
||||
|
||||
## 4. Plugin Logic Verification
|
||||
|
||||
The `markdown_normalizer` plugin implements the following logic:
|
||||
|
||||
1. **Detection**: Identifies Mermaid node definitions using a comprehensive regex covering all shapes above.
|
||||
2. **Normalization**:
|
||||
* Checks if the label is already quoted.
|
||||
* If **NOT quoted**, it wraps the label in double quotes `""`.
|
||||
* Escapes any existing double quotes inside the label (`"` -> `\"`).
|
||||
3. **Shape Preservation**: The regex captures the specific opening and closing delimiters (e.g., `((` and `))`) to ensure the node shape is strictly preserved during normalization.
|
||||
|
||||
**Conclusion**: The plugin's behavior of automatically adding quotes to unquoted labels is **fully aligned with Mermaid's official best practices** for robustness and error prevention.
|
||||
@@ -7,10 +7,10 @@
|
||||
## 📚 Table of Contents
|
||||
|
||||
1. [Quick Start](#1-quick-start)
|
||||
2. [Core Concepts & SDK Details](#2-core-concepts--sdk-details)
|
||||
2. [Core Concepts & SDK Details](#2-core-concepts-sdk-details)
|
||||
3. [Deep Dive into Plugin Types](#3-deep-dive-into-plugin-types)
|
||||
4. [Advanced Development Patterns](#4-advanced-development-patterns)
|
||||
5. [Best Practices & Design Principles](#5-best-practices--design-principles)
|
||||
5. [Best Practices & Design Principles](#5-best-practices-design-principles)
|
||||
6. [Troubleshooting](#6-troubleshooting)
|
||||
|
||||
---
|
||||
@@ -235,6 +235,124 @@ llm_response = await generate_chat_completion(
|
||||
)
|
||||
```
|
||||
|
||||
### 4.4 JS Render to Markdown (Data URL Embedding)
|
||||
|
||||
For scenarios requiring complex frontend rendering (e.g., AntV charts, Mermaid diagrams) but wanting **persistent pure Markdown output**, use the Data URL embedding pattern:
|
||||
|
||||
#### Workflow
|
||||
|
||||
```
|
||||
┌──────────────────────────────────────────────────────────────┐
|
||||
│ 1. Python Action │
|
||||
│ ├── Analyze message content │
|
||||
│ ├── Call LLM to generate structured data (optional) │
|
||||
│ └── Send JS code to frontend via __event_call__ │
|
||||
├──────────────────────────────────────────────────────────────┤
|
||||
│ 2. Browser JS (via __event_call__) │
|
||||
│ ├── Dynamically load visualization library │
|
||||
│ ├── Render SVG/Canvas offscreen │
|
||||
│ ├── Export to Base64 Data URL via toDataURL() │
|
||||
│ └── Update message content via REST API │
|
||||
├──────────────────────────────────────────────────────────────┤
|
||||
│ 3. Markdown Rendering │
|
||||
│ └── Display  │
|
||||
└──────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
#### Python Side (Send JS for Execution)
|
||||
|
||||
```python
|
||||
async def action(self, body, __event_call__, __metadata__, ...):
|
||||
chat_id = self._extract_chat_id(body, __metadata__)
|
||||
message_id = self._extract_message_id(body, __metadata__)
|
||||
|
||||
# Generate JS code
|
||||
js_code = self._generate_js_code(
|
||||
chat_id=chat_id,
|
||||
message_id=message_id,
|
||||
data=processed_data,
|
||||
)
|
||||
|
||||
# Execute JS
|
||||
if __event_call__:
|
||||
await __event_call__({
|
||||
"type": "execute",
|
||||
"data": {"code": js_code}
|
||||
})
|
||||
```
|
||||
|
||||
#### JavaScript Side (Render and Write-back)
|
||||
|
||||
```javascript
|
||||
(async function() {
|
||||
// 1. Load visualization library
|
||||
if (typeof VisualizationLib === 'undefined') {
|
||||
await new Promise((resolve, reject) => {
|
||||
const script = document.createElement('script');
|
||||
script.src = 'https://cdn.example.com/lib.min.js';
|
||||
script.onload = resolve;
|
||||
script.onerror = reject;
|
||||
document.head.appendChild(script);
|
||||
});
|
||||
}
|
||||
|
||||
// 2. Create offscreen container
|
||||
const container = document.createElement('div');
|
||||
container.style.cssText = 'position:absolute;left:-9999px;';
|
||||
document.body.appendChild(container);
|
||||
|
||||
// 3. Render visualization
|
||||
const instance = new VisualizationLib({ container });
|
||||
instance.render(data);
|
||||
|
||||
// 4. Export to Data URL
|
||||
const dataUrl = await instance.toDataURL({ type: 'svg', embedResources: true });
|
||||
|
||||
// 5. Cleanup
|
||||
instance.destroy();
|
||||
document.body.removeChild(container);
|
||||
|
||||
// 6. Generate Markdown image
|
||||
const markdownImage = ``;
|
||||
|
||||
// 7. Update message via API
|
||||
const token = localStorage.getItem("token");
|
||||
await fetch(`/api/v1/chats/${chatId}/messages/${messageId}/event`, {
|
||||
method: "POST",
|
||||
headers: {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": `Bearer ${token}`
|
||||
},
|
||||
body: JSON.stringify({
|
||||
type: "chat:message",
|
||||
data: { content: originalContent + "\n\n" + markdownImage }
|
||||
})
|
||||
});
|
||||
})();
|
||||
```
|
||||
|
||||
#### Benefits
|
||||
|
||||
- **Pure Markdown Output**: Standard Markdown image syntax, no HTML code blocks
|
||||
- **Self-Contained**: Images embedded as Base64 Data URL, no external dependencies
|
||||
- **Persistent**: Via API write-back, images remain after page reload
|
||||
- **Cross-Platform**: Works on any client supporting Markdown images
|
||||
|
||||
#### HTML Injection vs JS Render to Markdown
|
||||
|
||||
| Feature | HTML Injection | JS Render + Markdown |
|
||||
|---------|----------------|----------------------|
|
||||
| Output Format | HTML code block | Markdown image |
|
||||
| Interactivity | ✅ Buttons, animations | ❌ Static image |
|
||||
| External Deps | Requires JS libraries | None (self-contained) |
|
||||
| Persistence | Depends on browser | ✅ Permanent |
|
||||
| File Export | Needs special handling | ✅ Direct export |
|
||||
| Use Case | Interactive content | Infographics, chart snapshots |
|
||||
|
||||
#### Reference Implementations
|
||||
|
||||
- `plugins/actions/infographic/infographic.py` - Production-ready implementation using AntV + Data URL
|
||||
|
||||
---
|
||||
|
||||
## 5. Best Practices & Design Principles
|
||||
|
||||
@@ -4,19 +4,19 @@
|
||||
|
||||
## 📚 目录
|
||||
|
||||
1. [插件开发快速入门](#1-插件开发快速入门)
|
||||
2. [核心概念与 SDK 详解](#2-核心概念与-sdk-详解)
|
||||
3. [插件类型深度解析](#3-插件类型深度解析)
|
||||
* [Action (动作)](#31-action-动作)
|
||||
* [Filter (过滤器)](#32-filter-过滤器)
|
||||
* [Pipe (管道)](#33-pipe-管道)
|
||||
4. [高级开发模式](#4-高级开发模式)
|
||||
5. [最佳实践与设计原则](#5-最佳实践与设计原则)
|
||||
6. [故障排查](#6-故障排查)
|
||||
1. [插件开发快速入门](#1-quick-start)
|
||||
2. [核心概念与 SDK 详解](#2-core-concepts-sdk-details)
|
||||
3. [插件类型深度解析](#3-plugin-types)
|
||||
* [Action (动作)](#31-action)
|
||||
* [Filter (过滤器)](#32-filter)
|
||||
* [Pipe (管道)](#33-pipe)
|
||||
4. [高级开发模式](#4-advanced-patterns)
|
||||
5. [最佳实践与设计原则](#5-best-practices)
|
||||
6. [故障排查](#6-troubleshooting)
|
||||
|
||||
---
|
||||
|
||||
## 1. 插件开发快速入门
|
||||
## 1. 插件开发快速入门 {: #1-quick-start }
|
||||
|
||||
### 1.1 什么是 OpenWebUI 插件?
|
||||
|
||||
@@ -64,7 +64,7 @@ class Action:
|
||||
|
||||
---
|
||||
|
||||
## 2. 核心概念与 SDK 详解
|
||||
## 2. 核心概念与 SDK 详解 {: #2-core-concepts-sdk-details }
|
||||
|
||||
### 2.1 ⚠️ 重要:同步与异步
|
||||
|
||||
@@ -107,9 +107,9 @@ class Filter:
|
||||
|
||||
---
|
||||
|
||||
## 3. 插件类型深度解析
|
||||
## 3. 插件类型深度解析 {: #3-plugin-types }
|
||||
|
||||
### 3.1 Action (动作)
|
||||
### 3.1 Action (动作) {: #31-action }
|
||||
|
||||
**定位**:在消息下方添加按钮,用户点击触发。
|
||||
|
||||
@@ -134,7 +134,7 @@ async def action(self, body, __event_call__):
|
||||
await __event_call__({"type": "execute", "data": {"code": js}})
|
||||
```
|
||||
|
||||
### 3.2 Filter (过滤器)
|
||||
### 3.2 Filter (过滤器) {: #32-filter }
|
||||
|
||||
**定位**:中间件,拦截并修改请求/响应。
|
||||
|
||||
@@ -155,7 +155,7 @@ async def inlet(self, body, __metadata__):
|
||||
return body
|
||||
```
|
||||
|
||||
### 3.3 Pipe (管道)
|
||||
### 3.3 Pipe (管道) {: #33-pipe }
|
||||
|
||||
**定位**:自定义模型/代理。
|
||||
|
||||
@@ -177,7 +177,7 @@ class Pipe:
|
||||
|
||||
---
|
||||
|
||||
## 4. 高级开发模式
|
||||
## 4. 高级开发模式 {: #4-advanced-patterns }
|
||||
|
||||
### 4.1 Pipe 与 Filter 协同
|
||||
利用 `__request__.app.state` 在不同插件间共享数据。
|
||||
@@ -199,9 +199,125 @@ async def background_job(self, chat_id):
|
||||
pass
|
||||
```
|
||||
|
||||
---
|
||||
### 4.3 JS 渲染并嵌入 Markdown (Data URL 嵌入)
|
||||
|
||||
## 5. 最佳实践与设计原则
|
||||
对于需要复杂前端渲染(如 AntV 图表、Mermaid 图表)但希望结果**持久化为纯 Markdown 格式**的场景,推荐使用 Data URL 嵌入模式:
|
||||
|
||||
#### 工作流程
|
||||
|
||||
```
|
||||
┌──────────────────────────────────────────────────────────────┐
|
||||
│ 1. Python Action │
|
||||
│ ├── 分析消息内容 │
|
||||
│ ├── 调用 LLM 生成结构化数据(可选) │
|
||||
│ └── 通过 __event_call__ 发送 JS 代码到前端 │
|
||||
├──────────────────────────────────────────────────────────────┤
|
||||
│ 2. Browser JS (通过 __event_call__) │
|
||||
│ ├── 动态加载可视化库 │
|
||||
│ ├── 离屏渲染 SVG/Canvas │
|
||||
│ ├── 使用 toDataURL() 导出 Base64 Data URL │
|
||||
│ └── 通过 REST API 更新消息内容 │
|
||||
├──────────────────────────────────────────────────────────────┤
|
||||
│ 3. Markdown 渲染 │
|
||||
│ └── 显示  │
|
||||
└──────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
#### Python 端(发送 JS 执行)
|
||||
|
||||
```python
|
||||
async def action(self, body, __event_call__, __metadata__, ...):
|
||||
chat_id = self._extract_chat_id(body, __metadata__)
|
||||
message_id = self._extract_message_id(body, __metadata__)
|
||||
|
||||
# 生成 JS 代码
|
||||
js_code = self._generate_js_code(
|
||||
chat_id=chat_id,
|
||||
message_id=message_id,
|
||||
data=processed_data,
|
||||
)
|
||||
|
||||
# 执行 JS
|
||||
if __event_call__:
|
||||
await __event_call__({
|
||||
"type": "execute",
|
||||
"data": {"code": js_code}
|
||||
})
|
||||
```
|
||||
|
||||
#### JavaScript 端(渲染并回写)
|
||||
|
||||
```javascript
|
||||
(async function() {
|
||||
// 1. 加载可视化库
|
||||
if (typeof VisualizationLib === 'undefined') {
|
||||
await new Promise((resolve, reject) => {
|
||||
const script = document.createElement('script');
|
||||
script.src = 'https://cdn.example.com/lib.min.js';
|
||||
script.onload = resolve;
|
||||
script.onerror = reject;
|
||||
document.head.appendChild(script);
|
||||
});
|
||||
}
|
||||
|
||||
// 2. 创建离屏容器
|
||||
const container = document.createElement('div');
|
||||
container.style.cssText = 'position:absolute;left:-9999px;';
|
||||
document.body.appendChild(container);
|
||||
|
||||
// 3. 渲染可视化
|
||||
const instance = new VisualizationLib({ container });
|
||||
instance.render(data);
|
||||
|
||||
// 4. 导出为 Data URL
|
||||
const dataUrl = await instance.toDataURL({ type: 'svg', embedResources: true });
|
||||
|
||||
// 5. 清理
|
||||
instance.destroy();
|
||||
document.body.removeChild(container);
|
||||
|
||||
// 6. 生成 Markdown 图片
|
||||
const markdownImage = ``;
|
||||
|
||||
// 7. 通过 API 更新消息
|
||||
const token = localStorage.getItem("token");
|
||||
await fetch(`/api/v1/chats/${chatId}/messages/${messageId}/event`, {
|
||||
method: "POST",
|
||||
headers: {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": `Bearer ${token}`
|
||||
},
|
||||
body: JSON.stringify({
|
||||
type: "chat:message",
|
||||
data: { content: originalContent + "\n\n" + markdownImage }
|
||||
})
|
||||
});
|
||||
})();
|
||||
```
|
||||
|
||||
#### 优势
|
||||
|
||||
- **纯 Markdown 输出**:结果是标准的 Markdown 图片语法,无需 HTML 代码块
|
||||
- **自包含**:图片以 Base64 Data URL 嵌入,无外部依赖
|
||||
- **持久化**:通过 API 回写,消息重新加载后图片仍然存在
|
||||
- **跨平台**:任何支持 Markdown 图片的客户端都能显示
|
||||
|
||||
#### HTML 注入 vs JS 渲染嵌入 Markdown
|
||||
|
||||
| 特性 | HTML 注入 | JS 渲染 + Markdown 图片 |
|
||||
|------|----------|------------------------|
|
||||
| 输出格式 | HTML 代码块 | Markdown 图片 |
|
||||
| 交互性 | ✅ 支持按钮、动画 | ❌ 静态图片 |
|
||||
| 外部依赖 | 需要加载 JS 库 | 无(图片自包含) |
|
||||
| 持久化 | 依赖浏览器渲染 | ✅ 永久可见 |
|
||||
| 文件导出 | 需特殊处理 | ✅ 直接导出 |
|
||||
| 适用场景 | 交互式内容 | 信息图、图表快照 |
|
||||
|
||||
#### 参考实现
|
||||
|
||||
- `plugins/actions/infographic/infographic.py` - 基于 AntV + Data URL 的生产级实现
|
||||
|
||||
## 5. 最佳实践与设计原则 {: #5-best-practices }
|
||||
|
||||
### 5.1 命名与定位
|
||||
* **简短有力**:如 "闪记卡", "精读"。避免 "文本分析助手" 这种泛词。
|
||||
@@ -227,7 +343,7 @@ except Exception as e:
|
||||
|
||||
---
|
||||
|
||||
## 6. 故障排查
|
||||
## 6. 故障排查 {: #6-troubleshooting }
|
||||
|
||||
* **HTML 不显示?** 确保包裹在 ` ```html ... ``` ` 代码块中。
|
||||
* **数据库报错?** 检查是否在 `async` 函数中直接调用了同步的 DB 方法,请使用 `asyncio.to_thread`。
|
||||
|
||||
@@ -21,7 +21,7 @@
|
||||
|
||||
Open WebUI 通过文件顶部的特定格式注释来识别和展示插件信息。
|
||||
|
||||
**代码示例 (`思维导图.py`):**
|
||||
**代码示例 (`smart_mind_map_cn.py`):**
|
||||
|
||||
```python
|
||||
"""
|
||||
@@ -45,7 +45,7 @@ description: 智能分析文本内容,生成交互式思维导图,帮助用户
|
||||
|
||||
通过在 `Action` 类内部定义一个 `Valves` Pydantic 模型,可以为插件创建可在 Web UI 中配置的参数。
|
||||
|
||||
**代码示例 (`思维导图.py`):**
|
||||
**代码示例 (`smart_mind_map_cn.py`):**
|
||||
|
||||
```python
|
||||
class Action:
|
||||
@@ -83,7 +83,7 @@ class Action:
|
||||
|
||||
`action` 方法是插件的执行入口,它是一个异步函数,接收 Open WebUI 传入的上下文信息。
|
||||
|
||||
**代码示例 (`思维导图.py`):**
|
||||
**代码示例 (`smart_mind_map_cn.py`):**
|
||||
|
||||
```python
|
||||
async def action(
|
||||
|
||||
@@ -73,13 +73,13 @@ hide:
|
||||
|
||||
[:octicons-arrow-right-24: Learn More](plugins/actions/smart-mind-map.md)
|
||||
|
||||
- :material-card-text:{ .lg .middle } **Knowledge Card**
|
||||
- :material-card-text:{ .lg .middle } **Flash Card**
|
||||
|
||||
---
|
||||
|
||||
Quickly generates beautiful learning memory cards, perfect for studying and quick memorization.
|
||||
Quickly generates beautiful flashcards from text, extracting key points and categories.
|
||||
|
||||
[:octicons-arrow-right-24: Learn More](plugins/actions/knowledge-card.md)
|
||||
[:octicons-arrow-right-24: Learn More](plugins/actions/flash-card.md)
|
||||
|
||||
- :material-arrow-collapse-vertical:{ .lg .middle } **Async Context Compression**
|
||||
|
||||
@@ -104,10 +104,16 @@ hide:
|
||||
|
||||
### Using Plugins
|
||||
|
||||
1. Browse the [Plugin Center](plugins/index.md) and download the plugin file (`.py`)
|
||||
2. Open OpenWebUI **Admin Panel** → **Settings** → **Plugins**
|
||||
3. Click the upload button and select the `.py` file
|
||||
4. Refresh the page and enable the plugin in your chat settings
|
||||
1. **Install from OpenWebUI Community (Recommended)**:
|
||||
- Visit my profile: [Fu-Jie's Profile](https://openwebui.com/u/Fu-Jie)
|
||||
- Browse the plugins and select the one you like.
|
||||
- Click "Get" to import it directly into your OpenWebUI instance.
|
||||
|
||||
2. **Manual Installation**:
|
||||
- Browse the [Plugin Center](plugins/index.md) and download the plugin file (`.py`)
|
||||
- Open OpenWebUI **Admin Panel** → **Settings** → **Plugins**
|
||||
- Click the upload button and select the `.py` file
|
||||
- Refresh the page and enable the plugin in your chat settings
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -73,13 +73,13 @@ hide:
|
||||
|
||||
[:octicons-arrow-right-24: 了解更多](plugins/actions/smart-mind-map.md)
|
||||
|
||||
- :material-card-text:{ .lg .middle } **知识卡片**
|
||||
- :material-card-text:{ .lg .middle } **Flash Card(闪记卡)**
|
||||
|
||||
---
|
||||
|
||||
快速生成精美的学习记忆卡片,非常适合学习和快速记忆。
|
||||
|
||||
[:octicons-arrow-right-24: 了解更多](plugins/actions/knowledge-card.md)
|
||||
[:octicons-arrow-right-24: 了解更多](plugins/actions/flash-card.md)
|
||||
|
||||
- :material-arrow-collapse-vertical:{ .lg .middle } **异步上下文压缩**
|
||||
|
||||
@@ -104,10 +104,16 @@ hide:
|
||||
|
||||
### 使用插件
|
||||
|
||||
1. 浏览[插件中心](plugins/index.md)并下载插件文件(`.py`)
|
||||
2. 打开 OpenWebUI **管理面板** → **设置** → **插件**
|
||||
3. 点击上传按钮并选择 `.py` 文件
|
||||
4. 刷新页面并在聊天设置中启用插件
|
||||
1. **从 OpenWebUI 社区安装 (推荐)**:
|
||||
- 访问我的主页: [Fu-Jie's Profile](https://openwebui.com/u/Fu-Jie)
|
||||
- 浏览插件列表,选择你喜欢的插件。
|
||||
- 点击 "Get" 按钮,将其直接导入到你的 OpenWebUI 实例中。
|
||||
|
||||
2. **手动安装**:
|
||||
- 浏览[插件中心](plugins/index.md)并下载插件文件(`.py`)
|
||||
- 打开 OpenWebUI **管理面板** → **设置** → **插件**
|
||||
- 点击上传按钮并选择 `.py` 文件
|
||||
- 刷新页面并在聊天设置中启用插件
|
||||
|
||||
---
|
||||
|
||||
|
||||
290
docs/js-visualization-guide.md
Normal file
290
docs/js-visualization-guide.md
Normal file
@@ -0,0 +1,290 @@
|
||||
# 使用 JavaScript 生成可视化内容的技术方案
|
||||
|
||||
## 概述
|
||||
|
||||
本文档描述了在 OpenWebUI Action 插件中使用浏览器端 JavaScript 代码生成可视化内容(如思维导图、信息图等)并将结果保存到消息中的技术方案。
|
||||
|
||||
## 核心架构
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Plugin as Python 插件
|
||||
participant EventCall as __event_call__
|
||||
participant Browser as 浏览器 (JS)
|
||||
participant API as OpenWebUI API
|
||||
participant DB as 数据库
|
||||
|
||||
Plugin->>EventCall: 1. 发送 execute 事件 (含 JS 代码)
|
||||
EventCall->>Browser: 2. 执行 JS 代码
|
||||
Browser->>Browser: 3. 加载可视化库 (D3/Markmap/AntV)
|
||||
Browser->>Browser: 4. 渲染可视化内容
|
||||
Browser->>Browser: 5. 转换为 Base64 Data URI
|
||||
Browser->>API: 6. GET 获取当前消息内容
|
||||
API-->>Browser: 7. 返回消息数据
|
||||
Browser->>API: 8. POST 追加 Markdown 图片到消息
|
||||
API->>DB: 9. 保存更新后的消息
|
||||
```
|
||||
|
||||
## 关键步骤
|
||||
|
||||
### 1. Python 端通过 `__event_call__` 执行 JS
|
||||
|
||||
Python 插件**不直接修改 `body["messages"]`**,而是通过 `__event_call__` 发送 JS 代码让浏览器执行:
|
||||
|
||||
```python
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: dict = None,
|
||||
__event_emitter__=None,
|
||||
__event_call__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
__metadata__: Optional[dict] = None,
|
||||
__request__: Request = None,
|
||||
) -> dict:
|
||||
# 从 body 获取 chat_id 和 message_id
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # 注意:body["id"] 是 message_id
|
||||
|
||||
# 通过 __event_call__ 执行 JS 代码
|
||||
if __event_call__:
|
||||
await __event_call__({
|
||||
"type": "execute",
|
||||
"data": {
|
||||
"code": f"""
|
||||
(async function() {{
|
||||
const chatId = "{chat_id}";
|
||||
const messageId = "{message_id}";
|
||||
// ... JS 渲染和 API 更新逻辑 ...
|
||||
}})();
|
||||
"""
|
||||
},
|
||||
})
|
||||
|
||||
# 不修改 body,直接返回
|
||||
return body
|
||||
```
|
||||
|
||||
### 2. JavaScript 加载可视化库
|
||||
|
||||
在浏览器端动态加载所需的 JS 库:
|
||||
|
||||
```javascript
|
||||
// 加载 D3.js
|
||||
if (!window.d3) {
|
||||
await new Promise((resolve, reject) => {
|
||||
const script = document.createElement('script');
|
||||
script.src = 'https://cdn.jsdelivr.net/npm/d3@7';
|
||||
script.onload = resolve;
|
||||
script.onerror = reject;
|
||||
document.head.appendChild(script);
|
||||
});
|
||||
}
|
||||
|
||||
// 加载 Markmap (思维导图)
|
||||
if (!window.markmap) {
|
||||
await loadScript('https://cdn.jsdelivr.net/npm/markmap-lib@0.17');
|
||||
await loadScript('https://cdn.jsdelivr.net/npm/markmap-view@0.17');
|
||||
}
|
||||
```
|
||||
|
||||
### 3. 渲染并转换为 Data URI
|
||||
|
||||
```javascript
|
||||
// 创建 SVG 元素
|
||||
const svg = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
|
||||
svg.setAttribute('width', '800');
|
||||
svg.setAttribute('height', '600');
|
||||
svg.setAttribute('xmlns', 'http://www.w3.org/2000/svg');
|
||||
|
||||
// ... 执行渲染逻辑 (添加图形元素) ...
|
||||
|
||||
// 转换为 Base64 Data URI
|
||||
const svgData = new XMLSerializer().serializeToString(svg);
|
||||
const base64 = btoa(unescape(encodeURIComponent(svgData)));
|
||||
const dataUri = 'data:image/svg+xml;base64,' + base64;
|
||||
```
|
||||
|
||||
### 4. 获取当前消息内容
|
||||
|
||||
由于 Python 端不传递原始内容,JS 需要通过 API 获取:
|
||||
|
||||
```javascript
|
||||
const token = localStorage.getItem('token');
|
||||
|
||||
// 获取当前聊天数据
|
||||
const getResponse = await fetch(`/api/v1/chats/${chatId}`, {
|
||||
method: 'GET',
|
||||
headers: {
|
||||
'Authorization': `Bearer ${token}`
|
||||
}
|
||||
});
|
||||
|
||||
const chatData = await getResponse.json();
|
||||
|
||||
// 查找目标消息
|
||||
let originalContent = '';
|
||||
if (chatData.chat && chatData.chat.messages) {
|
||||
const targetMsg = chatData.chat.messages.find(m => m.id === messageId);
|
||||
if (targetMsg && targetMsg.content) {
|
||||
originalContent = targetMsg.content;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5. 调用 API 更新消息
|
||||
|
||||
```javascript
|
||||
// 构造新内容:原始内容 + Markdown 图片
|
||||
const markdownImage = ``;
|
||||
const newContent = originalContent + '\n\n' + markdownImage;
|
||||
|
||||
// 调用 API 更新消息
|
||||
const response = await fetch(`/api/v1/chats/${chatId}/messages/${messageId}/event`, {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
'Authorization': `Bearer ${token}`
|
||||
},
|
||||
body: JSON.stringify({
|
||||
type: 'chat:message',
|
||||
data: { content: newContent }
|
||||
})
|
||||
});
|
||||
|
||||
if (response.ok) {
|
||||
console.log('消息更新成功!');
|
||||
}
|
||||
```
|
||||
|
||||
## 完整示例
|
||||
|
||||
参考 [js_render_poc.py](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/actions/js-render-poc/js_render_poc.py) 获取完整的 PoC 实现。
|
||||
|
||||
## 事件类型
|
||||
|
||||
| 类型 | 用途 |
|
||||
|------|------|
|
||||
| `chat:message:delta` | 增量更新(追加文本) |
|
||||
| `chat:message` | 完全替换消息内容 |
|
||||
|
||||
```javascript
|
||||
// 增量更新
|
||||
{ type: "chat:message:delta", data: { content: "追加的内容" } }
|
||||
|
||||
// 完全替换
|
||||
{ type: "chat:message", data: { content: "完整的新内容" } }
|
||||
```
|
||||
|
||||
## 关键数据来源
|
||||
|
||||
| 数据 | 来源 | 说明 |
|
||||
|------|------|------|
|
||||
| `chat_id` | `body["chat_id"]` | 聊天会话 ID |
|
||||
| `message_id` | `body["id"]` | ⚠️ 注意:是 `body["id"]`,不是 `body["message_id"]` |
|
||||
| `token` | `localStorage.getItem('token')` | 用户认证 Token |
|
||||
| `originalContent` | 通过 API `GET /api/v1/chats/{chatId}` 获取 | 当前消息内容 |
|
||||
|
||||
## Python 端 API
|
||||
|
||||
| 参数 | 类型 | 说明 |
|
||||
|------|------|------|
|
||||
| `__event_emitter__` | Callable | 发送状态/通知事件 |
|
||||
| `__event_call__` | Callable | 执行 JS 代码(用于可视化渲染) |
|
||||
| `__metadata__` | dict | 元数据(可能为 None) |
|
||||
| `body` | dict | 请求体,包含 messages、chat_id、id 等 |
|
||||
|
||||
### body 结构示例
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "gemini-3-flash-preview",
|
||||
"messages": [...],
|
||||
"chat_id": "ac2633a3-5731-4944-98e3-bf9b3f0ef0ab",
|
||||
"id": "2e0bb7d4-dfc0-43d7-b028-fd9e06c6fdc8",
|
||||
"session_id": "bX30sHI8r4_CKxCdAAAL"
|
||||
}
|
||||
```
|
||||
|
||||
### 常用事件
|
||||
|
||||
```python
|
||||
# 发送状态更新
|
||||
await __event_emitter__({
|
||||
"type": "status",
|
||||
"data": {"description": "正在渲染...", "done": False}
|
||||
})
|
||||
|
||||
# 执行 JS 代码
|
||||
await __event_call__({
|
||||
"type": "execute",
|
||||
"data": {"code": "console.log('Hello from Python!')"}
|
||||
})
|
||||
|
||||
# 发送通知
|
||||
await __event_emitter__({
|
||||
"type": "notification",
|
||||
"data": {"type": "success", "content": "渲染完成!"}
|
||||
})
|
||||
```
|
||||
|
||||
## 适用场景
|
||||
|
||||
- **思维导图** (Markmap)
|
||||
- **信息图** (AntV Infographic)
|
||||
- **流程图** (Mermaid)
|
||||
- **数据图表** (ECharts, Chart.js)
|
||||
- **任何需要 JS 渲染的可视化内容**
|
||||
|
||||
## 注意事项
|
||||
|
||||
### 1. 竞态条件问题
|
||||
|
||||
⚠️ **多次快速点击会导致内容覆盖问题**
|
||||
|
||||
由于 API 调用是异步的,如果用户快速多次触发 Action:
|
||||
- 第一次点击:获取原始内容 A → 渲染 → 更新为 A+图片1
|
||||
- 第二次点击:可能获取到旧内容 A(第一次还没保存完)→ 更新为 A+图片2
|
||||
|
||||
结果:图片1 被覆盖丢失!
|
||||
|
||||
**解决方案**:
|
||||
- 添加防抖(debounce)机制
|
||||
- 使用锁/标志位防止重复执行
|
||||
- 或使用 `chat:message:delta` 增量更新
|
||||
|
||||
### 2. 不要直接修改 `body["messages"]`
|
||||
|
||||
消息更新应由 JS 通过 API 完成,确保获取最新内容。
|
||||
|
||||
### 3. f-string 限制
|
||||
|
||||
Python f-string 内不能直接使用反斜杠,需要将转义字符串预先处理:
|
||||
|
||||
```python
|
||||
# 转义 JSON 中的特殊字符
|
||||
body_json = json.dumps(data, ensure_ascii=False)
|
||||
escaped = body_json.replace("\\", "\\\\").replace("`", "\\`").replace("${", "\\${")
|
||||
```
|
||||
|
||||
### 4. Data URI 大小限制
|
||||
|
||||
Base64 编码会增加约 33% 的体积,复杂图片可能导致消息过大。
|
||||
|
||||
### 5. 跨域问题
|
||||
|
||||
确保 CDN 资源支持 CORS。
|
||||
|
||||
### 6. API 权限
|
||||
|
||||
确保用户 token 有权限访问和更新目标消息。
|
||||
|
||||
## 与传统方式对比
|
||||
|
||||
| 特性 | 传统方式 (修改 body) | 新方式 (__event_call__) |
|
||||
|------|---------------------|------------------------|
|
||||
| 消息更新 | Python 直接修改 | JS 通过 API 更新 |
|
||||
| 原始内容 | Python 传递给 JS | JS 通过 API 获取 |
|
||||
| 灵活性 | 低 | 高 |
|
||||
| 实时性 | 一次性 | 可多次更新 |
|
||||
| 复杂度 | 简单 | 中等 |
|
||||
| 竞态风险 | 低 | ⚠️ 需要处理 |
|
||||
111
docs/plugins/actions/deep-dive.md
Normal file
111
docs/plugins/actions/deep-dive.md
Normal file
@@ -0,0 +1,111 @@
|
||||
# Deep Dive
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
|
||||
A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Deep Dive plugin transforms how you understand complex content by guiding you through a structured thinking process. Rather than just summarizing, it deconstructs content across four phases:
|
||||
|
||||
- **🔍 The Context (What?)**: Panoramic view of the situation and background
|
||||
- **🧠 The Logic (Why?)**: Deconstruction of reasoning and mental models
|
||||
- **💎 The Insight (So What?)**: Non-obvious value and hidden implications
|
||||
- **🚀 The Path (Now What?)**: Specific, prioritized strategic actions
|
||||
|
||||
## Features
|
||||
|
||||
- :material-brain: **Thinking Chain**: Complete structured analysis process
|
||||
- :material-eye: **Deep Understanding**: Reveals hidden assumptions and blind spots
|
||||
- :material-lightbulb-on: **Insight Extraction**: Finds the "Aha!" moments
|
||||
- :material-rocket-launch: **Action Oriented**: Translates understanding into actionable steps
|
||||
- :material-theme-light-dark: **Theme Adaptive**: Auto-adapts to OpenWebUI light/dark theme
|
||||
- :material-translate: **Multi-language**: Outputs in user's preferred language
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`deep_dive.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/deep-dive)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Enable the plugin
|
||||
|
||||
---
|
||||
|
||||
## Usage
|
||||
|
||||
1. Provide any long text, article, or meeting notes in the chat
|
||||
2. Click the **Deep Dive** button in the message action bar
|
||||
3. Follow the visual timeline from Context → Logic → Insight → Path
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `SHOW_STATUS` | boolean | `true` | Show status updates during processing |
|
||||
| `MODEL_ID` | string | `""` | LLM model for analysis (empty = current model) |
|
||||
| `MIN_TEXT_LENGTH` | integer | `200` | Minimum text length for analysis |
|
||||
| `CLEAR_PREVIOUS_HTML` | boolean | `true` | Clear previous plugin results |
|
||||
| `MESSAGE_COUNT` | integer | `1` | Number of recent messages to analyze |
|
||||
|
||||
---
|
||||
|
||||
## Theme Support
|
||||
|
||||
Deep Dive automatically adapts to OpenWebUI's light/dark theme:
|
||||
|
||||
- Detects theme from parent document `<meta name="theme-color">` tag
|
||||
- Falls back to `html/body` class or `data-theme` attribute
|
||||
- Uses system preference `prefers-color-scheme: dark` as last resort
|
||||
|
||||
!!! tip "For Best Results"
|
||||
Enable **iframe Sandbox Allow Same Origin** in OpenWebUI:
|
||||
**Settings** → **Interface** → **Artifacts** → Check **iframe Sandbox Allow Same Origin**
|
||||
|
||||
---
|
||||
|
||||
## Example Output
|
||||
|
||||
The plugin generates a beautiful structured timeline:
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────┐
|
||||
│ 🌊 Deep Dive Analysis │
|
||||
│ 👤 User 📅 Date 📊 Word count │
|
||||
├─────────────────────────────────────┤
|
||||
│ 🔍 Phase 01: The Context │
|
||||
│ [High-level panoramic view] │
|
||||
│ │
|
||||
│ 🧠 Phase 02: The Logic │
|
||||
│ • Reasoning structure... │
|
||||
│ • Hidden assumptions... │
|
||||
│ │
|
||||
│ 💎 Phase 03: The Insight │
|
||||
│ • Non-obvious value... │
|
||||
│ • Blind spots revealed... │
|
||||
│ │
|
||||
│ 🚀 Phase 04: The Path │
|
||||
│ ▸ Priority Action 1... │
|
||||
│ ▸ Priority Action 2... │
|
||||
└─────────────────────────────────────┘
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Requirements
|
||||
|
||||
!!! note "Prerequisites"
|
||||
- OpenWebUI v0.3.0 or later
|
||||
- Uses the active LLM model for analysis
|
||||
- Requires `markdown` Python package
|
||||
|
||||
---
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/deep-dive){ .md-button }
|
||||
111
docs/plugins/actions/deep-dive.zh.md
Normal file
111
docs/plugins/actions/deep-dive.zh.md
Normal file
@@ -0,0 +1,111 @@
|
||||
# 精读 (Deep Dive)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
|
||||
全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。
|
||||
|
||||
---
|
||||
|
||||
## 概述
|
||||
|
||||
精读插件改变了您理解复杂内容的方式,通过结构化的思维过程引导您进行深度分析。它不仅仅是摘要,而是从四个阶段解构内容:
|
||||
|
||||
- **🔍 全景 (The Context)**: 情境与背景的高层级全景视图
|
||||
- **🧠 脉络 (The Logic)**: 解构底层推理逻辑与思维模型
|
||||
- **💎 洞察 (The Insight)**: 提取非显性价值与隐藏含义
|
||||
- **🚀 路径 (The Path)**: 具体的、按优先级排列的战略行动
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-brain: **思维链**: 完整的结构化分析过程
|
||||
- :material-eye: **深度理解**: 揭示隐藏的假设和思维盲点
|
||||
- :material-lightbulb-on: **洞察提取**: 发现"原来如此"的时刻
|
||||
- :material-rocket-launch: **行动导向**: 将深度理解转化为可执行步骤
|
||||
- :material-theme-light-dark: **主题自适应**: 自动适配 OpenWebUI 深色/浅色主题
|
||||
- :material-translate: **多语言**: 以用户偏好语言输出
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件: [`deep_dive_cn.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/deep-dive)
|
||||
2. 上传到 OpenWebUI: **管理面板** → **设置** → **Functions**
|
||||
3. 启用插件
|
||||
|
||||
---
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在聊天中提供任何长文本、文章或会议记录
|
||||
2. 点击消息操作栏中的 **精读** 按钮
|
||||
3. 沿着视觉时间轴从"全景"探索到"路径"
|
||||
|
||||
---
|
||||
|
||||
## 配置参数
|
||||
|
||||
| 选项 | 类型 | 默认值 | 描述 |
|
||||
|------|------|--------|------|
|
||||
| `SHOW_STATUS` | boolean | `true` | 处理过程中是否显示状态更新 |
|
||||
| `MODEL_ID` | string | `""` | 用于分析的 LLM 模型(空 = 当前模型) |
|
||||
| `MIN_TEXT_LENGTH` | integer | `200` | 分析所需的最小文本长度 |
|
||||
| `CLEAR_PREVIOUS_HTML` | boolean | `true` | 是否清除之前的插件结果 |
|
||||
| `MESSAGE_COUNT` | integer | `1` | 要分析的最近消息数量 |
|
||||
|
||||
---
|
||||
|
||||
## 主题支持
|
||||
|
||||
精读插件自动适配 OpenWebUI 的深色/浅色主题:
|
||||
|
||||
- 从父文档 `<meta name="theme-color">` 标签检测主题
|
||||
- 回退到 `html/body` 的 class 或 `data-theme` 属性
|
||||
- 最后使用系统偏好 `prefers-color-scheme: dark`
|
||||
|
||||
!!! tip "最佳效果"
|
||||
请在 OpenWebUI 中启用 **iframe Sandbox Allow Same Origin**:
|
||||
**设置** → **界面** → **Artifacts** → 勾选 **iframe Sandbox Allow Same Origin**
|
||||
|
||||
---
|
||||
|
||||
## 输出示例
|
||||
|
||||
插件生成精美的结构化时间轴:
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────┐
|
||||
│ 📖 精读分析报告 │
|
||||
│ 👤 用户 📅 日期 📊 字数 │
|
||||
├─────────────────────────────────────┤
|
||||
│ 🔍 阶段 01: 全景 (The Context) │
|
||||
│ [高层级全景视图内容] │
|
||||
│ │
|
||||
│ 🧠 阶段 02: 脉络 (The Logic) │
|
||||
│ • 推理结构分析... │
|
||||
│ • 隐藏假设识别... │
|
||||
│ │
|
||||
│ 💎 阶段 03: 洞察 (The Insight) │
|
||||
│ • 非显性价值提取... │
|
||||
│ • 思维盲点揭示... │
|
||||
│ │
|
||||
│ 🚀 阶段 04: 路径 (The Path) │
|
||||
│ ▸ 优先级行动 1... │
|
||||
│ ▸ 优先级行动 2... │
|
||||
└─────────────────────────────────────┘
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 系统要求
|
||||
|
||||
!!! note "前提条件"
|
||||
- OpenWebUI v0.3.0 或更高版本
|
||||
- 使用当前活跃的 LLM 模型进行分析
|
||||
- 需要 `markdown` Python 包
|
||||
|
||||
---
|
||||
|
||||
## 源代码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 上查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/deep-dive){ .md-button }
|
||||
@@ -1,12 +1,25 @@
|
||||
# Export to Excel
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.3.3</span>
|
||||
<span class="version-badge">v0.3.7</span>
|
||||
|
||||
Export chat conversations to Excel spreadsheet format for analysis, archiving, and sharing.
|
||||
|
||||
|
||||
### What's New in v0.3.6
|
||||
- **OpenWebUI-Style Theme**: Modern dark header with light gray zebra striping for better readability.
|
||||
- **Zebra Striping**: Alternating row colors for improved visual scanning.
|
||||
- **Smart Data Type Conversion**: Automatically converts columns to numeric or datetime types.
|
||||
- **Full Cell Bold/Italic**: Supports Markdown bold/italic formatting in Excel.
|
||||
- **Partial Markdown Cleanup**: Removes partial Markdown symbols for cleaner output.
|
||||
- **Export Scope**: Choose between "Last Message" or "All Messages".
|
||||
- **Smart Sheet Naming**: Names sheets based on Markdown headers or message index.
|
||||
- **Smart Filename Generation**: Generates filenames based on Chat Title, AI Summary, or Markdown Headers.
|
||||
- **AI Title Generation**: Supports using a specific model (`MODEL_ID`) for title generation with progress notifications.
|
||||
|
||||
---
|
||||
|
||||
|
||||
## Overview
|
||||
|
||||
The Export to Excel plugin allows you to download your chat conversations as Excel files. This is useful for:
|
||||
@@ -23,6 +36,13 @@ The Export to Excel plugin allows you to download your chat conversations as Exc
|
||||
- :material-download: **One-Click Download**: Instant file generation
|
||||
- :material-history: **Full History**: Exports complete conversation
|
||||
|
||||
## Configuration
|
||||
|
||||
- **Title Source**: Choose how the filename is generated:
|
||||
- `chat_title`: Use the chat title (default).
|
||||
- `ai_generated`: Use AI to generate a concise title from the content.
|
||||
- `markdown_title`: Extract the first H1/H2 header from the markdown content.
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
@@ -1,12 +1,25 @@
|
||||
# Export to Excel(导出到 Excel)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
<span class="version-badge">v0.3.7</span>
|
||||
|
||||
将聊天记录导出为 Excel 表格,便于分析、归档和分享。
|
||||
|
||||
|
||||
### v0.3.6 更新内容
|
||||
- **OpenWebUI 风格主题**:现代深灰表头,搭配浅灰斑马纹,提升可读性。
|
||||
- **斑马纹效果**:隔行变色,方便视觉扫描。
|
||||
- **智能数据类型转换**:自动将列转换为数字或日期类型。
|
||||
- **全单元格粗体/斜体**:支持 Markdown 粗体/斜体格式。
|
||||
- **部分 Markdown 清理**:移除部分 Markdown 符号,输出更整洁。
|
||||
- **导出范围**:可选择导出"最后一条消息"或"所有消息"。
|
||||
- **智能 Sheet 命名**:根据 Markdown 标题或消息索引命名 Sheet。
|
||||
- **智能文件名生成**:支持对话标题、AI 总结或 Markdown 标题生成文件名。
|
||||
- **AI 标题生成**:支持指定模型 (`MODEL_ID`) 生成标题,并提供生成进度通知。
|
||||
|
||||
---
|
||||
|
||||
|
||||
## 概览
|
||||
|
||||
Export to Excel 插件可以把你的聊天记录下载为 Excel 文件,适用于:
|
||||
@@ -23,6 +36,13 @@ Export to Excel 插件可以把你的聊天记录下载为 Excel 文件,适用
|
||||
- :material-download: **一键下载**:即时生成文件
|
||||
- :material-history: **完整历史**:导出完整会话内容
|
||||
|
||||
## 配置
|
||||
|
||||
- **标题来源 (Title Source)**:选择文件名的生成方式:
|
||||
- `chat_title`:使用对话标题(默认)。
|
||||
- `ai_generated`:使用 AI 根据内容生成简洁标题。
|
||||
- `markdown_title`:提取 Markdown 内容中的第一个 H1/H2 标题。
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Export to Word
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
<span class="version-badge">v0.4.3</span>
|
||||
|
||||
Export chat conversations to Word (.docx) with Markdown formatting, syntax highlighting, and smarter filenames.
|
||||
Export conversation to Word (.docx) with **syntax highlighting**, **native math equations**, **Mermaid diagrams**, **citations**, and **enhanced table formatting**.
|
||||
|
||||
---
|
||||
|
||||
@@ -13,11 +13,17 @@ The Export to Word plugin converts chat messages from Markdown to a polished Wor
|
||||
|
||||
## Features
|
||||
|
||||
- :material-file-word-box: **DOCX Export**: Generate Word files with one click
|
||||
- :material-format-bold: **Rich Markdown Support**: Headings, bold/italic, lists, tables
|
||||
- :material-code-tags: **Syntax Highlighting**: Pygments-powered code blocks
|
||||
- :material-format-quote-close: **Styled Blockquotes**: Left-border gray quote styling
|
||||
- :material-file-document-outline: **Smart Filenames**: Configurable title source (Chat Title, AI Generated, or Markdown Title)
|
||||
- :material-file-word-box: **One-Click Export**: Adds an "Export to Word" action button to the chat.
|
||||
- :material-format-bold: **Markdown Conversion**: Converts Markdown syntax to Word formatting (headings, bold, italic, code, tables, lists).
|
||||
- :material-code-tags: **Syntax Highlighting**: Code blocks are highlighted with Pygments (supports 500+ languages).
|
||||
- :material-sigma: **Native Math Equations**: LaTeX math (`$$...$$`, `\[...\]`, `$...$`, `\(...\)`) converted to editable Word equations.
|
||||
- :material-graph: **Mermaid Diagrams**: Mermaid flowcharts and sequence diagrams rendered as images in the document.
|
||||
- :material-book-open-page-variant: **Citations & References**: Auto-generates a References section from OpenWebUI sources with clickable citation links.
|
||||
- :material-brain-off: **Reasoning Stripping**: Automatically removes AI thinking blocks (`<think>`, `<analysis>`) from exports.
|
||||
- :material-table: **Enhanced Tables**: Smart column widths, column alignment (`:---`, `---:`, `:---:`), header row repeat across pages.
|
||||
- :material-format-quote-close: **Blockquote Support**: Markdown blockquotes are rendered with left border and gray styling.
|
||||
- :material-translate: **Multi-language Support**: Properly handles both Chinese and English text.
|
||||
- :material-file-document-outline: **Smarter Filenames**: Configurable title source (Chat Title, AI Generated, or Markdown Title).
|
||||
|
||||
---
|
||||
|
||||
@@ -25,9 +31,39 @@ The Export to Word plugin converts chat messages from Markdown to a polished Wor
|
||||
|
||||
You can configure the following settings via the **Valves** button in the plugin settings:
|
||||
|
||||
| Valve | Description | Default |
|
||||
| :------------- | :------------------------------------------------------------------------------------------ | :----------- |
|
||||
| Valve | Description | Default |
|
||||
| :--- | :--- | :--- |
|
||||
| `TITLE_SOURCE` | Source for document title/filename. Options: `chat_title`, `ai_generated`, `markdown_title` | `chat_title` |
|
||||
| `MAX_EMBED_IMAGE_MB` | Maximum image size to embed into DOCX (MB). | `20` |
|
||||
| `UI_LANGUAGE` | User interface language. Options: `en` (English), `zh` (Chinese). | `en` |
|
||||
| `FONT_LATIN` | Font name for Latin characters. | `Times New Roman` |
|
||||
| `FONT_ASIAN` | Font name for Asian characters. | `SimSun` |
|
||||
| `FONT_CODE` | Font name for code blocks. | `Consolas` |
|
||||
| `TABLE_HEADER_COLOR` | Table header background color (Hex without #). | `F2F2F2` |
|
||||
| `TABLE_ZEBRA_COLOR` | Table alternating row background color (Hex without #). | `FBFBFB` |
|
||||
| `MERMAID_JS_URL` | URL for the Mermaid.js library. | `https://cdn.jsdelivr.net/npm/mermaid@11.12.2/dist/mermaid.min.js` |
|
||||
| `MERMAID_JSZIP_URL` | URL for the JSZip library (required for DOCX manipulation). | `https://cdnjs.cloudflare.com/ajax/libs/jszip/3.10.1/jszip.min.js` |
|
||||
| `MERMAID_PNG_SCALE` | Scale factor for Mermaid PNG generation (Resolution). | `3.0` |
|
||||
| `MERMAID_DISPLAY_SCALE` | Scale factor for Mermaid visual size in Word. | `1.0` |
|
||||
| `MERMAID_OPTIMIZE_LAYOUT` | Automatically convert LR (Left-Right) flowcharts to TD (Top-Down). | `False` |
|
||||
| `MERMAID_BACKGROUND` | Background color for Mermaid diagrams (e.g., `white`, `transparent`). | `transparent` |
|
||||
| `MERMAID_CAPTIONS_ENABLE` | Enable/disable figure captions for Mermaid diagrams. | `True` |
|
||||
| `MERMAID_CAPTION_STYLE` | Paragraph style name for Mermaid captions. | `Caption` |
|
||||
| `MERMAID_CAPTION_PREFIX` | Caption prefix label (e.g., 'Figure'). Empty = auto-detect based on language. | `""` |
|
||||
| `MATH_ENABLE` | Enable LaTeX math block conversion. | `True` |
|
||||
| `MATH_INLINE_DOLLAR_ENABLE` | Enable inline `$ ... $` math conversion. | `True` |
|
||||
|
||||
## 🔥 What's New in v0.4.3
|
||||
|
||||
### User-Level Configuration (UserValves)
|
||||
|
||||
Users can override the following settings in their personal settings:
|
||||
- `TITLE_SOURCE`
|
||||
- `UI_LANGUAGE`
|
||||
- `FONT_LATIN`, `FONT_ASIAN`, `FONT_CODE`
|
||||
- `TABLE_HEADER_COLOR`, `TABLE_ZEBRA_COLOR`
|
||||
- `MERMAID_...` (Selected Mermaid settings)
|
||||
- `MATH_...` (Math settings)
|
||||
|
||||
---
|
||||
|
||||
@@ -47,34 +83,41 @@ You can configure the following settings via the **Valves** button in the plugin
|
||||
|
||||
---
|
||||
|
||||
## Supported Markdown
|
||||
## Supported Markdown Syntax
|
||||
|
||||
| Syntax | Word Result |
|
||||
| :---------------------------------- | :----------------------------- |
|
||||
| `# Heading 1` to `###### Heading 6` | Heading levels 1-6 |
|
||||
| `**bold**` / `__bold__` | Bold text |
|
||||
| `*italic*` / `_italic_` | Italic text |
|
||||
| `***bold italic***` | Bold + Italic |
|
||||
| `` `inline code` `` | Monospace with gray background |
|
||||
| <code>``` code block ```</code> | Syntax-highlighted code block |
|
||||
| `> blockquote` | Left-bordered gray italic text |
|
||||
| `[link](url)` | Blue underlined link |
|
||||
| `~~strikethrough~~` | Strikethrough |
|
||||
| `- item` / `* item` | Bullet list |
|
||||
| `1. item` | Numbered list |
|
||||
| Markdown tables | Grid table |
|
||||
| `---` / `***` | Horizontal rule |
|
||||
| Syntax | Word Result |
|
||||
| :--- | :--- |
|
||||
| `# Heading 1` to `###### Heading 6` | Heading levels 1-6 |
|
||||
| `**bold**` or `__bold__` | Bold text |
|
||||
| `*italic*` or `_italic_` | Italic text |
|
||||
| `***bold italic***` | Bold + Italic |
|
||||
| `` `inline code` `` | Monospace with gray background |
|
||||
| ` ``` code block ``` ` | **Syntax highlighted** code block |
|
||||
| `> blockquote` | Left-bordered gray italic text |
|
||||
| `[link](url)` | Blue underlined link text |
|
||||
| `~~strikethrough~~` | Strikethrough text |
|
||||
| `- item` or `* item` | Bullet list |
|
||||
| `1. item` | Numbered list |
|
||||
| Markdown tables | **Enhanced table** with smart widths |
|
||||
| `---` or `***` | Horizontal rule |
|
||||
| `$$LaTeX$$` or `\[LaTeX\]` | **Native Word equation** (display) |
|
||||
| `$LaTeX$` or `\(LaTeX\)` | **Native Word equation** (inline) |
|
||||
| ` ```mermaid ... ``` ` | **Mermaid diagram** as image |
|
||||
| `[1]` citation markers | **Clickable links** to References |
|
||||
|
||||
---
|
||||
|
||||
## Requirements
|
||||
|
||||
!!! note "Prerequisites"
|
||||
- `python-docx==1.1.2` (document generation)
|
||||
- `Pygments>=2.15.0` (syntax highlighting, optional but recommended)
|
||||
- `python-docx==1.1.2` - Word document generation
|
||||
- `Pygments>=2.15.0` - Syntax highlighting
|
||||
- `latex2mathml` - LaTeX to MathML conversion
|
||||
- `mathml2omml` - MathML to Office Math (OMML) conversion
|
||||
|
||||
---
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/export_to_docx){ .md-button }
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie) | **Version:** 0.4.3 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Export to Word(导出为 Word)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
<span class="version-badge">v0.4.3</span>
|
||||
|
||||
将聊天记录按 Markdown 格式导出为 Word (.docx),支持语法高亮、引用样式和更智能的文件命名。
|
||||
将当前对话导出为完美格式的 Word 文档,支持**代码语法高亮**、**原生数学公式**、**Mermaid 图表**、**引用资料**以及**增强表格**渲染。
|
||||
|
||||
---
|
||||
|
||||
@@ -13,11 +13,17 @@ Export to Word 插件会把聊天消息从 Markdown 转成精致的 Word 文档
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-file-word-box: **DOCX 导出**:一键生成 Word 文件
|
||||
- :material-format-bold: **丰富 Markdown 支持**:标题、粗斜体、列表、表格
|
||||
- :material-code-tags: **语法高亮**:Pygments 驱动的代码块上色
|
||||
- :material-format-quote-close: **引用样式**:左侧边框的灰色斜体引用
|
||||
- :material-file-document-outline: **智能文件名**:可配置标题来源(对话标题、AI 生成或 Markdown 标题)
|
||||
- :material-file-word-box: **一键导出**:在聊天界面添加"导出为 Word"动作按钮。
|
||||
- :material-format-bold: **Markdown 转换**:将 Markdown 语法转换为 Word 格式(标题、粗体、斜体、代码、表格、列表)。
|
||||
- :material-code-tags: **代码语法高亮**:使用 Pygments 库为代码块添加语法高亮(支持 500+ 种语言)。
|
||||
- :material-sigma: **原生数学公式**:LaTeX 公式(`$$...$$`、`\[...\]`、`$...$`、`\(...\)`)转换为可编辑的 Word 公式。
|
||||
- :material-graph: **Mermaid 图表**:Mermaid 流程图和时序图渲染为文档中的图片。
|
||||
- :material-book-open-page-variant: **引用与参考**:自动从 OpenWebUI 来源生成参考资料章节,支持可点击的引用链接。
|
||||
- :material-brain-off: **移除思考过程**:自动移除 AI 思考块(`<think>`、`<analysis>`)。
|
||||
- :material-table: **增强表格**:智能列宽、列对齐(`:---`、`---:`、`:---:`)、表头跨页重复。
|
||||
- :material-format-quote-close: **引用块支持**:Markdown 引用块渲染为带左侧边框的灰色斜体样式。
|
||||
- :material-translate: **多语言支持**:正确处理中文和英文文本,无乱码问题。
|
||||
- :material-file-document-outline: **智能文件名**:可配置标题来源(对话标题、AI 生成或 Markdown 标题)。
|
||||
|
||||
---
|
||||
|
||||
@@ -25,9 +31,37 @@ Export to Word 插件会把聊天消息从 Markdown 转成精致的 Word 文档
|
||||
|
||||
您可以通过插件设置中的 **Valves** 按钮配置以下选项:
|
||||
|
||||
| Valve | 说明 | 默认值 |
|
||||
| :------------- | :--------------------------------------------------------------------------------------------------------------- | :----------- |
|
||||
| `TITLE_SOURCE` | 文档标题/文件名的来源。选项:`chat_title` (对话标题), `ai_generated` (AI 生成), `markdown_title` (Markdown 标题) | `chat_title` |
|
||||
| Valve | 说明 | 默认值 |
|
||||
| :--- | :--- | :--- |
|
||||
| `文档标题来源` | 文档标题/文件名的来源。选项:`chat_title` (对话标题), `ai_generated` (AI 生成), `markdown_title` (Markdown 标题) | `chat_title` |
|
||||
| `最大嵌入图片大小MB` | 嵌入图片的最大大小 (MB)。 | `20` |
|
||||
| `界面语言` | 界面语言。选项:`en` (英语), `zh` (中文)。 | `zh` |
|
||||
| `英文字体` | 英文字体名称。 | `Calibri` |
|
||||
| `中文字体` | 中文字体名称。 | `SimSun` |
|
||||
| `代码字体` | 代码字体名称。 | `Consolas` |
|
||||
| `表头背景色` | 表头背景色(十六进制,不带#)。 | `F2F2F2` |
|
||||
| `表格隔行背景色` | 表格隔行背景色(十六进制,不带#)。 | `FBFBFB` |
|
||||
| `Mermaid_JS地址` | Mermaid.js 库的 URL。 | `https://cdn.jsdelivr.net/npm/mermaid@11.12.2/dist/mermaid.min.js` |
|
||||
| `JSZip库地址` | JSZip 库的 URL(用于 DOCX 操作)。 | `https://cdnjs.cloudflare.com/ajax/libs/jszip/3.10.1/jszip.min.js` |
|
||||
| `Mermaid_PNG缩放比例` | Mermaid PNG 生成缩放比例(分辨率)。 | `3.0` |
|
||||
| `Mermaid显示比例` | Mermaid 在 Word 中的显示比例(视觉大小)。 | `1.0` |
|
||||
| `Mermaid布局优化` | 优化 Mermaid 布局: 自动将 LR (左右) 转换为 TD (上下)。 | `False` |
|
||||
| `Mermaid背景色` | Mermaid 图表背景色(如 `white`, `transparent`)。 | `transparent` |
|
||||
| `启用Mermaid图注` | 启用/禁用 Mermaid 图表的图注。 | `True` |
|
||||
| `Mermaid图注样式` | Mermaid 图注的段落样式名称。 | `Caption` |
|
||||
| `Mermaid图注前缀` | 图注前缀(如 '图')。留空则根据语言自动检测。 | `""` |
|
||||
| `启用数学公式` | 启用 LaTeX 数学公式块转换。 | `True` |
|
||||
| `启用行内公式` | 启用行内 `$ ... $` 数学公式转换。 | `True` |
|
||||
|
||||
### 用户级配置 (UserValves)
|
||||
|
||||
用户可以在个人设置中覆盖以下配置:
|
||||
- `文档标题来源`
|
||||
- `界面语言`
|
||||
- `英文字体`, `中文字体`, `代码字体`
|
||||
- `表头背景色`, `表格隔行背景色`
|
||||
- `Mermaid_...` (部分 Mermaid 设置)
|
||||
- `启用数学公式`, `启用行内公式`
|
||||
|
||||
---
|
||||
|
||||
@@ -47,23 +81,27 @@ Export to Word 插件会把聊天消息从 Markdown 转成精致的 Word 文档
|
||||
|
||||
---
|
||||
|
||||
## 支持的 Markdown
|
||||
## 支持的 Markdown 语法
|
||||
|
||||
| 语法 | Word 效果 |
|
||||
| :-------------------------- | :------------------ |
|
||||
| `# 标题1` 到 `###### 标题6` | 标题级别 1-6 |
|
||||
| `**粗体**` / `__粗体__` | 粗体文本 |
|
||||
| `*斜体*` / `_斜体_` | 斜体文本 |
|
||||
| `***粗斜体***` | 粗体 + 斜体 |
|
||||
| `` `行内代码` `` | 等宽字体 + 灰色背景 |
|
||||
| <code>``` 代码块 ```</code> | 语法高亮代码块 |
|
||||
| `> 引用文本` | 左侧边框的灰色斜体 |
|
||||
| `[链接](url)` | 蓝色下划线链接 |
|
||||
| `~~删除线~~` | 删除线 |
|
||||
| `- 项目` / `* 项目` | 无序列表 |
|
||||
| `1. 项目` | 有序列表 |
|
||||
| Markdown 表格 | 带边框表格 |
|
||||
| `---` / `***` | 水平分割线 |
|
||||
| 语法 | Word 效果 |
|
||||
| :--- | :--- |
|
||||
| `# 标题1` 到 `###### 标题6` | 标题级别 1-6 |
|
||||
| `**粗体**` / `__粗体__` | 粗体文本 |
|
||||
| `*斜体*` / `_斜体_` | 斜体文本 |
|
||||
| `***粗斜体***` | 粗体 + 斜体 |
|
||||
| `` `行内代码` `` | 等宽字体 + 灰色背景 |
|
||||
| <code>``` 代码块 ```</code> | 语法高亮代码块 |
|
||||
| `> 引用文本` | 左侧边框的灰色斜体 |
|
||||
| `[链接](url)` | 蓝色下划线链接 |
|
||||
| `~~删除线~~` | 删除线 |
|
||||
| `- 项目` / `* 项目` | 无序列表 |
|
||||
| `1. 项目` | 有序列表 |
|
||||
| Markdown 表格 | **增强表格**(智能列宽) |
|
||||
| `---` / `***` | 水平分割线 |
|
||||
| `$$LaTeX$$` 或 `\[LaTeX\]` | **原生 Word 公式**(块级) |
|
||||
| `$LaTeX$` 或 `\(LaTeX\)` | **原生 Word 公式**(行内) |
|
||||
| ` ```mermaid ... ``` ` | **Mermaid 图表**(图片形式) |
|
||||
| `[1]` 引用标记 | **可点击链接**到参考资料 |
|
||||
|
||||
---
|
||||
|
||||
@@ -71,10 +109,12 @@ Export to Word 插件会把聊天消息从 Markdown 转成精致的 Word 文档
|
||||
|
||||
!!! note "前置条件"
|
||||
- `python-docx==1.1.2`(文档生成)
|
||||
- `Pygments>=2.15.0`(语法高亮,建议安装)
|
||||
- `Pygments>=2.15.0`(语法高亮)
|
||||
- `latex2mathml`(LaTeX 转 MathML)
|
||||
- `mathml2omml`(MathML 转 Office Math)
|
||||
|
||||
---
|
||||
|
||||
## 源码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/export_to_docx){ .md-button }
|
||||
[:fontawes**Author:** [Fu-Jie](https://github.com/Fu-Jie) | **Version:** 0.4.3 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui)/tree/main/plugins/actions/export_to_docx){ .md-button }
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Knowledge Card
|
||||
# Flash Card
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.2.2</span>
|
||||
<span class="version-badge">v0.2.4</span>
|
||||
|
||||
Quickly generates beautiful learning memory cards, perfect for studying and quick memorization.
|
||||
Quickly generates beautiful flashcards from text, extracting key points and categories.
|
||||
|
||||
---
|
||||
|
||||
@@ -23,7 +23,7 @@ The Knowledge Card plugin (also known as Flash Card / 闪记卡) transforms cont
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`knowledge_card.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/knowledge-card)
|
||||
1. Download the plugin file: [`flash_card.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/flash-card)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Enable the plugin
|
||||
|
||||
@@ -85,4 +85,4 @@ The Knowledge Card plugin (also known as Flash Card / 闪记卡) transforms cont
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/knowledge-card){ .md-button }
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/flash-card){ .md-button }
|
||||
@@ -1,7 +1,7 @@
|
||||
# Knowledge Card(知识卡片)
|
||||
# Flash Card(闪记卡)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.2.0</span>
|
||||
<span class="version-badge">v0.2.4</span>
|
||||
|
||||
快速生成精美的学习记忆卡片,适合学习和速记。
|
||||
|
||||
@@ -23,7 +23,7 @@ Knowledge Card 插件(又名 Flash Card / 闪记卡)会把内容转成视觉
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件:[`knowledge_card.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/knowledge-card)
|
||||
1. 下载插件文件:[`flash_card.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/flash-card)
|
||||
2. 上传到 OpenWebUI:**Admin Panel** → **Settings** → **Functions**
|
||||
3. 启用插件
|
||||
|
||||
@@ -85,4 +85,4 @@ Knowledge Card 插件(又名 Flash Card / 闪记卡)会把内容转成视觉
|
||||
|
||||
## 源码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/knowledge-card){ .md-button }
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/flash-card){ .md-button }
|
||||
@@ -23,7 +23,7 @@ Actions are interactive plugins that:
|
||||
|
||||
Intelligently analyzes text content and generates interactive mind maps with beautiful visualizations.
|
||||
|
||||
**Version:** 0.8.0
|
||||
**Version:** 0.9.1
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](smart-mind-map.md)
|
||||
|
||||
@@ -33,19 +33,19 @@ Actions are interactive plugins that:
|
||||
|
||||
Transform text into professional infographics using AntV visualization engine with various templates.
|
||||
|
||||
**Version:** 1.3.0
|
||||
**Version:** 1.4.9
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](smart-infographic.md)
|
||||
|
||||
- :material-card-text:{ .lg .middle } **Knowledge Card**
|
||||
- :material-card-text:{ .lg .middle } **Flash Card**
|
||||
|
||||
---
|
||||
|
||||
Quickly generates beautiful learning memory cards, perfect for studying and memorization.
|
||||
Quickly generates beautiful flashcards from text, extracting key points and categories.
|
||||
|
||||
**Version:** 0.2.2
|
||||
**Version:** 0.2.4
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](knowledge-card.md)
|
||||
[:octicons-arrow-right-24: Documentation](flash-card.md)
|
||||
|
||||
- :material-file-excel:{ .lg .middle } **Export to Excel**
|
||||
|
||||
@@ -53,29 +53,31 @@ Actions are interactive plugins that:
|
||||
|
||||
Export chat conversations to Excel spreadsheet format for analysis and archiving.
|
||||
|
||||
**Version:** 0.3.3
|
||||
**Version:** 0.3.7
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](export-to-excel.md)
|
||||
|
||||
- :material-file-word-box:{ .lg .middle } **Export to Word**
|
||||
- :material-file-word-box:{ .lg .middle } **Export to Word (Enhanced Formatting)**
|
||||
|
||||
---
|
||||
|
||||
Export chat content as Word (.docx) with Markdown formatting and syntax highlighting.
|
||||
|
||||
**Version:** 0.1.0
|
||||
Export the current conversation to a formatted Word doc with **syntax highlighting**, **native math equations**, **Mermaid diagrams**, **citations**, and **enhanced table formatting**.
|
||||
|
||||
**Version:** 0.4.2
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](export-to-word.md)
|
||||
|
||||
- :material-text-box-search:{ .lg .middle } **Summary**
|
||||
- :material-brain:{ .lg .middle } **Deep Dive**
|
||||
|
||||
---
|
||||
|
||||
Generate concise summaries of long text content with key points extraction.
|
||||
A comprehensive thinking lens that dives deep into any content - Context → Logic → Insight → Path. Supports theme auto-adaptation.
|
||||
|
||||
**Version:** 1.0.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](deep-dive.md)
|
||||
|
||||
**Version:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](summary.md)
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
@@ -33,19 +33,19 @@ Actions 是交互式插件,能够:
|
||||
|
||||
使用 AntV 可视化引擎,将文本转成专业的信息图。
|
||||
|
||||
**版本:** 1.3.0
|
||||
**版本:** 1.4.9
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](smart-infographic.md)
|
||||
|
||||
- :material-card-text:{ .lg .middle } **Knowledge Card**
|
||||
- :material-card-text:{ .lg .middle } **Flash Card(闪记卡)**
|
||||
|
||||
---
|
||||
|
||||
快速生成精美的学习记忆卡片,适合学习与记忆。
|
||||
快速生成精美的学习记忆卡片,非常适合学习和快速记忆。
|
||||
|
||||
**版本:** 0.2.2
|
||||
**版本:** 0.2.4
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](knowledge-card.md)
|
||||
[:octicons-arrow-right-24: 查看文档](flash-card.md)
|
||||
|
||||
- :material-file-excel:{ .lg .middle } **Export to Excel**
|
||||
|
||||
@@ -53,29 +53,31 @@ Actions 是交互式插件,能够:
|
||||
|
||||
将聊天记录导出为 Excel 电子表格,方便分析或归档。
|
||||
|
||||
**版本:** 0.3.3
|
||||
**版本:** 0.3.7
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](export-to-excel.md)
|
||||
|
||||
- :material-file-word-box:{ .lg .middle } **Export to Word**
|
||||
- :material-file-word-box:{ .lg .middle } **Word 导出 (格式增强)**
|
||||
|
||||
---
|
||||
|
||||
将聊天内容按 Markdown 格式导出为 Word (.docx),支持语法高亮。
|
||||
将当前对话导出为完美格式的 Word 文档,支持**代码语法高亮**、**原生数学公式**、**Mermaid 图表**、**引用资料**以及**增强表格**渲染。
|
||||
|
||||
**版本:** 0.1.0
|
||||
**版本:** 0.4.2
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](export-to-word.md)
|
||||
|
||||
- :material-text-box-search:{ .lg .middle } **Summary**
|
||||
- :material-brain:{ .lg .middle } **精读 (Deep Dive)**
|
||||
|
||||
---
|
||||
|
||||
对长文本进行精简总结,提取要点。
|
||||
全方位的思维透镜 —— 全景 → 脉络 → 洞察 → 路径。支持主题自适应。
|
||||
|
||||
**版本:** 1.0.0
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](deep-dive.zh.md)
|
||||
|
||||
**版本:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](summary.md)
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
120
docs/plugins/actions/infographic-markdown.md
Normal file
120
docs/plugins/actions/infographic-markdown.md
Normal file
@@ -0,0 +1,120 @@
|
||||
# Infographic to Markdown
|
||||
|
||||
> **Version:** 1.0.0 | **Author:** Fu-Jie
|
||||
|
||||
AI-powered infographic generator that renders SVG on the frontend and embeds it directly into Markdown as a Data URL image.
|
||||
|
||||
## Overview
|
||||
|
||||
This plugin combines the power of AI text analysis with AntV Infographic visualization to create beautiful infographics that are embedded directly into chat messages as Markdown images.
|
||||
|
||||
### Key Features
|
||||
|
||||
- :robot: **AI-Powered**: Automatically analyzes text and selects the best infographic template
|
||||
- :bar_chart: **Multiple Templates**: Supports 18+ infographic templates (lists, charts, comparisons, etc.)
|
||||
- :framed_picture: **Self-Contained**: SVG/PNG embedded as Data URL, no external dependencies
|
||||
- :memo: **Markdown Native**: Results are pure Markdown images, compatible everywhere
|
||||
- :arrows_counterclockwise: **API Writeback**: Updates message content via REST API for persistence
|
||||
|
||||
### How It Works
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
A[User triggers action] --> B[Python extracts message content]
|
||||
B --> C[LLM generates Infographic syntax]
|
||||
C --> D[Frontend JS loads AntV library]
|
||||
D --> E[Render SVG offscreen]
|
||||
E --> F[Export to Data URL]
|
||||
F --> G[Update message via API]
|
||||
G --> H[Display as Markdown image]
|
||||
```
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download `infographic_markdown.py` (English) or `infographic_markdown_cn.py` (Chinese)
|
||||
2. Navigate to **Admin Panel** → **Settings** → **Functions**
|
||||
3. Upload the file and configure settings
|
||||
4. Use the action button in chat messages
|
||||
|
||||
## Configuration
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
|-----------|------|---------|-------------|
|
||||
| `SHOW_STATUS` | bool | `true` | Show operation status updates |
|
||||
| `MODEL_ID` | string | `""` | LLM model ID (empty = use current model) |
|
||||
| `MIN_TEXT_LENGTH` | int | `50` | Minimum text length required |
|
||||
| `MESSAGE_COUNT` | int | `1` | Number of recent messages to use |
|
||||
| `SVG_WIDTH` | int | `800` | Width of generated SVG (pixels) |
|
||||
| `EXPORT_FORMAT` | string | `"svg"` | Export format: `svg` or `png` |
|
||||
|
||||
## Supported Templates
|
||||
|
||||
| Category | Template | Description |
|
||||
|----------|----------|-------------|
|
||||
| List | `list-grid` | Grid cards |
|
||||
| List | `list-vertical` | Vertical list |
|
||||
| Tree | `tree-vertical` | Vertical tree |
|
||||
| Tree | `tree-horizontal` | Horizontal tree |
|
||||
| Mind Map | `mindmap` | Mind map |
|
||||
| Process | `sequence-roadmap` | Roadmap |
|
||||
| Process | `sequence-zigzag` | Zigzag process |
|
||||
| Relation | `relation-sankey` | Sankey diagram |
|
||||
| Relation | `relation-circle` | Circular relation |
|
||||
| Compare | `compare-binary` | Binary comparison |
|
||||
| Analysis | `compare-swot` | SWOT analysis |
|
||||
| Quadrant | `quadrant-quarter` | Quadrant chart |
|
||||
| Chart | `chart-bar` | Bar chart |
|
||||
| Chart | `chart-column` | Column chart |
|
||||
| Chart | `chart-line` | Line chart |
|
||||
| Chart | `chart-pie` | Pie chart |
|
||||
| Chart | `chart-doughnut` | Doughnut chart |
|
||||
| Chart | `chart-area` | Area chart |
|
||||
|
||||
## Usage Example
|
||||
|
||||
1. Generate some text content in the chat (or have the AI generate it)
|
||||
2. Click the **📊 Infographic to Markdown** action button
|
||||
3. Wait for AI analysis and SVG rendering
|
||||
4. The infographic will be embedded as a Markdown image
|
||||
|
||||
## Technical Details
|
||||
|
||||
### Data URL Embedding
|
||||
|
||||
The plugin converts SVG graphics to Base64-encoded Data URLs:
|
||||
|
||||
```javascript
|
||||
const svgData = new XMLSerializer().serializeToString(svg);
|
||||
const base64 = btoa(unescape(encodeURIComponent(svgData)));
|
||||
const dataUri = "data:image/svg+xml;base64," + base64;
|
||||
const markdownImage = ``;
|
||||
```
|
||||
|
||||
### AntV toDataURL API
|
||||
|
||||
```javascript
|
||||
// Export as SVG (recommended)
|
||||
const svgUrl = await instance.toDataURL({
|
||||
type: 'svg',
|
||||
embedResources: true
|
||||
});
|
||||
|
||||
// Export as PNG
|
||||
const pngUrl = await instance.toDataURL({
|
||||
type: 'png',
|
||||
dpr: 2
|
||||
});
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
1. **Browser Compatibility**: Requires modern browsers with ES6+ and Fetch API support
|
||||
2. **Network Dependency**: First use requires loading AntV library from CDN
|
||||
3. **Data URL Size**: Base64 encoding increases size by ~33%
|
||||
4. **Chinese Fonts**: SVG export embeds fonts for correct display
|
||||
|
||||
## Related Resources
|
||||
|
||||
- [AntV Infographic Documentation](https://infographic.antv.vision/)
|
||||
- [Infographic API Reference](https://infographic.antv.vision/reference/infographic-api)
|
||||
- [Infographic Syntax Guide](https://infographic.antv.vision/learn/infographic-syntax)
|
||||
120
docs/plugins/actions/infographic-markdown.zh.md
Normal file
120
docs/plugins/actions/infographic-markdown.zh.md
Normal file
@@ -0,0 +1,120 @@
|
||||
# 信息图转 Markdown
|
||||
|
||||
> **版本:** 1.0.0 | **作者:** Fu-Jie
|
||||
|
||||
AI 驱动的信息图生成器,在前端渲染 SVG 并以 Data URL 图片格式直接嵌入到 Markdown 中。
|
||||
|
||||
## 概述
|
||||
|
||||
这个插件结合了 AI 文本分析能力和 AntV Infographic 可视化引擎,生成精美的信息图并以 Markdown 图片格式直接嵌入到聊天消息中。
|
||||
|
||||
### 主要特性
|
||||
|
||||
- :robot: **AI 驱动**: 自动分析文本并选择最佳的信息图模板
|
||||
- :bar_chart: **多种模板**: 支持 18+ 种信息图模板(列表、图表、对比等)
|
||||
- :framed_picture: **自包含**: SVG/PNG 以 Data URL 嵌入,无外部依赖
|
||||
- :memo: **Markdown 原生**: 结果是纯 Markdown 图片,兼容任何平台
|
||||
- :arrows_counterclockwise: **API 回写**: 通过 REST API 更新消息内容实现持久化
|
||||
|
||||
### 工作原理
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
A[用户触发动作] --> B[Python 提取消息内容]
|
||||
B --> C[LLM 生成 Infographic 语法]
|
||||
C --> D[前端 JS 加载 AntV 库]
|
||||
D --> E[离屏渲染 SVG]
|
||||
E --> F[导出为 Data URL]
|
||||
F --> G[通过 API 更新消息]
|
||||
G --> H[显示为 Markdown 图片]
|
||||
```
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载 `infographic_markdown.py`(英文版)或 `infographic_markdown_cn.py`(中文版)
|
||||
2. 进入 **管理面板** → **设置** → **功能**
|
||||
3. 上传文件并配置设置
|
||||
4. 在聊天消息中使用动作按钮
|
||||
|
||||
## 配置选项
|
||||
|
||||
| 参数 | 类型 | 默认值 | 描述 |
|
||||
|------|------|--------|------|
|
||||
| `SHOW_STATUS` | bool | `true` | 是否显示操作状态 |
|
||||
| `MODEL_ID` | string | `""` | LLM 模型 ID(空则使用当前模型) |
|
||||
| `MIN_TEXT_LENGTH` | int | `50` | 最小文本长度要求 |
|
||||
| `MESSAGE_COUNT` | int | `1` | 用于生成的最近消息数量 |
|
||||
| `SVG_WIDTH` | int | `800` | 生成的 SVG 宽度(像素) |
|
||||
| `EXPORT_FORMAT` | string | `"svg"` | 导出格式:`svg` 或 `png` |
|
||||
|
||||
## 支持的模板
|
||||
|
||||
| 类别 | 模板名称 | 描述 |
|
||||
|------|----------|------|
|
||||
| 列表 | `list-grid` | 网格卡片 |
|
||||
| 列表 | `list-vertical` | 垂直列表 |
|
||||
| 树形 | `tree-vertical` | 垂直树 |
|
||||
| 树形 | `tree-horizontal` | 水平树 |
|
||||
| 思维导图 | `mindmap` | 思维导图 |
|
||||
| 流程 | `sequence-roadmap` | 路线图 |
|
||||
| 流程 | `sequence-zigzag` | 折线流程 |
|
||||
| 关系 | `relation-sankey` | 桑基图 |
|
||||
| 关系 | `relation-circle` | 圆形关系 |
|
||||
| 对比 | `compare-binary` | 二元对比 |
|
||||
| 分析 | `compare-swot` | SWOT 分析 |
|
||||
| 象限 | `quadrant-quarter` | 四象限图 |
|
||||
| 图表 | `chart-bar` | 条形图 |
|
||||
| 图表 | `chart-column` | 柱状图 |
|
||||
| 图表 | `chart-line` | 折线图 |
|
||||
| 图表 | `chart-pie` | 饼图 |
|
||||
| 图表 | `chart-doughnut` | 环形图 |
|
||||
| 图表 | `chart-area` | 面积图 |
|
||||
|
||||
## 使用示例
|
||||
|
||||
1. 在聊天中生成一些文本内容(或让 AI 生成)
|
||||
2. 点击 **📊 信息图转 Markdown** 动作按钮
|
||||
3. 等待 AI 分析和 SVG 渲染
|
||||
4. 信息图将以 Markdown 图片形式嵌入
|
||||
|
||||
## 技术细节
|
||||
|
||||
### Data URL 嵌入
|
||||
|
||||
插件将 SVG 图形转换为 Base64 编码的 Data URL:
|
||||
|
||||
```javascript
|
||||
const svgData = new XMLSerializer().serializeToString(svg);
|
||||
const base64 = btoa(unescape(encodeURIComponent(svgData)));
|
||||
const dataUri = "data:image/svg+xml;base64," + base64;
|
||||
const markdownImage = ``;
|
||||
```
|
||||
|
||||
### AntV toDataURL API
|
||||
|
||||
```javascript
|
||||
// 导出 SVG(推荐)
|
||||
const svgUrl = await instance.toDataURL({
|
||||
type: 'svg',
|
||||
embedResources: true
|
||||
});
|
||||
|
||||
// 导出 PNG
|
||||
const pngUrl = await instance.toDataURL({
|
||||
type: 'png',
|
||||
dpr: 2
|
||||
});
|
||||
```
|
||||
|
||||
## 注意事项
|
||||
|
||||
1. **浏览器兼容性**: 需要现代浏览器支持 ES6+ 和 Fetch API
|
||||
2. **网络依赖**: 首次使用需要从 CDN 加载 AntV Infographic 库
|
||||
3. **Data URL 大小**: Base64 编码会增加约 33% 的体积
|
||||
4. **中文字体**: SVG 导出时会嵌入字体以确保正确显示
|
||||
|
||||
## 相关资源
|
||||
|
||||
- [AntV Infographic 官方文档](https://infographic.antv.vision/)
|
||||
- [Infographic API 参考](https://infographic.antv.vision/reference/infographic-api)
|
||||
- [Infographic 语法规范](https://infographic.antv.vision/learn/infographic-syntax)
|
||||
@@ -1,7 +1,7 @@
|
||||
# Smart Infographic
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v1.3.0</span>
|
||||
<span class="version-badge">v1.4.9</span>
|
||||
|
||||
An AntV Infographic engine powered plugin that transforms long text into professional, beautiful infographics with a single click.
|
||||
|
||||
@@ -14,11 +14,13 @@ The Smart Infographic plugin uses AI to analyze text content and generate profes
|
||||
## Features
|
||||
|
||||
- :material-robot: **AI-Powered Transformation**: Automatically analyzes text logic, extracts key points, and generates structured charts
|
||||
- :material-palette: **Professional Templates**: Includes various AntV official templates: Lists, Trees, Mindmaps, Comparison Tables, Flowcharts, and Statistical Charts
|
||||
- :material-magnify: **Auto-Icon Matching**: Built-in logic to search and match the most relevant Material Design Icons based on content
|
||||
- :material-palette: **70+ Professional Templates**: Includes various AntV official templates: Lists, Trees, Roadmaps, Timelines, Comparison Tables, SWOT, Quadrants, and Statistical Charts
|
||||
- :material-magnify: **Auto-Icon Matching**: Built-in logic to search and match the most relevant icons (Iconify) and illustrations (unDraw)
|
||||
- :material-download: **Multi-Format Export**: Download your infographics as **SVG**, **PNG**, or **Standalone HTML** file
|
||||
- :material-theme-light-dark: **Theme Support**: Supports Dark/Light modes, auto-adapts theme colors
|
||||
- :material-cellphone-link: **Responsive Design**: Generated charts look great on both desktop and mobile devices
|
||||
- :material-image: **Image Embedding**: Option to embed charts as static images for better compatibility
|
||||
- :material-monitor-screenshot: **Adaptive Sizing**: Images automatically adapt to the chat container width
|
||||
|
||||
---
|
||||
|
||||
@@ -35,10 +37,11 @@ The Smart Infographic plugin uses AI to analyze text content and generate profes
|
||||
|
||||
| Category | Template Name | Use Case |
|
||||
|:---------|:--------------|:---------|
|
||||
| **Lists & Hierarchy** | `list-grid`, `tree-vertical`, `mindmap` | Features, Org Charts, Brainstorming |
|
||||
| **Sequence & Relation** | `sequence-roadmap`, `relation-circle` | Roadmaps, Circular Flows, Steps |
|
||||
| **Comparison & Analysis** | `compare-binary`, `compare-swot`, `quadrant-quarter` | Pros/Cons, SWOT, Quadrants |
|
||||
| **Charts & Data** | `chart-bar`, `chart-line`, `chart-pie` | Trends, Distributions, Metrics |
|
||||
| **Sequence** | `sequence-timeline-simple`, `sequence-roadmap-vertical-simple`, `sequence-snake-steps-compact-card` | Timelines, Roadmaps, Processes |
|
||||
| **Lists** | `list-grid-candy-card-lite`, `list-row-horizontal-icon-arrow`, `list-column-simple-vertical-arrow` | Features, Bullet Points, Lists |
|
||||
| **Comparison** | `compare-binary-horizontal-underline-text-vs`, `compare-swot`, `quadrant-quarter-simple-card` | Pros/Cons, SWOT, Quadrants |
|
||||
| **Hierarchy** | `hierarchy-tree-tech-style-capsule-item`, `hierarchy-structure` | Org Charts, Structures |
|
||||
| **Charts** | `chart-column-simple`, `chart-bar-plain-text`, `chart-line-plain-text`, `chart-wordcloud` | Trends, Distributions, Metrics |
|
||||
|
||||
---
|
||||
|
||||
@@ -60,6 +63,7 @@ The Smart Infographic plugin uses AI to analyze text content and generate profes
|
||||
| `MIN_TEXT_LENGTH` | integer | `100` | Minimum characters required to trigger analysis |
|
||||
| `CLEAR_PREVIOUS_HTML` | boolean | `false` | Whether to clear previous charts |
|
||||
| `MESSAGE_COUNT` | integer | `1` | Number of recent messages to use for analysis |
|
||||
| `OUTPUT_MODE` | string | `image` | `image` for static image embedding (default), `html` for interactive chart |
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Smart Infographic(智能信息图)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
<span class="version-badge">v1.4.9</span>
|
||||
|
||||
基于 AntV 信息图引擎,将长文本一键转成专业、美观的信息图。
|
||||
|
||||
@@ -14,11 +14,13 @@ Smart Infographic 使用 AI 分析文本,并基于 AntV 可视化引擎生成
|
||||
## 功能特性
|
||||
|
||||
- :material-robot: **AI 转换**:自动分析文本逻辑,提取要点并生成结构化图表
|
||||
- :material-palette: **专业模板**:内置 AntV 官方模板:列表、树、思维导图、对比表、流程图、统计图等
|
||||
- :material-magnify: **自动匹配图标**:根据内容自动选择最合适的 Material Design Icons
|
||||
- :material-palette: **70+ 专业模板**:内置多种 AntV 官方模板,包括列表、树图、路线图、时间线、对比图、SWOT、象限图及统计图表等
|
||||
- :material-magnify: **自动匹配图标**:内置图标搜索逻辑,支持 Iconify 图标和 unDraw 插图自动匹配
|
||||
- :material-download: **多格式导出**:支持下载 **SVG**、**PNG**、**独立 HTML**
|
||||
- :material-theme-light-dark: **主题支持**:适配深色/浅色模式
|
||||
- :material-cellphone-link: **响应式**:桌面与移动端都能良好展示
|
||||
- :material-image: **图片嵌入**:支持将图表作为静态图片嵌入,兼容性更好
|
||||
- :material-monitor-screenshot: **自适应尺寸**:图片模式下自动适应聊天容器宽度
|
||||
|
||||
---
|
||||
|
||||
@@ -35,10 +37,11 @@ Smart Infographic 使用 AI 分析文本,并基于 AntV 可视化引擎生成
|
||||
|
||||
| 分类 | 模板名称 | 典型场景 |
|
||||
|:---------|:--------------|:---------|
|
||||
| **列表与层级** | `list-grid`, `tree-vertical`, `mindmap` | 特性列表、组织结构、头脑风暴 |
|
||||
| **序列与关系** | `sequence-roadmap`, `relation-circle` | 路线图、循环流程、步骤拆解 |
|
||||
| **对比与分析** | `compare-binary`, `compare-swot`, `quadrant-quarter` | 优劣势、SWOT、象限分析 |
|
||||
| **图表与数据** | `chart-bar`, `chart-line`, `chart-pie` | 趋势、分布、指标对比 |
|
||||
| **时序与流程** | `sequence-timeline-simple`, `sequence-roadmap-vertical-simple`, `sequence-snake-steps-compact-card` | 时间线、路线图、步骤说明 |
|
||||
| **列表与网格** | `list-grid-candy-card-lite`, `list-row-horizontal-icon-arrow`, `list-column-simple-vertical-arrow` | 功能亮点、要点列举、清单 |
|
||||
| **对比与分析** | `compare-binary-horizontal-underline-text-vs`, `compare-swot`, `quadrant-quarter-simple-card` | 优劣势对比、SWOT 分析、象限图 |
|
||||
| **层级与结构** | `hierarchy-tree-tech-style-capsule-item`, `hierarchy-structure` | 组织架构、层级关系 |
|
||||
| **图表与数据** | `chart-column-simple`, `chart-bar-plain-text`, `chart-line-plain-text`, `chart-wordcloud` | 数据趋势、比例分布、数值对比 |
|
||||
|
||||
---
|
||||
|
||||
@@ -60,6 +63,7 @@ Smart Infographic 使用 AI 分析文本,并基于 AntV 可视化引擎生成
|
||||
| `MIN_TEXT_LENGTH` | integer | `100` | 触发分析的最小字符数 |
|
||||
| `CLEAR_PREVIOUS_HTML` | boolean | `false` | 是否清空之前生成的图表 |
|
||||
| `MESSAGE_COUNT` | integer | `1` | 参与分析的最近消息条数 |
|
||||
| `OUTPUT_MODE` | string | `image` | `image` 为静态图片嵌入(默认),`html` 为交互式图表 |
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Smart Mind Map
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.8.0</span>
|
||||
<span class="version-badge">v0.9.1</span>
|
||||
|
||||
Intelligently analyzes text content and generates interactive mind maps for better visualization and understanding.
|
||||
|
||||
@@ -23,7 +23,7 @@ The Smart Mind Map plugin transforms text content into beautiful, interactive mi
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`思维导图.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/smart-mind-map)
|
||||
1. Download the plugin file: [`smart_mind_map.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/smart-mind-map)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions** (Actions)
|
||||
3. Enable the plugin, and optionally allow iframe same-origin access so theme auto-detection works
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Smart Mind Map(智能思维导图)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.8.0</span>
|
||||
<span class="version-badge">v0.9.1</span>
|
||||
|
||||
智能分析文本内容,生成交互式思维导图,帮助你更直观地理解信息结构。
|
||||
|
||||
@@ -23,7 +23,7 @@ Smart Mind Map 会将文本转换成漂亮的交互式思维导图。插件会
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件:[`思维导图.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/smart-mind-map)
|
||||
1. 下载插件文件:[`smart_mind_map.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/smart-mind-map)
|
||||
2. 上传到 OpenWebUI:**Admin Panel** → **Settings** → **Functions**(Actions)
|
||||
3. 启用插件,并可在设置中允许 iframe same-origin 以启用主题自动检测
|
||||
|
||||
|
||||
@@ -1,82 +0,0 @@
|
||||
# Summary
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
|
||||
Generate concise summaries of long text content with key points extraction.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Summary plugin helps you quickly understand long pieces of text by generating concise summaries with extracted key points. It's perfect for:
|
||||
|
||||
- Summarizing long articles or documents
|
||||
- Extracting key points from conversations
|
||||
- Creating quick overviews of complex topics
|
||||
|
||||
## Features
|
||||
|
||||
- :material-text-box-search: **Smart Summarization**: AI-powered content analysis
|
||||
- :material-format-list-bulleted: **Key Points**: Extracted important highlights
|
||||
- :material-content-copy: **Easy Copy**: One-click copying of summaries
|
||||
- :material-tune: **Adjustable Length**: Control summary detail level
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`summary.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/summary)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Enable the plugin
|
||||
|
||||
---
|
||||
|
||||
## Usage
|
||||
|
||||
1. Get a long response from the AI or paste long text
|
||||
2. Click the **Summary** button in the message action bar
|
||||
3. View the generated summary with key points
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `summary_length` | string | `"medium"` | Length of summary (short/medium/long) |
|
||||
| `include_key_points` | boolean | `true` | Extract and list key points |
|
||||
| `language` | string | `"auto"` | Output language |
|
||||
|
||||
---
|
||||
|
||||
## Example Output
|
||||
|
||||
```markdown
|
||||
## Summary
|
||||
|
||||
This document discusses the implementation of a new feature
|
||||
for the application, focusing on user experience improvements
|
||||
and performance optimizations.
|
||||
|
||||
### Key Points
|
||||
|
||||
- ✅ New user interface design improves accessibility
|
||||
- ✅ Backend optimizations reduce load times by 40%
|
||||
- ✅ Mobile responsiveness enhanced
|
||||
- ✅ Integration with third-party services simplified
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Requirements
|
||||
|
||||
!!! note "Prerequisites"
|
||||
- OpenWebUI v0.3.0 or later
|
||||
- Uses the active LLM model for summarization
|
||||
|
||||
---
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/summary){ .md-button }
|
||||
@@ -1,82 +0,0 @@
|
||||
# Summary(摘要)
|
||||
|
||||
<span class="category-badge action">Action</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
|
||||
为长文本生成简洁摘要,并提取关键要点。
|
||||
|
||||
---
|
||||
|
||||
## 概览
|
||||
|
||||
Summary 插件可以快速理解长文本,生成精炼摘要并列出关键点,适合:
|
||||
|
||||
- 总结长文章或文档
|
||||
- 从对话中提炼要点
|
||||
- 为复杂主题制作快速概览
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-text-box-search: **智能摘要**:AI 驱动的内容分析
|
||||
- :material-format-list-bulleted: **关键点**:提取重要信息
|
||||
- :material-content-copy: **便捷复制**:一键复制摘要
|
||||
- :material-tune: **长度可调**:可选择摘要详略程度
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件:[`summary.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/summary)
|
||||
2. 上传到 OpenWebUI:**Admin Panel** → **Settings** → **Functions**
|
||||
3. 启用插件
|
||||
|
||||
---
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 获取一段较长的 AI 回复或粘贴长文本
|
||||
2. 点击消息操作栏的 **Summary** 按钮
|
||||
3. 查看生成的摘要与关键点
|
||||
|
||||
---
|
||||
|
||||
## 配置项
|
||||
|
||||
| 选项 | 类型 | 默认值 | 说明 |
|
||||
|--------|------|---------|-------------|
|
||||
| `summary_length` | string | `"medium"` | 摘要长度(short/medium/long) |
|
||||
| `include_key_points` | boolean | `true` | 是否提取并列出关键点 |
|
||||
| `language` | string | `"auto"` | 输出语言 |
|
||||
|
||||
---
|
||||
|
||||
## 输出示例
|
||||
|
||||
```markdown
|
||||
## Summary
|
||||
|
||||
This document discusses the implementation of a new feature
|
||||
for the application, focusing on user experience improvements
|
||||
and performance optimizations.
|
||||
|
||||
### Key Points
|
||||
|
||||
- ✅ New user interface design improves accessibility
|
||||
- ✅ Backend optimizations reduce load times by 40%
|
||||
- ✅ Mobile responsiveness enhanced
|
||||
- ✅ Integration with third-party services simplified
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 运行要求
|
||||
|
||||
!!! note "前置条件"
|
||||
- OpenWebUI v0.3.0 及以上
|
||||
- 使用当前会话的 LLM 模型进行摘要
|
||||
|
||||
---
|
||||
|
||||
## 源码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/actions/summary){ .md-button }
|
||||
@@ -1,7 +1,7 @@
|
||||
# Async Context Compression
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v1.1.0</span>
|
||||
<span class="version-badge">v1.2.2</span>
|
||||
|
||||
Reduces token consumption in long conversations through intelligent summarization while maintaining conversational coherence.
|
||||
|
||||
@@ -29,6 +29,17 @@ This is especially useful for:
|
||||
- :material-clock-fast: **Async Processing**: Non-blocking background compression
|
||||
- :material-memory: **Context Preservation**: Keeps important information
|
||||
- :material-currency-usd-off: **Cost Reduction**: Minimize token usage
|
||||
- :material-console: **Frontend Debugging**: Debug logs in browser console
|
||||
- :material-alert-circle-check: **Enhanced Error Reporting**: Clear error status notifications
|
||||
- :material-check-all: **Open WebUI v0.7.x Compatibility**: Dynamic DB session handling
|
||||
- :material-account-convert: **Improved Compatibility**: Summary role changed to `assistant`
|
||||
- :material-shield-check: **Enhanced Stability**: Resolved race conditions in state management
|
||||
- :material-ruler: **Preflight Context Check**: Validates context fit before sending
|
||||
- :material-format-align-justify: **Structure-Aware Trimming**: Preserves document structure
|
||||
- :material-content-cut: **Native Tool Output Trimming**: Trims verbose tool outputs (Note: Non-native tool outputs are not fully injected into context)
|
||||
- :material-chart-bar: **Detailed Token Logging**: Granular token breakdown
|
||||
- :material-account-search: **Smart Model Matching**: Inherit config from base models
|
||||
- :material-image-off: **Multimodal Support**: Images are preserved but tokens are **NOT** calculated
|
||||
|
||||
---
|
||||
|
||||
@@ -59,10 +70,14 @@ graph TD
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `token_threshold` | integer | `4000` | Trigger compression above this token count |
|
||||
| `preserve_recent` | integer | `5` | Number of recent messages to keep uncompressed |
|
||||
| `summary_model` | string | `"auto"` | Model to use for summarization |
|
||||
| `compression_ratio` | float | `0.3` | Target compression ratio |
|
||||
| `compression_threshold_tokens` | integer | `64000` | Trigger compression above this token count |
|
||||
| `max_context_tokens` | integer | `128000` | Hard limit for context |
|
||||
| `keep_first` | integer | `1` | Always keep the first N messages |
|
||||
| `keep_last` | integer | `6` | Always keep the last N messages |
|
||||
| `summary_model` | string | `None` | Model to use for summarization |
|
||||
| `summary_model_max_context` | integer | `0` | Max context tokens for summary model |
|
||||
| `max_summary_tokens` | integer | `16384` | Maximum tokens for the summary |
|
||||
| `enable_tool_output_trimming` | boolean | `false` | Enable trimming of large tool outputs |
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Async Context Compression(异步上下文压缩)
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v1.1.0</span>
|
||||
<span class="version-badge">v1.2.2</span>
|
||||
|
||||
通过智能摘要减少长对话的 token 消耗,同时保持对话连贯。
|
||||
|
||||
@@ -29,6 +29,17 @@ Async Context Compression 过滤器通过以下方式帮助管理长对话的 to
|
||||
- :material-clock-fast: **异步处理**:后台非阻塞压缩
|
||||
- :material-memory: **保留上下文**:尽量保留重要信息
|
||||
- :material-currency-usd-off: **降低成本**:减少 token 使用
|
||||
- :material-console: **前端调试**:支持浏览器控制台日志
|
||||
- :material-alert-circle-check: **增强错误报告**:清晰的错误状态通知
|
||||
- :material-check-all: **Open WebUI v0.7.x 兼容性**:动态数据库会话处理
|
||||
- :material-account-convert: **兼容性提升**:摘要角色改为 `assistant`
|
||||
- :material-shield-check: **稳定性增强**:解决状态管理竞态条件
|
||||
- :material-ruler: **预检上下文检查**:发送前验证上下文是否超限
|
||||
- :material-format-align-justify: **结构感知裁剪**:保留文档结构的智能裁剪
|
||||
- :material-content-cut: **原生工具输出裁剪**:自动裁剪冗长的工具输出(注意:非原生工具调用输出不会完整注入上下文)
|
||||
- :material-chart-bar: **详细 Token 日志**:提供细粒度的 Token 统计
|
||||
- :material-account-search: **智能模型匹配**:自定义模型自动继承基础模型配置
|
||||
- :material-image-off: **多模态支持**:图片内容保留但 Token **不参与计算**
|
||||
|
||||
---
|
||||
|
||||
@@ -59,10 +70,14 @@ graph TD
|
||||
|
||||
| 选项 | 类型 | 默认值 | 说明 |
|
||||
|--------|------|---------|-------------|
|
||||
| `token_threshold` | integer | `4000` | 超过该 token 数触发压缩 |
|
||||
| `preserve_recent` | integer | `5` | 保留不压缩的最近消息数量 |
|
||||
| `summary_model` | string | `"auto"` | 用于摘要的模型 |
|
||||
| `compression_ratio` | float | `0.3` | 目标压缩比例 |
|
||||
| `compression_threshold_tokens` | integer | `64000` | 超过该 token 数触发压缩 |
|
||||
| `max_context_tokens` | integer | `128000` | 上下文硬性上限 |
|
||||
| `keep_first` | integer | `1` | 始终保留的前 N 条消息 |
|
||||
| `keep_last` | integer | `6` | 始终保留的后 N 条消息 |
|
||||
| `summary_model` | string | `None` | 用于摘要的模型 |
|
||||
| `summary_model_max_context` | integer | `0` | 摘要模型的最大上下文 Token 数 |
|
||||
| `max_summary_tokens` | integer | `16384` | 摘要的最大 token 数 |
|
||||
| `enable_tool_output_trimming` | boolean | `false` | 启用长工具输出裁剪 |
|
||||
|
||||
---
|
||||
|
||||
|
||||
57
docs/plugins/filters/folder-memory.md
Normal file
57
docs/plugins/filters/folder-memory.md
Normal file
@@ -0,0 +1,57 @@
|
||||
# Folder Memory
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 What's new in 0.1.0
|
||||
- **Initial Release**: Automated "Project Rules" management for OpenWebUI folders.
|
||||
- **Folder-Level Persistence**: Automatically updates folder system prompts with extracted rules.
|
||||
- **Optimized Performance**: Runs asynchronously and supports `PRIORITY` configuration for seamless integration with other filters.
|
||||
|
||||
---
|
||||
|
||||
**Folder Memory** is an intelligent context filter plugin for OpenWebUI. It automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||
|
||||
This ensures that all future conversations within that folder share the same evolved context and rules, without manual updates.
|
||||
|
||||
## Features
|
||||
|
||||
- **Automatic Extraction**: Analyzes chat history every N messages to extract project rules.
|
||||
- **Non-destructive Injection**: Updates only the specific "Project Rules" block in the system prompt, preserving other instructions.
|
||||
- **Async Processing**: Runs in the background without blocking the user's chat experience.
|
||||
- **ORM Integration**: Directly updates folder data using OpenWebUI's internal models for reliability.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- **Conversations must occur inside a folder.** This plugin only triggers when a chat belongs to a folder (i.e., you need to create a folder in OpenWebUI and start a conversation within it).
|
||||
|
||||
## Installation
|
||||
|
||||
1. Copy `folder_memory.py` to your OpenWebUI `plugins/filters/` directory (or upload via Admin UI).
|
||||
2. Enable the filter in your **Settings** -> **Filters**.
|
||||
3. (Optional) Configure the triggering threshold (default: every 10 messages).
|
||||
|
||||
## Configuration (Valves)
|
||||
|
||||
| Valve | Default | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | Priority level for the filter operations. |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | The number of messages required to trigger a rule analysis. |
|
||||
| `MODEL_ID` | `""` | The model used to generate rules. If empty, uses the current chat model. |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 Project Rules` | The title displayed above the injected rules block. |
|
||||
| `SHOW_DEBUG_LOG` | `False` | Show detailed debug logs in the browser console. |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | If enabled, finds and updates the root folder rules instead of the current subfolder. |
|
||||
|
||||
## How It Works
|
||||
|
||||
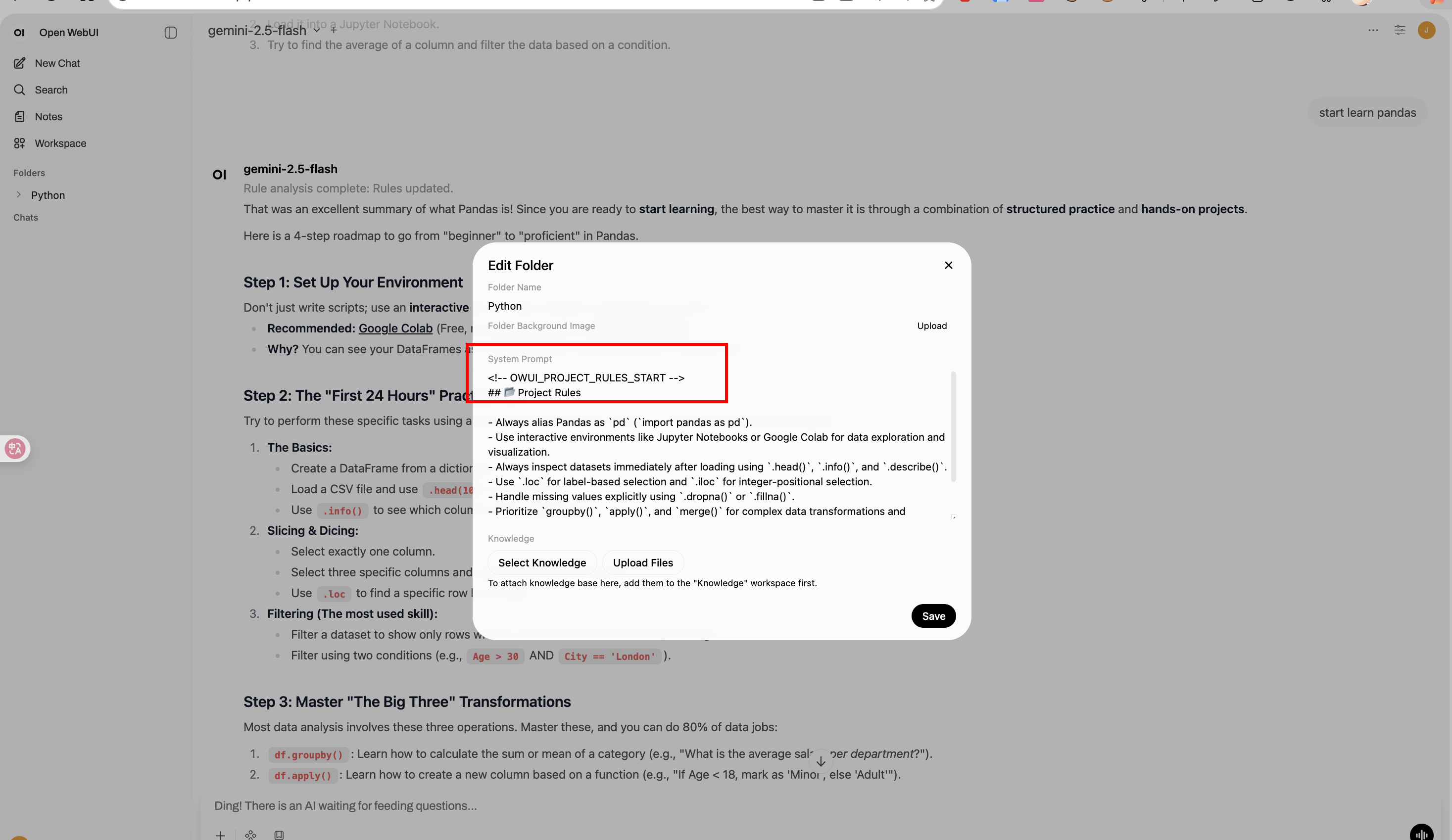
|
||||
|
||||
1. **Trigger**: When a conversation reaches `MESSAGE_TRIGGER_COUNT` (e.g., 10, 20 messages).
|
||||
2. **Analysis**: The plugin sends the recent conversation + existing rules to the LLM.
|
||||
3. **Synthesis**: The LLM merges new insights with old rules, removing obsolete ones.
|
||||
4. **Update**: The new rule set replaces the `<!-- OWUI_PROJECT_RULES_START -->` block in the folder's system prompt.
|
||||
|
||||
## Roadmap
|
||||
|
||||
See [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) for future plans, including "Project Knowledge" collection.
|
||||
57
docs/plugins/filters/folder-memory.zh.md
Normal file
57
docs/plugins/filters/folder-memory.zh.md
Normal file
@@ -0,0 +1,57 @@
|
||||
# 文件夹记忆 (Folder Memory)
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 0.1.0 版本特性
|
||||
- **首个版本发布**:专注于自动化的“项目规则”管理。
|
||||
- **文件夹级持久化**:自动将提取的规则回写到文件夹系统提示词中。
|
||||
- **性能优化**:采用异步处理机制,并支持 `PRIORITY` 配置,确保与其他过滤器(如上下文压缩)完美协作。
|
||||
|
||||
---
|
||||
|
||||
**文件夹记忆 (Folder Memory)** 是一个 OpenWebUI 的智能上下文过滤器插件。它能自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||
|
||||
这确保了该文件夹内的所有未来对话都能共享相同的进化上下文和规则,无需手动更新。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- **自动提取**:每隔 N 条消息分析一次聊天记录,提取项目规则。
|
||||
- **无损注入**:仅更新系统提示词中的特定“项目规则”块,保留其他指令。
|
||||
- **异步处理**:在后台运行,不阻塞用户的聊天体验。
|
||||
- **ORM 集成**:直接使用 OpenWebUI 的内部模型更新文件夹数据,确保可靠性。
|
||||
|
||||
## 前置条件
|
||||
|
||||
- **对话必须在文件夹内进行。** 此插件仅在聊天属于某个文件夹时触发(即您需要先在 OpenWebUI 中创建一个文件夹,并在其内部开始对话)。
|
||||
|
||||
## 安装指南
|
||||
|
||||
1. 将 `folder_memory.py` (或中文版 `folder_memory_cn.py`) 复制到 OpenWebUI 的 `plugins/filters/` 目录(或通过管理员 UI 上传)。
|
||||
2. 在 **设置** -> **过滤器** 中启用该插件。
|
||||
3. (可选)配置触发阈值(默认:每 10 条消息)。
|
||||
|
||||
## 配置 (Valves)
|
||||
|
||||
| 参数 | 默认值 | 说明 |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | 过滤器操作的优先级。 |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | 触发规则分析的消息数量阈值。 |
|
||||
| `MODEL_ID` | `""` | 用于生成规则的模型 ID。若为空,则使用当前对话模型。 |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 项目规则` | 显示在注入规则块上方的标题。 |
|
||||
| `SHOW_DEBUG_LOG` | `False` | 在浏览器控制台显示详细调试日志。 |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | 如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。 |
|
||||
|
||||
## 工作原理
|
||||
|
||||

|
||||
|
||||
1. **触发**:当对话达到 `MESSAGE_TRIGGER_COUNT`(例如 10、20 条消息)时。
|
||||
2. **分析**:插件将最近的对话 + 现有规则发送给 LLM。
|
||||
3. **综合**:LLM 将新见解与旧规则合并,移除过时的规则。
|
||||
4. **更新**:新的规则集替换文件夹系统提示词中的 `<!-- OWUI_PROJECT_RULES_START -->` 块。
|
||||
|
||||
## 路线图
|
||||
|
||||
查看 [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) 了解未来计划,包括“项目知识”收集功能。
|
||||
@@ -1,54 +0,0 @@
|
||||
# Gemini Manifold Companion
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.3.2</span>
|
||||
|
||||
Companion filter for the Gemini Manifold pipe plugin, providing enhanced functionality.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Gemini Manifold Companion works alongside the [Gemini Manifold Pipe](../pipes/gemini-manifold.md) to provide additional processing and enhancement for Gemini model integrations.
|
||||
|
||||
## Features
|
||||
|
||||
- :material-handshake: **Seamless Integration**: Works with Gemini Manifold pipe
|
||||
- :material-format-text: **Message Formatting**: Optimizes messages for Gemini
|
||||
- :material-shield: **Error Handling**: Graceful handling of API issues
|
||||
- :material-tune: **Fine-tuning**: Additional configuration options
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. First, install the [Gemini Manifold Pipe](../pipes/gemini-manifold.md)
|
||||
2. Download the companion filter: [`gemini_manifold_companion.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/gemini_manifold_companion)
|
||||
3. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
4. Enable the filter
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `auto_format` | boolean | `true` | Auto-format messages for Gemini |
|
||||
| `handle_errors` | boolean | `true` | Enable error handling |
|
||||
|
||||
---
|
||||
|
||||
## Requirements
|
||||
|
||||
!!! warning "Dependency"
|
||||
This filter requires the **Gemini Manifold Pipe** to be installed and configured.
|
||||
|
||||
!!! note "Prerequisites"
|
||||
- OpenWebUI v0.3.0 or later
|
||||
- Gemini Manifold Pipe installed
|
||||
|
||||
---
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/gemini_manifold_companion){ .md-button }
|
||||
@@ -1,54 +0,0 @@
|
||||
# Gemini Manifold Companion
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.3.2</span>
|
||||
|
||||
Gemini Manifold Pipe 的伴随过滤器,用于增强 Gemini 集成的处理效果。
|
||||
|
||||
---
|
||||
|
||||
## 概览
|
||||
|
||||
Gemini Manifold Companion 与 [Gemini Manifold Pipe](../pipes/gemini-manifold.md) 搭配使用,为 Gemini 模型集成提供额外的处理与优化。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-handshake: **无缝协同**:与 Gemini Manifold Pipe 配合工作
|
||||
- :material-format-text: **消息格式化**:针对 Gemini 优化消息
|
||||
- :material-shield: **错误处理**:更友好的 API 异常处理
|
||||
- :material-tune: **精细配置**:提供额外调优选项
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 先安装 [Gemini Manifold Pipe](../pipes/gemini-manifold.md)
|
||||
2. 下载伴随过滤器:[`gemini_manifold_companion.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/gemini_manifold_companion)
|
||||
3. 上传到 OpenWebUI:**Admin Panel** → **Settings** → **Functions**
|
||||
4. 启用过滤器
|
||||
|
||||
---
|
||||
|
||||
## 配置项
|
||||
|
||||
| 选项 | 类型 | 默认值 | 说明 |
|
||||
|--------|------|---------|-------------|
|
||||
| `auto_format` | boolean | `true` | 为 Gemini 自动格式化消息 |
|
||||
| `handle_errors` | boolean | `true` | 开启错误处理 |
|
||||
|
||||
---
|
||||
|
||||
## 运行要求
|
||||
|
||||
!!! warning "依赖"
|
||||
本过滤器需要先安装并配置 **Gemini Manifold Pipe**。
|
||||
|
||||
!!! note "前置条件"
|
||||
- OpenWebUI v0.3.0 及以上
|
||||
- 已安装 Gemini Manifold Pipe
|
||||
|
||||
---
|
||||
|
||||
## 源码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/gemini_manifold_companion){ .md-button }
|
||||
@@ -22,7 +22,7 @@ Filters act as middleware in the message pipeline:
|
||||
|
||||
Reduces token consumption in long conversations through intelligent summarization while maintaining coherence.
|
||||
|
||||
**Version:** 1.1.0
|
||||
**Version:** 1.2.2
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](async-context-compression.md)
|
||||
|
||||
@@ -36,15 +36,45 @@ Filters act as middleware in the message pipeline:
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](context-enhancement.md)
|
||||
|
||||
- :material-google:{ .lg .middle } **Gemini Manifold Companion**
|
||||
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||
|
||||
---
|
||||
|
||||
Companion filter for the Gemini Manifold pipe plugin.
|
||||
Automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||
|
||||
**Version:** 1.7.0
|
||||
**Version:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](gemini-manifold-companion.md)
|
||||
[:octicons-arrow-right-24: Documentation](folder-memory.md)
|
||||
|
||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||
|
||||
---
|
||||
|
||||
Fixes common Markdown formatting issues in LLM outputs, including Mermaid syntax, code blocks, and LaTeX formulas.
|
||||
|
||||
**Version:** 1.2.4
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](markdown_normalizer.md)
|
||||
|
||||
- :material-merge:{ .lg .middle } **Multi-Model Context Merger**
|
||||
|
||||
---
|
||||
|
||||
Automatically merges context from multiple model responses in the previous turn, enabling collaborative answers.
|
||||
|
||||
**Version:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](multi-model-context-merger.md)
|
||||
|
||||
- :material-file-document-multiple:{ .lg .middle } **Web Gemini Multimodal Filter**
|
||||
|
||||
---
|
||||
|
||||
A powerful filter that provides multimodal capabilities (PDF, Office, Images, Audio, Video) to any model in OpenWebUI.
|
||||
|
||||
**Version:** 0.3.2
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](web-gemini-multimodel.md)
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ Filter 充当消息管线中的中间件:
|
||||
|
||||
通过智能总结减少长对话的 token 消耗,同时保持连贯性。
|
||||
|
||||
**版本:** 1.1.0
|
||||
**版本:** 1.2.2
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](async-context-compression.md)
|
||||
|
||||
@@ -36,15 +36,25 @@ Filter 充当消息管线中的中间件:
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](context-enhancement.md)
|
||||
|
||||
- :material-google:{ .lg .middle } **Gemini Manifold Companion**
|
||||
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||
|
||||
---
|
||||
|
||||
Gemini Manifold Pipe 插件的伴随过滤器。
|
||||
自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||
|
||||
**版本:** 1.7.0
|
||||
**版本:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](gemini-manifold-companion.md)
|
||||
[:octicons-arrow-right-24: 查看文档](folder-memory.zh.md)
|
||||
|
||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||
|
||||
---
|
||||
|
||||
修复 LLM 输出中常见的 Markdown 格式问题,包括 Mermaid 语法、代码块和 LaTeX 公式。
|
||||
|
||||
**版本:** 1.2.4
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](markdown_normalizer.zh.md)
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
98
docs/plugins/filters/markdown_normalizer.md
Normal file
98
docs/plugins/filters/markdown_normalizer.md
Normal file
@@ -0,0 +1,98 @@
|
||||
# Markdown Normalizer Filter
|
||||
|
||||
A content normalizer filter for Open WebUI that fixes common Markdown formatting issues in LLM outputs. It ensures that code blocks, LaTeX formulas, Mermaid diagrams, and other Markdown elements are rendered correctly.
|
||||
|
||||
## Features
|
||||
|
||||
* **Details Tag Normalization**: Ensures proper spacing for `<details>` tags (used for thought chains). Adds a blank line after `</details>` and ensures a newline after self-closing `<details />` tags to prevent rendering issues.
|
||||
* **Emphasis Spacing Fix**: Fixes extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`) which can cause rendering failures. Includes safeguards to protect math expressions (e.g., `2 * 3 * 4`) and list variables.
|
||||
* **Mermaid Syntax Fix**: Automatically fixes common Mermaid syntax errors, such as unquoted node labels (including multi-line labels and citations) and unclosed subgraphs. **New in v1.1.2**: Comprehensive protection for edge labels (text on connecting lines) across all link types (solid, dotted, thick).
|
||||
* **Frontend Console Debugging**: Supports printing structured debug logs directly to the browser console (F12) for easier troubleshooting.
|
||||
* **Code Block Formatting**: Fixes broken code block prefixes, suffixes, and indentation.
|
||||
* **LaTeX Normalization**: Standardizes LaTeX formula delimiters (`\[` -> `$$`, `\(` -> `$`).
|
||||
* **Thought Tag Normalization**: Unifies thought tags (`<think>`, `<thinking>` -> `<thought>`).
|
||||
* **Escape Character Fix**: Cleans up excessive escape characters (`\\n`, `\\t`).
|
||||
* **List Formatting**: Ensures proper newlines in list items.
|
||||
* **Heading Fix**: Adds missing spaces in headings (`#Heading` -> `# Heading`).
|
||||
* **Table Fix**: Adds missing closing pipes in tables.
|
||||
* **XML Cleanup**: Removes leftover XML artifacts.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Install the plugin in Open WebUI.
|
||||
2. Enable the filter globally or for specific models.
|
||||
3. Configure the enabled fixes in the **Valves** settings.
|
||||
4. (Optional) **Show Debug Log** is enabled by default in Valves. This prints structured logs to the browser console (F12).
|
||||
> [!WARNING]
|
||||
> As this is an initial version, some "negative fixes" might occur (e.g., breaking valid Markdown). If you encounter issues, please check the console logs, copy the "Original" vs "Normalized" content, and submit an issue.
|
||||
|
||||
## Configuration (Valves)
|
||||
|
||||
* `priority`: Filter priority (default: 50).
|
||||
* `enable_escape_fix`: Fix excessive escape characters.
|
||||
* `enable_thought_tag_fix`: Normalize thought tags.
|
||||
* `enable_details_tag_fix`: Normalize details tags (default: True).
|
||||
* `enable_code_block_fix`: Fix code block formatting.
|
||||
* `enable_latex_fix`: Normalize LaTeX formulas.
|
||||
* `enable_list_fix`: Fix list item newlines (Experimental).
|
||||
* `enable_unclosed_block_fix`: Auto-close unclosed code blocks.
|
||||
* `enable_fullwidth_symbol_fix`: Fix full-width symbols in code blocks.
|
||||
* `enable_mermaid_fix`: Fix Mermaid syntax errors.
|
||||
* `enable_heading_fix`: Fix missing space in headings.
|
||||
* `enable_table_fix`: Fix missing closing pipe in tables.
|
||||
* `enable_xml_tag_cleanup`: Cleanup leftover XML tags.
|
||||
* `enable_emphasis_spacing_fix`: Fix extra spaces in emphasis (default: True).
|
||||
* `show_status`: Show status notification when fixes are applied.
|
||||
* `show_debug_log`: Print debug logs to browser console.
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
* **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## Changelog
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **Documentation Updates**: Synchronized version numbers across all documentation and code files.
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **List Marker Protection Enhancement**: Fixed a bug where list markers (`*`) followed by plain text and emphasis were having their spaces incorrectly stripped (e.g., `* U16 forward` became `*U16 forward`).
|
||||
* **Placeholder Support**: Confirmed that 4 or more underscores (e.g., `____`) are correctly treated as placeholders and not modified by the emphasis fix.
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **Code Block Indentation Fix**: Fixed an issue where code blocks nested inside lists were having their indentation incorrectly stripped. Now preserves proper indentation for nested code blocks.
|
||||
* **Underscore Emphasis Support**: Extended emphasis spacing fix to support `__` (double underscore for bold) and `___` (triple underscore for bold+italic) syntax.
|
||||
* **List Marker Protection**: Fixed a bug where list markers (`*`) followed by emphasis markers (`**`) were incorrectly merged (e.g., `* **Yes**` became `***Yes**`). Added safeguard to prevent this.
|
||||
* **Test Suite**: Added comprehensive pytest test suite with 56 test cases covering all major features.
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **Emphasis Spacing Fix**: Added a new fix for extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`).
|
||||
* Uses a recursive approach to handle nested emphasis (e.g., `**bold _italic _**`).
|
||||
* Includes safeguards to prevent modifying math expressions (e.g., `2 * 3 * 4`) or list variables.
|
||||
* Controlled by the `enable_emphasis_spacing_fix` valve (default: True).
|
||||
|
||||
### v1.2.0
|
||||
|
||||
* **Details Tag Support**: Added normalization for `<details>` tags.
|
||||
* Ensures a blank line is added after `</details>` closing tags to separate thought content from the main response.
|
||||
* Ensures a newline is added after self-closing `<details ... />` tags to prevent them from interfering with subsequent Markdown headings (e.g., fixing `<details/>#Heading`).
|
||||
* Includes safeguard to prevent modification of `<details>` tags inside code blocks.
|
||||
|
||||
### v1.1.2
|
||||
|
||||
* **Mermaid Edge Label Protection**: Implemented comprehensive protection for edge labels (text on connecting lines) to prevent them from being incorrectly modified. Now supports all Mermaid link types including solid (`--`), dotted (`-.`), and thick (`==`) lines with or without arrows.
|
||||
* **Bug Fixes**: Fixed an issue where lines without arrows (e.g., `A -- text --- B`) were not correctly protected.
|
||||
|
||||
### v1.1.0
|
||||
|
||||
* **Mermaid Fix Refinement**: Improved regex to handle nested parentheses in node labels (e.g., `ID("Label (text)")`) and avoided matching connection labels.
|
||||
* **HTML Safeguard Optimization**: Refined `_contains_html` to allow common tags like `<br/>`, `<b>`, `<i>`, etc., ensuring Mermaid diagrams with these tags are still normalized.
|
||||
* **Full-width Symbol Cleanup**: Fixed duplicate keys and incorrect quote mapping in `FULLWIDTH_MAP`.
|
||||
* **Bug Fixes**: Fixed missing `Dict` import in Python files.
|
||||
|
||||
## License
|
||||
|
||||
MIT
|
||||
98
docs/plugins/filters/markdown_normalizer.zh.md
Normal file
98
docs/plugins/filters/markdown_normalizer.zh.md
Normal file
@@ -0,0 +1,98 @@
|
||||
# Markdown 格式化过滤器 (Markdown Normalizer)
|
||||
|
||||
这是一个用于 Open WebUI 的内容格式化过滤器,旨在修复 LLM 输出中常见的 Markdown 格式问题。它能确保代码块、LaTeX 公式、Mermaid 图表和其他 Markdown 元素被正确渲染。
|
||||
|
||||
## 功能特性
|
||||
|
||||
* **Details 标签规范化**: 确保 `<details>` 标签(常用于思维链)有正确的间距。在 `</details>` 后添加空行,并在自闭合 `<details />` 标签后添加换行,防止渲染问题。
|
||||
* **强调空格修复**: 修复强调标记内部的多余空格(例如 `** 文本 **` -> `**文本**`),这会导致 Markdown 渲染失败。包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* **Mermaid 语法修复**: 自动修复常见的 Mermaid 语法错误,如未加引号的节点标签(支持多行标签和引用标记)和未闭合的子图 (Subgraph)。**v1.1.2 新增**: 全面保护各种类型的连线标签(实线、虚线、粗线),防止被误修改。
|
||||
* **前端控制台调试**: 支持将结构化的调试日志直接打印到浏览器控制台 (F12),方便排查问题。
|
||||
* **代码块格式化**: 修复破损的代码块前缀、后缀和缩进问题。
|
||||
* **LaTeX 规范化**: 标准化 LaTeX 公式定界符 (`\[` -> `$$`, `\(` -> `$`)。
|
||||
* **思维标签规范化**: 统一思维链标签 (`<think>`, `<thinking>` -> `<thought>`)。
|
||||
* **转义字符修复**: 清理过度的转义字符 (`\\n`, `\\t`)。
|
||||
* **列表格式化**: 确保列表项有正确的换行。
|
||||
* **标题修复**: 修复标题中缺失的空格 (`#标题` -> `# 标题`)。
|
||||
* **表格修复**: 修复表格中缺失的闭合管道符。
|
||||
* **XML 清理**: 移除残留的 XML 标签。
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在 Open WebUI 中安装此插件。
|
||||
2. 全局启用或为特定模型启用此过滤器。
|
||||
3. 在 **Valves** 设置中配置需要启用的修复项。
|
||||
4. (可选) **显示调试日志 (Show Debug Log)** 在 Valves 中默认开启。这会将结构化的日志打印到浏览器控制台 (F12)。
|
||||
> [!WARNING]
|
||||
> 由于这是初版,可能会出现“负向修复”的情况(例如破坏了原本正确的格式)。如果您遇到问题,请务必查看控制台日志,复制“原始 (Original)”与“规范化 (Normalized)”的内容对比,并提交 Issue 反馈。
|
||||
|
||||
## 配置项 (Valves)
|
||||
|
||||
* `priority`: 过滤器优先级 (默认: 50)。
|
||||
* `enable_escape_fix`: 修复过度的转义字符。
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_details_tag_fix`: 规范化 Details 标签 (默认: True)。
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: 规范化 LaTeX 公式。
|
||||
* `enable_list_fix`: 修复列表项换行 (实验性)。
|
||||
* `enable_unclosed_block_fix`: 自动闭合未闭合的代码块。
|
||||
* `enable_fullwidth_symbol_fix`: 修复代码块中的全角符号。
|
||||
* `enable_mermaid_fix`: 修复 Mermaid 语法错误。
|
||||
* `enable_heading_fix`: 修复标题中缺失的空格。
|
||||
* `enable_table_fix`: 修复表格中缺失的闭合管道符。
|
||||
* `enable_xml_tag_cleanup`: 清理残留的 XML 标签。
|
||||
* `enable_emphasis_spacing_fix`: 修复强调语法中的多余空格 (默认: True)。
|
||||
* `show_status`: 应用修复时显示状态通知。
|
||||
* `show_debug_log`: 在浏览器控制台打印调试日志。
|
||||
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
* **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## 更新日志
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **文档更新**: 同步了所有文档和代码文件的版本号。
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **列表标记保护增强**: 修复了列表标记 (`*`) 后跟普通文本和强调标记时,空格被错误剥离的问题(例如 `* U16 前锋` 变成 `*U16 前锋`)。
|
||||
* **占位符支持**: 确认 4 个或更多下划线(如 `____`)会被正确视为占位符,不会被强调修复逻辑修改。
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **代码块缩进修复**: 修复了列表中嵌套代码块的缩进被错误剥离的问题。现在会正确保留嵌套代码块的缩进。
|
||||
* **下划线强调语法支持**: 扩展强调空格修复以支持 `__` (双下划线加粗) 和 `___` (三下划线加粗斜体) 语法。
|
||||
* **列表标记保护**: 修复了列表标记 (`*`) 后跟强调标记 (`**`) 被错误合并的 Bug(例如 `* **是**` 变成 `***是**`)。添加了保护逻辑防止此问题。
|
||||
* **测试套件**: 新增完整的 pytest 测试套件,包含 56 个测试用例,覆盖所有主要功能。
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **强调空格修复**: 新增了对强调标记内部多余空格的修复(例如 `** 文本 **` -> `**文本**`)。
|
||||
* 采用递归方法处理嵌套强调(例如 `**加粗 _斜体 _**`)。
|
||||
* 包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* 通过 `enable_emphasis_spacing_fix` 开关控制(默认:开启)。
|
||||
|
||||
### v1.2.0
|
||||
|
||||
* **Details 标签支持**: 新增了对 `<details>` 标签的规范化支持。
|
||||
* 确保在 `</details>` 闭合标签后添加空行,将思维内容与正文分隔开。
|
||||
* 确保在自闭合 `<details ... />` 标签后添加换行,防止其干扰后续的 Markdown 标题(例如修复 `<details/>#标题`)。
|
||||
* 包含保护机制,防止修改代码块内部的 `<details>` 标签。
|
||||
|
||||
### v1.1.2
|
||||
|
||||
* **Mermaid 连线标签保护**: 实现了全面的连线标签保护机制,防止连接线上的文字被误修改。现在支持所有 Mermaid 连线类型,包括实线 (`--`)、虚线 (`-.`) 和粗线 (`==`),无论是否带有箭头。
|
||||
* **Bug 修复**: 修复了无箭头连线(如 `A -- text --- B`)未被正确保护的问题。
|
||||
|
||||
### v1.1.0
|
||||
|
||||
* **Mermaid 修复优化**: 改进了正则表达式以处理节点标签中的嵌套括号(如 `ID("标签 (文本)")`),并避免误匹配连接线上的文字。
|
||||
* **HTML 保护机制优化**: 优化了 `_contains_html` 检测,允许 `<br/>`, `<b>`, `<i>` 等常见标签,确保包含这些标签的 Mermaid 图表能被正常规范化。
|
||||
* **全角符号清理**: 修复了 `FULLWIDTH_MAP` 中的重复键名和错误的引号映射。
|
||||
* **Bug 修复**: 修复了 Python 文件中缺失的 `Dict` 类型导入。
|
||||
|
||||
## 许可证
|
||||
|
||||
MIT
|
||||
35
docs/plugins/filters/multi-model-context-merger.md
Normal file
35
docs/plugins/filters/multi-model-context-merger.md
Normal file
@@ -0,0 +1,35 @@
|
||||
# Multi-Model Context Merger
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
|
||||
Automatically merges context from multiple model responses in the previous turn, enabling collaborative answers.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
This filter detects when multiple models have responded in the previous turn (e.g., using "Arena" mode or multiple models selected). It consolidates these responses and injects them as context for the current turn, allowing the next model to see what others have said.
|
||||
|
||||
## Features
|
||||
|
||||
- :material-merge: **Auto-Merge**: Consolidates responses from multiple models into a single context block.
|
||||
- :material-format-list-group: **Structured Injection**: Uses XML-like tags (`<response>`) to separate different model outputs.
|
||||
- :material-robot-confused: **Collaboration**: Enables models to build upon or critique each other's answers.
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`multi_model_context_merger.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Enable the filter.
|
||||
|
||||
---
|
||||
|
||||
## Usage
|
||||
|
||||
1. Select **multiple models** in the chat (or use Arena mode).
|
||||
2. Ask a question. All models will respond.
|
||||
3. Ask a follow-up question.
|
||||
4. The filter will inject the previous responses from ALL models into the context of the current model(s).
|
||||
35
docs/plugins/filters/multi-model-context-merger.zh.md
Normal file
35
docs/plugins/filters/multi-model-context-merger.zh.md
Normal file
@@ -0,0 +1,35 @@
|
||||
# 多模型上下文合并 (Multi-Model Context Merger)
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.1.0</span>
|
||||
|
||||
自动合并上一轮中多个模型的回答上下文,实现协作问答。
|
||||
|
||||
---
|
||||
|
||||
## 概述
|
||||
|
||||
此过滤器检测上一轮是否由多个模型回复(例如使用“竞技场”模式或选择了多个模型)。它将这些回复合并并作为上下文注入到当前轮次,使下一个模型能够看到其他模型之前所说的内容。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-merge: **自动合并**: 将多个模型的回复合并为单个上下文块。
|
||||
- :material-format-list-group: **结构化注入**: 使用类似 XML 的标签 (`<response>`) 分隔不同模型的输出。
|
||||
- :material-robot-confused: **协作**: 允许模型基于彼此的回答进行构建或评论。
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件: [`multi_model_context_merger.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters)
|
||||
2. 上传到 OpenWebUI: **管理员面板** → **设置** → **函数**
|
||||
3. 启用过滤器。
|
||||
|
||||
---
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在聊天中选择 **多个模型** (或使用竞技场模式)。
|
||||
2. 提问。所有模型都会回答。
|
||||
3. 提出后续问题。
|
||||
4. 过滤器会将所有模型之前的回答注入到当前模型的上下文中。
|
||||
51
docs/plugins/filters/web-gemini-multimodel.md
Normal file
51
docs/plugins/filters/web-gemini-multimodel.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# Web Gemini Multimodal Filter
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.3.2</span>
|
||||
|
||||
A powerful filter that provides multimodal capabilities (PDF, Office, Images, Audio, Video) to any model in OpenWebUI.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
This plugin enables multimodal processing for any model by leveraging Gemini as an analyzer. It supports direct file processing for Gemini models and "Analyzer Mode" for other models (like DeepSeek, Llama), where Gemini analyzes the file and injects the result as context.
|
||||
|
||||
## Features
|
||||
|
||||
- :material-file-document-multiple: **Multimodal Support**: Process PDF, Word, Excel, PowerPoint, EPUB, MP3, MP4, and Images.
|
||||
- :material-router-network: **Smart Routing**:
|
||||
- **Direct Mode**: Files are passed directly to Gemini models.
|
||||
- **Analyzer Mode**: Files are analyzed by Gemini, and results are injected into the context for other models.
|
||||
- :material-history: **Persistent Context**: Maintains session history across multiple turns using OpenWebUI Chat ID.
|
||||
- :material-database-check: **Deduplication**: Automatically tracks analyzed file hashes to prevent redundant processing.
|
||||
- :material-subtitles: **Subtitle Enhancement**: Specialized mode for generating high-quality SRT subtitles from video/audio.
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`web_gemini_multimodel.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/web_gemini_multimodel_filter)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Configure the Gemini Adapter URL and other settings.
|
||||
4. Enable the filter globally or per chat.
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `gemini_adapter_url` | string | `http://...` | URL of the Gemini Adapter service |
|
||||
| `target_model_keyword` | string | `"webgemini"` | Keyword to identify Gemini models |
|
||||
| `mode` | string | `"auto"` | `auto`, `direct`, or `analyzer` |
|
||||
| `analyzer_base_model_id` | string | `"gemini-3.0-pro"` | Model used for document analysis |
|
||||
| `subtitle_keywords` | string | `"字幕,srt"` | Keywords to trigger subtitle flow |
|
||||
|
||||
---
|
||||
|
||||
## Usage
|
||||
|
||||
1. **Upload a file** (PDF, Image, Video, etc.) in the chat.
|
||||
2. **Ask a question** about the file.
|
||||
3. The plugin will automatically process the file and provide context to your selected model.
|
||||
51
docs/plugins/filters/web-gemini-multimodel.zh.md
Normal file
51
docs/plugins/filters/web-gemini-multimodel.zh.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# Web Gemini 多模态过滤器
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v0.3.2</span>
|
||||
|
||||
一个强大的过滤器,为 OpenWebUI 中的任何模型提供多模态能力:PDF、Office、图片、音频、视频等。
|
||||
|
||||
---
|
||||
|
||||
## 概述
|
||||
|
||||
此插件利用 Gemini 作为分析器,为任何模型提供多模态处理能力。它支持 Gemini 模型的直接文件处理,以及其他模型(如 DeepSeek, Llama)的“分析器模式”,即由 Gemini 分析文件并将结果注入上下文。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-file-document-multiple: **多模态支持**: 处理 PDF, Word, Excel, PowerPoint, EPUB, MP3, MP4 和图片。
|
||||
- :material-router-network: **智能路由**:
|
||||
- **直连模式 (Direct Mode)**: 对于 Gemini 模型,文件直接传递(原生多模态)。
|
||||
- **分析器模式 (Analyzer Mode)**: 对于非 Gemini 模型,文件由 Gemini 分析,结果注入为上下文。
|
||||
- :material-history: **持久上下文**: 利用 OpenWebUI 的 Chat ID 跨多轮对话维护会话历史。
|
||||
- :material-database-check: **数据库去重**: 自动记录已分析文件的哈希值,防止重复上传和分析。
|
||||
- :material-subtitles: **字幕增强**: 针对视频/音频上传的专用模式,生成高质量 SRT 字幕。
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件: [`web_gemini_multimodel.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/filters/web_gemini_multimodel_filter)
|
||||
2. 上传到 OpenWebUI: **管理员面板** → **设置** → **函数**
|
||||
3. 配置 Gemini Adapter URL 和其他设置。
|
||||
4. 启用过滤器。
|
||||
|
||||
---
|
||||
|
||||
## 配置
|
||||
|
||||
| 选项 | 类型 | 默认值 | 描述 |
|
||||
|------|------|--------|------|
|
||||
| `gemini_adapter_url` | string | `http://...` | Gemini Adapter 服务的 URL |
|
||||
| `target_model_keyword` | string | `"webgemini"` | 识别 Gemini 模型的关键字 |
|
||||
| `mode` | string | `"auto"` | `auto` (自动), `direct` (直连), 或 `analyzer` (分析器) |
|
||||
| `analyzer_base_model_id` | string | `"gemini-3.0-pro"` | 用于文档分析的模型 |
|
||||
| `subtitle_keywords` | string | `"字幕,srt"` | 触发字幕流程的关键字 |
|
||||
|
||||
---
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在聊天中 **上传文件** (PDF, 图片, 视频等)。
|
||||
2. 关于文件 **提问**。
|
||||
3. 插件会自动处理文件并为所选模型提供上下文。
|
||||
@@ -48,16 +48,15 @@ OpenWebUI supports four types of plugins, each serving a different purpose:
|
||||
|
||||
| Plugin | Type | Description | Version |
|
||||
|--------|------|-------------|---------|
|
||||
| [Smart Mind Map](actions/smart-mind-map.md) | Action | Generate interactive mind maps from text | 0.8.0 |
|
||||
| [Smart Infographic](actions/smart-infographic.md) | Action | Transform text into professional infographics | 1.0.0 |
|
||||
| [Knowledge Card](actions/knowledge-card.md) | Action | Create beautiful learning flashcards | 0.2.0 |
|
||||
| [Export to Excel](actions/export-to-excel.md) | Action | Export chat history to Excel files | 1.0.0 |
|
||||
| [Export to Word](actions/export-to-word.md) | Action | Export chat content to Word (.docx) with formatting | 0.1.0 |
|
||||
| [Summary](actions/summary.md) | Action | Text summarization tool | 1.0.0 |
|
||||
| [Async Context Compression](filters/async-context-compression.md) | Filter | Intelligent context compression | 1.0.0 |
|
||||
| [Context Enhancement](filters/context-enhancement.md) | Filter | Enhance chat context | 1.0.0 |
|
||||
| [Gemini Manifold Companion](filters/gemini-manifold-companion.md) | Filter | Companion for Gemini Manifold | 1.0.0 |
|
||||
| [Gemini Manifold](pipes/gemini-manifold.md) | Pipe | Gemini model integration | 1.0.0 |
|
||||
| [Smart Mind Map](actions/smart-mind-map.md) | Action | Generate interactive mind maps from text | 0.9.1 |
|
||||
| [Smart Infographic](actions/smart-infographic.md) | Action | Transform text into professional infographics | 1.4.9 |
|
||||
| [Flash Card](actions/flash-card.md) | Action | Create beautiful learning flashcards | 0.2.4 |
|
||||
| [Export to Excel](actions/export-to-excel.md) | Action | Export chat history to Excel files | 0.3.7 |
|
||||
| [Export to Word](actions/export-to-word.md) | Action | Export chat content to Word (.docx) with formatting | 0.4.3 |
|
||||
| [Async Context Compression](filters/async-context-compression.md) | Filter | Intelligent context compression | 1.1.3 |
|
||||
| [Context Enhancement](filters/context-enhancement.md) | Filter | Enhance chat context | 0.3.0 |
|
||||
| [Multi-Model Context Merger](filters/multi-model-context-merger.md) | Filter | Merge context from multiple models | 0.1.0 |
|
||||
| [Web Gemini Multimodal Filter](filters/web-gemini-multimodel.md) | Filter | Multimodal capabilities for any model | 0.3.2 |
|
||||
| [MoE Prompt Refiner](pipelines/moe-prompt-refiner.md) | Pipeline | Multi-model prompt refinement | 1.0.0 |
|
||||
|
||||
---
|
||||
|
||||
@@ -48,16 +48,15 @@ OpenWebUI 支持四种类型的插件,每种都有不同的用途:
|
||||
|
||||
| 插件 | 类型 | 描述 | 版本 |
|
||||
|--------|------|-------------|---------|
|
||||
| [Smart Mind Map(智能思维导图)](actions/smart-mind-map.md) | Action | 从文本生成交互式思维导图 | 0.8.0 |
|
||||
| [Smart Infographic(智能信息图)](actions/smart-infographic.md) | Action | 将文本转成专业信息图 | 1.0.0 |
|
||||
| [Knowledge Card(知识卡片)](actions/knowledge-card.md) | Action | 生成精美学习卡片 | 0.2.0 |
|
||||
| [Export to Excel(导出到 Excel)](actions/export-to-excel.md) | Action | 导出聊天记录为 Excel | 1.0.0 |
|
||||
| [Export to Word(导出为 Word)](actions/export-to-word.md) | Action | 将聊天内容导出为 Word (.docx) 并保留格式 | 0.1.0 |
|
||||
| [Summary(摘要)](actions/summary.md) | Action | 文本摘要工具 | 1.0.0 |
|
||||
| [Async Context Compression(异步上下文压缩)](filters/async-context-compression.md) | Filter | 智能上下文压缩 | 1.0.0 |
|
||||
| [Context Enhancement(上下文增强)](filters/context-enhancement.md) | Filter | 提升对话上下文 | 1.0.0 |
|
||||
| [Gemini Manifold Companion](filters/gemini-manifold-companion.md) | Filter | Gemini Manifold 伴侣 | 1.0.0 |
|
||||
| [Gemini Manifold](pipes/gemini-manifold.md) | Pipe | Gemini 模型集成 | 1.0.0 |
|
||||
| [Smart Mind Map(智能思维导图)](actions/smart-mind-map.md) | Action | 从文本生成交互式思维导图 | 0.9.1 |
|
||||
| [Smart Infographic(智能信息图)](actions/smart-infographic.md) | Action | 将文本转成专业信息图 | 1.4.9 |
|
||||
| [Flash Card(闪记卡)](actions/flash-card.md) | Action | 生成精美学习卡片 | 0.2.4 |
|
||||
| [Export to Excel(导出到 Excel)](actions/export-to-excel.md) | Action | 导出聊天记录为 Excel | 0.3.7 |
|
||||
| [Export to Word(导出为 Word)](actions/export-to-word.md) | Action | 将聊天内容导出为 Word (.docx) 并保留格式 | 0.4.3 |
|
||||
| [Async Context Compression(异步上下文压缩)](filters/async-context-compression.md) | Filter | 智能上下文压缩 | 1.1.3 |
|
||||
| [Context Enhancement(上下文增强)](filters/context-enhancement.md) | Filter | 提升对话上下文 | 0.3.0 |
|
||||
| [Multi-Model Context Merger(多模型上下文合并)](filters/multi-model-context-merger.md) | Filter | 合并多个模型的上下文 | 0.1.0 |
|
||||
| [Web Gemini Multimodal Filter(Web Gemini 多模态过滤器)](filters/web-gemini-multimodel.md) | Filter | 为任何模型提供多模态能力 | 0.3.2 |
|
||||
| [MoE Prompt Refiner](pipelines/moe-prompt-refiner.md) | Pipeline | 多模型提示词优化 | 1.0.0 |
|
||||
|
||||
---
|
||||
|
||||
@@ -1,106 +0,0 @@
|
||||
# Gemini Manifold
|
||||
|
||||
<span class="category-badge pipe">Pipe</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
|
||||
Integration pipeline for Google's Gemini models with full streaming support.
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Gemini Manifold pipe provides seamless integration with Google's Gemini AI models. It exposes Gemini models as selectable options in OpenWebUI, allowing you to use them just like any other model.
|
||||
|
||||
## Features
|
||||
|
||||
- :material-google: **Full Gemini Support**: Access all Gemini model variants
|
||||
- :material-stream: **Streaming**: Real-time response streaming
|
||||
- :material-image: **Multimodal**: Support for images and text
|
||||
- :material-shield: **Error Handling**: Robust error management
|
||||
- :material-tune: **Configurable**: Customize model parameters
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the plugin file: [`gemini_manifold.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/pipes/gemini_mainfold)
|
||||
2. Upload to OpenWebUI: **Admin Panel** → **Settings** → **Functions**
|
||||
3. Configure your Gemini API key
|
||||
4. Select Gemini models from the model dropdown
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
| Option | Type | Required | Description |
|
||||
|--------|------|----------|-------------|
|
||||
| `GEMINI_API_KEY` | string | Yes | Your Google AI Studio API key |
|
||||
| `DEFAULT_MODEL` | string | No | Default Gemini model to use |
|
||||
| `TEMPERATURE` | float | No | Response temperature (0-1) |
|
||||
| `MAX_TOKENS` | integer | No | Maximum response tokens |
|
||||
|
||||
---
|
||||
|
||||
## Available Models
|
||||
|
||||
When configured, the following models become available:
|
||||
|
||||
- `gemini-pro` - Text-only model
|
||||
- `gemini-pro-vision` - Multimodal model
|
||||
- `gemini-1.5-pro` - Latest Pro model
|
||||
- `gemini-1.5-flash` - Fast response model
|
||||
|
||||
---
|
||||
|
||||
## Usage
|
||||
|
||||
1. After installation, go to any chat
|
||||
2. Open the model selector dropdown
|
||||
3. Look for models prefixed with your pipe name
|
||||
4. Select a Gemini model
|
||||
5. Start chatting!
|
||||
|
||||
---
|
||||
|
||||
## Getting an API Key
|
||||
|
||||
1. Visit [Google AI Studio](https://makersuite.google.com/app/apikey)
|
||||
2. Create a new API key
|
||||
3. Copy the key and paste it in the plugin configuration
|
||||
|
||||
!!! warning "API Key Security"
|
||||
Keep your API key secure. Never share it publicly or commit it to version control.
|
||||
|
||||
---
|
||||
|
||||
## Companion Filter
|
||||
|
||||
For enhanced functionality, consider installing the [Gemini Manifold Companion](../filters/gemini-manifold-companion.md) filter.
|
||||
|
||||
---
|
||||
|
||||
## Requirements
|
||||
|
||||
!!! note "Prerequisites"
|
||||
- OpenWebUI v0.3.0 or later
|
||||
- Valid Gemini API key
|
||||
- Internet access to Google AI APIs
|
||||
|
||||
---
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
??? question "Models not appearing?"
|
||||
Ensure your API key is correctly configured and the plugin is enabled.
|
||||
|
||||
??? question "API errors?"
|
||||
Check your API key validity and quota limits in Google AI Studio.
|
||||
|
||||
??? question "Slow responses?"
|
||||
Consider using `gemini-1.5-flash` for faster response times.
|
||||
|
||||
---
|
||||
|
||||
## Source Code
|
||||
|
||||
[:fontawesome-brands-github: View on GitHub](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/pipes/gemini_mainfold){ .md-button }
|
||||
@@ -1,106 +0,0 @@
|
||||
# Gemini Manifold
|
||||
|
||||
<span class="category-badge pipe">Pipe</span>
|
||||
<span class="version-badge">v1.0.0</span>
|
||||
|
||||
面向 Google Gemini 模型的集成流水线,支持完整流式返回。
|
||||
|
||||
---
|
||||
|
||||
## 概览
|
||||
|
||||
Gemini Manifold Pipe 提供与 Google Gemini AI 模型的无缝集成。它会将 Gemini 模型作为可选项暴露在 OpenWebUI 中,你可以像使用其他模型一样使用它们。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- :material-google: **完整 Gemini 支持**:可使用所有 Gemini 模型变体
|
||||
- :material-stream: **流式输出**:实时流式响应
|
||||
- :material-image: **多模态**:支持图像与文本
|
||||
- :material-shield: **错误处理**:健壮的错误管理
|
||||
- :material-tune: **可配置**:可自定义模型参数
|
||||
|
||||
---
|
||||
|
||||
## 安装
|
||||
|
||||
1. 下载插件文件:[`gemini_manifold.py`](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/pipes/gemini_mainfold)
|
||||
2. 上传到 OpenWebUI:**Admin Panel** → **Settings** → **Functions**
|
||||
3. 配置你的 Gemini API Key
|
||||
4. 在模型下拉中选择 Gemini 模型
|
||||
|
||||
---
|
||||
|
||||
## 配置
|
||||
|
||||
| 选项 | 类型 | 是否必填 | 说明 |
|
||||
|--------|------|----------|-------------|
|
||||
| `GEMINI_API_KEY` | string | 是 | 你的 Google AI Studio API Key |
|
||||
| `DEFAULT_MODEL` | string | 否 | 默认使用的 Gemini 模型 |
|
||||
| `TEMPERATURE` | float | 否 | 输出温度(0-1) |
|
||||
| `MAX_TOKENS` | integer | 否 | 最大回复 token 数 |
|
||||
|
||||
---
|
||||
|
||||
## 可用模型
|
||||
|
||||
配置完成后,你可以选择以下模型:
|
||||
|
||||
- `gemini-pro` —— 纯文本模型
|
||||
- `gemini-pro-vision` —— 多模态模型
|
||||
- `gemini-1.5-pro` —— 最新 Pro 模型
|
||||
- `gemini-1.5-flash` —— 快速响应模型
|
||||
|
||||
---
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 安装后进入任意对话
|
||||
2. 打开模型选择下拉
|
||||
3. 查找以 Pipe 名称前缀的模型
|
||||
4. 选择 Gemini 模型
|
||||
5. 开始聊天!
|
||||
|
||||
---
|
||||
|
||||
## 获取 API Key
|
||||
|
||||
1. 访问 [Google AI Studio](https://makersuite.google.com/app/apikey)
|
||||
2. 创建新的 API Key
|
||||
3. 复制并粘贴到插件配置中
|
||||
|
||||
!!! warning "API Key 安全"
|
||||
请妥善保管你的 API Key,不要公开或提交到版本库。
|
||||
|
||||
---
|
||||
|
||||
## 伴随过滤器
|
||||
|
||||
如需增强功能,可安装 [Gemini Manifold Companion](../filters/gemini-manifold-companion.md) 过滤器。
|
||||
|
||||
---
|
||||
|
||||
## 运行要求
|
||||
|
||||
!!! note "前置条件"
|
||||
- OpenWebUI v0.3.0 及以上
|
||||
- 有效的 Gemini API Key
|
||||
- 可访问 Google AI API 的网络
|
||||
|
||||
---
|
||||
|
||||
## 常见问题
|
||||
|
||||
??? question "模型没有出现?"
|
||||
请确认 API Key 配置正确且插件已启用。
|
||||
|
||||
??? question "出现 API 错误?"
|
||||
检查 Google AI Studio 中的 Key 有效性和额度限制。
|
||||
|
||||
??? question "响应较慢?"
|
||||
可尝试使用 `gemini-1.5-flash` 获得更快速度。
|
||||
|
||||
---
|
||||
|
||||
## 源码
|
||||
|
||||
[:fontawesome-brands-github: 在 GitHub 查看](https://github.com/Fu-Jie/awesome-openwebui/tree/main/plugins/pipes/gemini_mainfold){ .md-button }
|
||||
84
docs/plugins/pipes/github-copilot-sdk.md
Normal file
84
docs/plugins/pipes/github-copilot-sdk.md
Normal file
@@ -0,0 +1,84 @@
|
||||
# GitHub Copilot SDK Pipe for OpenWebUI
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
This is an advanced Pipe function for [OpenWebUI](https://github.com/open-webui/open-webui) that allows you to use GitHub Copilot models (such as `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`) directly within OpenWebUI. It is built upon the official [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk), providing a native integration experience.
|
||||
|
||||
## 🚀 What's New (v0.1.0)
|
||||
|
||||
* **♾️ Infinite Sessions**: Automatic context compaction for long-running conversations. No more context limit errors!
|
||||
* **🧠 Thinking Process**: Real-time display of model reasoning/thinking process (for supported models).
|
||||
* **📂 Workspace Control**: Restricted workspace directory for secure file operations.
|
||||
* **🔍 Model Filtering**: Exclude specific models using keywords (e.g., `codex`, `haiku`).
|
||||
* **💾 Session Persistence**: Improved session resume logic using OpenWebUI chat ID mapping.
|
||||
|
||||
## ✨ Core Features
|
||||
|
||||
* **🚀 Official SDK Integration**: Built on the official SDK for stability and reliability.
|
||||
* **💬 Multi-turn Conversation**: Automatically concatenates history context so Copilot understands your previous messages.
|
||||
* **🌊 Streaming Output**: Supports typewriter effect for fast responses.
|
||||
* **🖼️ Multimodal Support**: Supports image uploads, automatically converting them to attachments for Copilot (requires model support).
|
||||
* **🛠️ Zero-config Installation**: Automatically detects and downloads the GitHub Copilot CLI, ready to use out of the box.
|
||||
* **🔑 Secure Authentication**: Supports Fine-grained Personal Access Tokens for minimized permissions.
|
||||
* **🐛 Debug Mode**: Built-in detailed log output for easy connection troubleshooting.
|
||||
|
||||
## 📦 Installation & Usage
|
||||
|
||||
### 1. Import Function
|
||||
|
||||
1. Open OpenWebUI.
|
||||
2. Go to **Workspace** -> **Functions**.
|
||||
3. Click **+** (Create Function).
|
||||
4. Paste the content of `github_copilot_sdk.py` (or `github_copilot_sdk_cn.py` for Chinese) completely.
|
||||
5. Save.
|
||||
|
||||
### 2. Configure Valves (Settings)
|
||||
|
||||
Find "GitHub Copilot" in the function list and click the **⚙️ (Valves)** icon to configure:
|
||||
|
||||
| Parameter | Description | Default |
|
||||
| :--- | :--- | :--- |
|
||||
| **GH_TOKEN** | **(Required)** Your GitHub Token. | - |
|
||||
| **MODEL_ID** | The model name to use. Recommended `gpt-5-mini` or `gpt-5`. | `gpt-5-mini` |
|
||||
| **CLI_PATH** | Path to the Copilot CLI. Will download automatically if not found. | `/usr/local/bin/copilot` |
|
||||
| **DEBUG** | Whether to enable debug logs (output to chat). | `True` |
|
||||
| **SHOW_THINKING** | Show model reasoning/thinking process. | `True` |
|
||||
| **EXCLUDE_KEYWORDS** | Exclude models containing these keywords (comma separated). | - |
|
||||
| **WORKSPACE_DIR** | Restricted workspace directory for file operations. | - |
|
||||
| **INFINITE_SESSION** | Enable Infinite Sessions (automatic context compaction). | `True` |
|
||||
| **COMPACTION_THRESHOLD** | Background compaction threshold (0.0-1.0). | `0.8` |
|
||||
| **BUFFER_THRESHOLD** | Buffer exhaustion threshold (0.0-1.0). | `0.95` |
|
||||
|
||||
### 3. Get GH_TOKEN
|
||||
|
||||
For security, it is recommended to use a **Fine-grained Personal Access Token**:
|
||||
|
||||
1. Visit [GitHub Token Settings](https://github.com/settings/tokens?type=beta).
|
||||
2. Click **Generate new token**.
|
||||
3. **Repository access**: Select `All repositories` or `Public Repositories`.
|
||||
4. **Permissions**:
|
||||
* Click **Account permissions**.
|
||||
* Find **Copilot Requests**, select **Read and write** (or Access).
|
||||
5. Generate and copy the Token.
|
||||
|
||||
## 📋 Dependencies
|
||||
|
||||
This Pipe will automatically attempt to install the following dependencies:
|
||||
|
||||
* `github-copilot-sdk` (Python package)
|
||||
* `github-copilot-cli` (Binary file, installed via official script)
|
||||
|
||||
## ⚠️ FAQ
|
||||
|
||||
* **Stuck on "Waiting..."**:
|
||||
* Check if `GH_TOKEN` is correct and has `Copilot Requests` permission.
|
||||
* Try changing `MODEL_ID` to `gpt-4o` or `copilot-chat`.
|
||||
* **Images not recognized**:
|
||||
* Ensure `MODEL_ID` is a model that supports multimodal input.
|
||||
* **CLI Installation Failed**:
|
||||
* Ensure the OpenWebUI container has internet access.
|
||||
* You can manually download the CLI and specify `CLI_PATH` in Valves.
|
||||
|
||||
## 📄 License
|
||||
|
||||
MIT
|
||||
84
docs/plugins/pipes/github-copilot-sdk.zh.md
Normal file
84
docs/plugins/pipes/github-copilot-sdk.zh.md
Normal file
@@ -0,0 +1,84 @@
|
||||
# GitHub Copilot SDK 官方管道
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
这是一个用于 [OpenWebUI](https://github.com/open-webui/open-webui) 的高级 Pipe 函数,允许你直接在 OpenWebUI 中使用 GitHub Copilot 模型(如 `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`)。它基于官方 [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk) 构建,提供了原生级的集成体验。
|
||||
|
||||
## 🚀 最新特性 (v0.1.0)
|
||||
|
||||
* **♾️ 无限会话 (Infinite Sessions)**:支持长对话的自动上下文压缩,告别上下文超限错误!
|
||||
* **🧠 思考过程展示**:实时显示模型的推理/思考过程(需模型支持)。
|
||||
* **📂 工作目录控制**:支持设置受限工作目录,确保文件操作安全。
|
||||
* **🔍 模型过滤**:支持通过关键词排除特定模型(如 `codex`, `haiku`)。
|
||||
* **💾 会话持久化**: 改进的会话恢复逻辑,直接关联 OpenWebUI 聊天 ID,连接更稳定。
|
||||
|
||||
## ✨ 核心特性
|
||||
|
||||
* **🚀 官方 SDK 集成**:基于官方 SDK,稳定可靠。
|
||||
* **💬 多轮对话支持**:自动拼接历史上下文,Copilot 能理解你的前文。
|
||||
* **🌊 流式输出 (Streaming)**:支持打字机效果,响应迅速。
|
||||
* **🖼️ 多模态支持**:支持上传图片,自动转换为附件发送给 Copilot(需模型支持)。
|
||||
* **🛠️ 零配置安装**:自动检测并下载 GitHub Copilot CLI,开箱即用。
|
||||
* **🔑 安全认证**:支持 Fine-grained Personal Access Tokens,权限最小化。
|
||||
* **🐛 调试模式**:内置详细的日志输出,方便排查连接问题。
|
||||
|
||||
## 📦 安装与使用
|
||||
|
||||
### 1. 导入函数
|
||||
|
||||
1. 打开 OpenWebUI。
|
||||
2. 进入 **Workspace** -> **Functions**。
|
||||
3. 点击 **+** (创建函数)。
|
||||
4. 将 `github_copilot_sdk_cn.py` 的内容完整粘贴进去。
|
||||
5. 保存。
|
||||
|
||||
### 2. 配置 Valves (设置)
|
||||
|
||||
在函数列表中找到 "GitHub Copilot",点击 **⚙️ (Valves)** 图标进行配置:
|
||||
|
||||
| 参数 | 说明 | 默认值 |
|
||||
| :--- | :--- | :--- |
|
||||
| **GH_TOKEN** | **(必填)** 你的 GitHub Token。 | - |
|
||||
| **MODEL_ID** | 使用的模型名称。推荐 `gpt-5-mini` 或 `gpt-5`。 | `gpt-5-mini` |
|
||||
| **CLI_PATH** | Copilot CLI 的路径。如果未找到会自动下载。 | `/usr/local/bin/copilot` |
|
||||
| **DEBUG** | 是否开启调试日志(输出到对话框)。 | `True` |
|
||||
| **SHOW_THINKING** | 是否显示模型推理/思考过程。 | `True` |
|
||||
| **EXCLUDE_KEYWORDS** | 排除包含这些关键词的模型 (逗号分隔)。 | - |
|
||||
| **WORKSPACE_DIR** | 文件操作的受限工作目录。 | - |
|
||||
| **INFINITE_SESSION** | 启用无限会话 (自动上下文压缩)。 | `True` |
|
||||
| **COMPACTION_THRESHOLD** | 后台压缩阈值 (0.0-1.0)。 | `0.8` |
|
||||
| **BUFFER_THRESHOLD** | 缓冲耗尽阈值 (0.0-1.0)。 | `0.95` |
|
||||
|
||||
### 3. 获取 GH_TOKEN
|
||||
|
||||
为了安全起见,推荐使用 **Fine-grained Personal Access Token**:
|
||||
|
||||
1. 访问 [GitHub Token Settings](https://github.com/settings/tokens?type=beta)。
|
||||
2. 点击 **Generate new token**。
|
||||
3. **Repository access**: 选择 `All repositories` 或 `Public Repositories`。
|
||||
4. **Permissions**:
|
||||
* 点击 **Account permissions**。
|
||||
* 找到 **Copilot Requests**,选择 **Read and write** (或 Access)。
|
||||
5. 生成并复制 Token。
|
||||
|
||||
## 📋 依赖说明
|
||||
|
||||
该 Pipe 会自动尝试安装以下依赖(如果环境中缺失):
|
||||
|
||||
* `github-copilot-sdk` (Python 包)
|
||||
* `github-copilot-cli` (二进制文件,通过官方脚本安装)
|
||||
|
||||
## ⚠️ 常见问题
|
||||
|
||||
* **一直显示 "Waiting..."**:
|
||||
* 检查 `GH_TOKEN` 是否正确且拥有 `Copilot Requests` 权限。
|
||||
* 尝试将 `MODEL_ID` 改为 `gpt-4o` 或 `copilot-chat`。
|
||||
* **图片无法识别**:
|
||||
* 确保 `MODEL_ID` 是支持多模态的模型。
|
||||
* **CLI 安装失败**:
|
||||
* 确保 OpenWebUI 容器有外网访问权限。
|
||||
* 你可以手动下载 CLI 并挂载到容器中,然后在 Valves 中指定 `CLI_PATH`。
|
||||
|
||||
## 📄 许可证
|
||||
|
||||
MIT
|
||||
@@ -15,19 +15,7 @@ Pipes allow you to:
|
||||
|
||||
## Available Pipe Plugins
|
||||
|
||||
<div class="grid cards" markdown>
|
||||
|
||||
- :material-google:{ .lg .middle } **Gemini Manifold**
|
||||
|
||||
---
|
||||
|
||||
Integration pipeline for Google's Gemini models with full streaming support.
|
||||
|
||||
**Version:** 1.0.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](gemini-manifold.md)
|
||||
|
||||
</div>
|
||||
- [GitHub Copilot SDK](github-copilot-sdk.md) (v0.1.1) - Official GitHub Copilot SDK integration. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -15,19 +15,7 @@ Pipes 可以用于:
|
||||
|
||||
## 可用的 Pipe 插件
|
||||
|
||||
<div class="grid cards" markdown>
|
||||
|
||||
- :material-google:{ .lg .middle } **Gemini Manifold**
|
||||
|
||||
---
|
||||
|
||||
面向 Google Gemini 的集成流水线,支持完整流式返回。
|
||||
|
||||
**版本:** 1.0.0
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](gemini-manifold.md)
|
||||
|
||||
</div>
|
||||
- [GitHub Copilot SDK](github-copilot-sdk.zh.md) (v0.1.1) - GitHub Copilot SDK 官方集成。支持动态模型、多轮对话、流式输出、图片输入及无限会话。
|
||||
|
||||
---
|
||||
|
||||
|
||||
13
mkdocs.yml
13
mkdocs.yml
@@ -97,14 +97,14 @@ plugins:
|
||||
Documentation Guide: 文档编写指南
|
||||
Smart Mind Map: 智能思维导图
|
||||
Smart Infographic: 智能信息图
|
||||
Knowledge Card: 知识卡片
|
||||
Flash Card: 闪记卡
|
||||
Export to Excel: 导出到 Excel
|
||||
Export to Word: 导出为 Word
|
||||
Summary: 摘要
|
||||
Async Context Compression: 异步上下文压缩
|
||||
Context Enhancement: 上下文增强
|
||||
Gemini Manifold Companion: Gemini Manifold 伴侣
|
||||
Gemini Manifold: Gemini Manifold
|
||||
Multi-Model Context Merger: 多模型上下文合并
|
||||
Web Gemini Multimodal Filter: Web Gemini 多模态过滤器
|
||||
MoE Prompt Refiner: MoE 提示词优化器
|
||||
- minify:
|
||||
minify_html: true
|
||||
@@ -184,18 +184,17 @@ nav:
|
||||
- plugins/actions/index.md
|
||||
- Smart Mind Map: plugins/actions/smart-mind-map.md
|
||||
- Smart Infographic: plugins/actions/smart-infographic.md
|
||||
- Knowledge Card: plugins/actions/knowledge-card.md
|
||||
- Flash Card: plugins/actions/flash-card.md
|
||||
- Export to Excel: plugins/actions/export-to-excel.md
|
||||
- Export to Word: plugins/actions/export-to-word.md
|
||||
- Summary: plugins/actions/summary.md
|
||||
- Filters:
|
||||
- plugins/filters/index.md
|
||||
- Async Context Compression: plugins/filters/async-context-compression.md
|
||||
- Context Enhancement: plugins/filters/context-enhancement.md
|
||||
- Gemini Manifold Companion: plugins/filters/gemini-manifold-companion.md
|
||||
- Multi-Model Context Merger: plugins/filters/multi-model-context-merger.md
|
||||
- Web Gemini Multimodal Filter: plugins/filters/web-gemini-multimodel.md
|
||||
- Pipes:
|
||||
- plugins/pipes/index.md
|
||||
- Gemini Manifold: plugins/pipes/gemini-manifold.md
|
||||
- Pipelines:
|
||||
- plugins/pipelines/index.md
|
||||
- MoE Prompt Refiner: plugins/pipelines/moe-prompt-refiner.md
|
||||
|
||||
@@ -124,10 +124,6 @@ Each plugin should include:
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## License
|
||||
|
||||
MIT License
|
||||
|
||||
---
|
||||
|
||||
> **Note**: For detailed information about each plugin type, see the respective README files in each plugin type directory.
|
||||
|
||||
@@ -124,10 +124,6 @@ plugins/
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## 许可证
|
||||
|
||||
MIT License
|
||||
|
||||
---
|
||||
|
||||
> **注意**:有关每种插件类型的详细信息,请参阅每个插件类型目录中的相应 README 文件。
|
||||
|
||||
@@ -315,7 +315,7 @@ class Action:
|
||||
if role == "user"
|
||||
else "Assistant" if role == "assistant" else role
|
||||
)
|
||||
aggregated_parts.append(f"[{role_label} Message {i}]\n{text_content}")
|
||||
aggregated_parts.append(f"{text_content}")
|
||||
|
||||
if not aggregated_parts:
|
||||
return body # Or handle error
|
||||
|
||||
@@ -326,7 +326,7 @@ class Action:
|
||||
if role == "user"
|
||||
else "助手" if role == "assistant" else role
|
||||
)
|
||||
aggregated_parts.append(f"[{role_label} 消息 {i}]\n{text_content}")
|
||||
aggregated_parts.append(f"{text_content}")
|
||||
|
||||
if not aggregated_parts:
|
||||
return body # 或者处理错误
|
||||
|
||||
@@ -230,7 +230,3 @@ except Exception as e:
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## License
|
||||
|
||||
MIT License
|
||||
|
||||
@@ -229,7 +229,3 @@ except Exception as e:
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## 许可证
|
||||
|
||||
MIT License
|
||||
|
||||
90
plugins/actions/deep-dive/README.md
Normal file
90
plugins/actions/deep-dive/README.md
Normal file
@@ -0,0 +1,90 @@
|
||||
# 🌊 Deep Dive
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.0.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.
|
||||
|
||||
## 🔥 What's New in v1.0.0
|
||||
|
||||
- ✨ **Thinking Chain Structure**: Moves from surface understanding to deep strategic action.
|
||||
- 🔍 **Phase 01: The Context**: Panoramic view of the situation and background.
|
||||
- 🧠 **Phase 02: The Logic**: Deconstruction of the underlying reasoning and mental models.
|
||||
- 💎 **Phase 03: The Insight**: Extraction of non-obvious value and hidden implications.
|
||||
- 🚀 **Phase 04: The Path**: Definition of specific, prioritized strategic directions.
|
||||
- 🎨 **Premium UI**: Modern, process-oriented design with a "Thinking Line" timeline.
|
||||
- 🌗 **Theme Adaptive**: Automatically adapts to OpenWebUI's light/dark theme.
|
||||
|
||||
## ✨ Key Features
|
||||
|
||||
- 🌊 **Deep Thinking**: Not just a summary, but a full deconstruction of content.
|
||||
- 🧠 **Logical Analysis**: Reveals how arguments are built and identifies hidden assumptions.
|
||||
- 💎 **Value Extraction**: Finds the "Aha!" moments and blind spots.
|
||||
- 🚀 **Action Oriented**: Translates deep understanding into immediate, actionable steps.
|
||||
- 🌍 **Multi-language**: Automatically adapts to the user's preferred language.
|
||||
- 🌗 **Theme Support**: Seamlessly switches between light and dark themes based on OpenWebUI settings.
|
||||
|
||||
## 🚀 How to Use
|
||||
|
||||
1. **Input Content**: Provide any text, article, or meeting notes in the chat.
|
||||
2. **Trigger Deep Dive**: Click the **Deep Dive** action button.
|
||||
3. **Explore the Chain**: Follow the visual timeline from Context to Path.
|
||||
|
||||
## ⚙️ Configuration (Valves)
|
||||
|
||||
| Parameter | Default | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| **Show Status (SHOW_STATUS)** | `True` | Whether to show status updates during the thinking process. |
|
||||
| **Model ID (MODEL_ID)** | `Empty` | LLM model for analysis. Empty = use current model. |
|
||||
| **Min Text Length (MIN_TEXT_LENGTH)** | `200` | Minimum characters required for a meaningful deep dive. |
|
||||
| **Clear Previous HTML (CLEAR_PREVIOUS_HTML)** | `True` | Whether to clear previous plugin results. |
|
||||
| **Message Count (MESSAGE_COUNT)** | `1` | Number of recent messages to analyze. |
|
||||
|
||||
## 🌗 Theme Support
|
||||
|
||||
The plugin automatically detects and adapts to OpenWebUI's theme settings:
|
||||
|
||||
- **Detection Priority**:
|
||||
1. Parent document `<meta name="theme-color">` tag
|
||||
2. Parent document `html/body` class or `data-theme` attribute
|
||||
3. System preference via `prefers-color-scheme: dark`
|
||||
|
||||
- **Requirements**: For best results, enable **iframe Sandbox Allow Same Origin** in OpenWebUI:
|
||||
- Go to **Settings** → **Interface** → **Artifacts** → Check **iframe Sandbox Allow Same Origin**
|
||||
|
||||
## 🎨 Visual Preview
|
||||
|
||||
The plugin generates a structured thinking timeline:
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────┐
|
||||
│ 🌊 Deep Dive Analysis │
|
||||
│ 👤 User 📅 Date 📊 Word count │
|
||||
├─────────────────────────────────────┤
|
||||
│ 🔍 Phase 01: The Context │
|
||||
│ [High-level panoramic view] │
|
||||
│ │
|
||||
│ 🧠 Phase 02: The Logic │
|
||||
│ • Reasoning structure... │
|
||||
│ • Hidden assumptions... │
|
||||
│ │
|
||||
│ 💎 Phase 03: The Insight │
|
||||
│ • Non-obvious value... │
|
||||
│ • Blind spots revealed... │
|
||||
│ │
|
||||
│ 🚀 Phase 04: The Path │
|
||||
│ ▸ Priority Action 1... │
|
||||
│ ▸ Priority Action 2... │
|
||||
└─────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## 📂 Files
|
||||
|
||||
- `deep_dive.py` - English version
|
||||
- `deep_dive_cn.py` - Chinese version (精读)
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
- **Plugin not working?**: Check if the filter/action is enabled in the model settings.
|
||||
- **Debug Logs**: Enable `SHOW_STATUS` in Valves to see progress updates.
|
||||
- **Error Messages**: If you see an error, please copy the full error message and report it.
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
90
plugins/actions/deep-dive/README_CN.md
Normal file
90
plugins/actions/deep-dive/README_CN.md
Normal file
@@ -0,0 +1,90 @@
|
||||
# 📖 精读
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.0.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。
|
||||
|
||||
## 🔥 v1.0.0 更新内容
|
||||
|
||||
- ✨ **思维链结构**: 从表面理解一步步深入到战略行动。
|
||||
- 🔍 **阶段 01: 全景 (The Context)**: 提供情境与背景的高层级全景视图。
|
||||
- 🧠 **阶段 02: 脉络 (The Logic)**: 解构底层推理逻辑与思维模型。
|
||||
- 💎 **阶段 03: 洞察 (The Insight)**: 提取非显性价值与隐藏的深层含义。
|
||||
- 🚀 **阶段 04: 路径 (The Path)**: 定义具体的、按优先级排列的战略方向。
|
||||
- 🎨 **高端 UI**: 现代化的过程导向设计,带有"思维导火索"时间轴。
|
||||
- 🌗 **主题自适应**: 自动适配 OpenWebUI 的深色/浅色主题。
|
||||
|
||||
## ✨ 核心特性
|
||||
|
||||
- 📖 **深度思考**: 不仅仅是摘要,而是对内容的全面解构。
|
||||
- 🧠 **逻辑分析**: 揭示论点是如何构建的,识别隐藏的假设。
|
||||
- 💎 **价值提取**: 发现"原来如此"的时刻与思维盲点。
|
||||
- 🚀 **行动导向**: 将深度理解转化为立即、可执行的步骤。
|
||||
- 🌍 **多语言支持**: 自动适配用户的偏好语言。
|
||||
- 🌗 **主题支持**: 根据 OpenWebUI 设置自动切换深色/浅色主题。
|
||||
|
||||
## 🚀 如何使用
|
||||
|
||||
1. **输入内容**: 在聊天中提供任何文本、文章或会议记录。
|
||||
2. **触发精读**: 点击 **精读** 操作按钮。
|
||||
3. **探索思维链**: 沿着视觉时间轴从"全景"探索到"路径"。
|
||||
|
||||
## ⚙️ 配置参数 (Valves)
|
||||
|
||||
| 参数 | 默认值 | 描述 |
|
||||
| :--- | :--- | :--- |
|
||||
| **显示状态 (SHOW_STATUS)** | `True` | 是否在思维过程中显示状态更新。 |
|
||||
| **模型 ID (MODEL_ID)** | `空` | 用于分析的 LLM 模型。留空 = 使用当前模型。 |
|
||||
| **最小文本长度 (MIN_TEXT_LENGTH)** | `200` | 进行有意义的精读所需的最小字符数。 |
|
||||
| **清除旧 HTML (CLEAR_PREVIOUS_HTML)** | `True` | 是否清除之前的插件结果。 |
|
||||
| **消息数量 (MESSAGE_COUNT)** | `1` | 要分析的最近消息数量。 |
|
||||
|
||||
## 🌗 主题支持
|
||||
|
||||
插件会自动检测并适配 OpenWebUI 的主题设置:
|
||||
|
||||
- **检测优先级**:
|
||||
1. 父文档 `<meta name="theme-color">` 标签
|
||||
2. 父文档 `html/body` 的 class 或 `data-theme` 属性
|
||||
3. 系统偏好 `prefers-color-scheme: dark`
|
||||
|
||||
- **环境要求**: 为获得最佳效果,请在 OpenWebUI 中启用 **iframe Sandbox Allow Same Origin**:
|
||||
- 进入 **设置** → **界面** → **Artifacts** → 勾选 **iframe Sandbox Allow Same Origin**
|
||||
|
||||
## 🎨 视觉预览
|
||||
|
||||
插件生成结构化的思维时间轴:
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────┐
|
||||
│ 📖 精读分析报告 │
|
||||
│ 👤 用户 📅 日期 📊 字数 │
|
||||
├─────────────────────────────────────┤
|
||||
│ 🔍 阶段 01: 全景 (The Context) │
|
||||
│ [高层级全景视图内容] │
|
||||
│ │
|
||||
│ 🧠 阶段 02: 脉络 (The Logic) │
|
||||
│ • 推理结构分析... │
|
||||
│ • 隐藏假设识别... │
|
||||
│ │
|
||||
│ 💎 阶段 03: 洞察 (The Insight) │
|
||||
│ • 非显性价值提取... │
|
||||
│ • 思维盲点揭示... │
|
||||
│ │
|
||||
│ 🚀 阶段 04: 路径 (The Path) │
|
||||
│ ▸ 优先级行动 1... │
|
||||
│ ▸ 优先级行动 2... │
|
||||
└─────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## 📂 文件说明
|
||||
|
||||
- `deep_dive.py` - 英文版 (Deep Dive)
|
||||
- `deep_dive_cn.py` - 中文版 (精读)
|
||||
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
- **插件不工作?**: 请检查是否在模型设置中启用了该过滤器/动作。
|
||||
- **调试日志**: 在 Valves 中启用 `SHOW_STATUS` 以查看进度更新。
|
||||
- **错误信息**: 如果看到错误,请复制完整的错误信息并报告。
|
||||
- **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
BIN
plugins/actions/deep-dive/deep_dive.png
Normal file
BIN
plugins/actions/deep-dive/deep_dive.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 783 KiB |
944
plugins/actions/deep-dive/deep_dive.py
Normal file
944
plugins/actions/deep-dive/deep_dive.py
Normal file
@@ -0,0 +1,944 @@
|
||||
"""
|
||||
title: Deep Dive
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 1.0.0
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwYXRoIGQ9Ik0xMiA3djE0Ii8+PHBhdGggZD0iTTMgMThhMSAxIDAgMCAxLTEtMVY0YTEgMSAwIDAgMSAxLTFoNWE0IDQgMCAwIDEgNCA0IDQgNCAwIDAgMSA0LTRoNWExIDEgMCAwIDEgMSAxdjEzYTEgMSAwIDAgMS0xIDFoLTZhMyAzIDAgMCAwLTMgMyAzIDMgMCAwIDAtMy0zeiIvPjxwYXRoIGQ9Ik02IDEyaDIiLz48cGF0aCBkPSJNMTYgMTJoMiIvPjwvc3ZnPg==
|
||||
requirements: markdown
|
||||
description: A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.
|
||||
"""
|
||||
|
||||
# Standard library imports
|
||||
import re
|
||||
import logging
|
||||
from typing import Optional, Dict, Any, Callable, Awaitable
|
||||
from datetime import datetime
|
||||
|
||||
# Third-party imports
|
||||
from pydantic import BaseModel, Field
|
||||
from fastapi import Request
|
||||
import markdown
|
||||
|
||||
# OpenWebUI imports
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from open_webui.models.users import Users
|
||||
|
||||
# Logging setup
|
||||
logging.basicConfig(
|
||||
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# =================================================================
|
||||
# HTML Template - Process-Oriented Design with Theme Support
|
||||
# =================================================================
|
||||
HTML_WRAPPER_TEMPLATE = """
|
||||
<!-- OPENWEBUI_PLUGIN_OUTPUT -->
|
||||
<!DOCTYPE html>
|
||||
<html lang="{user_language}">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<style>
|
||||
:root {
|
||||
--dd-bg-primary: #ffffff;
|
||||
--dd-bg-secondary: #f8fafc;
|
||||
--dd-bg-tertiary: #f1f5f9;
|
||||
--dd-text-primary: #0f172a;
|
||||
--dd-text-secondary: #334155;
|
||||
--dd-text-dim: #64748b;
|
||||
--dd-border: #e2e8f0;
|
||||
--dd-accent: #3b82f6;
|
||||
--dd-accent-soft: #eff6ff;
|
||||
--dd-header-gradient: linear-gradient(135deg, #1e293b 0%, #0f172a 100%);
|
||||
--dd-shadow: 0 10px 40px rgba(0,0,0,0.06);
|
||||
--dd-code-bg: #f1f5f9;
|
||||
}
|
||||
.theme-dark {
|
||||
--dd-bg-primary: #1e293b;
|
||||
--dd-bg-secondary: #0f172a;
|
||||
--dd-bg-tertiary: #334155;
|
||||
--dd-text-primary: #f1f5f9;
|
||||
--dd-text-secondary: #e2e8f0;
|
||||
--dd-text-dim: #94a3b8;
|
||||
--dd-border: #475569;
|
||||
--dd-accent: #60a5fa;
|
||||
--dd-accent-soft: rgba(59, 130, 246, 0.15);
|
||||
--dd-header-gradient: linear-gradient(135deg, #0f172a 0%, #1e1e2e 100%);
|
||||
--dd-shadow: 0 10px 40px rgba(0,0,0,0.3);
|
||||
--dd-code-bg: #334155;
|
||||
}
|
||||
body {
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif;
|
||||
margin: 0;
|
||||
padding: 10px;
|
||||
background-color: transparent;
|
||||
}
|
||||
#main-container {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 24px;
|
||||
width: 100%;
|
||||
max-width: 900px;
|
||||
margin: 0 auto;
|
||||
}
|
||||
.plugin-item {
|
||||
background: var(--dd-bg-primary);
|
||||
border-radius: 24px;
|
||||
box-shadow: var(--dd-shadow);
|
||||
overflow: hidden;
|
||||
border: 1px solid var(--dd-border);
|
||||
}
|
||||
/* STYLES_INSERTION_POINT */
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div id="main-container">
|
||||
<!-- CONTENT_INSERTION_POINT -->
|
||||
</div>
|
||||
<!-- SCRIPTS_INSERTION_POINT -->
|
||||
<script>
|
||||
(function() {
|
||||
const parseColorLuma = (colorStr) => {
|
||||
if (!colorStr) return null;
|
||||
let m = colorStr.match(/^#?([0-9a-f]{6})$/i);
|
||||
if (m) {
|
||||
const hex = m[1];
|
||||
const r = parseInt(hex.slice(0, 2), 16);
|
||||
const g = parseInt(hex.slice(2, 4), 16);
|
||||
const b = parseInt(hex.slice(4, 6), 16);
|
||||
return (0.2126 * r + 0.7152 * g + 0.0722 * b) / 255;
|
||||
}
|
||||
m = colorStr.match(/rgba?\\s*\\(\\s*(\\d+)\\s*,\\s*(\\d+)\\s*,\\s*(\\d+)/i);
|
||||
if (m) {
|
||||
const r = parseInt(m[1], 10);
|
||||
const g = parseInt(m[2], 10);
|
||||
const b = parseInt(m[3], 10);
|
||||
return (0.2126 * r + 0.7152 * g + 0.0722 * b) / 255;
|
||||
}
|
||||
return null;
|
||||
};
|
||||
const getThemeFromMeta = (doc) => {
|
||||
const metas = Array.from((doc || document).querySelectorAll('meta[name="theme-color"]'));
|
||||
if (!metas.length) return null;
|
||||
const color = metas[metas.length - 1].content.trim();
|
||||
const luma = parseColorLuma(color);
|
||||
if (luma === null) return null;
|
||||
return luma < 0.5 ? 'dark' : 'light';
|
||||
};
|
||||
const getParentDocumentSafe = () => {
|
||||
try {
|
||||
if (!window.parent || window.parent === window) return null;
|
||||
const pDoc = window.parent.document;
|
||||
void pDoc.title;
|
||||
return pDoc;
|
||||
} catch (err) { return null; }
|
||||
};
|
||||
const getThemeFromParentClass = () => {
|
||||
try {
|
||||
if (!window.parent || window.parent === window) return null;
|
||||
const pDoc = window.parent.document;
|
||||
const html = pDoc.documentElement;
|
||||
const body = pDoc.body;
|
||||
const htmlClass = html ? html.className : '';
|
||||
const bodyClass = body ? body.className : '';
|
||||
const htmlDataTheme = html ? html.getAttribute('data-theme') : '';
|
||||
if (htmlDataTheme === 'dark' || bodyClass.includes('dark') || htmlClass.includes('dark')) return 'dark';
|
||||
if (htmlDataTheme === 'light' || bodyClass.includes('light') || htmlClass.includes('light')) return 'light';
|
||||
return null;
|
||||
} catch (err) { return null; }
|
||||
};
|
||||
const setTheme = () => {
|
||||
const parentDoc = getParentDocumentSafe();
|
||||
const metaTheme = parentDoc ? getThemeFromMeta(parentDoc) : null;
|
||||
const parentClassTheme = getThemeFromParentClass();
|
||||
const prefersDark = window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches;
|
||||
const chosen = metaTheme || parentClassTheme || (prefersDark ? 'dark' : 'light');
|
||||
document.documentElement.classList.toggle('theme-dark', chosen === 'dark');
|
||||
};
|
||||
setTheme();
|
||||
if (window.matchMedia) {
|
||||
window.matchMedia('(prefers-color-scheme: dark)').addEventListener('change', setTheme);
|
||||
}
|
||||
})();
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
# =================================================================
|
||||
# LLM Prompts - Deep Dive Thinking Chain
|
||||
# =================================================================
|
||||
|
||||
SYSTEM_PROMPT = """
|
||||
You are a Deep Dive Analyst. Your goal is to guide the user through a comprehensive thinking process, moving from surface understanding to deep strategic action.
|
||||
|
||||
## Thinking Structure (STRICT)
|
||||
|
||||
You MUST analyze the input across these four specific dimensions:
|
||||
|
||||
### 1. 🔍 The Context (What?)
|
||||
Provide a high-level panoramic view. What is this content about? What is the core situation, background, or problem being addressed? (2-3 paragraphs)
|
||||
|
||||
### 2. 🧠 The Logic (Why?)
|
||||
Deconstruct the underlying structure. How is the argument built? What is the reasoning, the hidden assumptions, or the mental models at play? (Bullet points)
|
||||
|
||||
### 3. 💎 The Insight (So What?)
|
||||
Extract the non-obvious value. What are the "Aha!" moments? What are the implications, the blind spots, or the unique perspectives revealed? (Bullet points)
|
||||
|
||||
### 4. 🚀 The Path (Now What?)
|
||||
Define the strategic direction. What are the specific, prioritized next steps? How can this knowledge be applied immediately? (Actionable steps)
|
||||
|
||||
## Rules
|
||||
- Output in the user's specified language.
|
||||
- Maintain a professional, analytical, yet inspiring tone.
|
||||
- Focus on the *process* of understanding, not just the result.
|
||||
- No greetings or meta-commentary.
|
||||
"""
|
||||
|
||||
USER_PROMPT = """
|
||||
Initiate a Deep Dive into the following content:
|
||||
|
||||
**User Context:**
|
||||
- User: {user_name}
|
||||
- Time: {current_date_time_str}
|
||||
- Language: {user_language}
|
||||
|
||||
**Content to Analyze:**
|
||||
```
|
||||
{long_text_content}
|
||||
```
|
||||
|
||||
Please execute the full thinking chain: Context → Logic → Insight → Path.
|
||||
"""
|
||||
|
||||
# =================================================================
|
||||
# Premium CSS Design - Deep Dive Theme
|
||||
# =================================================================
|
||||
|
||||
CSS_TEMPLATE = """
|
||||
.deep-dive {
|
||||
font-family: 'Inter', -apple-system, system-ui, sans-serif;
|
||||
color: var(--dd-text-secondary);
|
||||
}
|
||||
|
||||
.dd-header {
|
||||
background: var(--dd-header-gradient);
|
||||
padding: 40px 32px;
|
||||
color: white;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.dd-header-badge {
|
||||
display: inline-block;
|
||||
padding: 4px 12px;
|
||||
background: rgba(255,255,255,0.1);
|
||||
border: 1px solid rgba(255,255,255,0.2);
|
||||
border-radius: 100px;
|
||||
font-size: 0.75rem;
|
||||
font-weight: 600;
|
||||
letter-spacing: 0.05em;
|
||||
text-transform: uppercase;
|
||||
margin-bottom: 16px;
|
||||
}
|
||||
|
||||
.dd-title {
|
||||
font-size: 2rem;
|
||||
font-weight: 800;
|
||||
margin: 0 0 12px 0;
|
||||
letter-spacing: -0.02em;
|
||||
}
|
||||
|
||||
.dd-meta {
|
||||
display: flex;
|
||||
gap: 20px;
|
||||
font-size: 0.85rem;
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.dd-body {
|
||||
padding: 32px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 40px;
|
||||
position: relative;
|
||||
background: var(--dd-bg-primary);
|
||||
}
|
||||
|
||||
/* The Thinking Line */
|
||||
.dd-body::before {
|
||||
content: '';
|
||||
position: absolute;
|
||||
left: 52px;
|
||||
top: 40px;
|
||||
bottom: 40px;
|
||||
width: 2px;
|
||||
background: var(--dd-border);
|
||||
z-index: 0;
|
||||
}
|
||||
|
||||
.dd-step {
|
||||
position: relative;
|
||||
z-index: 1;
|
||||
display: flex;
|
||||
gap: 24px;
|
||||
}
|
||||
|
||||
.dd-step-icon {
|
||||
flex-shrink: 0;
|
||||
width: 40px;
|
||||
height: 40px;
|
||||
background: var(--dd-bg-primary);
|
||||
border: 2px solid var(--dd-border);
|
||||
border-radius: 12px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
font-size: 1.25rem;
|
||||
box-shadow: 0 4px 12px rgba(0,0,0,0.03);
|
||||
transition: all 0.3s ease;
|
||||
}
|
||||
|
||||
.dd-step:hover .dd-step-icon {
|
||||
border-color: var(--dd-accent);
|
||||
transform: scale(1.1);
|
||||
}
|
||||
|
||||
.dd-step-content {
|
||||
flex: 1;
|
||||
}
|
||||
|
||||
.dd-step-label {
|
||||
font-size: 0.75rem;
|
||||
font-weight: 700;
|
||||
color: var(--dd-accent);
|
||||
text-transform: uppercase;
|
||||
letter-spacing: 0.1em;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.dd-step-title {
|
||||
font-size: 1.25rem;
|
||||
font-weight: 700;
|
||||
color: var(--dd-text-primary);
|
||||
margin: 0 0 16px 0;
|
||||
}
|
||||
|
||||
.dd-text {
|
||||
line-height: 1.7;
|
||||
font-size: 1rem;
|
||||
}
|
||||
|
||||
.dd-text p { margin-bottom: 16px; }
|
||||
.dd-text p:last-child { margin-bottom: 0; }
|
||||
|
||||
.dd-list {
|
||||
list-style: none;
|
||||
padding: 0;
|
||||
margin: 0;
|
||||
display: grid;
|
||||
gap: 12px;
|
||||
}
|
||||
|
||||
.dd-list-item {
|
||||
background: var(--dd-bg-secondary);
|
||||
padding: 16px 20px;
|
||||
border-radius: 12px;
|
||||
border-left: 4px solid var(--dd-border);
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.dd-list-item:hover {
|
||||
background: var(--dd-bg-tertiary);
|
||||
border-left-color: var(--dd-accent);
|
||||
transform: translateX(4px);
|
||||
}
|
||||
|
||||
.dd-list-item strong {
|
||||
color: var(--dd-text-primary);
|
||||
display: block;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.dd-path-item {
|
||||
background: var(--dd-accent-soft);
|
||||
border-left-color: var(--dd-accent);
|
||||
}
|
||||
|
||||
.dd-footer {
|
||||
padding: 24px 32px;
|
||||
background: var(--dd-bg-secondary);
|
||||
border-top: 1px solid var(--dd-border);
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
font-size: 0.8rem;
|
||||
color: var(--dd-text-dim);
|
||||
}
|
||||
|
||||
.dd-tag {
|
||||
padding: 2px 8px;
|
||||
background: var(--dd-bg-tertiary);
|
||||
border-radius: 4px;
|
||||
font-weight: 600;
|
||||
}
|
||||
|
||||
.dd-text code,
|
||||
.dd-list-item code {
|
||||
background: var(--dd-code-bg);
|
||||
color: var(--dd-text-primary);
|
||||
padding: 2px 6px;
|
||||
border-radius: 4px;
|
||||
font-family: 'SF Mono', 'Consolas', 'Monaco', monospace;
|
||||
font-size: 0.85em;
|
||||
}
|
||||
|
||||
.dd-list-item em {
|
||||
font-style: italic;
|
||||
color: var(--dd-text-dim);
|
||||
}
|
||||
"""
|
||||
|
||||
CONTENT_TEMPLATE = """
|
||||
<div class="deep-dive">
|
||||
<div class="dd-header">
|
||||
<div class="dd-header-badge">Thinking Process</div>
|
||||
<h1 class="dd-title">Deep Dive Analysis</h1>
|
||||
<div class="dd-meta">
|
||||
<span>👤 {user_name}</span>
|
||||
<span>📅 {current_date_time_str}</span>
|
||||
<span>📊 {word_count} words</span>
|
||||
</div>
|
||||
</div>
|
||||
<div class="dd-body">
|
||||
<!-- Step 1: Context -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🔍</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 01</div>
|
||||
<h2 class="dd-step-title">The Context</h2>
|
||||
<div class="dd-text">{context_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Step 2: Logic -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🧠</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 02</div>
|
||||
<h2 class="dd-step-title">The Logic</h2>
|
||||
<div class="dd-text">{logic_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Step 3: Insight -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">💎</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 03</div>
|
||||
<h2 class="dd-step-title">The Insight</h2>
|
||||
<div class="dd-text">{insight_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Step 4: Path -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🚀</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 04</div>
|
||||
<h2 class="dd-step-title">The Path</h2>
|
||||
<div class="dd-text">{path_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="dd-footer">
|
||||
<span>Deep Dive Engine v1.0</span>
|
||||
<span><span class="dd-tag">AI-Powered</span></span>
|
||||
</div>
|
||||
</div>
|
||||
"""
|
||||
|
||||
|
||||
class Action:
|
||||
class Valves(BaseModel):
|
||||
SHOW_STATUS: bool = Field(
|
||||
default=True,
|
||||
description="Whether to show operation status updates.",
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False,
|
||||
description="Whether to print debug logs in the browser console.",
|
||||
)
|
||||
MODEL_ID: str = Field(
|
||||
default="",
|
||||
description="LLM Model ID for analysis. Empty = use current model.",
|
||||
)
|
||||
MIN_TEXT_LENGTH: int = Field(
|
||||
default=200,
|
||||
description="Minimum text length for deep dive (chars).",
|
||||
)
|
||||
CLEAR_PREVIOUS_HTML: bool = Field(
|
||||
default=True,
|
||||
description="Whether to clear previous plugin results.",
|
||||
)
|
||||
MESSAGE_COUNT: int = Field(
|
||||
default=1,
|
||||
description="Number of recent messages to analyze.",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
|
||||
def _get_user_context(self, __user__: Optional[Dict[str, Any]]) -> Dict[str, str]:
|
||||
"""Safely extracts user context information."""
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_data = __user__[0] if __user__ else {}
|
||||
elif isinstance(__user__, dict):
|
||||
user_data = __user__
|
||||
else:
|
||||
user_data = {}
|
||||
|
||||
return {
|
||||
"user_id": user_data.get("id", "unknown_user"),
|
||||
"user_name": user_data.get("name", "User"),
|
||||
"user_language": user_data.get("language", "en-US"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""
|
||||
Unified extraction of chat context information (chat_id, message_id).
|
||||
Prioritizes extraction from body, then metadata.
|
||||
"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
# 1. Try to get from body
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # message_id is usually 'id' in body
|
||||
|
||||
# Check body.metadata as fallback
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
# 2. Try to get from __metadata__ (as supplement)
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
def _process_llm_output(self, llm_output: str) -> Dict[str, str]:
|
||||
"""Parse LLM output and convert to styled HTML."""
|
||||
# Extract sections using flexible regex
|
||||
context_match = re.search(
|
||||
r"###\s*1\.\s*🔍?\s*The Context\s*\((.*?)\)\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
logic_match = re.search(
|
||||
r"###\s*2\.\s*🧠?\s*The Logic\s*\((.*?)\)\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
insight_match = re.search(
|
||||
r"###\s*3\.\s*💎?\s*The Insight\s*\((.*?)\)\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
path_match = re.search(
|
||||
r"###\s*4\.\s*🚀?\s*The Path\s*\((.*?)\)\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
|
||||
# Fallback if numbering is different
|
||||
if not context_match:
|
||||
context_match = re.search(
|
||||
r"###\s*🔍?\s*The Context.*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not logic_match:
|
||||
logic_match = re.search(
|
||||
r"###\s*🧠?\s*The Logic.*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not insight_match:
|
||||
insight_match = re.search(
|
||||
r"###\s*💎?\s*The Insight.*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not path_match:
|
||||
path_match = re.search(
|
||||
r"###\s*🚀?\s*The Path.*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
|
||||
context_md = (
|
||||
context_match.group(1 if context_match.lastindex == 1 else 2).strip()
|
||||
if context_match
|
||||
else ""
|
||||
)
|
||||
logic_md = (
|
||||
logic_match.group(1 if logic_match.lastindex == 1 else 2).strip()
|
||||
if logic_match
|
||||
else ""
|
||||
)
|
||||
insight_md = (
|
||||
insight_match.group(1 if insight_match.lastindex == 1 else 2).strip()
|
||||
if insight_match
|
||||
else ""
|
||||
)
|
||||
path_md = (
|
||||
path_match.group(1 if path_match.lastindex == 1 else 2).strip()
|
||||
if path_match
|
||||
else ""
|
||||
)
|
||||
|
||||
if not any([context_md, logic_md, insight_md, path_md]):
|
||||
context_md = llm_output.strip()
|
||||
logger.warning("LLM output did not follow format. Using as context.")
|
||||
|
||||
md_extensions = ["nl2br"]
|
||||
|
||||
context_html = (
|
||||
markdown.markdown(context_md, extensions=md_extensions)
|
||||
if context_md
|
||||
else '<p class="dd-no-content">No context extracted.</p>'
|
||||
)
|
||||
logic_html = (
|
||||
self._process_list_items(logic_md, "logic")
|
||||
if logic_md
|
||||
else '<p class="dd-no-content">No logic deconstructed.</p>'
|
||||
)
|
||||
insight_html = (
|
||||
self._process_list_items(insight_md, "insight")
|
||||
if insight_md
|
||||
else '<p class="dd-no-content">No insights found.</p>'
|
||||
)
|
||||
path_html = (
|
||||
self._process_list_items(path_md, "path")
|
||||
if path_md
|
||||
else '<p class="dd-no-content">No path defined.</p>'
|
||||
)
|
||||
|
||||
return {
|
||||
"context_html": context_html,
|
||||
"logic_html": logic_html,
|
||||
"insight_html": insight_html,
|
||||
"path_html": path_html,
|
||||
}
|
||||
|
||||
def _process_list_items(self, md_content: str, section_type: str) -> str:
|
||||
"""Convert markdown list to styled HTML cards with full markdown support."""
|
||||
lines = md_content.strip().split("\n")
|
||||
items = []
|
||||
current_paragraph = []
|
||||
|
||||
for line in lines:
|
||||
line = line.strip()
|
||||
|
||||
# Check for list item (bullet or numbered)
|
||||
bullet_match = re.match(r"^[-*]\s+(.+)$", line)
|
||||
numbered_match = re.match(r"^\d+\.\s+(.+)$", line)
|
||||
|
||||
if bullet_match or numbered_match:
|
||||
# Flush any accumulated paragraph
|
||||
if current_paragraph:
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
current_paragraph = []
|
||||
|
||||
# Extract the list item content
|
||||
text = (
|
||||
bullet_match.group(1) if bullet_match else numbered_match.group(1)
|
||||
)
|
||||
|
||||
# Handle bold title pattern: **Title:** Description or **Title**: Description
|
||||
title_match = re.match(r"\*\*(.+?)\*\*[:\s]*(.*)$", text)
|
||||
if title_match:
|
||||
title = self._convert_inline_markdown(title_match.group(1))
|
||||
desc = self._convert_inline_markdown(title_match.group(2).strip())
|
||||
path_class = "dd-path-item" if section_type == "path" else ""
|
||||
item_html = f'<div class="dd-list-item {path_class}"><strong>{title}</strong>{desc}</div>'
|
||||
else:
|
||||
text_html = self._convert_inline_markdown(text)
|
||||
path_class = "dd-path-item" if section_type == "path" else ""
|
||||
item_html = (
|
||||
f'<div class="dd-list-item {path_class}">{text_html}</div>'
|
||||
)
|
||||
items.append(item_html)
|
||||
elif line and not line.startswith("#"):
|
||||
# Accumulate paragraph text
|
||||
current_paragraph.append(line)
|
||||
elif not line and current_paragraph:
|
||||
# Empty line ends paragraph
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
current_paragraph = []
|
||||
|
||||
# Flush remaining paragraph
|
||||
if current_paragraph:
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
|
||||
if items:
|
||||
return f'<div class="dd-list">{" ".join(items)}</div>'
|
||||
return f'<p class="dd-no-content">No items found.</p>'
|
||||
|
||||
def _convert_inline_markdown(self, text: str) -> str:
|
||||
"""Convert inline markdown (bold, italic, code) to HTML."""
|
||||
# Convert inline code: `code` -> <code>code</code>
|
||||
text = re.sub(r"`([^`]+)`", r"<code>\1</code>", text)
|
||||
# Convert bold: **text** -> <strong>text</strong>
|
||||
text = re.sub(r"\*\*(.+?)\*\*", r"<strong>\1</strong>", text)
|
||||
# Convert italic: *text* -> <em>text</em> (but not inside **)
|
||||
text = re.sub(r"(?<!\*)\*([^*]+)\*(?!\*)", r"<em>\1</em>", text)
|
||||
return text
|
||||
|
||||
async def _emit_status(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
description: str,
|
||||
done: bool = False,
|
||||
):
|
||||
"""Emits a status update event."""
|
||||
if self.valves.SHOW_STATUS and emitter:
|
||||
await emitter(
|
||||
{"type": "status", "data": {"description": description, "done": done}}
|
||||
)
|
||||
|
||||
async def _emit_notification(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
content: str,
|
||||
ntype: str = "info",
|
||||
):
|
||||
"""Emits a notification event."""
|
||||
if emitter:
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": ntype, "content": content}}
|
||||
)
|
||||
|
||||
async def _emit_debug_log(self, emitter, title: str, data: dict):
|
||||
"""Print structured debug logs in the browser console"""
|
||||
if not self.valves.SHOW_DEBUG_LOG or not emitter:
|
||||
return
|
||||
|
||||
try:
|
||||
import json
|
||||
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
await emitter({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
|
||||
def _remove_existing_html(self, content: str) -> str:
|
||||
"""Removes existing plugin-generated HTML."""
|
||||
pattern = r"```html\s*<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?```"
|
||||
return re.sub(pattern, "", content).strip()
|
||||
|
||||
def _extract_text_content(self, content) -> str:
|
||||
"""Extract text from message content."""
|
||||
if isinstance(content, str):
|
||||
return content
|
||||
elif isinstance(content, list):
|
||||
text_parts = []
|
||||
for item in content:
|
||||
if isinstance(item, dict) and item.get("type") == "text":
|
||||
text_parts.append(item.get("text", ""))
|
||||
elif isinstance(item, str):
|
||||
text_parts.append(item)
|
||||
return "\n".join(text_parts)
|
||||
return str(content) if content else ""
|
||||
|
||||
def _merge_html(
|
||||
self,
|
||||
existing_html: str,
|
||||
new_content: str,
|
||||
new_styles: str = "",
|
||||
user_language: str = "en-US",
|
||||
) -> str:
|
||||
"""Merges new content into HTML container."""
|
||||
if "<!-- OPENWEBUI_PLUGIN_OUTPUT -->" in existing_html:
|
||||
base_html = re.sub(r"^```html\s*", "", existing_html)
|
||||
base_html = re.sub(r"\s*```$", "", base_html)
|
||||
else:
|
||||
base_html = HTML_WRAPPER_TEMPLATE.replace("{user_language}", user_language)
|
||||
|
||||
wrapped = f'<div class="plugin-item">\n{new_content}\n</div>'
|
||||
|
||||
if new_styles:
|
||||
base_html = base_html.replace(
|
||||
"/* STYLES_INSERTION_POINT */",
|
||||
f"{new_styles}\n/* STYLES_INSERTION_POINT */",
|
||||
)
|
||||
|
||||
base_html = base_html.replace(
|
||||
"<!-- CONTENT_INSERTION_POINT -->",
|
||||
f"{wrapped}\n<!-- CONTENT_INSERTION_POINT -->",
|
||||
)
|
||||
|
||||
return base_html.strip()
|
||||
|
||||
def _build_content_html(self, context: dict) -> str:
|
||||
"""Build content HTML."""
|
||||
html = CONTENT_TEMPLATE
|
||||
for key, value in context.items():
|
||||
html = html.replace(f"{{{key}}}", str(value))
|
||||
return html
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: Optional[Dict[str, Any]] = None,
|
||||
__event_emitter__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
__request__: Optional[Request] = None,
|
||||
) -> Optional[dict]:
|
||||
logger.info("Action: Deep Dive v1.0.0 started")
|
||||
|
||||
user_ctx = self._get_user_context(__user__)
|
||||
user_id = user_ctx["user_id"]
|
||||
user_name = user_ctx["user_name"]
|
||||
user_language = user_ctx["user_language"]
|
||||
|
||||
now = datetime.now()
|
||||
current_date_time_str = now.strftime("%b %d, %Y %H:%M")
|
||||
|
||||
original_content = ""
|
||||
try:
|
||||
messages = body.get("messages", [])
|
||||
if not messages:
|
||||
raise ValueError("No messages found.")
|
||||
|
||||
message_count = min(self.valves.MESSAGE_COUNT, len(messages))
|
||||
recent_messages = messages[-message_count:]
|
||||
|
||||
aggregated_parts = []
|
||||
for msg in recent_messages:
|
||||
text = self._extract_text_content(msg.get("content"))
|
||||
if text:
|
||||
aggregated_parts.append(text)
|
||||
|
||||
if not aggregated_parts:
|
||||
raise ValueError("No text content found.")
|
||||
|
||||
original_content = "\n\n---\n\n".join(aggregated_parts)
|
||||
word_count = len(original_content.split())
|
||||
|
||||
if len(original_content) < self.valves.MIN_TEXT_LENGTH:
|
||||
msg = f"Content too brief ({len(original_content)} chars). Deep Dive requires at least {self.valves.MIN_TEXT_LENGTH} chars for meaningful analysis."
|
||||
await self._emit_notification(__event_emitter__, msg, "warning")
|
||||
return {"messages": [{"role": "assistant", "content": f"⚠️ {msg}"}]}
|
||||
|
||||
await self._emit_notification(
|
||||
__event_emitter__, "🌊 Initiating Deep Dive thinking process...", "info"
|
||||
)
|
||||
await self._emit_status(
|
||||
__event_emitter__, "🌊 Deep Dive: Analyzing Context & Logic...", False
|
||||
)
|
||||
|
||||
prompt = USER_PROMPT.format(
|
||||
user_name=user_name,
|
||||
current_date_time_str=current_date_time_str,
|
||||
user_language=user_language,
|
||||
long_text_content=original_content,
|
||||
)
|
||||
|
||||
model = self.valves.MODEL_ID or body.get("model")
|
||||
payload = {
|
||||
"model": model,
|
||||
"messages": [
|
||||
{"role": "system", "content": SYSTEM_PROMPT},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
user_obj = Users.get_user_by_id(user_id)
|
||||
if not user_obj:
|
||||
raise ValueError(f"User not found: {user_id}")
|
||||
|
||||
response = await generate_chat_completion(__request__, payload, user_obj)
|
||||
llm_output = response["choices"][0]["message"]["content"]
|
||||
|
||||
processed = self._process_llm_output(llm_output)
|
||||
|
||||
context = {
|
||||
"user_name": user_name,
|
||||
"current_date_time_str": current_date_time_str,
|
||||
"word_count": word_count,
|
||||
**processed,
|
||||
}
|
||||
|
||||
content_html = self._build_content_html(context)
|
||||
|
||||
# Handle existing HTML
|
||||
existing = ""
|
||||
match = re.search(
|
||||
r"```html\s*(<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?)```",
|
||||
original_content,
|
||||
)
|
||||
if match:
|
||||
existing = match.group(1)
|
||||
|
||||
if self.valves.CLEAR_PREVIOUS_HTML or not existing:
|
||||
original_content = self._remove_existing_html(original_content)
|
||||
final_html = self._merge_html(
|
||||
"", content_html, CSS_TEMPLATE, user_language
|
||||
)
|
||||
else:
|
||||
original_content = self._remove_existing_html(original_content)
|
||||
final_html = self._merge_html(
|
||||
existing, content_html, CSS_TEMPLATE, user_language
|
||||
)
|
||||
|
||||
body["messages"][-1][
|
||||
"content"
|
||||
] = f"{original_content}\n\n```html\n{final_html}\n```"
|
||||
|
||||
await self._emit_status(__event_emitter__, "🌊 Deep Dive complete!", True)
|
||||
await self._emit_notification(
|
||||
__event_emitter__,
|
||||
f"🌊 Deep Dive complete, {user_name}! Thinking chain generated.",
|
||||
"success",
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Deep Dive Error: {e}", exc_info=True)
|
||||
body["messages"][-1][
|
||||
"content"
|
||||
] = f"{original_content}\n\n❌ **Error:** {str(e)}"
|
||||
await self._emit_status(__event_emitter__, "Deep Dive failed.", True)
|
||||
await self._emit_notification(
|
||||
__event_emitter__, f"Error: {str(e)}", "error"
|
||||
)
|
||||
|
||||
return body
|
||||
BIN
plugins/actions/deep-dive/deep_dive_cn.png
Normal file
BIN
plugins/actions/deep-dive/deep_dive_cn.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 997 KiB |
936
plugins/actions/deep-dive/deep_dive_cn.py
Normal file
936
plugins/actions/deep-dive/deep_dive_cn.py
Normal file
@@ -0,0 +1,936 @@
|
||||
"""
|
||||
title: 精读
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 1.0.0
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwYXRoIGQ9Ik0xMiA3djE0Ii8+PHBhdGggZD0iTTMgMThhMSAxIDAgMCAxLTEtMVY0YTEgMSAwIDAgMSAxLTFoNWE0IDQgMCAwIDEgNCA0IDQgNCAwIDAgMSA0LTRoNWExIDEgMCAwIDEgMSAxdjEzYTEgMSAwIDAgMS0xIDFoLTZhMyAzIDAgMCAwLTMgMyAzIDMgMCAwIDAtMy0zeiIvPjxwYXRoIGQ9Ik02IDEyaDIiLz48cGF0aCBkPSJNMTYgMTJoMiIvPjwvc3ZnPg==
|
||||
requirements: markdown
|
||||
description: 全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。
|
||||
"""
|
||||
|
||||
# Standard library imports
|
||||
import re
|
||||
import logging
|
||||
from typing import Optional, Dict, Any, Callable, Awaitable
|
||||
from datetime import datetime
|
||||
|
||||
# Third-party imports
|
||||
from pydantic import BaseModel, Field
|
||||
from fastapi import Request
|
||||
import markdown
|
||||
|
||||
# OpenWebUI imports
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from open_webui.models.users import Users
|
||||
|
||||
# Logging setup
|
||||
logging.basicConfig(
|
||||
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# =================================================================
|
||||
# HTML 模板 - 过程导向设计,支持主题自适应
|
||||
# =================================================================
|
||||
HTML_WRAPPER_TEMPLATE = """
|
||||
<!-- OPENWEBUI_PLUGIN_OUTPUT -->
|
||||
<!DOCTYPE html>
|
||||
<html lang="{user_language}">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<style>
|
||||
:root {
|
||||
--dd-bg-primary: #ffffff;
|
||||
--dd-bg-secondary: #f8fafc;
|
||||
--dd-bg-tertiary: #f1f5f9;
|
||||
--dd-text-primary: #0f172a;
|
||||
--dd-text-secondary: #334155;
|
||||
--dd-text-dim: #64748b;
|
||||
--dd-border: #e2e8f0;
|
||||
--dd-accent: #3b82f6;
|
||||
--dd-accent-soft: #eff6ff;
|
||||
--dd-header-gradient: linear-gradient(135deg, #1e293b 0%, #0f172a 100%);
|
||||
--dd-shadow: 0 10px 40px rgba(0,0,0,0.06);
|
||||
--dd-code-bg: #f1f5f9;
|
||||
}
|
||||
.theme-dark {
|
||||
--dd-bg-primary: #1e293b;
|
||||
--dd-bg-secondary: #0f172a;
|
||||
--dd-bg-tertiary: #334155;
|
||||
--dd-text-primary: #f1f5f9;
|
||||
--dd-text-secondary: #e2e8f0;
|
||||
--dd-text-dim: #94a3b8;
|
||||
--dd-border: #475569;
|
||||
--dd-accent: #60a5fa;
|
||||
--dd-accent-soft: rgba(59, 130, 246, 0.15);
|
||||
--dd-header-gradient: linear-gradient(135deg, #0f172a 0%, #1e1e2e 100%);
|
||||
--dd-shadow: 0 10px 40px rgba(0,0,0,0.3);
|
||||
--dd-code-bg: #334155;
|
||||
}
|
||||
body {
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif;
|
||||
margin: 0;
|
||||
padding: 10px;
|
||||
background-color: transparent;
|
||||
}
|
||||
#main-container {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 24px;
|
||||
width: 100%;
|
||||
max-width: 900px;
|
||||
margin: 0 auto;
|
||||
}
|
||||
.plugin-item {
|
||||
background: var(--dd-bg-primary);
|
||||
border-radius: 24px;
|
||||
box-shadow: var(--dd-shadow);
|
||||
overflow: hidden;
|
||||
border: 1px solid var(--dd-border);
|
||||
}
|
||||
/* STYLES_INSERTION_POINT */
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div id="main-container">
|
||||
<!-- CONTENT_INSERTION_POINT -->
|
||||
</div>
|
||||
<!-- SCRIPTS_INSERTION_POINT -->
|
||||
<script>
|
||||
(function() {
|
||||
const parseColorLuma = (colorStr) => {
|
||||
if (!colorStr) return null;
|
||||
let m = colorStr.match(/^#?([0-9a-f]{6})$/i);
|
||||
if (m) {
|
||||
const hex = m[1];
|
||||
const r = parseInt(hex.slice(0, 2), 16);
|
||||
const g = parseInt(hex.slice(2, 4), 16);
|
||||
const b = parseInt(hex.slice(4, 6), 16);
|
||||
return (0.2126 * r + 0.7152 * g + 0.0722 * b) / 255;
|
||||
}
|
||||
m = colorStr.match(/rgba?\\s*\\(\\s*(\\d+)\\s*,\\s*(\\d+)\\s*,\\s*(\\d+)/i);
|
||||
if (m) {
|
||||
const r = parseInt(m[1], 10);
|
||||
const g = parseInt(m[2], 10);
|
||||
const b = parseInt(m[3], 10);
|
||||
return (0.2126 * r + 0.7152 * g + 0.0722 * b) / 255;
|
||||
}
|
||||
return null;
|
||||
};
|
||||
const getThemeFromMeta = (doc) => {
|
||||
const metas = Array.from((doc || document).querySelectorAll('meta[name="theme-color"]'));
|
||||
if (!metas.length) return null;
|
||||
const color = metas[metas.length - 1].content.trim();
|
||||
const luma = parseColorLuma(color);
|
||||
if (luma === null) return null;
|
||||
return luma < 0.5 ? 'dark' : 'light';
|
||||
};
|
||||
const getParentDocumentSafe = () => {
|
||||
try {
|
||||
if (!window.parent || window.parent === window) return null;
|
||||
const pDoc = window.parent.document;
|
||||
void pDoc.title;
|
||||
return pDoc;
|
||||
} catch (err) { return null; }
|
||||
};
|
||||
const getThemeFromParentClass = () => {
|
||||
try {
|
||||
if (!window.parent || window.parent === window) return null;
|
||||
const pDoc = window.parent.document;
|
||||
const html = pDoc.documentElement;
|
||||
const body = pDoc.body;
|
||||
const htmlClass = html ? html.className : '';
|
||||
const bodyClass = body ? body.className : '';
|
||||
const htmlDataTheme = html ? html.getAttribute('data-theme') : '';
|
||||
if (htmlDataTheme === 'dark' || bodyClass.includes('dark') || htmlClass.includes('dark')) return 'dark';
|
||||
if (htmlDataTheme === 'light' || bodyClass.includes('light') || htmlClass.includes('light')) return 'light';
|
||||
return null;
|
||||
} catch (err) { return null; }
|
||||
};
|
||||
const setTheme = () => {
|
||||
const parentDoc = getParentDocumentSafe();
|
||||
const metaTheme = parentDoc ? getThemeFromMeta(parentDoc) : null;
|
||||
const parentClassTheme = getThemeFromParentClass();
|
||||
const prefersDark = window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches;
|
||||
const chosen = metaTheme || parentClassTheme || (prefersDark ? 'dark' : 'light');
|
||||
document.documentElement.classList.toggle('theme-dark', chosen === 'dark');
|
||||
};
|
||||
setTheme();
|
||||
if (window.matchMedia) {
|
||||
window.matchMedia('(prefers-color-scheme: dark)').addEventListener('change', setTheme);
|
||||
}
|
||||
})();
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
# =================================================================
|
||||
# LLM 提示词 - 深度下潜思维链
|
||||
# =================================================================
|
||||
|
||||
SYSTEM_PROMPT = """
|
||||
你是一位“深度下潜 (Deep Dive)”分析专家。你的目标是引导用户完成一个全面的思维过程,从表面理解深入到战略行动。
|
||||
|
||||
## 思维结构 (严格遵守)
|
||||
|
||||
你必须从以下四个维度剖析输入内容:
|
||||
|
||||
### 1. 🔍 The Context (全景)
|
||||
提供一个高层级的全景视图。内容是关于什么的?核心情境、背景或正在解决的问题是什么?(2-3 段话)
|
||||
|
||||
### 2. 🧠 The Logic (脉络)
|
||||
解构底层结构。论点是如何构建的?其中的推理逻辑、隐藏假设或起作用的思维模型是什么?(列表形式)
|
||||
|
||||
### 3. 💎 The Insight (洞察)
|
||||
提取非显性的价值。有哪些“原来如此”的时刻?揭示了哪些深层含义、盲点或独特视角?(列表形式)
|
||||
|
||||
### 4. 🚀 The Path (路径)
|
||||
定义战略方向。具体的、按优先级排列的下一步行动是什么?如何立即应用这些知识?(可执行步骤)
|
||||
|
||||
## 规则
|
||||
- 使用用户指定的语言输出。
|
||||
- 保持专业、分析性且富有启发性的语调。
|
||||
- 聚焦于“理解的过程”,而不仅仅是结果。
|
||||
- 不要包含寒暄或元对话。
|
||||
"""
|
||||
|
||||
USER_PROMPT = """
|
||||
对以下内容发起“深度下潜”:
|
||||
|
||||
**用户上下文:**
|
||||
- 用户:{user_name}
|
||||
- 时间:{current_date_time_str}
|
||||
- 语言:{user_language}
|
||||
|
||||
**待分析内容:**
|
||||
```
|
||||
{long_text_content}
|
||||
```
|
||||
|
||||
请执行完整的思维链:全景 (Context) → 脉络 (Logic) → 洞察 (Insight) → 路径 (Path)。
|
||||
"""
|
||||
|
||||
# =================================================================
|
||||
# 现代 CSS 设计 - 深度下潜主题
|
||||
# =================================================================
|
||||
|
||||
CSS_TEMPLATE = """
|
||||
.deep-dive {
|
||||
font-family: 'Inter', -apple-system, system-ui, sans-serif;
|
||||
color: var(--dd-text-secondary);
|
||||
}
|
||||
|
||||
.dd-header {
|
||||
background: var(--dd-header-gradient);
|
||||
padding: 40px 32px;
|
||||
color: white;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.dd-header-badge {
|
||||
display: inline-block;
|
||||
padding: 4px 12px;
|
||||
background: rgba(255,255,255,0.1);
|
||||
border: 1px solid rgba(255,255,255,0.2);
|
||||
border-radius: 100px;
|
||||
font-size: 0.75rem;
|
||||
font-weight: 600;
|
||||
letter-spacing: 0.05em;
|
||||
text-transform: uppercase;
|
||||
margin-bottom: 16px;
|
||||
}
|
||||
|
||||
.dd-title {
|
||||
font-size: 2rem;
|
||||
font-weight: 800;
|
||||
margin: 0 0 12px 0;
|
||||
letter-spacing: -0.02em;
|
||||
}
|
||||
|
||||
.dd-meta {
|
||||
display: flex;
|
||||
gap: 20px;
|
||||
font-size: 0.85rem;
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.dd-body {
|
||||
padding: 32px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 40px;
|
||||
position: relative;
|
||||
background: var(--dd-bg-primary);
|
||||
}
|
||||
|
||||
/* 思维导火索 */
|
||||
.dd-body::before {
|
||||
content: '';
|
||||
position: absolute;
|
||||
left: 52px;
|
||||
top: 40px;
|
||||
bottom: 40px;
|
||||
width: 2px;
|
||||
background: var(--dd-border);
|
||||
z-index: 0;
|
||||
}
|
||||
|
||||
.dd-step {
|
||||
position: relative;
|
||||
z-index: 1;
|
||||
display: flex;
|
||||
gap: 24px;
|
||||
}
|
||||
|
||||
.dd-step-icon {
|
||||
flex-shrink: 0;
|
||||
width: 40px;
|
||||
height: 40px;
|
||||
background: var(--dd-bg-primary);
|
||||
border: 2px solid var(--dd-border);
|
||||
border-radius: 12px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
font-size: 1.25rem;
|
||||
box-shadow: 0 4px 12px rgba(0,0,0,0.03);
|
||||
transition: all 0.3s ease;
|
||||
}
|
||||
|
||||
.dd-step:hover .dd-step-icon {
|
||||
border-color: var(--dd-accent);
|
||||
transform: scale(1.1);
|
||||
}
|
||||
|
||||
.dd-step-content {
|
||||
flex: 1;
|
||||
}
|
||||
|
||||
.dd-step-label {
|
||||
font-size: 0.75rem;
|
||||
font-weight: 700;
|
||||
color: var(--dd-accent);
|
||||
text-transform: uppercase;
|
||||
letter-spacing: 0.1em;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.dd-step-title {
|
||||
font-size: 1.25rem;
|
||||
font-weight: 700;
|
||||
color: var(--dd-text-primary);
|
||||
margin: 0 0 16px 0;
|
||||
}
|
||||
|
||||
.dd-text {
|
||||
line-height: 1.7;
|
||||
font-size: 1rem;
|
||||
}
|
||||
|
||||
.dd-text p { margin-bottom: 16px; }
|
||||
.dd-text p:last-child { margin-bottom: 0; }
|
||||
|
||||
.dd-list {
|
||||
list-style: none;
|
||||
padding: 0;
|
||||
margin: 0;
|
||||
display: grid;
|
||||
gap: 12px;
|
||||
}
|
||||
|
||||
.dd-list-item {
|
||||
background: var(--dd-bg-secondary);
|
||||
padding: 16px 20px;
|
||||
border-radius: 12px;
|
||||
border-left: 4px solid var(--dd-border);
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.dd-list-item:hover {
|
||||
background: var(--dd-bg-tertiary);
|
||||
border-left-color: var(--dd-accent);
|
||||
transform: translateX(4px);
|
||||
}
|
||||
|
||||
.dd-list-item strong {
|
||||
color: var(--dd-text-primary);
|
||||
display: block;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.dd-path-item {
|
||||
background: var(--dd-accent-soft);
|
||||
border-left-color: var(--dd-accent);
|
||||
}
|
||||
|
||||
.dd-footer {
|
||||
padding: 24px 32px;
|
||||
background: var(--dd-bg-secondary);
|
||||
border-top: 1px solid var(--dd-border);
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
font-size: 0.8rem;
|
||||
color: var(--dd-text-dim);
|
||||
}
|
||||
|
||||
.dd-tag {
|
||||
padding: 2px 8px;
|
||||
background: var(--dd-bg-tertiary);
|
||||
border-radius: 4px;
|
||||
font-weight: 600;
|
||||
}
|
||||
|
||||
.dd-text code,
|
||||
.dd-list-item code {
|
||||
background: var(--dd-code-bg);
|
||||
color: var(--dd-text-primary);
|
||||
padding: 2px 6px;
|
||||
border-radius: 4px;
|
||||
font-family: 'SF Mono', 'Consolas', 'Monaco', monospace;
|
||||
font-size: 0.85em;
|
||||
}
|
||||
|
||||
.dd-list-item em {
|
||||
font-style: italic;
|
||||
color: var(--dd-text-dim);
|
||||
}
|
||||
"""
|
||||
|
||||
CONTENT_TEMPLATE = """
|
||||
<div class="deep-dive">
|
||||
<div class="dd-header">
|
||||
<div class="dd-header-badge">思维过程</div>
|
||||
<h1 class="dd-title">精读分析报告</h1>
|
||||
<div class="dd-meta">
|
||||
<span>👤 {user_name}</span>
|
||||
<span>📅 {current_date_time_str}</span>
|
||||
<span>📊 {word_count} 字</span>
|
||||
</div>
|
||||
</div>
|
||||
<div class="dd-body">
|
||||
<!-- 第一步:全景 -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🔍</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 01</div>
|
||||
<h2 class="dd-step-title">全景 (The Context)</h2>
|
||||
<div class="dd-text">{context_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- 第二步:脉络 -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🧠</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 02</div>
|
||||
<h2 class="dd-step-title">脉络 (The Logic)</h2>
|
||||
<div class="dd-text">{logic_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- 第三步:洞察 -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">💎</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 03</div>
|
||||
<h2 class="dd-step-title">洞察 (The Insight)</h2>
|
||||
<div class="dd-text">{insight_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- 第四步:路径 -->
|
||||
<div class="dd-step">
|
||||
<div class="dd-step-icon">🚀</div>
|
||||
<div class="dd-step-content">
|
||||
<div class="dd-step-label">Phase 04</div>
|
||||
<h2 class="dd-step-title">路径 (The Path)</h2>
|
||||
<div class="dd-text">{path_html}</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="dd-footer">
|
||||
<span>Deep Dive Engine v1.0</span>
|
||||
<span><span class="dd-tag">AI 驱动分析</span></span>
|
||||
</div>
|
||||
</div>
|
||||
"""
|
||||
|
||||
|
||||
class Action:
|
||||
class Valves(BaseModel):
|
||||
SHOW_STATUS: bool = Field(
|
||||
default=True,
|
||||
description="是否显示操作状态更新。",
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False,
|
||||
description="是否在浏览器控制台打印调试日志。",
|
||||
)
|
||||
MODEL_ID: str = Field(
|
||||
default="",
|
||||
description="用于分析的 LLM 模型 ID。留空则使用当前模型。",
|
||||
)
|
||||
MIN_TEXT_LENGTH: int = Field(
|
||||
default=200,
|
||||
description="深度下潜所需的最小文本长度(字符)。",
|
||||
)
|
||||
CLEAR_PREVIOUS_HTML: bool = Field(
|
||||
default=True,
|
||||
description="是否清除之前的插件结果。",
|
||||
)
|
||||
MESSAGE_COUNT: int = Field(
|
||||
default=1,
|
||||
description="要分析的最近消息数量。",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
|
||||
def _get_user_context(self, __user__: Optional[Dict[str, Any]]) -> Dict[str, str]:
|
||||
"""安全提取用户上下文信息。"""
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_data = __user__[0] if __user__ else {}
|
||||
elif isinstance(__user__, dict):
|
||||
user_data = __user__
|
||||
else:
|
||||
user_data = {}
|
||||
|
||||
return {
|
||||
"user_id": user_data.get("id", "unknown_user"),
|
||||
"user_name": user_data.get("name", "用户"),
|
||||
"user_language": user_data.get("language", "zh-CN"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""
|
||||
统一提取聊天上下文信息 (chat_id, message_id)。
|
||||
优先从 body 中提取,其次从 metadata 中提取。
|
||||
"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
# 1. 尝试从 body 获取
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # message_id 在 body 中通常是 id
|
||||
|
||||
# 再次检查 body.metadata
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
# 2. 尝试从 __metadata__ 获取 (作为补充)
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
def _process_llm_output(self, llm_output: str) -> Dict[str, str]:
|
||||
"""解析 LLM 输出并转换为样式化 HTML。"""
|
||||
# 使用灵活的正则提取各部分
|
||||
context_match = re.search(
|
||||
r"###\s*1\.\s*🔍?\s*(?:全景|The Context)\s*(?:\((.*?)\))?\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
logic_match = re.search(
|
||||
r"###\s*2\.\s*🧠?\s*(?:脉络|The Logic)\s*(?:\((.*?)\))?\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
insight_match = re.search(
|
||||
r"###\s*3\.\s*💎?\s*(?:洞察|The Insight)\s*(?:\((.*?)\))?\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
path_match = re.search(
|
||||
r"###\s*4\.\s*🚀?\s*(?:路径|The Path)\s*(?:\((.*?)\))?\s*\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
|
||||
# 兜底正则
|
||||
if not context_match:
|
||||
context_match = re.search(
|
||||
r"###\s*🔍?\s*(?:全景|The Context).*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not logic_match:
|
||||
logic_match = re.search(
|
||||
r"###\s*🧠?\s*(?:脉络|The Logic).*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not insight_match:
|
||||
insight_match = re.search(
|
||||
r"###\s*💎?\s*(?:洞察|The Insight).*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
if not path_match:
|
||||
path_match = re.search(
|
||||
r"###\s*🚀?\s*(?:路径|The Path).*?\n(.*?)(?=\n###|$)",
|
||||
llm_output,
|
||||
re.DOTALL | re.IGNORECASE,
|
||||
)
|
||||
|
||||
context_md = (
|
||||
context_match.group(context_match.lastindex).strip()
|
||||
if context_match
|
||||
else ""
|
||||
)
|
||||
logic_md = (
|
||||
logic_match.group(logic_match.lastindex).strip() if logic_match else ""
|
||||
)
|
||||
insight_md = (
|
||||
insight_match.group(insight_match.lastindex).strip()
|
||||
if insight_match
|
||||
else ""
|
||||
)
|
||||
path_md = path_match.group(path_match.lastindex).strip() if path_match else ""
|
||||
|
||||
if not any([context_md, logic_md, insight_md, path_md]):
|
||||
context_md = llm_output.strip()
|
||||
logger.warning("LLM 输出未遵循格式,将作为全景处理。")
|
||||
|
||||
md_extensions = ["nl2br"]
|
||||
|
||||
context_html = (
|
||||
markdown.markdown(context_md, extensions=md_extensions)
|
||||
if context_md
|
||||
else '<p class="dd-no-content">未能提取全景信息。</p>'
|
||||
)
|
||||
logic_html = (
|
||||
self._process_list_items(logic_md, "logic")
|
||||
if logic_md
|
||||
else '<p class="dd-no-content">未能解构脉络。</p>'
|
||||
)
|
||||
insight_html = (
|
||||
self._process_list_items(insight_md, "insight")
|
||||
if insight_md
|
||||
else '<p class="dd-no-content">未能发现洞察。</p>'
|
||||
)
|
||||
path_html = (
|
||||
self._process_list_items(path_md, "path")
|
||||
if path_md
|
||||
else '<p class="dd-no-content">未能定义路径。</p>'
|
||||
)
|
||||
|
||||
return {
|
||||
"context_html": context_html,
|
||||
"logic_html": logic_html,
|
||||
"insight_html": insight_html,
|
||||
"path_html": path_html,
|
||||
}
|
||||
|
||||
def _process_list_items(self, md_content: str, section_type: str) -> str:
|
||||
"""将 markdown 列表转换为样式化卡片,支持完整的 markdown 格式。"""
|
||||
lines = md_content.strip().split("\n")
|
||||
items = []
|
||||
current_paragraph = []
|
||||
|
||||
for line in lines:
|
||||
line = line.strip()
|
||||
|
||||
# 检查列表项(无序或有序)
|
||||
bullet_match = re.match(r"^[-*]\s+(.+)$", line)
|
||||
numbered_match = re.match(r"^\d+\.\s+(.+)$", line)
|
||||
|
||||
if bullet_match or numbered_match:
|
||||
# 清空累积的段落
|
||||
if current_paragraph:
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
current_paragraph = []
|
||||
|
||||
# 提取列表项内容
|
||||
text = (
|
||||
bullet_match.group(1) if bullet_match else numbered_match.group(1)
|
||||
)
|
||||
|
||||
# 处理粗体标题模式:**标题:** 描述 或 **标题**: 描述
|
||||
title_match = re.match(r"\*\*(.+?)\*\*[:\s:]*(.*)$", text)
|
||||
if title_match:
|
||||
title = self._convert_inline_markdown(title_match.group(1))
|
||||
desc = self._convert_inline_markdown(title_match.group(2).strip())
|
||||
path_class = "dd-path-item" if section_type == "path" else ""
|
||||
item_html = f'<div class="dd-list-item {path_class}"><strong>{title}</strong>{desc}</div>'
|
||||
else:
|
||||
text_html = self._convert_inline_markdown(text)
|
||||
path_class = "dd-path-item" if section_type == "path" else ""
|
||||
item_html = (
|
||||
f'<div class="dd-list-item {path_class}">{text_html}</div>'
|
||||
)
|
||||
items.append(item_html)
|
||||
elif line and not line.startswith("#"):
|
||||
# 累积段落文本
|
||||
current_paragraph.append(line)
|
||||
elif not line and current_paragraph:
|
||||
# 空行结束段落
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
current_paragraph = []
|
||||
|
||||
# 清空剩余段落
|
||||
if current_paragraph:
|
||||
para_text = " ".join(current_paragraph)
|
||||
para_html = self._convert_inline_markdown(para_text)
|
||||
items.append(f"<p>{para_html}</p>")
|
||||
|
||||
if items:
|
||||
return f'<div class="dd-list">{" ".join(items)}</div>'
|
||||
return f'<p class="dd-no-content">未找到条目。</p>'
|
||||
|
||||
def _convert_inline_markdown(self, text: str) -> str:
|
||||
"""将行内 markdown(粗体、斜体、代码)转换为 HTML。"""
|
||||
# 转换行内代码:`code` -> <code>code</code>
|
||||
text = re.sub(r"`([^`]+)`", r"<code>\1</code>", text)
|
||||
# 转换粗体:**text** -> <strong>text</strong>
|
||||
text = re.sub(r"\*\*(.+?)\*\*", r"<strong>\1</strong>", text)
|
||||
# 转换斜体:*text* -> <em>text</em>(但不在 ** 内部)
|
||||
text = re.sub(r"(?<!\*)\*([^*]+)\*(?!\*)", r"<em>\1</em>", text)
|
||||
return text
|
||||
|
||||
async def _emit_status(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
description: str,
|
||||
done: bool = False,
|
||||
):
|
||||
"""发送状态更新事件。"""
|
||||
if self.valves.SHOW_STATUS and emitter:
|
||||
await emitter(
|
||||
{"type": "status", "data": {"description": description, "done": done}}
|
||||
)
|
||||
|
||||
async def _emit_notification(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
content: str,
|
||||
ntype: str = "info",
|
||||
):
|
||||
"""发送通知事件。"""
|
||||
if emitter:
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": ntype, "content": content}}
|
||||
)
|
||||
|
||||
async def _emit_debug_log(self, emitter, title: str, data: dict):
|
||||
"""在浏览器控制台打印结构化调试日志"""
|
||||
if not self.valves.SHOW_DEBUG_LOG or not emitter:
|
||||
return
|
||||
|
||||
try:
|
||||
import json
|
||||
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
await emitter({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
|
||||
def _remove_existing_html(self, content: str) -> str:
|
||||
"""移除已有的插件生成的 HTML。"""
|
||||
pattern = r"```html\s*<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?```"
|
||||
return re.sub(pattern, "", content).strip()
|
||||
|
||||
def _extract_text_content(self, content) -> str:
|
||||
"""从消息内容中提取文本。"""
|
||||
if isinstance(content, str):
|
||||
return content
|
||||
elif isinstance(content, list):
|
||||
text_parts = []
|
||||
for item in content:
|
||||
if isinstance(item, dict) and item.get("type") == "text":
|
||||
text_parts.append(item.get("text", ""))
|
||||
elif isinstance(item, str):
|
||||
text_parts.append(item)
|
||||
return "\n".join(text_parts)
|
||||
return str(content) if content else ""
|
||||
|
||||
def _merge_html(
|
||||
self,
|
||||
existing_html: str,
|
||||
new_content: str,
|
||||
new_styles: str = "",
|
||||
user_language: str = "zh-CN",
|
||||
) -> str:
|
||||
"""合并新内容到 HTML 容器。"""
|
||||
if "<!-- OPENWEBUI_PLUGIN_OUTPUT -->" in existing_html:
|
||||
base_html = re.sub(r"^```html\s*", "", existing_html)
|
||||
base_html = re.sub(r"\s*```$", "", base_html)
|
||||
else:
|
||||
base_html = HTML_WRAPPER_TEMPLATE.replace("{user_language}", user_language)
|
||||
|
||||
wrapped = f'<div class="plugin-item">\n{new_content}\n</div>'
|
||||
|
||||
if new_styles:
|
||||
base_html = base_html.replace(
|
||||
"/* STYLES_INSERTION_POINT */",
|
||||
f"{new_styles}\n/* STYLES_INSERTION_POINT */",
|
||||
)
|
||||
|
||||
base_html = base_html.replace(
|
||||
"<!-- CONTENT_INSERTION_POINT -->",
|
||||
f"{wrapped}\n<!-- CONTENT_INSERTION_POINT -->",
|
||||
)
|
||||
|
||||
return base_html.strip()
|
||||
|
||||
def _build_content_html(self, context: dict) -> str:
|
||||
"""构建内容 HTML。"""
|
||||
html = CONTENT_TEMPLATE
|
||||
for key, value in context.items():
|
||||
html = html.replace(f"{{{key}}}", str(value))
|
||||
return html
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: Optional[Dict[str, Any]] = None,
|
||||
__event_emitter__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
__request__: Optional[Request] = None,
|
||||
) -> Optional[dict]:
|
||||
logger.info("Action: 精读 v1.0.0 启动")
|
||||
|
||||
user_ctx = self._get_user_context(__user__)
|
||||
user_id = user_ctx["user_id"]
|
||||
user_name = user_ctx["user_name"]
|
||||
user_language = user_ctx["user_language"]
|
||||
|
||||
now = datetime.now()
|
||||
current_date_time_str = now.strftime("%Y年%m月%d日 %H:%M")
|
||||
|
||||
original_content = ""
|
||||
try:
|
||||
messages = body.get("messages", [])
|
||||
if not messages:
|
||||
raise ValueError("未找到消息内容。")
|
||||
|
||||
message_count = min(self.valves.MESSAGE_COUNT, len(messages))
|
||||
recent_messages = messages[-message_count:]
|
||||
|
||||
aggregated_parts = []
|
||||
for msg in recent_messages:
|
||||
text = self._extract_text_content(msg.get("content"))
|
||||
if text:
|
||||
aggregated_parts.append(text)
|
||||
|
||||
if not aggregated_parts:
|
||||
raise ValueError("未找到文本内容。")
|
||||
|
||||
original_content = "\n\n---\n\n".join(aggregated_parts)
|
||||
word_count = len(original_content)
|
||||
|
||||
if len(original_content) < self.valves.MIN_TEXT_LENGTH:
|
||||
msg = f"内容过短({len(original_content)} 字符)。精读至少需要 {self.valves.MIN_TEXT_LENGTH} 字符才能进行有意义的分析。"
|
||||
await self._emit_notification(__event_emitter__, msg, "warning")
|
||||
return {"messages": [{"role": "assistant", "content": f"⚠️ {msg}"}]}
|
||||
|
||||
await self._emit_notification(
|
||||
__event_emitter__, "📖 正在发起精读分析...", "info"
|
||||
)
|
||||
await self._emit_status(
|
||||
__event_emitter__, "📖 精读:正在分析全景与脉络...", False
|
||||
)
|
||||
|
||||
prompt = USER_PROMPT.format(
|
||||
user_name=user_name,
|
||||
current_date_time_str=current_date_time_str,
|
||||
user_language=user_language,
|
||||
long_text_content=original_content,
|
||||
)
|
||||
|
||||
model = self.valves.MODEL_ID or body.get("model")
|
||||
payload = {
|
||||
"model": model,
|
||||
"messages": [
|
||||
{"role": "system", "content": SYSTEM_PROMPT},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
user_obj = Users.get_user_by_id(user_id)
|
||||
if not user_obj:
|
||||
raise ValueError(f"未找到用户:{user_id}")
|
||||
|
||||
response = await generate_chat_completion(__request__, payload, user_obj)
|
||||
llm_output = response["choices"][0]["message"]["content"]
|
||||
|
||||
processed = self._process_llm_output(llm_output)
|
||||
|
||||
context = {
|
||||
"user_name": user_name,
|
||||
"current_date_time_str": current_date_time_str,
|
||||
"word_count": word_count,
|
||||
**processed,
|
||||
}
|
||||
|
||||
content_html = self._build_content_html(context)
|
||||
|
||||
# 处理已有 HTML
|
||||
existing = ""
|
||||
match = re.search(
|
||||
r"```html\s*(<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?)```",
|
||||
original_content,
|
||||
)
|
||||
if match:
|
||||
existing = match.group(1)
|
||||
|
||||
if self.valves.CLEAR_PREVIOUS_HTML or not existing:
|
||||
original_content = self._remove_existing_html(original_content)
|
||||
final_html = self._merge_html(
|
||||
"", content_html, CSS_TEMPLATE, user_language
|
||||
)
|
||||
else:
|
||||
original_content = self._remove_existing_html(original_content)
|
||||
final_html = self._merge_html(
|
||||
existing, content_html, CSS_TEMPLATE, user_language
|
||||
)
|
||||
|
||||
body["messages"][-1][
|
||||
"content"
|
||||
] = f"{original_content}\n\n```html\n{final_html}\n```"
|
||||
|
||||
await self._emit_status(__event_emitter__, "📖 精读完成!", True)
|
||||
await self._emit_notification(
|
||||
__event_emitter__,
|
||||
f"📖 精读完成,{user_name}!思维链已生成。",
|
||||
"success",
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Deep Dive 错误:{e}", exc_info=True)
|
||||
body["messages"][-1][
|
||||
"content"
|
||||
] = f"{original_content}\n\n❌ **错误:** {str(e)}"
|
||||
await self._emit_status(__event_emitter__, "精读失败。", True)
|
||||
await self._emit_notification(__event_emitter__, f"错误:{str(e)}", "error")
|
||||
|
||||
return body
|
||||
@@ -1,74 +1,95 @@
|
||||
# Export to Word
|
||||
# 📝 Export to Word (Enhanced)
|
||||
|
||||
Export current conversation from Markdown to Word (.docx) with **syntax highlighting**, **blockquote support**, and smarter filenames.
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.4.3 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
## Features
|
||||
Export conversation to Word (.docx) with **syntax highlighting**, **native math equations**, **Mermaid diagrams**, **citations**, and **enhanced table formatting**.
|
||||
|
||||
- **One-Click Export**: Adds an "Export to Word" action button to the chat.
|
||||
- **Markdown Conversion**: Converts Markdown syntax to Word formatting (headings, bold, italic, code, tables, lists).
|
||||
- **Syntax Highlighting**: Code blocks are highlighted with Pygments (supports 500+ languages).
|
||||
- **Blockquote Support**: Markdown blockquotes are rendered with left border and gray styling.
|
||||
- **Multi-language Support**: Properly handles both Chinese and English text without garbled characters.
|
||||
- **Smarter Filenames**: Configurable title source (Chat Title, AI Generated, or Markdown Title).
|
||||
## 🔥 What's New in v0.4.3
|
||||
|
||||
## Configuration
|
||||
- ✨ **S3 Object Storage Support**: Direct access to images stored in S3/MinIO via boto3, bypassing API layer for faster exports.
|
||||
- 🔧 **Multi-level File Fallback**: 6-level fallback mechanism for file retrieval (DB → S3 → Local → URL → API → Attributes).
|
||||
- 🛡️ **Improved Error Handling**: Better logging and error messages for file retrieval failures.
|
||||
|
||||
You can configure the following settings via the **Valves** button in the plugin settings:
|
||||
## ✨ Key Features
|
||||
|
||||
- **TITLE_SOURCE**: Choose how the document title/filename is generated.
|
||||
- `chat_title`: Use the conversation title (default).
|
||||
- `ai_generated`: Use AI to generate a short title based on the content.
|
||||
- `markdown_title`: Extract the first h1/h2 heading from the Markdown content.
|
||||
- 🚀 **One-Click Export**: Adds an "Export to Word" action button to the chat.
|
||||
- 📄 **Markdown Conversion**: Full Markdown syntax support (headings, bold, italic, code, tables, lists).
|
||||
- 🎨 **Syntax Highlighting**: Code blocks highlighted with Pygments (500+ languages).
|
||||
- 🔢 **Native Math Equations**: LaTeX math (`$$...$$`, `\[...\]`, `$...$`) converted to editable Word equations.
|
||||
- 📊 **Mermaid Diagrams**: Flowcharts and sequence diagrams rendered as images.
|
||||
- 📚 **Citations & References**: Auto-generates References section with clickable citation links.
|
||||
- 🧹 **Reasoning Stripping**: Automatically removes AI thinking blocks (`<think>`, `<analysis>`).
|
||||
- 📋 **Enhanced Tables**: Smart column widths, alignment, header row repeat across pages.
|
||||
- 💬 **Blockquote Support**: Markdown blockquotes with left border and gray styling.
|
||||
- 🌐 **Multi-language Support**: Proper handling of Chinese and English text.
|
||||
|
||||
## Supported Markdown Syntax
|
||||
## 🚀 How to Use
|
||||
|
||||
| Syntax | Word Result |
|
||||
| :---------------------------------- | :-------------------------------- |
|
||||
| `# Heading 1` to `###### Heading 6` | Heading levels 1-6 |
|
||||
| `**bold**` or `__bold__` | Bold text |
|
||||
| `*italic*` or `_italic_` | Italic text |
|
||||
| `***bold italic***` | Bold + Italic |
|
||||
| `` `inline code` `` | Monospace with gray background |
|
||||
| ` ``` code block ``` ` | **Syntax highlighted** code block |
|
||||
| `> blockquote` | Left-bordered gray italic text |
|
||||
| `[link](url)` | Blue underlined link text |
|
||||
| `~~strikethrough~~` | Strikethrough text |
|
||||
| `- item` or `* item` | Bullet list |
|
||||
| `1. item` | Numbered list |
|
||||
| Markdown tables | Table with grid |
|
||||
| `---` or `***` | Horizontal rule |
|
||||
1. **Install**: Search for "Export to Word" in the Open WebUI Community and install.
|
||||
2. **Trigger**: In any chat, click the "Export to Word" action button.
|
||||
3. **Download**: The .docx file will be automatically downloaded.
|
||||
|
||||
## Usage
|
||||
## ⚙️ Configuration (Valves)
|
||||
|
||||
1. Install the plugin.
|
||||
2. In any chat, click the "Export to Word" button.
|
||||
3. The .docx file will be automatically downloaded to your device.
|
||||
| Parameter | Default | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| **Title Source (TITLE_SOURCE)** | `chat_title` | `chat_title`, `ai_generated`, or `markdown_title` |
|
||||
| **Max Image Size (MAX_EMBED_IMAGE_MB)** | `20` | Maximum image size to embed (MB) |
|
||||
| **UI Language (UI_LANGUAGE)** | `en` | `en` (English) or `zh` (Chinese) |
|
||||
| **Latin Font (FONT_LATIN)** | `Times New Roman` | Font for Latin characters |
|
||||
| **Asian Font (FONT_ASIAN)** | `SimSun` | Font for Asian characters |
|
||||
| **Code Font (FONT_CODE)** | `Consolas` | Font for code blocks |
|
||||
| **Table Header Color** | `F2F2F2` | Header background color (hex) |
|
||||
| **Table Zebra Color** | `FBFBFB` | Alternating row color (hex) |
|
||||
| **Mermaid PNG Scale** | `3.0` | Resolution multiplier for Mermaid images |
|
||||
| **Math Enable** | `True` | Enable LaTeX math conversion |
|
||||
|
||||
## 🛠️ Supported Markdown Syntax
|
||||
|
||||
### Notes
|
||||
| Syntax | Word Result |
|
||||
| :--- | :--- |
|
||||
| `# Heading 1` to `###### Heading 6` | Heading levels 1-6 |
|
||||
| `**bold**` or `__bold__` | Bold text |
|
||||
| `*italic*` or `_italic_` | Italic text |
|
||||
| `` `inline code` `` | Monospace with gray background |
|
||||
| ` ``` code block ``` ` | **Syntax highlighted** code block |
|
||||
| `> blockquote` | Left-bordered gray italic text |
|
||||
| `[link](url)` | Blue underlined link |
|
||||
| `~~strikethrough~~` | Strikethrough text |
|
||||
| `- item` or `* item` | Bullet list |
|
||||
| `1. item` | Numbered list |
|
||||
| Markdown tables | **Enhanced table** with smart widths |
|
||||
| `$$LaTeX$$` or `\[LaTeX\]` | **Native Word equation** (display) |
|
||||
| `$LaTeX$` or `\(LaTeX\)` | **Native Word equation** (inline) |
|
||||
| ` ```mermaid ... ``` ` | **Mermaid diagram** as image |
|
||||
| `[1]` citation markers | **Clickable links** to References |
|
||||
|
||||
- Title detection only considers h1/h2 headings.
|
||||
- If the request carries `chat_id` (body or metadata), the plugin will fetch the chat title from the database when the body lacks one.
|
||||
- Default fonts: Times New Roman (en), SimSun/SimHei (zh), Consolas (code).
|
||||
|
||||
### Requirements
|
||||
## 📦 Requirements
|
||||
|
||||
- `python-docx==1.1.2` - Word document generation
|
||||
- `Pygments>=2.15.0` - Syntax highlighting (optional but recommended)
|
||||
- `Pygments>=2.15.0` - Syntax highlighting
|
||||
- `latex2mathml` - LaTeX to MathML conversion
|
||||
- `mathml2omml` - MathML to Office Math (OMML) conversion
|
||||
|
||||
Both are declared in the plugin docstring; ensure they are installed in your environment.
|
||||
## 📝 Changelog
|
||||
|
||||
## Font Configuration
|
||||
### v0.4.3
|
||||
- **S3 Object Storage**: Direct S3/MinIO access via boto3 for faster image retrieval.
|
||||
- **6-Level Fallback**: Robust file retrieval: DB → S3 → Local → URL → API → Attributes.
|
||||
- **Better Logging**: Improved error messages for debugging file access issues.
|
||||
|
||||
- **English Text**: Times New Roman
|
||||
- **Chinese Text**: SimSun (宋体) for body, SimHei (黑体) for headings
|
||||
- **Code**: Consolas
|
||||
### v0.4.1
|
||||
- **Chinese Parameter Names**: Localized configuration names for Chinese version.
|
||||
|
||||
## Author
|
||||
### v0.4.0
|
||||
- **Multi-language Support**: UI language switching (English/Chinese).
|
||||
- **Font & Style Configuration**: Customizable fonts and table colors.
|
||||
- **Mermaid Enhancements**: Hybrid SVG+PNG rendering, background color config.
|
||||
- **Performance**: Real-time progress updates for large exports.
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
## Troubleshooting ❓
|
||||
|
||||
## License
|
||||
|
||||
MIT License
|
||||
- **Plugin not working?**: Check if the filter/action is enabled in the model settings.
|
||||
- **Debug Logs**: Check the browser console (F12) for detailed logs if available.
|
||||
- **Error Messages**: If you see an error, please copy the full error message and report it.
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
@@ -1,73 +1,95 @@
|
||||
# 导出为 Word
|
||||
# 📝 导出为 Word (增强版)
|
||||
|
||||
将当前对话内容从 Markdown 转换并导出为 Word (.docx) 文件,支持**代码语法高亮**、**引用块样式**和更智能的文件命名。
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.4.3 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
## 功能特点
|
||||
将对话导出为 Word (.docx),支持**代码语法高亮**、**原生数学公式**、**Mermaid 图表**、**引用参考**和**增强表格格式**。
|
||||
|
||||
- **一键导出**:在聊天界面添加“导出为 Word”动作按钮。
|
||||
- **Markdown 转换**:将 Markdown 语法转换为 Word 格式(标题、粗体、斜体、代码、表格、列表)。
|
||||
- **代码语法高亮**:使用 Pygments 库为代码块添加语法高亮(支持 500+ 种语言)。
|
||||
- **引用块支持**:Markdown 引用块会渲染为带左侧边框的灰色斜体样式。
|
||||
- **多语言支持**:正确处理中文和英文文本,无乱码问题。
|
||||
- **更智能的文件名**:可配置标题来源(对话标题、AI 生成或 Markdown 标题)。
|
||||
## 🔥 v0.4.3 更新内容
|
||||
|
||||
## 配置 (Configuration)
|
||||
- ✨ **S3 对象存储支持**: 通过 boto3 直连 S3/MinIO,绕过 API 层,导出速度更快。
|
||||
- 🔧 **多级文件回退**: 6 级文件获取机制(数据库 → S3 → 本地 → URL → API → 属性)。
|
||||
- 🛡️ **错误处理优化**: 更完善的日志记录和错误提示,便于调试文件访问问题。
|
||||
|
||||
您可以通过插件设置中的 **Valves** 按钮配置以下选项:
|
||||
## ✨ 核心特性
|
||||
|
||||
- **TITLE_SOURCE**:选择文档标题/文件名的生成方式。
|
||||
- `chat_title`:使用对话标题(默认)。
|
||||
- `ai_generated`:使用 AI 根据内容生成简短标题。
|
||||
- `markdown_title`:从 Markdown 内容中提取第一个一级或二级标题。
|
||||
- 🚀 **一键导出**: 在聊天界面添加"导出为 Word"动作按钮。
|
||||
- 📄 **Markdown 转换**: 完整支持 Markdown 语法(标题、粗体、斜体、代码、表格、列表)。
|
||||
- 🎨 **代码语法高亮**: 使用 Pygments 库高亮代码块(支持 500+ 种语言)。
|
||||
- 🔢 **原生数学公式**: LaTeX 公式(`$$...$$`、`\[...\]`、`$...$`)转换为可编辑的 Word 公式。
|
||||
- 📊 **Mermaid 图表**: 流程图和时序图渲染为文档中的图片。
|
||||
- 📚 **引用与参考**: 自动生成参考资料章节,支持可点击的引用链接。
|
||||
- 🧹 **移除思考过程**: 自动移除 AI 思考块(`<think>`、`<analysis>`)。
|
||||
- 📋 **增强表格**: 智能列宽、对齐、表头跨页重复。
|
||||
- 💬 **引用块支持**: Markdown 引用块渲染为带左侧边框的灰色斜体样式。
|
||||
- 🌐 **多语言支持**: 正确处理中文和英文文本。
|
||||
|
||||
## 支持的 Markdown 语法
|
||||
## 🚀 使用方法
|
||||
|
||||
| 语法 | Word 效果 |
|
||||
| :-------------------------- | :----------------------- |
|
||||
| `# 标题1` 到 `###### 标题6` | 标题级别 1-6 |
|
||||
| `**粗体**` 或 `__粗体__` | 粗体文本 |
|
||||
| `*斜体*` 或 `_斜体_` | 斜体文本 |
|
||||
| `***粗斜体***` | 粗体 + 斜体 |
|
||||
| `` `行内代码` `` | 等宽字体 + 灰色背景 |
|
||||
| ` ``` 代码块 ``` ` | **语法高亮**的代码块 |
|
||||
| `> 引用文本` | 带左侧边框的灰色斜体文本 |
|
||||
| `[链接](url)` | 蓝色下划线链接文本 |
|
||||
| `~~删除线~~` | 删除线文本 |
|
||||
| `- 项目` 或 `* 项目` | 无序列表 |
|
||||
| `1. 项目` | 有序列表 |
|
||||
| Markdown 表格 | 带边框表格 |
|
||||
| `---` 或 `***` | 水平分割线 |
|
||||
1. **安装**: 在 Open WebUI 社区搜索 "导出为 Word" 并安装。
|
||||
2. **触发**: 在任意对话中,点击"导出为 Word"动作按钮。
|
||||
3. **下载**: .docx 文件将自动下载到你的设备。
|
||||
|
||||
## 使用方法
|
||||
## ⚙️ 配置参数 (Valves)
|
||||
|
||||
1. 安装插件。
|
||||
2. 在任意对话中,点击"导出为 Word"按钮。
|
||||
3. .docx 文件将自动下载到你的设备。
|
||||
| 参数 | 默认值 | 说明 |
|
||||
| :--- | :--- | :--- |
|
||||
| **文档标题来源** | `chat_title` | `chat_title`(对话标题)、`ai_generated`(AI 生成)、`markdown_title`(Markdown 标题)|
|
||||
| **最大嵌入图片大小MB** | `20` | 嵌入图片的最大大小 (MB) |
|
||||
| **界面语言** | `zh` | `en`(英语)或 `zh`(中文)|
|
||||
| **英文字体** | `Calibri` | 英文字体名称 |
|
||||
| **中文字体** | `SimSun` | 中文字体名称 |
|
||||
| **代码字体** | `Consolas` | 代码块字体名称 |
|
||||
| **表头背景色** | `F2F2F2` | 表头背景色(十六进制)|
|
||||
| **表格隔行背景色** | `FBFBFB` | 表格隔行背景色(十六进制)|
|
||||
| **Mermaid_PNG缩放比例** | `3.0` | Mermaid 图片分辨率倍数 |
|
||||
| **启用数学公式** | `True` | 启用 LaTeX 公式转换 |
|
||||
|
||||
### 说明
|
||||
## 🛠️ 支持的 Markdown 语法
|
||||
|
||||
- 标题检测仅考虑一级/二级标题(h1/h2)。
|
||||
- 若请求体或 metadata 提供 `chat_id`,当正文缺少标题时会从数据库查询对话标题。
|
||||
- 默认字体:英文 Times New Roman,中文宋体/黑体,代码 Consolas。
|
||||
| 语法 | Word 效果 |
|
||||
| :--- | :--- |
|
||||
| `# 标题1` 到 `###### 标题6` | 标题级别 1-6 |
|
||||
| `**粗体**` 或 `__粗体__` | 粗体文本 |
|
||||
| `*斜体*` 或 `_斜体_` | 斜体文本 |
|
||||
| `` `行内代码` `` | 等宽字体 + 灰色背景 |
|
||||
| ` ``` 代码块 ``` ` | **语法高亮**的代码块 |
|
||||
| `> 引用文本` | 带左侧边框的灰色斜体文本 |
|
||||
| `[链接](url)` | 蓝色下划线链接文本 |
|
||||
| `~~删除线~~` | 删除线文本 |
|
||||
| `- 项目` 或 `* 项目` | 无序列表 |
|
||||
| `1. 项目` | 有序列表 |
|
||||
| Markdown 表格 | **增强表格**(智能列宽)|
|
||||
| `$$LaTeX$$` 或 `\[LaTeX\]` | **原生 Word 公式**(块级)|
|
||||
| `$LaTeX$` 或 `\(LaTeX\)` | **原生 Word 公式**(行内)|
|
||||
| ` ```mermaid ... ``` ` | **Mermaid 图表**(图片形式)|
|
||||
| `[1]` 引用标记 | **可点击链接**到参考资料 |
|
||||
|
||||
### 依赖
|
||||
## 📦 依赖
|
||||
|
||||
- `python-docx==1.1.2` - Word 文档生成
|
||||
- `Pygments>=2.15.0` - 语法高亮(可选但建议安装)
|
||||
- `Pygments>=2.15.0` - 语法高亮
|
||||
- `latex2mathml` - LaTeX 转 MathML
|
||||
- `mathml2omml` - MathML 转 Office Math (OMML)
|
||||
|
||||
两者已在插件文档字符串中声明,请确保环境已安装。
|
||||
## 📝 更新日志
|
||||
|
||||
## 字体配置
|
||||
### v0.4.3
|
||||
- **S3 对象存储**: 通过 boto3 直连 S3/MinIO,图片获取速度更快。
|
||||
- **6 级回退机制**: 稳健的文件获取:数据库 → S3 → 本地 → URL → API → 属性。
|
||||
- **日志优化**: 改进错误提示,便于调试文件访问问题。
|
||||
|
||||
- **英文文本**:Times New Roman
|
||||
- **中文文本**:宋体(正文)、黑体(标题)
|
||||
- **代码**:Consolas
|
||||
### v0.4.1
|
||||
- **中文参数名**: 配置项名称和描述全部汉化。
|
||||
|
||||
## 作者
|
||||
### v0.4.0
|
||||
- **多语言支持**: 界面语言切换(中文/英文)。
|
||||
- **字体与样式配置**: 支持自定义中英文字体、代码字体以及表格颜色。
|
||||
- **Mermaid 增强**: 混合 SVG+PNG 渲染,支持背景色配置。
|
||||
- **性能优化**: 导出大型文档时提供实时进度反馈。
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
## 许可证
|
||||
|
||||
MIT License
|
||||
- **插件不工作?**: 请检查是否在模型设置中启用了该过滤器/动作。
|
||||
- **调试日志**: 请查看浏览器控制台 (F12) 获取详细日志(如果可用)。
|
||||
- **错误信息**: 如果看到错误,请复制完整的错误信息并报告。
|
||||
- **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
BIN
plugins/actions/export_to_docx/export_to_word.png
Normal file
BIN
plugins/actions/export_to_docx/export_to_word.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 78 KiB |
File diff suppressed because it is too large
Load Diff
BIN
plugins/actions/export_to_docx/export_to_word_cn.png
Normal file
BIN
plugins/actions/export_to_docx/export_to_word_cn.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 86 KiB |
3097
plugins/actions/export_to_docx/export_to_word_cn.py
Normal file
3097
plugins/actions/export_to_docx/export_to_word_cn.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -1,882 +0,0 @@
|
||||
"""
|
||||
title: 导出为 Word
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie
|
||||
funding_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
version: 0.1.0
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZwogIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyIKICB3aWR0aD0iMjQiCiAgaGVpZ2h0PSIyNCIKICB2aWV3Qm94PSIwIDAgMjQgMjQiCiAgZmlsbD0ibm9uZSIKICBzdHJva2U9ImN1cnJlbnRDb2xvciIKICBzdHJva2Utd2lkdGg9IjIiCiAgc3Ryb2tlLWxpbmVjYXA9InJvdW5kIgogIHN0cm9rZS1saW5lam9pbj0icm91bmQiCj4KICA8cGF0aCBkPSJNNiAyMmEyIDIgMCAwIDEtMi0yVjRhMiAyIDAgMCAxIDItMmg4YTIuNCAyLjQgMCAwIDEgMS43MDQuNzA2bDMuNTg4IDMuNTg4QTIuNCAyLjQgMCAwIDEgMjAgOHYxMmEyIDIgMCAwIDEtMiAyeiIgLz4KICA8cGF0aCBkPSJNMTQgMnY1YTEgMSAwIDAgMCAxIDFoNSIgLz4KICA8cGF0aCBkPSJNMTAgOUg4IiAvPgogIDxwYXRoIGQ9Ik0xNiAxM0g4IiAvPgogIDxwYXRoIGQ9Ik0xNiAxN0g4IiAvPgo8L3N2Zz4K
|
||||
requirements: python-docx==1.1.2, Pygments>=2.15.0
|
||||
description: 将当前对话内容从 Markdown 转换并导出为 Word (.docx) 文件,支持代码语法高亮和引用块。
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
import base64
|
||||
import datetime
|
||||
import io
|
||||
import asyncio
|
||||
import logging
|
||||
from typing import Optional, Callable, Awaitable, Any, List, Tuple
|
||||
from docx import Document
|
||||
from docx.shared import Pt, Inches, RGBColor, Cm
|
||||
from docx.enum.text import WD_ALIGN_PARAGRAPH, WD_LINE_SPACING
|
||||
from docx.enum.table import WD_TABLE_ALIGNMENT
|
||||
from docx.enum.style import WD_STYLE_TYPE
|
||||
from docx.oxml.ns import qn
|
||||
from docx.oxml import OxmlElement
|
||||
from open_webui.models.chats import Chats
|
||||
from open_webui.models.users import Users
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
# Pygments for syntax highlighting
|
||||
try:
|
||||
from pygments import lex
|
||||
from pygments.lexers import get_lexer_by_name, TextLexer
|
||||
from pygments.token import Token
|
||||
|
||||
PYGMENTS_AVAILABLE = True
|
||||
except ImportError:
|
||||
PYGMENTS_AVAILABLE = False
|
||||
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class Action:
|
||||
class Valves(BaseModel):
|
||||
TITLE_SOURCE: str = Field(
|
||||
default="chat_title",
|
||||
description="标题来源: 'chat_title' (对话标题), 'ai_generated' (AI 生成), 'markdown_title' (Markdown 标题)",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
|
||||
async def _send_notification(self, emitter: Callable, type: str, content: str):
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": type, "content": content}}
|
||||
)
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__=None,
|
||||
__event_emitter__=None,
|
||||
__event_call__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
__metadata__: Optional[dict] = None,
|
||||
__request__: Optional[Any] = None,
|
||||
):
|
||||
logger.info(f"action:{__name__}")
|
||||
|
||||
# 解析用户信息
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_language = (
|
||||
__user__[0].get("language", "zh-CN") if __user__ else "zh-CN"
|
||||
)
|
||||
user_name = __user__[0].get("name", "用户") if __user__[0] else "用户"
|
||||
user_id = (
|
||||
__user__[0]["id"]
|
||||
if __user__ and "id" in __user__[0]
|
||||
else "unknown_user"
|
||||
)
|
||||
elif isinstance(__user__, dict):
|
||||
user_language = __user__.get("language", "zh-CN")
|
||||
user_name = __user__.get("name", "用户")
|
||||
user_id = __user__.get("id", "unknown_user")
|
||||
|
||||
if __event_emitter__:
|
||||
last_assistant_message = body["messages"][-1]
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "正在转换为 Word 文档...", "done": False},
|
||||
}
|
||||
)
|
||||
|
||||
try:
|
||||
message_content = last_assistant_message["content"]
|
||||
|
||||
if not message_content or not message_content.strip():
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", "没有找到可导出的内容!"
|
||||
)
|
||||
return
|
||||
|
||||
# 生成文件名
|
||||
title = ""
|
||||
chat_id = self.extract_chat_id(body, __metadata__)
|
||||
|
||||
# 直接通过 chat_id 获取标题,因为 body 中通常不包含标题
|
||||
chat_title = ""
|
||||
if chat_id:
|
||||
chat_title = await self.fetch_chat_title(chat_id, user_id)
|
||||
|
||||
# 根据配置决定文件名使用的标题
|
||||
if (
|
||||
self.valves.TITLE_SOURCE == "chat_title"
|
||||
or not self.valves.TITLE_SOURCE
|
||||
):
|
||||
title = chat_title
|
||||
elif self.valves.TITLE_SOURCE == "markdown_title":
|
||||
title = self.extract_title(message_content)
|
||||
elif self.valves.TITLE_SOURCE == "ai_generated":
|
||||
title = await self.generate_title_using_ai(
|
||||
body, message_content, user_id, __request__
|
||||
)
|
||||
|
||||
current_datetime = datetime.datetime.now()
|
||||
formatted_date = current_datetime.strftime("%Y%m%d")
|
||||
|
||||
if title:
|
||||
filename = f"{self.clean_filename(title)}.docx"
|
||||
else:
|
||||
filename = f"{user_name}_{formatted_date}.docx"
|
||||
|
||||
# 创建 Word 文档;若正文无一级标题,使用对话标题作为一级标题
|
||||
# 如果选择了 chat_title 且获取到了,则作为 top_heading
|
||||
# 如果选择了其他方式,title 就是文件名,也可以作为 top_heading
|
||||
|
||||
# 保持原有逻辑:top_heading 主要是为了在文档开头补充标题
|
||||
# 这里我们尽量使用 chat_title 作为 top_heading,如果它存在的话,因为它通常是对话的主题
|
||||
# 即使文件名是 AI 生成的,文档内的标题用 chat_title 也是合理的
|
||||
# 但如果用户选择了 markdown_title,可能不希望插入 chat_title
|
||||
|
||||
top_heading = ""
|
||||
if chat_title:
|
||||
top_heading = chat_title
|
||||
elif title:
|
||||
top_heading = title
|
||||
|
||||
has_h1 = bool(re.search(r"^#\s+.+$", message_content, re.MULTILINE))
|
||||
doc = self.markdown_to_docx(
|
||||
message_content, top_heading=top_heading, has_h1=has_h1
|
||||
)
|
||||
|
||||
# 保存到内存
|
||||
doc_buffer = io.BytesIO()
|
||||
doc.save(doc_buffer)
|
||||
doc_buffer.seek(0)
|
||||
file_content = doc_buffer.read()
|
||||
base64_blob = base64.b64encode(file_content).decode("utf-8")
|
||||
|
||||
# 触发文件下载
|
||||
if __event_call__:
|
||||
await __event_call__(
|
||||
{
|
||||
"type": "execute",
|
||||
"data": {
|
||||
"code": f"""
|
||||
try {{
|
||||
const base64Data = "{base64_blob}";
|
||||
const binaryData = atob(base64Data);
|
||||
const arrayBuffer = new Uint8Array(binaryData.length);
|
||||
for (let i = 0; i < binaryData.length; i++) {{
|
||||
arrayBuffer[i] = binaryData.charCodeAt(i);
|
||||
}}
|
||||
const blob = new Blob([arrayBuffer], {{ type: "application/vnd.openxmlformats-officedocument.wordprocessingml.document" }});
|
||||
const filename = "{filename}";
|
||||
|
||||
const url = URL.createObjectURL(blob);
|
||||
const a = document.createElement("a");
|
||||
a.style.display = "none";
|
||||
a.href = url;
|
||||
a.download = filename;
|
||||
document.body.appendChild(a);
|
||||
a.click();
|
||||
URL.revokeObjectURL(url);
|
||||
document.body.removeChild(a);
|
||||
}} catch (error) {{
|
||||
console.error('触发下载时出错:', error);
|
||||
}}
|
||||
"""
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "Word 文档已导出", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
await self._send_notification(
|
||||
__event_emitter__, "success", f"已成功导出为 {filename}"
|
||||
)
|
||||
|
||||
return {"message": "下载事件已触发"}
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error exporting to Word: {str(e)}")
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {
|
||||
"description": f"导出失败: {str(e)}",
|
||||
"done": True,
|
||||
},
|
||||
}
|
||||
)
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", f"导出 Word 文档时出错: {str(e)}"
|
||||
)
|
||||
|
||||
async def generate_title_using_ai(
|
||||
self, body: dict, content: str, user_id: str, request: Any
|
||||
) -> str:
|
||||
if not request:
|
||||
return ""
|
||||
|
||||
try:
|
||||
user_obj = Users.get_user_by_id(user_id)
|
||||
model = body.get("model")
|
||||
|
||||
payload = {
|
||||
"model": model,
|
||||
"messages": [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a helpful assistant. Generate a short, concise title (max 10 words) for the following text. Do not use quotes. Only output the title.",
|
||||
},
|
||||
{"role": "user", "content": content[:2000]}, # Limit content length
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
response = await generate_chat_completion(request, payload, user_obj)
|
||||
if response and "choices" in response:
|
||||
return response["choices"][0]["message"]["content"].strip()
|
||||
except Exception as e:
|
||||
logger.error(f"Error generating title: {e}")
|
||||
|
||||
return ""
|
||||
|
||||
def extract_title(self, content: str) -> str:
|
||||
"""从 Markdown 内容提取一级/二级标题"""
|
||||
lines = content.split("\n")
|
||||
for line in lines:
|
||||
# 仅匹配 h1-h2 标题
|
||||
match = re.match(r"^#{1,2}\s+(.+)$", line.strip())
|
||||
if match:
|
||||
return match.group(1).strip()
|
||||
return ""
|
||||
|
||||
def extract_chat_title(self, body: dict) -> str:
|
||||
"""从请求体中提取会话标题"""
|
||||
if not isinstance(body, dict):
|
||||
return ""
|
||||
|
||||
candidates = []
|
||||
|
||||
for key in ("chat", "conversation"):
|
||||
if isinstance(body.get(key), dict):
|
||||
candidates.append(body.get(key, {}).get("title", ""))
|
||||
|
||||
for key in ("title", "chat_title"):
|
||||
value = body.get(key)
|
||||
if isinstance(value, str):
|
||||
candidates.append(value)
|
||||
|
||||
for candidate in candidates:
|
||||
if candidate and isinstance(candidate, str):
|
||||
return candidate.strip()
|
||||
return ""
|
||||
|
||||
def extract_chat_id(self, body: dict, metadata: Optional[dict]) -> str:
|
||||
"""从 body 或 metadata 中提取 chat_id"""
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id") or body.get("id")
|
||||
if isinstance(chat_id, str) and chat_id.strip():
|
||||
return chat_id.strip()
|
||||
|
||||
for key in ("chat", "conversation"):
|
||||
nested = body.get(key)
|
||||
if isinstance(nested, dict):
|
||||
nested_id = nested.get("id") or nested.get("chat_id")
|
||||
if isinstance(nested_id, str) and nested_id.strip():
|
||||
return nested_id.strip()
|
||||
if isinstance(metadata, dict):
|
||||
chat_id = metadata.get("chat_id")
|
||||
if isinstance(chat_id, str) and chat_id.strip():
|
||||
return chat_id.strip()
|
||||
return ""
|
||||
|
||||
async def fetch_chat_title(self, chat_id: str, user_id: str = "") -> str:
|
||||
"""根据 chat_id 从数据库获取标题"""
|
||||
if not chat_id:
|
||||
return ""
|
||||
|
||||
def _load_chat():
|
||||
if user_id:
|
||||
return Chats.get_chat_by_id_and_user_id(id=chat_id, user_id=user_id)
|
||||
return Chats.get_chat_by_id(chat_id)
|
||||
|
||||
try:
|
||||
chat = await asyncio.to_thread(_load_chat)
|
||||
except Exception as exc:
|
||||
logger.warning(f"加载聊天 {chat_id} 失败: {exc}")
|
||||
return ""
|
||||
|
||||
if not chat:
|
||||
return ""
|
||||
|
||||
data = getattr(chat, "chat", {}) or {}
|
||||
title = data.get("title") or getattr(chat, "title", "")
|
||||
return title.strip() if isinstance(title, str) else ""
|
||||
|
||||
def clean_filename(self, name: str) -> str:
|
||||
"""清理文件名中的非法字符"""
|
||||
return re.sub(r'[\\/*?:"<>|]', "", name).strip()[:50]
|
||||
|
||||
def markdown_to_docx(
|
||||
self, markdown_text: str, top_heading: str = "", has_h1: bool = False
|
||||
) -> Document:
|
||||
"""
|
||||
将 Markdown 文本转换为 Word 文档
|
||||
支持:标题、段落、粗体、斜体、代码块、列表、表格、链接
|
||||
"""
|
||||
doc = Document()
|
||||
|
||||
# 设置默认中文字体
|
||||
self.set_document_default_font(doc)
|
||||
|
||||
# 若正文无一级标题且有对话标题,则作为一级标题写入
|
||||
if top_heading and not has_h1:
|
||||
self.add_heading(doc, top_heading, 1)
|
||||
|
||||
lines = markdown_text.split("\n")
|
||||
i = 0
|
||||
in_code_block = False
|
||||
code_block_content = []
|
||||
code_block_lang = ""
|
||||
in_list = False
|
||||
list_items = []
|
||||
list_type = None # 'ordered' or 'unordered'
|
||||
|
||||
while i < len(lines):
|
||||
line = lines[i]
|
||||
|
||||
# 处理代码块
|
||||
if line.strip().startswith("```"):
|
||||
if not in_code_block:
|
||||
# 先处理之前积累的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
in_code_block = True
|
||||
code_block_lang = line.strip()[3:].strip()
|
||||
code_block_content = []
|
||||
else:
|
||||
# 代码块结束
|
||||
in_code_block = False
|
||||
self.add_code_block(
|
||||
doc, "\n".join(code_block_content), code_block_lang
|
||||
)
|
||||
code_block_content = []
|
||||
code_block_lang = ""
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if in_code_block:
|
||||
code_block_content.append(line)
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理表格
|
||||
if line.strip().startswith("|") and line.strip().endswith("|"):
|
||||
# 先处理之前积累的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
table_lines = []
|
||||
while i < len(lines) and lines[i].strip().startswith("|"):
|
||||
table_lines.append(lines[i])
|
||||
i += 1
|
||||
self.add_table(doc, table_lines)
|
||||
continue
|
||||
|
||||
# 处理标题
|
||||
header_match = re.match(r"^(#{1,6})\s+(.+)$", line.strip())
|
||||
if header_match:
|
||||
# 先处理之前积累的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
level = len(header_match.group(1))
|
||||
text = header_match.group(2)
|
||||
self.add_heading(doc, text, level)
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理无序列表
|
||||
unordered_match = re.match(r"^(\s*)[-*+]\s+(.+)$", line)
|
||||
if unordered_match:
|
||||
if not in_list or list_type != "unordered":
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = True
|
||||
list_type = "unordered"
|
||||
indent = len(unordered_match.group(1)) // 2
|
||||
list_items.append((indent, unordered_match.group(2)))
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理有序列表
|
||||
ordered_match = re.match(r"^(\s*)\d+[.)]\s+(.+)$", line)
|
||||
if ordered_match:
|
||||
if not in_list or list_type != "ordered":
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = True
|
||||
list_type = "ordered"
|
||||
indent = len(ordered_match.group(1)) // 2
|
||||
list_items.append((indent, ordered_match.group(2)))
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理引用块
|
||||
if line.strip().startswith(">"):
|
||||
# 先处理之前积累的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
# 收集连续的引用行
|
||||
blockquote_lines = []
|
||||
while i < len(lines) and lines[i].strip().startswith(">"):
|
||||
# 移除开头的 > 和可能的空格
|
||||
quote_line = re.sub(r"^>\s?", "", lines[i])
|
||||
blockquote_lines.append(quote_line)
|
||||
i += 1
|
||||
self.add_blockquote(doc, "\n".join(blockquote_lines))
|
||||
continue
|
||||
|
||||
# 处理水平分割线
|
||||
if re.match(r"^[-*_]{3,}$", line.strip()):
|
||||
# 先处理之前积累的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
self.add_horizontal_rule(doc)
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理空行
|
||||
if not line.strip():
|
||||
# 列表结束
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
i += 1
|
||||
continue
|
||||
|
||||
# 处理普通段落
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
list_items = []
|
||||
in_list = False
|
||||
|
||||
self.add_paragraph(doc, line)
|
||||
i += 1
|
||||
|
||||
# 处理剩余的列表
|
||||
if in_list and list_items:
|
||||
self.add_list_to_doc(doc, list_items, list_type)
|
||||
|
||||
return doc
|
||||
|
||||
def set_document_default_font(self, doc: Document):
|
||||
"""设置文档默认字体,确保中英文都正常显示"""
|
||||
# 设置正文样式
|
||||
style = doc.styles["Normal"]
|
||||
font = style.font
|
||||
font.name = "Times New Roman" # 英文字体
|
||||
font.size = Pt(11)
|
||||
|
||||
# 设置中文字体
|
||||
style._element.rPr.rFonts.set(qn("w:eastAsia"), "宋体")
|
||||
|
||||
# 设置段落格式
|
||||
paragraph_format = style.paragraph_format
|
||||
paragraph_format.line_spacing_rule = WD_LINE_SPACING.ONE_POINT_FIVE
|
||||
paragraph_format.space_after = Pt(6)
|
||||
|
||||
def add_heading(self, doc: Document, text: str, level: int):
|
||||
"""添加标题"""
|
||||
# Word 标题级别从 0 开始,Markdown 从 1 开始
|
||||
heading_level = min(level, 9) # Word 最多支持 Heading 9
|
||||
heading = doc.add_heading(level=heading_level)
|
||||
|
||||
# 解析并添加格式化文本
|
||||
self.add_formatted_text(heading, text)
|
||||
|
||||
# 设置中文字体
|
||||
for run in heading.runs:
|
||||
run.font.name = "Times New Roman"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "黑体")
|
||||
run.font.color.rgb = RGBColor(0, 0, 0)
|
||||
|
||||
def add_paragraph(self, doc: Document, text: str):
|
||||
"""添加段落,支持内联格式"""
|
||||
paragraph = doc.add_paragraph()
|
||||
self.add_formatted_text(paragraph, text)
|
||||
|
||||
# 设置中文字体
|
||||
for run in paragraph.runs:
|
||||
run.font.name = "Times New Roman"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "宋体")
|
||||
|
||||
def add_formatted_text(self, paragraph, text: str):
|
||||
"""
|
||||
解析 Markdown 内联格式并添加到段落
|
||||
支持:粗体、斜体、行内代码、链接、删除线
|
||||
"""
|
||||
# 定义格式化模式
|
||||
patterns = [
|
||||
# 粗斜体 ***text*** 或 ___text___
|
||||
(r"\*\*\*(.+?)\*\*\*|___(.+?)___", {"bold": True, "italic": True}),
|
||||
# 粗体 **text** 或 __text__
|
||||
(r"\*\*(.+?)\*\*|__(.+?)__", {"bold": True}),
|
||||
# 斜体 *text* 或 _text_
|
||||
(
|
||||
r"(?<!\*)\*(?!\*)(.+?)(?<!\*)\*(?!\*)|(?<!_)_(?!_)(.+?)(?<!_)_(?!_)",
|
||||
{"italic": True},
|
||||
),
|
||||
# 行内代码 `code`
|
||||
(r"`([^`]+)`", {"code": True}),
|
||||
# 链接 [text](url)
|
||||
(r"\[([^\]]+)\]\(([^)]+)\)", {"link": True}),
|
||||
# 删除线 ~~text~~
|
||||
(r"~~(.+?)~~", {"strike": True}),
|
||||
]
|
||||
|
||||
# 简化处理:逐段解析
|
||||
remaining = text
|
||||
last_end = 0
|
||||
|
||||
# 合并所有匹配项
|
||||
all_matches = []
|
||||
|
||||
for pattern, style in patterns:
|
||||
for match in re.finditer(pattern, text):
|
||||
# 获取匹配的文本内容
|
||||
groups = match.groups()
|
||||
matched_text = next((g for g in groups if g is not None), "")
|
||||
all_matches.append(
|
||||
{
|
||||
"start": match.start(),
|
||||
"end": match.end(),
|
||||
"text": matched_text,
|
||||
"style": style,
|
||||
"full_match": match.group(0),
|
||||
"url": (
|
||||
groups[1] if style.get("link") and len(groups) > 1 else None
|
||||
),
|
||||
}
|
||||
)
|
||||
|
||||
# 按位置排序
|
||||
all_matches.sort(key=lambda x: x["start"])
|
||||
|
||||
# 移除重叠的匹配
|
||||
filtered_matches = []
|
||||
last_end = 0
|
||||
for m in all_matches:
|
||||
if m["start"] >= last_end:
|
||||
filtered_matches.append(m)
|
||||
last_end = m["end"]
|
||||
|
||||
# 构建最终文本
|
||||
pos = 0
|
||||
for match in filtered_matches:
|
||||
# 添加匹配前的普通文本
|
||||
if match["start"] > pos:
|
||||
plain_text = text[pos : match["start"]]
|
||||
if plain_text:
|
||||
paragraph.add_run(plain_text)
|
||||
|
||||
# 添加格式化文本
|
||||
style = match["style"]
|
||||
run_text = match["text"]
|
||||
|
||||
if style.get("link"):
|
||||
# 链接处理
|
||||
run = paragraph.add_run(run_text)
|
||||
run.font.color.rgb = RGBColor(0, 0, 255)
|
||||
run.font.underline = True
|
||||
elif style.get("code"):
|
||||
# 行内代码
|
||||
run = paragraph.add_run(run_text)
|
||||
run.font.name = "Consolas"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "SimHei")
|
||||
run.font.size = Pt(10)
|
||||
# 添加背景色
|
||||
shading = OxmlElement("w:shd")
|
||||
shading.set(qn("w:fill"), "E8E8E8")
|
||||
run._element.rPr.append(shading)
|
||||
else:
|
||||
run = paragraph.add_run(run_text)
|
||||
if style.get("bold"):
|
||||
run.bold = True
|
||||
if style.get("italic"):
|
||||
run.italic = True
|
||||
if style.get("strike"):
|
||||
run.font.strike = True
|
||||
|
||||
pos = match["end"]
|
||||
|
||||
# 添加剩余的普通文本
|
||||
if pos < len(text):
|
||||
paragraph.add_run(text[pos:])
|
||||
|
||||
def add_code_block(self, doc: Document, code: str, language: str = ""):
|
||||
"""添加代码块,支持语法高亮"""
|
||||
# 语法高亮颜色映射 (基于常见的 IDE 配色)
|
||||
TOKEN_COLORS = {
|
||||
Token.Keyword: RGBColor(0, 92, 197), # macOS 风格蓝 - 关键字
|
||||
Token.Keyword.Constant: RGBColor(0, 92, 197),
|
||||
Token.Keyword.Declaration: RGBColor(0, 92, 197),
|
||||
Token.Keyword.Namespace: RGBColor(0, 92, 197),
|
||||
Token.Keyword.Type: RGBColor(0, 92, 197),
|
||||
Token.Name.Function: RGBColor(0, 0, 0), # 函数名保持黑色
|
||||
Token.Name.Class: RGBColor(38, 82, 120), # 深青蓝 - 类名
|
||||
Token.Name.Decorator: RGBColor(170, 51, 0), # 暖橙 - 装饰器
|
||||
Token.Name.Builtin: RGBColor(0, 110, 71), # 墨绿 - 内置
|
||||
Token.String: RGBColor(196, 26, 22), # 红色 - 字符串
|
||||
Token.String.Doc: RGBColor(109, 120, 133), # 灰 - 文档字符串
|
||||
Token.Comment: RGBColor(109, 120, 133), # 灰 - 注释
|
||||
Token.Comment.Single: RGBColor(109, 120, 133),
|
||||
Token.Comment.Multiline: RGBColor(109, 120, 133),
|
||||
Token.Number: RGBColor(28, 0, 207), # 靛蓝 - 数字
|
||||
Token.Number.Integer: RGBColor(28, 0, 207),
|
||||
Token.Number.Float: RGBColor(28, 0, 207),
|
||||
Token.Operator: RGBColor(90, 99, 120), # 灰蓝 - 运算符
|
||||
Token.Punctuation: RGBColor(0, 0, 0), # 黑色 - 标点
|
||||
}
|
||||
|
||||
def get_token_color(token_type):
|
||||
"""递归查找 token 颜色"""
|
||||
while token_type:
|
||||
if token_type in TOKEN_COLORS:
|
||||
return TOKEN_COLORS[token_type]
|
||||
token_type = token_type.parent
|
||||
return None
|
||||
|
||||
# 添加语言标签(如果有)
|
||||
if language:
|
||||
lang_para = doc.add_paragraph()
|
||||
lang_para.paragraph_format.space_before = Pt(6)
|
||||
lang_para.paragraph_format.space_after = Pt(0)
|
||||
lang_para.paragraph_format.left_indent = Cm(0.5)
|
||||
lang_run = lang_para.add_run(language.upper())
|
||||
lang_run.font.name = "Consolas"
|
||||
lang_run.font.size = Pt(8)
|
||||
lang_run.font.color.rgb = RGBColor(100, 100, 100)
|
||||
lang_run.font.bold = True
|
||||
|
||||
# 添加代码块段落
|
||||
paragraph = doc.add_paragraph()
|
||||
paragraph.paragraph_format.left_indent = Cm(0.5)
|
||||
paragraph.paragraph_format.space_before = Pt(3) if language else Pt(6)
|
||||
paragraph.paragraph_format.space_after = Pt(6)
|
||||
|
||||
# 添加浅灰色背景
|
||||
shading = OxmlElement("w:shd")
|
||||
shading.set(qn("w:fill"), "F7F7F7")
|
||||
paragraph._element.pPr.append(shading)
|
||||
|
||||
# 尝试使用 Pygments 进行语法高亮
|
||||
if PYGMENTS_AVAILABLE and language:
|
||||
try:
|
||||
lexer = get_lexer_by_name(language, stripall=False)
|
||||
except Exception:
|
||||
lexer = TextLexer()
|
||||
|
||||
tokens = list(lex(code, lexer))
|
||||
|
||||
for token_type, token_value in tokens:
|
||||
if not token_value:
|
||||
continue
|
||||
run = paragraph.add_run(token_value)
|
||||
run.font.name = "Consolas"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "SimHei")
|
||||
run.font.size = Pt(10)
|
||||
|
||||
# 应用颜色
|
||||
color = get_token_color(token_type)
|
||||
if color:
|
||||
run.font.color.rgb = color
|
||||
|
||||
# 关键字加粗
|
||||
if token_type in Token.Keyword:
|
||||
run.font.bold = True
|
||||
else:
|
||||
# 无语法高亮,纯文本显示
|
||||
run = paragraph.add_run(code)
|
||||
run.font.name = "Consolas"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "SimHei")
|
||||
run.font.size = Pt(10)
|
||||
|
||||
def add_table(self, doc: Document, table_lines: List[str]):
|
||||
"""添加表格,支持表头底色与隔行底色"""
|
||||
if len(table_lines) < 2:
|
||||
return
|
||||
|
||||
def _set_cell_shading(cell, fill: str):
|
||||
tc_pr = cell._element.get_or_add_tcPr()
|
||||
shd = OxmlElement("w:shd")
|
||||
shd.set(qn("w:fill"), fill)
|
||||
tc_pr.append(shd)
|
||||
|
||||
header_fill = "F2F2F2"
|
||||
zebra_fill = "FBFBFB"
|
||||
|
||||
# 解析表格数据
|
||||
rows = []
|
||||
for line in table_lines:
|
||||
cells = [cell.strip() for cell in line.strip().strip("|").split("|")]
|
||||
# 跳过分隔行
|
||||
if all(re.fullmatch(r"[-:]+", cell) for cell in cells):
|
||||
continue
|
||||
rows.append(cells)
|
||||
|
||||
if not rows:
|
||||
return
|
||||
|
||||
# 确定列数
|
||||
num_cols = max(len(row) for row in rows)
|
||||
|
||||
# 创建表格
|
||||
table = doc.add_table(rows=len(rows), cols=num_cols)
|
||||
table.style = "Table Grid"
|
||||
table.alignment = WD_TABLE_ALIGNMENT.CENTER
|
||||
|
||||
# 填充表格
|
||||
for row_idx, row_data in enumerate(rows):
|
||||
row = table.rows[row_idx]
|
||||
for col_idx, cell_text in enumerate(row_data):
|
||||
if col_idx < num_cols:
|
||||
cell = row.cells[col_idx]
|
||||
# 清除默认段落
|
||||
cell.paragraphs[0].clear()
|
||||
para = cell.paragraphs[0]
|
||||
para.paragraph_format.space_after = Pt(3)
|
||||
para.paragraph_format.space_before = Pt(1)
|
||||
para.alignment = WD_ALIGN_PARAGRAPH.LEFT
|
||||
|
||||
self.add_formatted_text(para, cell_text)
|
||||
|
||||
# 设置单元格字体
|
||||
for run in para.runs:
|
||||
run.font.name = "Times New Roman"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "宋体")
|
||||
run.font.size = Pt(10)
|
||||
|
||||
# 表头加粗并填充底色
|
||||
if row_idx == 0:
|
||||
for run in para.runs:
|
||||
run.bold = True
|
||||
_set_cell_shading(cell, header_fill)
|
||||
# 隔行底色
|
||||
elif row_idx % 2 == 1:
|
||||
_set_cell_shading(cell, zebra_fill)
|
||||
|
||||
# 统一列对齐为左对齐,避免居中导致阅读困难
|
||||
for row in table.rows:
|
||||
for cell in row.cells:
|
||||
for para in cell.paragraphs:
|
||||
para.alignment = WD_ALIGN_PARAGRAPH.LEFT
|
||||
|
||||
def add_list_to_doc(
|
||||
self, doc: Document, items: List[Tuple[int, str]], list_type: str
|
||||
):
|
||||
"""添加列表"""
|
||||
for indent, text in items:
|
||||
paragraph = doc.add_paragraph()
|
||||
|
||||
if list_type == "unordered":
|
||||
# 无序列表使用项目符号
|
||||
paragraph.style = "List Bullet"
|
||||
else:
|
||||
# 有序列表使用编号
|
||||
paragraph.style = "List Number"
|
||||
|
||||
# 设置缩进
|
||||
paragraph.paragraph_format.left_indent = Cm(0.5 * (indent + 1))
|
||||
|
||||
# 添加格式化文本
|
||||
self.add_formatted_text(paragraph, text)
|
||||
|
||||
# 设置字体
|
||||
for run in paragraph.runs:
|
||||
run.font.name = "Times New Roman"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "宋体")
|
||||
|
||||
def add_horizontal_rule(self, doc: Document):
|
||||
"""添加水平分割线"""
|
||||
paragraph = doc.add_paragraph()
|
||||
paragraph.paragraph_format.space_before = Pt(12)
|
||||
paragraph.paragraph_format.space_after = Pt(12)
|
||||
|
||||
# 添加底部边框作为分割线
|
||||
pPr = paragraph._element.get_or_add_pPr()
|
||||
pBdr = OxmlElement("w:pBdr")
|
||||
bottom = OxmlElement("w:bottom")
|
||||
bottom.set(qn("w:val"), "single")
|
||||
bottom.set(qn("w:sz"), "6")
|
||||
bottom.set(qn("w:space"), "1")
|
||||
bottom.set(qn("w:color"), "auto")
|
||||
pBdr.append(bottom)
|
||||
pPr.append(pBdr)
|
||||
|
||||
def add_blockquote(self, doc: Document, text: str):
|
||||
"""添加引用块,带有左侧边框和灰色背景"""
|
||||
for line in text.split("\n"):
|
||||
paragraph = doc.add_paragraph()
|
||||
paragraph.paragraph_format.left_indent = Cm(1.0)
|
||||
paragraph.paragraph_format.space_before = Pt(3)
|
||||
paragraph.paragraph_format.space_after = Pt(3)
|
||||
|
||||
# 添加左侧边框
|
||||
pPr = paragraph._element.get_or_add_pPr()
|
||||
pBdr = OxmlElement("w:pBdr")
|
||||
left = OxmlElement("w:left")
|
||||
left.set(qn("w:val"), "single")
|
||||
left.set(qn("w:sz"), "24") # 边框粗细
|
||||
left.set(qn("w:space"), "4") # 边框与文字间距
|
||||
left.set(qn("w:color"), "CCCCCC") # 灰色边框
|
||||
pBdr.append(left)
|
||||
pPr.append(pBdr)
|
||||
|
||||
# 添加浅灰色背景
|
||||
shading = OxmlElement("w:shd")
|
||||
shading.set(qn("w:fill"), "F9F9F9")
|
||||
pPr.append(shading)
|
||||
|
||||
# 添加格式化文本
|
||||
self.add_formatted_text(paragraph, line)
|
||||
|
||||
# 设置字体为斜体灰色
|
||||
for run in paragraph.runs:
|
||||
run.font.name = "Times New Roman"
|
||||
run._element.rPr.rFonts.set(qn("w:eastAsia"), "楷体")
|
||||
run.font.color.rgb = RGBColor(85, 85, 85) # 深灰色文字
|
||||
run.italic = True
|
||||
@@ -2,12 +2,33 @@
|
||||
|
||||
This plugin allows you to export your chat history to an Excel (.xlsx) file directly from the chat interface.
|
||||
|
||||
## What's New in v0.3.6
|
||||
|
||||
- **OpenWebUI-Style Theme**: Modern dark header (#1f2937) with light gray zebra striping for better readability.
|
||||
- **Zebra Striping**: Alternating row colors (#ffffff / #f3f4f6) for improved visual scanning.
|
||||
- **Smart Data Type Conversion**: Automatically converts columns to numeric or datetime types with fallback to string.
|
||||
- **Full Cell Bold/Italic**: Supports full cell Markdown bold (`**text**`) and italic (`*text*`) formatting in Excel.
|
||||
- **Partial Markdown Cleanup**: Automatically removes partial Markdown formatting symbols (e.g., `Some **bold** text` → `Some bold text`) for cleaner Excel output.
|
||||
- **Export Scope**: Added `EXPORT_SCOPE` valve to choose between exporting tables from the "Last Message" (default) or "All Messages".
|
||||
- **Smart Sheet Naming**: Automatically names sheets based on Markdown headers, AI titles (if enabled), or message index (e.g., `Msg1-Tab1`).
|
||||
- **Multiple Tables Support**: Improved handling of multiple tables within single or multiple messages.
|
||||
- **Smart Filename Generation**: Supports generating filenames based on Chat Title, AI Summary, or Markdown Headers.
|
||||
- **Configuration Options**: Added `TITLE_SOURCE` setting to control filename generation strategy.
|
||||
- **AI Title Generation**: Added `MODEL_ID` setting to specify the model for AI title generation, with progress notifications.
|
||||
|
||||
## Features
|
||||
|
||||
- **One-Click Export**: Adds an "Export to Excel" button to the chat.
|
||||
- **Automatic Header Extraction**: Intelligently identifies table headers from the chat content.
|
||||
- **Multi-Table Support**: Handles multiple tables within a single chat session.
|
||||
|
||||
## Configuration
|
||||
|
||||
- **Title Source**: Choose how the filename is generated:
|
||||
- `chat_title`: Use the chat title (default).
|
||||
- `ai_generated`: Use AI to generate a concise title from the content.
|
||||
- `markdown_title`: Extract the first H1/H2 header from the markdown content.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Install the plugin.
|
||||
|
||||
@@ -2,16 +2,37 @@
|
||||
|
||||
此插件允许你直接从聊天界面将对话历史导出为 Excel (.xlsx) 文件。
|
||||
|
||||
## v0.3.6 更新内容
|
||||
|
||||
- **OpenWebUI 风格主题**:现代深灰表头 (#1f2937),搭配浅灰斑马纹,提升可读性。
|
||||
- **斑马纹效果**:隔行变色(#ffffff / #f3f4f6),方便视觉扫描。
|
||||
- **智能数据类型转换**:自动将列转换为数字或日期类型,无法转换时保持字符串。
|
||||
- **全单元格粗体/斜体**:支持 Excel 中的全单元格 Markdown 粗体 (`**text**`) 和斜体 (`*text*`) 格式。
|
||||
- **部分 Markdown 清理**:自动移除部分 Markdown 格式符号(如 `部分**加粗**文本` → `部分加粗文本`),使 Excel 输出更整洁。
|
||||
- **导出范围**: 新增 `EXPORT_SCOPE` 配置项,可选择导出"最后一条消息"(默认)或"所有消息"中的表格。
|
||||
- **智能 Sheet 命名**: 根据 Markdown 标题、AI 标题(如启用)或消息索引(如 `消息1-表1`)自动命名 Sheet。
|
||||
- **多表格支持**: 优化了对单条或多条消息中包含多个表格的处理。
|
||||
- **智能文件名生成**:支持根据对话标题、AI 总结或 Markdown 标题生成文件名。
|
||||
- **配置选项**:新增 `TITLE_SOURCE` 设置,用于控制文件名生成策略。
|
||||
- **AI 标题生成**:新增 `MODEL_ID` 设置用于指定 AI 标题生成模型,并支持生成进度通知。
|
||||
|
||||
## 功能特点
|
||||
|
||||
- **一键导出**:在聊天界面添加“导出为 Excel”按钮。
|
||||
- **一键导出**:在聊天界面添加"导出为 Excel"按钮。
|
||||
- **自动表头提取**:智能识别聊天内容中的表格标题。
|
||||
- **多表支持**:支持处理单次对话中的多个表格。
|
||||
|
||||
## 配置
|
||||
|
||||
- **标题来源 (Title Source)**:选择文件名的生成方式:
|
||||
- `chat_title`:使用对话标题(默认)。
|
||||
- `ai_generated`:使用 AI 根据内容生成简洁标题。
|
||||
- `markdown_title`:提取 Markdown 内容中的第一个 H1/H2 标题。
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 安装插件。
|
||||
2. 在任意对话中,点击“导出为 Excel”按钮。
|
||||
2. 在任意对话中,点击"导出为 Excel"按钮。
|
||||
3. 文件将自动下载到你的设备。
|
||||
|
||||
## 作者
|
||||
|
||||
@@ -1,11 +1,12 @@
|
||||
"""
|
||||
title: Export to Excel
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie
|
||||
funding_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
version: 0.3.3
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 0.3.7
|
||||
openwebui_id: 244b8f9d-7459-47d6-84d3-c7ae8e3ec710
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwYXRoIGQ9Ik0xNSAySDZhMiAyIDAgMCAwLTIgMnYxNmEyIDIgMCAwIDAgMiAyaDEyYTIgMiAwIDAgMCAyLTJWN1oiLz48cGF0aCBkPSJNMTQgMnY0YTIgMiAwIDAgMCAyIDJoNCIvPjxwYXRoIGQ9Ik04IDEzaDIiLz48cGF0aCBkPSJNMTQgMTNoMiIvPjxwYXRoIGQ9Ik04IDE3aDIiLz48cGF0aCBkPSJNMTQgMTdoMiIvPjwvc3ZnPg==
|
||||
description: Exports the current chat history to an Excel (.xlsx) file, with automatic header extraction.
|
||||
description: Extracts tables from chat messages and exports them to Excel (.xlsx) files with smart formatting.
|
||||
"""
|
||||
|
||||
import os
|
||||
@@ -15,19 +16,85 @@ import base64
|
||||
from fastapi import FastAPI, HTTPException
|
||||
from typing import Optional, Callable, Awaitable, Any, List, Dict
|
||||
import datetime
|
||||
import asyncio
|
||||
from open_webui.models.chats import Chats
|
||||
from open_webui.models.users import Users
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from pydantic import BaseModel, Field
|
||||
from typing import Literal
|
||||
|
||||
app = FastAPI()
|
||||
|
||||
|
||||
class Action:
|
||||
class Valves(BaseModel):
|
||||
TITLE_SOURCE: Literal["chat_title", "ai_generated", "markdown_title"] = Field(
|
||||
default="chat_title",
|
||||
description="Title Source: 'chat_title' (Chat Title), 'ai_generated' (AI Generated), 'markdown_title' (Markdown Title)",
|
||||
)
|
||||
SHOW_STATUS: bool = Field(
|
||||
default=True,
|
||||
description="Whether to show operation status updates.",
|
||||
)
|
||||
EXPORT_SCOPE: Literal["last_message", "all_messages"] = Field(
|
||||
default="last_message",
|
||||
description="Export Scope: 'last_message' (Last Message Only), 'all_messages' (All Messages)",
|
||||
)
|
||||
MODEL_ID: str = Field(
|
||||
default="",
|
||||
description="Model ID for AI title generation. Leave empty to use the current chat model.",
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False,
|
||||
description="Whether to print debug logs in the browser console.",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
self.valves = self.Valves()
|
||||
|
||||
async def _send_notification(self, emitter: Callable, type: str, content: str):
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": type, "content": content}}
|
||||
)
|
||||
async def _emit_status(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
description: str,
|
||||
done: bool = False,
|
||||
):
|
||||
"""Emits a status update event."""
|
||||
if self.valves.SHOW_STATUS and emitter:
|
||||
await emitter(
|
||||
{"type": "status", "data": {"description": description, "done": done}}
|
||||
)
|
||||
|
||||
async def _emit_notification(
|
||||
self,
|
||||
emitter: Optional[Callable[[Any], Awaitable[None]]],
|
||||
content: str,
|
||||
ntype: str = "info",
|
||||
):
|
||||
"""Emits a notification event (info, success, warning, error)."""
|
||||
if emitter:
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": ntype, "content": content}}
|
||||
)
|
||||
|
||||
async def _emit_debug_log(self, emitter, title: str, data: dict):
|
||||
"""Print structured debug logs in the browser console"""
|
||||
if not self.valves.SHOW_DEBUG_LOG or not emitter:
|
||||
return
|
||||
|
||||
try:
|
||||
import json
|
||||
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
await emitter({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
|
||||
async def action(
|
||||
self,
|
||||
@@ -35,6 +102,7 @@ class Action:
|
||||
__user__=None,
|
||||
__event_emitter__=None,
|
||||
__event_call__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
__request__: Optional[Any] = None,
|
||||
):
|
||||
print(f"action:{__name__}")
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
@@ -53,8 +121,6 @@ class Action:
|
||||
user_id = __user__.get("id", "unknown_user")
|
||||
|
||||
if __event_emitter__:
|
||||
last_assistant_message = body["messages"][-1]
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
@@ -63,24 +129,181 @@ class Action:
|
||||
)
|
||||
|
||||
try:
|
||||
message_content = last_assistant_message["content"]
|
||||
tables = self.extract_tables_from_message(message_content)
|
||||
messages = body.get("messages", [])
|
||||
if not messages:
|
||||
raise HTTPException(status_code=400, detail="No messages found.")
|
||||
|
||||
if not tables:
|
||||
raise HTTPException(status_code=400, detail="No tables found.")
|
||||
# Determine messages to process based on scope
|
||||
target_messages = []
|
||||
if self.valves.EXPORT_SCOPE == "all_messages":
|
||||
target_messages = messages
|
||||
else:
|
||||
target_messages = [messages[-1]]
|
||||
|
||||
# Get dynamic filename and sheet names
|
||||
workbook_name, sheet_names = self.generate_names_from_content(
|
||||
message_content, tables
|
||||
)
|
||||
all_tables = []
|
||||
all_sheet_names = []
|
||||
|
||||
# Process messages
|
||||
for msg_index, msg in enumerate(target_messages):
|
||||
content = msg.get("content", "")
|
||||
tables = self.extract_tables_from_message(content)
|
||||
|
||||
if not tables:
|
||||
continue
|
||||
|
||||
# Generate sheet names for this message's tables
|
||||
# If multiple messages, we need to ensure uniqueness across the whole workbook
|
||||
# We'll generate base names here and deduplicate later if needed,
|
||||
# or better: generate unique names on the fly.
|
||||
|
||||
# Extract headers for this message
|
||||
headers = []
|
||||
lines = content.split("\n")
|
||||
for i, line in enumerate(lines):
|
||||
if re.match(r"^#{1,6}\s+", line):
|
||||
headers.append(
|
||||
{
|
||||
"text": re.sub(r"^#{1,6}\s+", "", line).strip(),
|
||||
"line_num": i,
|
||||
}
|
||||
)
|
||||
|
||||
for table_index, table in enumerate(tables):
|
||||
sheet_name = ""
|
||||
|
||||
# 1. Try Markdown Header (closest above)
|
||||
table_start_line = table["start_line"] - 1
|
||||
closest_header_text = None
|
||||
candidate_headers = [
|
||||
h for h in headers if h["line_num"] < table_start_line
|
||||
]
|
||||
if candidate_headers:
|
||||
closest_header = max(
|
||||
candidate_headers, key=lambda x: x["line_num"]
|
||||
)
|
||||
closest_header_text = closest_header["text"]
|
||||
|
||||
if closest_header_text:
|
||||
sheet_name = self.clean_sheet_name(closest_header_text)
|
||||
|
||||
# 2. AI Generated (Only if explicitly enabled and we have a request object)
|
||||
# Note: Generating titles for EVERY table in all messages might be too slow/expensive.
|
||||
# We'll skip this for 'all_messages' scope to avoid timeout, unless it's just one message.
|
||||
if (
|
||||
not sheet_name
|
||||
and self.valves.TITLE_SOURCE == "ai_generated"
|
||||
and len(target_messages) == 1
|
||||
):
|
||||
# Logic for AI generation (simplified for now, reusing existing flow if possible)
|
||||
pass
|
||||
|
||||
# 3. Fallback: Message Index
|
||||
if not sheet_name:
|
||||
if len(target_messages) > 1:
|
||||
# Use global message index (from original list if possible, but here we iterate target_messages)
|
||||
# Let's use the loop index.
|
||||
# If multiple tables in one message: "Msg 1 - Table 1"
|
||||
if len(tables) > 1:
|
||||
sheet_name = f"Msg{msg_index+1}-Tab{table_index+1}"
|
||||
else:
|
||||
sheet_name = f"Msg{msg_index+1}"
|
||||
else:
|
||||
# Single message (last_message scope)
|
||||
if len(tables) > 1:
|
||||
sheet_name = f"Table {table_index+1}"
|
||||
else:
|
||||
sheet_name = "Sheet1"
|
||||
|
||||
all_tables.append(table)
|
||||
all_sheet_names.append(sheet_name)
|
||||
|
||||
if not all_tables:
|
||||
raise HTTPException(
|
||||
status_code=400, detail="No tables found in the selected scope."
|
||||
)
|
||||
|
||||
# Deduplicate sheet names
|
||||
final_sheet_names = []
|
||||
seen_names = {}
|
||||
for name in all_sheet_names:
|
||||
base_name = name
|
||||
counter = 1
|
||||
while name in seen_names:
|
||||
name = f"{base_name} ({counter})"
|
||||
counter += 1
|
||||
seen_names[name] = True
|
||||
final_sheet_names.append(name)
|
||||
|
||||
# Notify user about the number of tables found
|
||||
table_count = len(all_tables)
|
||||
if self.valves.EXPORT_SCOPE == "all_messages":
|
||||
await self._emit_notification(
|
||||
__event_emitter__,
|
||||
f"Found {table_count} table(s) in all messages.",
|
||||
"info",
|
||||
)
|
||||
# Wait a moment for user to see the notification before download dialog
|
||||
await asyncio.sleep(1.5)
|
||||
# Generate Workbook Title (Filename)
|
||||
# Use the title of the chat, or the first header of the first message with tables
|
||||
title = ""
|
||||
chat_ctx = self._get_chat_context(body, None)
|
||||
chat_id = chat_ctx["chat_id"]
|
||||
chat_title = ""
|
||||
if chat_id:
|
||||
chat_title = await self.fetch_chat_title(chat_id, user_id)
|
||||
|
||||
if (
|
||||
self.valves.TITLE_SOURCE == "chat_title"
|
||||
or not self.valves.TITLE_SOURCE
|
||||
):
|
||||
title = chat_title
|
||||
elif self.valves.TITLE_SOURCE == "ai_generated":
|
||||
# Use AI to generate a title based on message content
|
||||
if target_messages and __request__:
|
||||
# Get content from the first message with tables
|
||||
content_for_title = ""
|
||||
for msg in target_messages:
|
||||
msg_content = msg.get("content", "")
|
||||
if msg_content:
|
||||
content_for_title = msg_content
|
||||
break
|
||||
if content_for_title:
|
||||
title = await self.generate_title_using_ai(
|
||||
body,
|
||||
content_for_title,
|
||||
user_id,
|
||||
__request__,
|
||||
__event_emitter__,
|
||||
)
|
||||
elif self.valves.TITLE_SOURCE == "markdown_title":
|
||||
# Try to find first header in the first message that has content
|
||||
for msg in target_messages:
|
||||
extracted = self.extract_title(msg.get("content", ""))
|
||||
if extracted:
|
||||
title = extracted
|
||||
break
|
||||
|
||||
# Fallback for filename
|
||||
if not title:
|
||||
if chat_title:
|
||||
title = chat_title
|
||||
else:
|
||||
# Try extracting from content again if not already tried
|
||||
if self.valves.TITLE_SOURCE != "markdown_title":
|
||||
for msg in target_messages:
|
||||
extracted = self.extract_title(msg.get("content", ""))
|
||||
if extracted:
|
||||
title = extracted
|
||||
break
|
||||
|
||||
# Use optimized filename generation logic
|
||||
current_datetime = datetime.datetime.now()
|
||||
formatted_date = current_datetime.strftime("%Y%m%d")
|
||||
|
||||
# If no title found, use user_yyyymmdd format
|
||||
if not workbook_name:
|
||||
if not title:
|
||||
workbook_name = f"{user_name}_{formatted_date}"
|
||||
else:
|
||||
workbook_name = self.clean_filename(title)
|
||||
|
||||
filename = f"{workbook_name}.xlsx"
|
||||
excel_file_path = os.path.join(
|
||||
@@ -89,8 +312,10 @@ class Action:
|
||||
|
||||
os.makedirs(os.path.dirname(excel_file_path), exist_ok=True)
|
||||
|
||||
# Save tables to Excel (using enhanced formatting)
|
||||
self.save_tables_to_excel_enhanced(tables, excel_file_path, sheet_names)
|
||||
# Save tables to Excel
|
||||
self.save_tables_to_excel_enhanced(
|
||||
all_tables, excel_file_path, final_sheet_names
|
||||
)
|
||||
|
||||
# Trigger file download
|
||||
if __event_call__:
|
||||
@@ -153,8 +378,8 @@ class Action:
|
||||
},
|
||||
}
|
||||
)
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", "No tables found to export!"
|
||||
await self._emit_notification(
|
||||
__event_emitter__, "No tables found to export!", "error"
|
||||
)
|
||||
raise e
|
||||
except Exception as e:
|
||||
@@ -168,10 +393,185 @@ class Action:
|
||||
},
|
||||
}
|
||||
)
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", "No tables found to export!"
|
||||
await self._emit_notification(
|
||||
__event_emitter__, "No tables found to export!", "error"
|
||||
)
|
||||
|
||||
async def generate_title_using_ai(
|
||||
self,
|
||||
body: dict,
|
||||
content: str,
|
||||
user_id: str,
|
||||
request: Any,
|
||||
event_emitter: Callable = None,
|
||||
) -> str:
|
||||
if not request:
|
||||
return ""
|
||||
|
||||
try:
|
||||
user_obj = Users.get_user_by_id(user_id)
|
||||
# Use configured MODEL_ID or fallback to current chat model
|
||||
model = (
|
||||
self.valves.MODEL_ID.strip()
|
||||
if self.valves.MODEL_ID
|
||||
else body.get("model")
|
||||
)
|
||||
|
||||
payload = {
|
||||
"model": model,
|
||||
"messages": [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a helpful assistant. Generate a short, concise filename (max 10 words) for an Excel export based on the following content. Do not use quotes or file extensions. Avoid special characters that are invalid in filenames. Only output the filename.",
|
||||
},
|
||||
{"role": "user", "content": content[:2000]}, # Limit content length
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
# Define the generation task
|
||||
async def generate_task():
|
||||
return await generate_chat_completion(request, payload, user_obj)
|
||||
|
||||
# Define the notification task
|
||||
async def notification_task():
|
||||
# Send initial notification immediately
|
||||
if event_emitter:
|
||||
await self._emit_notification(
|
||||
event_emitter,
|
||||
"AI is generating a filename for your Excel file...",
|
||||
"info",
|
||||
)
|
||||
|
||||
# Subsequent notifications every 5 seconds
|
||||
while True:
|
||||
await asyncio.sleep(5)
|
||||
if event_emitter:
|
||||
await self._emit_notification(
|
||||
event_emitter,
|
||||
"Still generating filename, please be patient...",
|
||||
"info",
|
||||
)
|
||||
|
||||
# Run tasks concurrently
|
||||
gen_future = asyncio.ensure_future(generate_task())
|
||||
notify_future = asyncio.ensure_future(notification_task())
|
||||
|
||||
done, pending = await asyncio.wait(
|
||||
[gen_future, notify_future], return_when=asyncio.FIRST_COMPLETED
|
||||
)
|
||||
|
||||
# Cancel notification task if generation is done
|
||||
if not notify_future.done():
|
||||
notify_future.cancel()
|
||||
|
||||
# Get result
|
||||
if gen_future in done:
|
||||
response = gen_future.result()
|
||||
if response and "choices" in response:
|
||||
return response["choices"][0]["message"]["content"].strip()
|
||||
else:
|
||||
# Should not happen if return_when=FIRST_COMPLETED and we cancel notify
|
||||
await gen_future
|
||||
response = gen_future.result()
|
||||
if response and "choices" in response:
|
||||
return response["choices"][0]["message"]["content"].strip()
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error generating title: {e}")
|
||||
if event_emitter:
|
||||
await self._emit_notification(
|
||||
event_emitter,
|
||||
f"AI title generation failed, using default title. Error: {str(e)}",
|
||||
"warning",
|
||||
)
|
||||
|
||||
return ""
|
||||
|
||||
def extract_title(self, content: str) -> str:
|
||||
"""Extract title from Markdown h1/h2 only"""
|
||||
lines = content.split("\n")
|
||||
for line in lines:
|
||||
# Match h1-h2 headings only
|
||||
match = re.match(r"^#{1,2}\s+(.+)$", line.strip())
|
||||
if match:
|
||||
return match.group(1).strip()
|
||||
return ""
|
||||
|
||||
def _get_user_context(self, __user__: Optional[Dict[str, Any]]) -> Dict[str, str]:
|
||||
"""Safely extracts user context information."""
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_data = __user__[0] if __user__ else {}
|
||||
elif isinstance(__user__, dict):
|
||||
user_data = __user__
|
||||
else:
|
||||
user_data = {}
|
||||
|
||||
return {
|
||||
"user_id": user_data.get("id", "unknown_user"),
|
||||
"user_name": user_data.get("name", "User"),
|
||||
"user_language": user_data.get("language", "en-US"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""
|
||||
Unified extraction of chat context information (chat_id, message_id).
|
||||
Prioritizes extraction from body, then metadata.
|
||||
"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
# 1. Try to get from body
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # message_id is usually 'id' in body
|
||||
|
||||
# Check body.metadata as fallback
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
# 2. Try to get from __metadata__ (as supplement)
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
async def fetch_chat_title(self, chat_id: str, user_id: str = "") -> str:
|
||||
"""Fetch chat title from database by chat_id"""
|
||||
if not chat_id:
|
||||
return ""
|
||||
|
||||
def _load_chat():
|
||||
if user_id:
|
||||
return Chats.get_chat_by_id_and_user_id(id=chat_id, user_id=user_id)
|
||||
return Chats.get_chat_by_id(chat_id)
|
||||
|
||||
try:
|
||||
chat = await asyncio.to_thread(_load_chat)
|
||||
except Exception as exc:
|
||||
print(f"Failed to load chat {chat_id}: {exc}")
|
||||
return ""
|
||||
|
||||
if not chat:
|
||||
return ""
|
||||
|
||||
data = getattr(chat, "chat", {}) or {}
|
||||
title = data.get("title") or getattr(chat, "title", "")
|
||||
return title.strip() if isinstance(title, str) else ""
|
||||
|
||||
def extract_tables_from_message(self, message: str) -> List[Dict]:
|
||||
"""
|
||||
Extract Markdown tables and their positions from message text
|
||||
@@ -456,24 +856,51 @@ class Action:
|
||||
with pd.ExcelWriter(file_path, engine="xlsxwriter") as writer:
|
||||
workbook = writer.book
|
||||
|
||||
# OpenWebUI-style theme colors
|
||||
HEADER_BG = "#1f2937" # Dark gray (matches OpenWebUI sidebar)
|
||||
HEADER_FG = "#ffffff" # White text
|
||||
ROW_ODD_BG = "#ffffff" # White for odd rows
|
||||
ROW_EVEN_BG = "#f3f4f6" # Light gray for even rows (zebra striping)
|
||||
BORDER_COLOR = "#e5e7eb" # Light border
|
||||
|
||||
# Define header style - Center aligned
|
||||
header_format = workbook.add_format(
|
||||
{
|
||||
"bold": True,
|
||||
"font_size": 12,
|
||||
"font_color": "white",
|
||||
"bg_color": "#00abbd",
|
||||
"font_size": 11,
|
||||
"font_name": "Arial",
|
||||
"font_color": HEADER_FG,
|
||||
"bg_color": HEADER_BG,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"align": "center",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
# Text cell style - Left aligned
|
||||
# Text cell style - Left aligned (odd rows)
|
||||
text_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
# Text cell style - Left aligned (even rows - zebra)
|
||||
text_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
@@ -482,14 +909,51 @@ class Action:
|
||||
|
||||
# Number cell style - Right aligned
|
||||
number_format = workbook.add_format(
|
||||
{"border": 1, "align": "right", "valign": "vcenter"}
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
number_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
# Integer format - Right aligned
|
||||
integer_format = workbook.add_format(
|
||||
{
|
||||
"num_format": "0",
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
integer_format_alt = workbook.add_format(
|
||||
{
|
||||
"num_format": "0",
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
@@ -499,7 +963,24 @@ class Action:
|
||||
decimal_format = workbook.add_format(
|
||||
{
|
||||
"num_format": "0.00",
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
decimal_format_alt = workbook.add_format(
|
||||
{
|
||||
"num_format": "0.00",
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "right",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
@@ -508,7 +989,24 @@ class Action:
|
||||
# Date format - Center aligned
|
||||
date_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "center",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
date_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "center",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
@@ -518,12 +1016,114 @@ class Action:
|
||||
# Sequence format - Center aligned
|
||||
sequence_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "center",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
sequence_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "center",
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
# Bold cell style (for full cell bolding)
|
||||
text_bold_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
"bold": True,
|
||||
}
|
||||
)
|
||||
|
||||
text_bold_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
"bold": True,
|
||||
}
|
||||
)
|
||||
|
||||
# Italic cell style (for full cell italics)
|
||||
text_italic_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_ODD_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
"italic": True,
|
||||
}
|
||||
)
|
||||
|
||||
text_italic_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Arial",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": ROW_EVEN_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
"italic": True,
|
||||
}
|
||||
)
|
||||
|
||||
# Code cell style (for inline code with highlight background)
|
||||
CODE_BG = "#f0f0f0" # Light gray background for code
|
||||
text_code_format = workbook.add_format(
|
||||
{
|
||||
"font_name": "Consolas",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": CODE_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
text_code_format_alt = workbook.add_format(
|
||||
{
|
||||
"font_name": "Consolas",
|
||||
"font_size": 10,
|
||||
"border": 1,
|
||||
"border_color": BORDER_COLOR,
|
||||
"bg_color": CODE_BG,
|
||||
"align": "left",
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
for i, table in enumerate(tables):
|
||||
try:
|
||||
table_data = table["data"]
|
||||
@@ -565,12 +1165,18 @@ class Action:
|
||||
|
||||
print(f"DataFrame created with columns: {list(df.columns)}")
|
||||
|
||||
# Fix pandas FutureWarning
|
||||
# Smart data type conversion using pandas infer_objects
|
||||
for col in df.columns:
|
||||
# Try numeric conversion first
|
||||
try:
|
||||
df[col] = pd.to_numeric(df[col])
|
||||
except (ValueError, TypeError):
|
||||
pass
|
||||
# Try datetime conversion
|
||||
try:
|
||||
df[col] = pd.to_datetime(df[col], errors="raise")
|
||||
except (ValueError, TypeError):
|
||||
# Keep as string, use infer_objects for optimization
|
||||
df[col] = df[col].infer_objects()
|
||||
|
||||
# Write data first (without header)
|
||||
df.to_excel(
|
||||
@@ -582,19 +1188,25 @@ class Action:
|
||||
)
|
||||
worksheet = writer.sheets[sheet_name]
|
||||
|
||||
# Apply enhanced formatting
|
||||
# Apply enhanced formatting with zebra striping
|
||||
formats = {
|
||||
"header": header_format,
|
||||
"text": [text_format, text_format_alt],
|
||||
"number": [number_format, number_format_alt],
|
||||
"integer": [integer_format, integer_format_alt],
|
||||
"decimal": [decimal_format, decimal_format_alt],
|
||||
"date": [date_format, date_format_alt],
|
||||
"sequence": [sequence_format, sequence_format_alt],
|
||||
"bold": [text_bold_format, text_bold_format_alt],
|
||||
"italic": [text_italic_format, text_italic_format_alt],
|
||||
"code": [text_code_format, text_code_format_alt],
|
||||
}
|
||||
self.apply_enhanced_formatting(
|
||||
worksheet,
|
||||
df,
|
||||
headers,
|
||||
workbook,
|
||||
header_format,
|
||||
text_format,
|
||||
number_format,
|
||||
integer_format,
|
||||
decimal_format,
|
||||
date_format,
|
||||
sequence_format,
|
||||
formats,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
@@ -611,23 +1223,22 @@ class Action:
|
||||
df,
|
||||
headers,
|
||||
workbook,
|
||||
header_format,
|
||||
text_format,
|
||||
number_format,
|
||||
integer_format,
|
||||
decimal_format,
|
||||
date_format,
|
||||
sequence_format,
|
||||
formats,
|
||||
):
|
||||
"""
|
||||
Apply enhanced formatting
|
||||
- Header: Center aligned
|
||||
Apply enhanced formatting with zebra striping
|
||||
- Header: Center aligned (dark background)
|
||||
- Number: Right aligned
|
||||
- Text: Left aligned
|
||||
- Date: Center aligned
|
||||
- Sequence: Center aligned
|
||||
- Zebra striping: alternating row colors
|
||||
- Supports full cell Markdown bold (**text**) and italic (*text*)
|
||||
"""
|
||||
try:
|
||||
# Extract format from formats dict
|
||||
header_format = formats["header"]
|
||||
|
||||
# 1. Write headers (Center aligned)
|
||||
print(f"Writing headers with enhanced alignment: {headers}")
|
||||
for col_idx, header in enumerate(headers):
|
||||
@@ -651,43 +1262,99 @@ class Action:
|
||||
else:
|
||||
column_types[col_idx] = "text"
|
||||
|
||||
# 3. Write and format data
|
||||
# 3. Write and format data with zebra striping
|
||||
for row_idx, row in df.iterrows():
|
||||
# Determine if odd or even row (0-indexed, so row 0 is odd visually as row 1)
|
||||
is_alt_row = (
|
||||
row_idx % 2 == 1
|
||||
) # Even index = odd visual row, use alt format
|
||||
|
||||
for col_idx, value in enumerate(row):
|
||||
content_type = column_types.get(col_idx, "text")
|
||||
|
||||
# Select format based on content type
|
||||
# Select format based on content type and zebra striping
|
||||
fmt_idx = 1 if is_alt_row else 0
|
||||
|
||||
if content_type == "number":
|
||||
# Number - Right aligned
|
||||
if pd.api.types.is_numeric_dtype(df.iloc[:, col_idx]):
|
||||
if pd.api.types.is_integer_dtype(df.iloc[:, col_idx]):
|
||||
current_format = integer_format
|
||||
current_format = formats["integer"][fmt_idx]
|
||||
else:
|
||||
try:
|
||||
numeric_value = float(value)
|
||||
if numeric_value.is_integer():
|
||||
current_format = integer_format
|
||||
current_format = formats["integer"][fmt_idx]
|
||||
value = int(numeric_value)
|
||||
else:
|
||||
current_format = decimal_format
|
||||
current_format = formats["decimal"][fmt_idx]
|
||||
except (ValueError, TypeError):
|
||||
current_format = decimal_format
|
||||
current_format = formats["decimal"][fmt_idx]
|
||||
else:
|
||||
current_format = number_format
|
||||
current_format = formats["number"][fmt_idx]
|
||||
|
||||
elif content_type == "date":
|
||||
# Date - Center aligned
|
||||
current_format = date_format
|
||||
current_format = formats["date"][fmt_idx]
|
||||
|
||||
elif content_type == "sequence":
|
||||
# Sequence - Center aligned
|
||||
current_format = sequence_format
|
||||
current_format = formats["sequence"][fmt_idx]
|
||||
|
||||
else:
|
||||
# Text - Left aligned
|
||||
current_format = text_format
|
||||
current_format = formats["text"][fmt_idx]
|
||||
|
||||
worksheet.write(row_idx + 1, col_idx, value, current_format)
|
||||
if content_type == "text" and isinstance(value, str):
|
||||
# Check for full cell bold (**text**)
|
||||
match_bold = re.fullmatch(r"\*\*(.+)\*\*", value.strip())
|
||||
# Check for full cell italic (*text*)
|
||||
match_italic = re.fullmatch(r"\*(.+)\*", value.strip())
|
||||
# Check for full cell code (`text`)
|
||||
match_code = re.fullmatch(r"`(.+)`", value.strip())
|
||||
|
||||
if match_bold:
|
||||
# Extract content and apply bold format
|
||||
clean_value = match_bold.group(1)
|
||||
worksheet.write(
|
||||
row_idx + 1,
|
||||
col_idx,
|
||||
clean_value,
|
||||
formats["bold"][fmt_idx],
|
||||
)
|
||||
elif match_italic:
|
||||
# Extract content and apply italic format
|
||||
clean_value = match_italic.group(1)
|
||||
worksheet.write(
|
||||
row_idx + 1,
|
||||
col_idx,
|
||||
clean_value,
|
||||
formats["italic"][fmt_idx],
|
||||
)
|
||||
elif match_code:
|
||||
# Extract content and apply code format (highlighted)
|
||||
clean_value = match_code.group(1)
|
||||
worksheet.write(
|
||||
row_idx + 1,
|
||||
col_idx,
|
||||
clean_value,
|
||||
formats["code"][fmt_idx],
|
||||
)
|
||||
else:
|
||||
# Remove partial markdown formatting symbols (can't render partial formatting in Excel)
|
||||
# Remove bold markers **text** -> text
|
||||
clean_value = re.sub(r"\*\*(.+?)\*\*", r"\1", value)
|
||||
# Remove italic markers *text* -> text (but not inside **)
|
||||
clean_value = re.sub(
|
||||
r"(?<!\*)\*([^*]+)\*(?!\*)", r"\1", clean_value
|
||||
)
|
||||
# Remove code markers `text` -> text
|
||||
clean_value = re.sub(r"`(.+?)`", r"\1", clean_value)
|
||||
worksheet.write(
|
||||
row_idx + 1, col_idx, clean_value, current_format
|
||||
)
|
||||
else:
|
||||
worksheet.write(row_idx + 1, col_idx, value, current_format)
|
||||
|
||||
# 4. Auto-adjust column width
|
||||
for col_idx, column in enumerate(headers):
|
||||
@@ -777,3 +1444,6 @@ class Action:
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error in basic formatting: {str(e)}")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error in basic formatting: {str(e)}")
|
||||
|
||||
1462
plugins/actions/export_to_excel/export_to_excel_cn.py
Normal file
1462
plugins/actions/export_to_excel/export_to_excel_cn.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -1,806 +0,0 @@
|
||||
"""
|
||||
title: 导出为 Excel
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie
|
||||
funding_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
version: 0.3.3
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwYXRoIGQ9Ik0xNSAySDZhMiAyIDAgMCAwLTIgMnYxNmEyIDIgMCAwIDAgMiAyaDEyYTIgMiAwIDAgMCAyLTJWN1oiLz48cGF0aCBkPSJNMTQgMnY0YTIgMiAwIDAgMCAyIDJoNCIvPjxwYXRoIGQ9Ik04IDEzaDIiLz48cGF0aCBkPSJNMTQgMTNoMiIvPjxwYXRoIGQ9Ik04IDE3aDIiLz48cGF0aCBkPSJNMTQgMTdoMiIvPjwvc3ZnPg==
|
||||
description: 将当前对话历史导出为 Excel (.xlsx) 文件,支持自动提取表头。
|
||||
"""
|
||||
|
||||
import os
|
||||
import pandas as pd
|
||||
import re
|
||||
import base64
|
||||
from fastapi import FastAPI, HTTPException
|
||||
from typing import Optional, Callable, Awaitable, Any, List, Dict
|
||||
import datetime
|
||||
|
||||
app = FastAPI()
|
||||
|
||||
|
||||
class Action:
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
async def _send_notification(self, emitter: Callable, type: str, content: str):
|
||||
await emitter(
|
||||
{"type": "notification", "data": {"type": type, "content": content}}
|
||||
)
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
__user__=None,
|
||||
__event_emitter__=None,
|
||||
__event_call__: Optional[Callable[[Any], Awaitable[None]]] = None,
|
||||
):
|
||||
print(f"action:{__name__}")
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_language = (
|
||||
__user__[0].get("language", "zh-CN") if __user__ else "zh-CN"
|
||||
)
|
||||
user_name = __user__[0].get("name", "用户") if __user__[0] else "用户"
|
||||
user_id = (
|
||||
__user__[0]["id"]
|
||||
if __user__ and "id" in __user__[0]
|
||||
else "unknown_user"
|
||||
)
|
||||
elif isinstance(__user__, dict):
|
||||
user_language = __user__.get("language", "zh-CN")
|
||||
user_name = __user__.get("name", "用户")
|
||||
user_id = __user__.get("id", "unknown_user")
|
||||
|
||||
if __event_emitter__:
|
||||
last_assistant_message = body["messages"][-1]
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "正在保存到文件...", "done": False},
|
||||
}
|
||||
)
|
||||
|
||||
try:
|
||||
message_content = last_assistant_message["content"]
|
||||
tables = self.extract_tables_from_message(message_content)
|
||||
|
||||
if not tables:
|
||||
raise HTTPException(status_code=400, detail="未找到任何表格。")
|
||||
|
||||
# 获取动态文件名和sheet名称
|
||||
workbook_name, sheet_names = self.generate_names_from_content(
|
||||
message_content, tables
|
||||
)
|
||||
|
||||
# 使用优化后的文件名生成逻辑
|
||||
current_datetime = datetime.datetime.now()
|
||||
formatted_date = current_datetime.strftime("%Y%m%d")
|
||||
|
||||
# 如果没找到标题则使用 user_yyyymmdd 格式
|
||||
if not workbook_name:
|
||||
workbook_name = f"{user_name}_{formatted_date}"
|
||||
|
||||
filename = f"{workbook_name}.xlsx"
|
||||
excel_file_path = os.path.join(
|
||||
"app", "backend", "data", "temp", filename
|
||||
)
|
||||
|
||||
os.makedirs(os.path.dirname(excel_file_path), exist_ok=True)
|
||||
|
||||
# 保存表格到Excel(使用符合中国规范的格式化功能)
|
||||
self.save_tables_to_excel_enhanced(tables, excel_file_path, sheet_names)
|
||||
|
||||
# 触发文件下载
|
||||
if __event_call__:
|
||||
with open(excel_file_path, "rb") as file:
|
||||
file_content = file.read()
|
||||
base64_blob = base64.b64encode(file_content).decode("utf-8")
|
||||
|
||||
await __event_call__(
|
||||
{
|
||||
"type": "execute",
|
||||
"data": {
|
||||
"code": f"""
|
||||
try {{
|
||||
const base64Data = "{base64_blob}";
|
||||
const binaryData = atob(base64Data);
|
||||
const arrayBuffer = new Uint8Array(binaryData.length);
|
||||
for (let i = 0; i < binaryData.length; i++) {{
|
||||
arrayBuffer[i] = binaryData.charCodeAt(i);
|
||||
}}
|
||||
const blob = new Blob([arrayBuffer], {{ type: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" }});
|
||||
const filename = "{filename}";
|
||||
|
||||
const url = URL.createObjectURL(blob);
|
||||
const a = document.createElement("a");
|
||||
a.style.display = "none";
|
||||
a.href = url;
|
||||
a.download = filename;
|
||||
document.body.appendChild(a);
|
||||
a.click();
|
||||
URL.revokeObjectURL(url);
|
||||
document.body.removeChild(a);
|
||||
}} catch (error) {{
|
||||
console.error('触发下载时出错:', error);
|
||||
}}
|
||||
"""
|
||||
},
|
||||
}
|
||||
)
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "输出已保存", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
# 清理临时文件
|
||||
if os.path.exists(excel_file_path):
|
||||
os.remove(excel_file_path)
|
||||
|
||||
return {"message": "下载事件已触发"}
|
||||
|
||||
except HTTPException as e:
|
||||
print(f"Error processing tables: {str(e.detail)}")
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {
|
||||
"description": f"保存文件时出错: {e.detail}",
|
||||
"done": True,
|
||||
},
|
||||
}
|
||||
)
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", "没有找到可以导出的表格!"
|
||||
)
|
||||
raise e
|
||||
except Exception as e:
|
||||
print(f"Error processing tables: {str(e)}")
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {
|
||||
"description": f"保存文件时出错: {str(e)}",
|
||||
"done": True,
|
||||
},
|
||||
}
|
||||
)
|
||||
await self._send_notification(
|
||||
__event_emitter__, "error", "没有找到可以导出的表格!"
|
||||
)
|
||||
|
||||
def extract_tables_from_message(self, message: str) -> List[Dict]:
|
||||
"""
|
||||
从消息文本中提取Markdown表格及位置信息
|
||||
返回结构: [{
|
||||
"data": 表格数据,
|
||||
"start_line": 起始行号,
|
||||
"end_line": 结束行号
|
||||
}]
|
||||
"""
|
||||
table_row_pattern = r"^\s*\|.*\|.*\s*$"
|
||||
rows = message.split("\n")
|
||||
tables = []
|
||||
current_table = []
|
||||
start_line = None
|
||||
current_line = 0
|
||||
|
||||
for row in rows:
|
||||
current_line += 1
|
||||
if re.search(table_row_pattern, row):
|
||||
if start_line is None:
|
||||
start_line = current_line # 记录表格起始行
|
||||
|
||||
# 处理表格行
|
||||
cells = [cell.strip() for cell in row.strip().strip("|").split("|")]
|
||||
|
||||
# 跳过分隔行
|
||||
is_separator_row = all(re.fullmatch(r"[:\-]+", cell) for cell in cells)
|
||||
if not is_separator_row:
|
||||
current_table.append(cells)
|
||||
elif current_table:
|
||||
# 表格结束
|
||||
tables.append(
|
||||
{
|
||||
"data": current_table,
|
||||
"start_line": start_line,
|
||||
"end_line": current_line - 1,
|
||||
}
|
||||
)
|
||||
current_table = []
|
||||
start_line = None
|
||||
|
||||
# 处理最后一个表格
|
||||
if current_table:
|
||||
tables.append(
|
||||
{
|
||||
"data": current_table,
|
||||
"start_line": start_line,
|
||||
"end_line": current_line,
|
||||
}
|
||||
)
|
||||
|
||||
return tables
|
||||
|
||||
def generate_names_from_content(self, content: str, tables: List[Dict]) -> tuple:
|
||||
"""
|
||||
根据内容生成工作簿名称和sheet名称
|
||||
- 忽略非空段落,只使用 markdown 标题 (h1-h6)。
|
||||
- 单表格: 使用最近的标题作为工作簿和工作表名。
|
||||
- 多表格: 使用文档第一个标题作为工作簿名,各表格最近的标题作为工作表名。
|
||||
- 默认命名:
|
||||
- 工作簿: 在主流程中处理 (user_yyyymmdd.xlsx)。
|
||||
- 工作表: 表1, 表2, ...
|
||||
"""
|
||||
lines = content.split("\n")
|
||||
workbook_name = ""
|
||||
sheet_names = []
|
||||
all_headers = []
|
||||
|
||||
# 1. 查找文档中所有 h1-h6 标题及其位置
|
||||
for i, line in enumerate(lines):
|
||||
if re.match(r"^#{1,6}\s+", line):
|
||||
all_headers.append(
|
||||
{"text": re.sub(r"^#{1,6}\s+", "", line).strip(), "line_num": i}
|
||||
)
|
||||
|
||||
# 2. 为每个表格生成 sheet 名称
|
||||
for i, table in enumerate(tables):
|
||||
table_start_line = table["start_line"] - 1 # 转换为 0-based 索引
|
||||
closest_header_text = None
|
||||
|
||||
# 查找当前表格上方最近的标题
|
||||
candidate_headers = [
|
||||
h for h in all_headers if h["line_num"] < table_start_line
|
||||
]
|
||||
if candidate_headers:
|
||||
# 找到候选标题中行号最大的,即为最接近的
|
||||
closest_header = max(candidate_headers, key=lambda x: x["line_num"])
|
||||
closest_header_text = closest_header["text"]
|
||||
|
||||
if closest_header_text:
|
||||
# 清理并添加找到的标题
|
||||
sheet_names.append(self.clean_sheet_name(closest_header_text))
|
||||
else:
|
||||
# 如果找不到标题,使用默认名称 "表{i+1}"
|
||||
sheet_names.append(f"表{i+1}")
|
||||
|
||||
# 3. 根据表格数量确定工作簿名称
|
||||
if len(tables) == 1:
|
||||
# 单个表格: 使用其工作表名作为工作簿名 (前提是该名称不是默认的 "表1")
|
||||
if sheet_names[0] != "表1":
|
||||
workbook_name = sheet_names[0]
|
||||
elif len(tables) > 1:
|
||||
# 多个表格: 使用文档中的第一个标题作为工作簿名
|
||||
if all_headers:
|
||||
# 找到所有标题中行号最小的,即为第一个标题
|
||||
first_header = min(all_headers, key=lambda x: x["line_num"])
|
||||
workbook_name = first_header["text"]
|
||||
|
||||
# 4. 清理工作簿名称 (如果为空,主流程会使用默认名称)
|
||||
workbook_name = self.clean_filename(workbook_name) if workbook_name else ""
|
||||
|
||||
return workbook_name, sheet_names
|
||||
|
||||
def clean_filename(self, name: str) -> str:
|
||||
"""清理文件名中的非法字符"""
|
||||
return re.sub(r'[\\/*?:"<>|]', "", name).strip()
|
||||
|
||||
def clean_sheet_name(self, name: str) -> str:
|
||||
"""清理sheet名称(限制31字符,去除非法字符)"""
|
||||
name = re.sub(r"[\\/*?[\]:]", "", name).strip()
|
||||
return name[:31] if len(name) > 31 else name
|
||||
|
||||
# ======================== 符合中国规范的格式化功能 ========================
|
||||
|
||||
def calculate_text_width(self, text: str) -> float:
|
||||
"""
|
||||
计算文本显示宽度,考虑中英文字符差异
|
||||
中文字符按2个单位计算,英文字符按1个单位计算
|
||||
"""
|
||||
if not text:
|
||||
return 0
|
||||
|
||||
width = 0
|
||||
for char in str(text):
|
||||
# 判断是否为中文字符(包括中文标点)
|
||||
if "\u4e00" <= char <= "\u9fff" or "\u3000" <= char <= "\u303f":
|
||||
width += 2 # 中文字符占2个单位宽度
|
||||
else:
|
||||
width += 1 # 英文字符占1个单位宽度
|
||||
|
||||
return width
|
||||
|
||||
def calculate_text_height(self, text: str, max_width: int = 50) -> int:
|
||||
"""
|
||||
计算文本显示所需的行数
|
||||
根据换行符和文本长度计算
|
||||
"""
|
||||
if not text:
|
||||
return 1
|
||||
|
||||
text = str(text)
|
||||
# 计算换行符导致的行数
|
||||
explicit_lines = text.count("\n") + 1
|
||||
|
||||
# 计算因文本长度超出而需要的额外行数
|
||||
text_width = self.calculate_text_width(text.replace("\n", ""))
|
||||
wrapped_lines = max(
|
||||
1, int(text_width / max_width) + (1 if text_width % max_width > 0 else 0)
|
||||
)
|
||||
|
||||
return max(explicit_lines, wrapped_lines)
|
||||
|
||||
def get_column_letter(self, col_index: int) -> str:
|
||||
"""
|
||||
将列索引转换为Excel列字母 (A, B, C, ..., AA, AB, ...)
|
||||
"""
|
||||
result = ""
|
||||
while col_index >= 0:
|
||||
result = chr(65 + col_index % 26) + result
|
||||
col_index = col_index // 26 - 1
|
||||
return result
|
||||
|
||||
def determine_content_type(self, header: str, values: list) -> str:
|
||||
"""
|
||||
根据表头和内容智能判断数据类型,符合中国官方表格规范
|
||||
返回: 'number', 'date', 'sequence', 'text'
|
||||
"""
|
||||
header_lower = str(header).lower().strip()
|
||||
|
||||
# 检查表头关键词
|
||||
number_keywords = [
|
||||
"数量",
|
||||
"金额",
|
||||
"价格",
|
||||
"费用",
|
||||
"成本",
|
||||
"收入",
|
||||
"支出",
|
||||
"总计",
|
||||
"小计",
|
||||
"百分比",
|
||||
"%",
|
||||
"比例",
|
||||
"率",
|
||||
"数值",
|
||||
"分数",
|
||||
"成绩",
|
||||
"得分",
|
||||
]
|
||||
date_keywords = ["日期", "时间", "年份", "月份", "时刻", "date", "time"]
|
||||
sequence_keywords = [
|
||||
"序号",
|
||||
"编号",
|
||||
"号码",
|
||||
"排序",
|
||||
"次序",
|
||||
"顺序",
|
||||
"id",
|
||||
"编码",
|
||||
]
|
||||
|
||||
# 检查表头
|
||||
for keyword in number_keywords:
|
||||
if keyword in header_lower:
|
||||
return "number"
|
||||
|
||||
for keyword in date_keywords:
|
||||
if keyword in header_lower:
|
||||
return "date"
|
||||
|
||||
for keyword in sequence_keywords:
|
||||
if keyword in header_lower:
|
||||
return "sequence"
|
||||
|
||||
# 检查数据内容
|
||||
if not values:
|
||||
return "text"
|
||||
|
||||
sample_values = [
|
||||
str(v).strip() for v in values[:10] if str(v).strip()
|
||||
] # 取前10个非空值作为样本
|
||||
if not sample_values:
|
||||
return "text"
|
||||
|
||||
numeric_count = 0
|
||||
date_count = 0
|
||||
sequence_count = 0
|
||||
|
||||
for value in sample_values:
|
||||
# 检查是否为数字
|
||||
try:
|
||||
float(
|
||||
value.replace(",", "")
|
||||
.replace(",", "")
|
||||
.replace("%", "")
|
||||
.replace("%", "")
|
||||
)
|
||||
numeric_count += 1
|
||||
continue
|
||||
except ValueError:
|
||||
pass
|
||||
|
||||
# 检查是否为日期格式
|
||||
date_patterns = [
|
||||
r"\d{4}[-/年]\d{1,2}[-/月]\d{1,2}日?",
|
||||
r"\d{1,2}[-/]\d{1,2}[-/]\d{4}",
|
||||
r"\d{4}\d{2}\d{2}",
|
||||
]
|
||||
for pattern in date_patterns:
|
||||
if re.match(pattern, value):
|
||||
date_count += 1
|
||||
break
|
||||
|
||||
# 检查是否为序号格式
|
||||
if (
|
||||
re.match(r"^\d+$", value) and len(value) <= 4
|
||||
): # 纯数字且不超过4位,可能是序号
|
||||
sequence_count += 1
|
||||
|
||||
total_count = len(sample_values)
|
||||
|
||||
# 根据比例判断类型
|
||||
if numeric_count / total_count >= 0.7:
|
||||
return "number"
|
||||
elif date_count / total_count >= 0.7:
|
||||
return "date"
|
||||
elif sequence_count / total_count >= 0.8 and sequence_count > 2:
|
||||
return "sequence"
|
||||
else:
|
||||
return "text"
|
||||
|
||||
def get_column_letter(self, col_index: int) -> str:
|
||||
"""
|
||||
将列索引转换为Excel列字母 (A, B, C, ..., AA, AB, ...)
|
||||
"""
|
||||
result = ""
|
||||
while col_index >= 0:
|
||||
result = chr(65 + col_index % 26) + result
|
||||
col_index = col_index // 26 - 1
|
||||
return result
|
||||
|
||||
def save_tables_to_excel_enhanced(
|
||||
self, tables: List[Dict], file_path: str, sheet_names: List[str]
|
||||
):
|
||||
"""
|
||||
符合中国官方表格规范的Excel保存功能
|
||||
"""
|
||||
try:
|
||||
with pd.ExcelWriter(file_path, engine="xlsxwriter") as writer:
|
||||
workbook = writer.book
|
||||
|
||||
# 定义表头样式 - 居中对齐(符合中国规范)
|
||||
header_format = workbook.add_format(
|
||||
{
|
||||
"bold": True,
|
||||
"font_size": 12,
|
||||
"font_color": "white",
|
||||
"bg_color": "#00abbd",
|
||||
"border": 1,
|
||||
"align": "center", # 表头居中
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
# 文本单元格样式 - 左对齐
|
||||
text_format = workbook.add_format(
|
||||
{
|
||||
"border": 1,
|
||||
"align": "left", # 文本左对齐
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
# 数值单元格样式 - 右对齐
|
||||
number_format = workbook.add_format(
|
||||
{"border": 1, "align": "right", "valign": "vcenter"} # 数值右对齐
|
||||
)
|
||||
|
||||
# 整数格式 - 右对齐
|
||||
integer_format = workbook.add_format(
|
||||
{
|
||||
"num_format": "0",
|
||||
"border": 1,
|
||||
"align": "right", # 整数右对齐
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
# 小数格式 - 右对齐
|
||||
decimal_format = workbook.add_format(
|
||||
{
|
||||
"num_format": "0.00",
|
||||
"border": 1,
|
||||
"align": "right", # 小数右对齐
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
# 日期格式 - 居中对齐
|
||||
date_format = workbook.add_format(
|
||||
{
|
||||
"border": 1,
|
||||
"align": "center", # 日期居中对齐
|
||||
"valign": "vcenter",
|
||||
"text_wrap": True,
|
||||
}
|
||||
)
|
||||
|
||||
# 序号格式 - 居中对齐
|
||||
sequence_format = workbook.add_format(
|
||||
{
|
||||
"border": 1,
|
||||
"align": "center", # 序号居中对齐
|
||||
"valign": "vcenter",
|
||||
}
|
||||
)
|
||||
|
||||
for i, table in enumerate(tables):
|
||||
try:
|
||||
table_data = table["data"]
|
||||
if not table_data or len(table_data) < 1:
|
||||
print(f"Skipping empty table at index {i}")
|
||||
continue
|
||||
|
||||
print(f"Processing table {i+1} with {len(table_data)} rows")
|
||||
|
||||
# 获取sheet名称
|
||||
sheet_name = (
|
||||
sheet_names[i] if i < len(sheet_names) else f"表{i+1}"
|
||||
)
|
||||
|
||||
# 创建DataFrame
|
||||
headers = [
|
||||
str(cell).strip()
|
||||
for cell in table_data[0]
|
||||
if str(cell).strip()
|
||||
]
|
||||
if not headers:
|
||||
print(f"Warning: No valid headers found for table {i+1}")
|
||||
headers = [f"列{j+1}" for j in range(len(table_data[0]))]
|
||||
|
||||
data_rows = []
|
||||
if len(table_data) > 1:
|
||||
max_cols = len(headers)
|
||||
for row in table_data[1:]:
|
||||
processed_row = []
|
||||
for j in range(max_cols):
|
||||
if j < len(row):
|
||||
processed_row.append(str(row[j]))
|
||||
else:
|
||||
processed_row.append("")
|
||||
data_rows.append(processed_row)
|
||||
df = pd.DataFrame(data_rows, columns=headers)
|
||||
else:
|
||||
df = pd.DataFrame(columns=headers)
|
||||
|
||||
print(f"DataFrame created with columns: {list(df.columns)}")
|
||||
|
||||
# 修复pandas FutureWarning - 使用try-except替代errors='ignore'
|
||||
for col in df.columns:
|
||||
try:
|
||||
df[col] = pd.to_numeric(df[col])
|
||||
except (ValueError, TypeError):
|
||||
pass
|
||||
|
||||
# 先写入数据(不包含表头)
|
||||
df.to_excel(
|
||||
writer,
|
||||
sheet_name=sheet_name,
|
||||
index=False,
|
||||
header=False,
|
||||
startrow=1,
|
||||
)
|
||||
worksheet = writer.sheets[sheet_name]
|
||||
|
||||
# 应用符合中国规范的格式化
|
||||
self.apply_chinese_standard_formatting(
|
||||
worksheet,
|
||||
df,
|
||||
headers,
|
||||
workbook,
|
||||
header_format,
|
||||
text_format,
|
||||
number_format,
|
||||
integer_format,
|
||||
decimal_format,
|
||||
date_format,
|
||||
sequence_format,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error processing table {i+1}: {str(e)}")
|
||||
continue
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error saving Excel file: {str(e)}")
|
||||
raise
|
||||
|
||||
def apply_chinese_standard_formatting(
|
||||
self,
|
||||
worksheet,
|
||||
df,
|
||||
headers,
|
||||
workbook,
|
||||
header_format,
|
||||
text_format,
|
||||
number_format,
|
||||
integer_format,
|
||||
decimal_format,
|
||||
date_format,
|
||||
sequence_format,
|
||||
):
|
||||
"""
|
||||
应用符合中国官方表格规范的格式化
|
||||
- 表头: 居中对齐
|
||||
- 数值: 右对齐
|
||||
- 文本: 左对齐
|
||||
- 日期: 居中对齐
|
||||
- 序号: 居中对齐
|
||||
"""
|
||||
try:
|
||||
# 1. 写入表头(居中对齐)
|
||||
print(f"Writing headers with Chinese standard alignment: {headers}")
|
||||
for col_idx, header in enumerate(headers):
|
||||
if header and str(header).strip():
|
||||
worksheet.write(0, col_idx, str(header).strip(), header_format)
|
||||
else:
|
||||
default_header = f"列{col_idx+1}"
|
||||
worksheet.write(0, col_idx, default_header, header_format)
|
||||
|
||||
# 2. 分析每列的数据类型并应用相应格式
|
||||
column_types = {}
|
||||
for col_idx, column in enumerate(headers):
|
||||
if col_idx < len(df.columns):
|
||||
column_values = df.iloc[:, col_idx].tolist()
|
||||
column_types[col_idx] = self.determine_content_type(
|
||||
column, column_values
|
||||
)
|
||||
print(
|
||||
f"Column '{column}' determined as type: {column_types[col_idx]}"
|
||||
)
|
||||
else:
|
||||
column_types[col_idx] = "text"
|
||||
|
||||
# 3. 写入并格式化数据(根据类型使用不同对齐方式)
|
||||
for row_idx, row in df.iterrows():
|
||||
for col_idx, value in enumerate(row):
|
||||
content_type = column_types.get(col_idx, "text")
|
||||
|
||||
# 根据内容类型选择格式
|
||||
if content_type == "number":
|
||||
# 数值类型 - 右对齐
|
||||
if pd.api.types.is_numeric_dtype(df.iloc[:, col_idx]):
|
||||
if pd.api.types.is_integer_dtype(df.iloc[:, col_idx]):
|
||||
current_format = integer_format
|
||||
else:
|
||||
try:
|
||||
numeric_value = float(value)
|
||||
if numeric_value.is_integer():
|
||||
current_format = integer_format
|
||||
value = int(numeric_value)
|
||||
else:
|
||||
current_format = decimal_format
|
||||
except (ValueError, TypeError):
|
||||
current_format = decimal_format
|
||||
else:
|
||||
current_format = number_format
|
||||
|
||||
elif content_type == "date":
|
||||
# 日期类型 - 居中对齐
|
||||
current_format = date_format
|
||||
|
||||
elif content_type == "sequence":
|
||||
# 序号类型 - 居中对齐
|
||||
current_format = sequence_format
|
||||
|
||||
else:
|
||||
# 文本类型 - 左对齐
|
||||
current_format = text_format
|
||||
|
||||
worksheet.write(row_idx + 1, col_idx, value, current_format)
|
||||
|
||||
# 4. 自动调整列宽
|
||||
for col_idx, column in enumerate(headers):
|
||||
col_letter = self.get_column_letter(col_idx)
|
||||
|
||||
# 计算表头宽度
|
||||
header_width = self.calculate_text_width(str(column))
|
||||
|
||||
# 计算数据列的最大宽度
|
||||
max_data_width = 0
|
||||
if not df.empty and col_idx < len(df.columns):
|
||||
for value in df.iloc[:, col_idx]:
|
||||
value_width = self.calculate_text_width(str(value))
|
||||
max_data_width = max(max_data_width, value_width)
|
||||
|
||||
# 基础宽度:取表头和数据的最大宽度
|
||||
base_width = max(header_width, max_data_width)
|
||||
|
||||
# 根据内容类型调整宽度
|
||||
content_type = column_types.get(col_idx, "text")
|
||||
if content_type == "sequence":
|
||||
# 序号列通常比较窄
|
||||
optimal_width = max(8, min(15, base_width + 2))
|
||||
elif content_type == "number":
|
||||
# 数值列需要额外空间显示数字
|
||||
optimal_width = max(12, min(25, base_width + 3))
|
||||
elif content_type == "date":
|
||||
# 日期列需要固定宽度
|
||||
optimal_width = max(15, min(20, base_width + 2))
|
||||
else:
|
||||
# 文本列根据内容调整
|
||||
if base_width <= 10:
|
||||
optimal_width = base_width + 3
|
||||
elif base_width <= 20:
|
||||
optimal_width = base_width + 4
|
||||
else:
|
||||
optimal_width = base_width + 5
|
||||
optimal_width = max(10, min(60, optimal_width))
|
||||
|
||||
worksheet.set_column(f"{col_letter}:{col_letter}", optimal_width)
|
||||
|
||||
# 5. 自动调整行高
|
||||
# 设置表头行高为35点
|
||||
worksheet.set_row(0, 35)
|
||||
|
||||
# 设置数据行行高
|
||||
for row_idx, row in df.iterrows():
|
||||
max_row_height = 20 # 中国表格规范建议的最小行高
|
||||
|
||||
for col_idx, value in enumerate(row):
|
||||
if col_idx < len(headers):
|
||||
col_width = min(
|
||||
60,
|
||||
max(
|
||||
10, self.calculate_text_width(str(headers[col_idx])) + 5
|
||||
),
|
||||
)
|
||||
else:
|
||||
col_width = 15
|
||||
|
||||
cell_lines = self.calculate_text_height(str(value), col_width)
|
||||
cell_height = cell_lines * 20 # 每行20点高度,符合中国规范
|
||||
|
||||
max_row_height = max(max_row_height, cell_height)
|
||||
|
||||
final_height = min(120, max_row_height)
|
||||
worksheet.set_row(row_idx + 1, final_height)
|
||||
|
||||
print(f"Successfully applied Chinese standard formatting")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Warning: Failed to apply Chinese standard formatting: {str(e)}")
|
||||
# 降级到基础格式化
|
||||
self.apply_basic_formatting_fallback(worksheet, df)
|
||||
|
||||
def apply_basic_formatting_fallback(self, worksheet, df):
|
||||
"""
|
||||
基础格式化降级方案
|
||||
"""
|
||||
try:
|
||||
# 基础列宽调整
|
||||
for i, column in enumerate(df.columns):
|
||||
column_width = (
|
||||
max(
|
||||
len(str(column)),
|
||||
(df[column].astype(str).map(len).max() if not df.empty else 0),
|
||||
)
|
||||
+ 2
|
||||
)
|
||||
|
||||
col_letter = self.get_column_letter(i)
|
||||
worksheet.set_column(
|
||||
f"{col_letter}:{col_letter}", min(60, max(10, column_width))
|
||||
)
|
||||
|
||||
print("Applied basic formatting fallback")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Warning: Even basic formatting failed: {str(e)}")
|
||||
@@ -2,9 +2,18 @@
|
||||
|
||||
Generate polished learning flashcards from any text—title, summary, key points, tags, and category—ready for review and sharing.
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.2.4 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
## Preview 📸
|
||||
|
||||

|
||||
|
||||
## Highlights
|
||||
## What's New
|
||||
|
||||
### v0.2.4
|
||||
- **Clean Output**: Removed debug messages from output.
|
||||
|
||||
## Key Features 🔑
|
||||
|
||||
- **One-click generation**: Drop in text, get a structured card.
|
||||
- **Concise extraction**: 3–5 key points and 2–4 tags automatically surfaced.
|
||||
@@ -12,7 +21,14 @@ Generate polished learning flashcards from any text—title, summary, key points
|
||||
- **Progressive merge**: Multiple runs append cards into the same HTML container; enable clearing to reset.
|
||||
- **Status updates**: Live notifications for generating/done/error.
|
||||
|
||||
## Parameters
|
||||
## How to Use 🛠️
|
||||
|
||||
1. **Install**: Add the plugin to your OpenWebUI instance.
|
||||
2. **Configure**: Adjust settings in the Valves menu (optional).
|
||||
3. **Trigger**: Send text to the chat.
|
||||
4. **Result**: Watch status updates; the card HTML is embedded into the latest message.
|
||||
|
||||
## Configuration (Valves) ⚙️
|
||||
|
||||
| Param | Description | Default |
|
||||
| ------------------- | ------------------------------------------------------------ | ------- |
|
||||
@@ -23,28 +39,9 @@ Generate polished learning flashcards from any text—title, summary, key points
|
||||
| CLEAR_PREVIOUS_HTML | Whether to clear previous card HTML (otherwise append/merge) | false |
|
||||
| MESSAGE_COUNT | Use the latest N messages to build the card | 1 |
|
||||
|
||||
## How to Use
|
||||
## Troubleshooting ❓
|
||||
|
||||
1. Install and enable “Flash Card”.
|
||||
2. Send the text to the chat (multi-turn supported; governed by MESSAGE_COUNT).
|
||||
3. Watch status updates; the card HTML is embedded into the latest message.
|
||||
4. To regenerate from scratch, toggle CLEAR_PREVIOUS_HTML or resend text.
|
||||
|
||||
## Output Format
|
||||
|
||||
- JSON fields: `title`, `summary`, `key_points` (3–5), `tags` (2–4), `category`.
|
||||
- UI: gradient-styled card with tags, key-point list; supports stacking multiple cards.
|
||||
|
||||
## Tips
|
||||
|
||||
- Very short text triggers a prompt to add more; consider summarizing first.
|
||||
- Long text is accepted; for deep analysis, pre-condense with other tools before card creation.
|
||||
|
||||
## Author
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## License
|
||||
|
||||
MIT License
|
||||
- **Plugin not working?**: Check if the filter/action is enabled in the model settings.
|
||||
- **Debug Logs**: Enable `SHOW_STATUS` in Valves to see progress updates.
|
||||
- **Error Messages**: If you see an error, please copy the full error message and report it.
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
@@ -2,9 +2,18 @@
|
||||
|
||||
快速将文本提炼为精美的学习记忆卡片,自动抽取标题、摘要、关键要点、标签和分类,适合复习与分享。
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.2.4 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
## 预览 📸
|
||||
|
||||

|
||||
|
||||
## 功能亮点
|
||||
## 更新日志
|
||||
|
||||
### v0.2.4
|
||||
- **输出优化**: 移除输出中的调试信息。
|
||||
|
||||
## 核心特性 🔑
|
||||
|
||||
- **一键生成**:输入任意文本,直接产出结构化卡片。
|
||||
- **要点聚合**:自动提取 3-5 个记忆要点与 2-4 个标签。
|
||||
@@ -12,7 +21,14 @@
|
||||
- **渐进合并**:多次调用会将新卡片合并到同一 HTML 容器中;如需重置可启用清空选项。
|
||||
- **状态提示**:实时推送“生成中/完成/错误”等状态与通知。
|
||||
|
||||
## 参数说明
|
||||
## 使用方法 🛠️
|
||||
|
||||
1. **安装**: 在插件市场安装并启用“闪记卡”。
|
||||
2. **配置**: 根据需要调整 Valves 设置(可选)。
|
||||
3. **触发**: 将待整理的文本发送到聊天框。
|
||||
4. **结果**: 等待状态提示,卡片将以 HTML 形式嵌入到最新消息中。
|
||||
|
||||
## 配置参数 (Valves) ⚙️
|
||||
|
||||
| 参数 | 说明 | 默认值 |
|
||||
| ------------------- | ------------------------------------- | ------ |
|
||||
@@ -23,28 +39,9 @@
|
||||
| CLEAR_PREVIOUS_HTML | 是否清空旧的卡片 HTML(否则合并追加) | false |
|
||||
| MESSAGE_COUNT | 取最近 N 条消息生成卡片 | 1 |
|
||||
|
||||
## 使用步骤
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
1. 在插件市场安装并启用“闪记卡”。
|
||||
2. 将待整理的文本发送到聊天框(可多轮对话,受 MESSAGE_COUNT 控制)。
|
||||
3. 等待状态提示,卡片将以 HTML 形式嵌入到最新消息中。
|
||||
4. 若需重新生成,开启 CLEAR_PREVIOUS_HTML 或直接重发文本。
|
||||
|
||||
## 输出格式
|
||||
|
||||
- JSON 字段:`title`、`summary`、`key_points`(3-5 条)、`tags`(2-4 条)、`category`。
|
||||
- 前端呈现:单卡片带渐变主题、标签胶囊、要点列表,可连续追加多张卡片。
|
||||
|
||||
## 使用建议
|
||||
|
||||
- 文本过短会提醒补充,可先汇总再生成卡片。
|
||||
- 长文本无需截断,直接生成;如需深度分析可先用其他工具精炼后再制作卡片。
|
||||
|
||||
## 作者
|
||||
|
||||
Fu-Jie
|
||||
GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## 许可证
|
||||
|
||||
MIT License
|
||||
- **插件不工作?**: 请检查是否在模型设置中启用了该过滤器/动作。
|
||||
- **调试日志**: 在 Valves 中启用 `SHOW_STATUS` 以查看进度更新。
|
||||
- **错误信息**: 如果看到错误,请复制完整的错误信息并报告。
|
||||
- **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
"""
|
||||
title: Flash Card
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie
|
||||
funding_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
version: 0.2.2
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 0.2.4
|
||||
openwebui_id: 65a2ea8f-2a13-4587-9d76-55eea0035cc8
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwb2x5Z29uIHBvaW50cz0iMTIgMiAyIDcgMTIgMTIgMjIgNyAxMiAyIi8+PHBvbHlsaW5lIHBvaW50cz0iMiAxNyAxMiAyMiAyMiAxNyIvPjxwb2x5bGluZSBwb2ludHM9IjIgMTIgMTIgMTcgMjIgMTIiLz48L3N2Zz4=
|
||||
description: Quickly generates beautiful flashcards from text, extracting key points and categories.
|
||||
"""
|
||||
@@ -88,6 +89,10 @@ class Action:
|
||||
default=True,
|
||||
description="Whether to show status updates in the chat interface.",
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False,
|
||||
description="Whether to print debug logs in the browser console.",
|
||||
)
|
||||
CLEAR_PREVIOUS_HTML: bool = Field(
|
||||
default=False,
|
||||
description="Whether to force clear previous plugin results (if True, overwrites instead of merging).",
|
||||
@@ -115,6 +120,42 @@ class Action:
|
||||
"user_language": user_data.get("language", "en-US"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""
|
||||
Unified extraction of chat context information (chat_id, message_id).
|
||||
Prioritizes extraction from body, then metadata.
|
||||
"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
# 1. Try to get from body
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # message_id is usually 'id' in body
|
||||
|
||||
# Check body.metadata as fallback
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
# 2. Try to get from __metadata__ (as supplement)
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
@@ -147,7 +188,7 @@ class Action:
|
||||
if role == "user"
|
||||
else "Assistant" if role == "assistant" else role
|
||||
)
|
||||
aggregated_parts.append(f"[{role_label} Message {i}]\n{text_content}")
|
||||
aggregated_parts.append(f"{text_content}")
|
||||
|
||||
if not aggregated_parts:
|
||||
return body
|
||||
@@ -330,6 +371,26 @@ Important Principles:
|
||||
{"type": "notification", "data": {"type": ntype, "content": content}}
|
||||
)
|
||||
|
||||
async def _emit_debug_log(self, emitter, title: str, data: dict):
|
||||
"""Print structured debug logs in the browser console"""
|
||||
if not self.valves.SHOW_DEBUG_LOG or not emitter:
|
||||
return
|
||||
|
||||
try:
|
||||
import json
|
||||
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
await emitter({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
|
||||
def _remove_existing_html(self, content: str) -> str:
|
||||
"""Removes existing plugin-generated HTML code blocks from the content."""
|
||||
pattern = r"```html\s*<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?```"
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
"""
|
||||
title: 闪记卡 (Flash Card)
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie
|
||||
funding_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
version: 0.2.2
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 0.2.4
|
||||
openwebui_id: 4a31eac3-a3c4-4c30-9ca5-dab36b5fac65
|
||||
icon_url: data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0IiBmaWxsPSJub25lIiBzdHJva2U9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIyIiBzdHJva2UtbGluZWNhcD0icm91bmQiIHN0cm9rZS1saW5lam9pbj0icm91bmQiPjxwb2x5Z29uIHBvaW50cz0iMTIgMiAyIDcgMTIgMTIgMjIgNyAxMiAyIi8+PHBvbHlsaW5lIHBvaW50cz0iMiAxNyAxMiAyMiAyMiAxNyIvPjxwb2x5bGluZSBwb2ludHM9IjIgMTIgMTIgMTcgMjIgMTIiLz48L3N2Zz4=
|
||||
description: 快速将文本提炼为精美的学习记忆卡片,支持核心要点提取与分类。
|
||||
"""
|
||||
@@ -85,6 +86,10 @@ class Action:
|
||||
SHOW_STATUS: bool = Field(
|
||||
default=True, description="是否在聊天界面显示状态更新。"
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False,
|
||||
description="是否在浏览器控制台打印调试日志。",
|
||||
)
|
||||
CLEAR_PREVIOUS_HTML: bool = Field(
|
||||
default=False,
|
||||
description="是否强制清除旧的插件结果(如果为 True,则不合并,直接覆盖)。",
|
||||
@@ -112,6 +117,42 @@ class Action:
|
||||
"user_language": user_data.get("language", "zh-CN"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""
|
||||
统一提取聊天上下文信息 (chat_id, message_id)。
|
||||
优先从 body 中提取,其次从 metadata 中提取。
|
||||
"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
# 1. 尝试从 body 获取
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "") # message_id 在 body 中通常是 id
|
||||
|
||||
# 再次检查 body.metadata
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
# 2. 尝试从 __metadata__ 获取 (作为补充)
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
async def action(
|
||||
self,
|
||||
body: dict,
|
||||
@@ -144,7 +185,7 @@ class Action:
|
||||
if role == "user"
|
||||
else "助手" if role == "assistant" else role
|
||||
)
|
||||
aggregated_parts.append(f"[{role_label} 消息 {i}]\n{text_content}")
|
||||
aggregated_parts.append(f"{text_content}")
|
||||
|
||||
if not aggregated_parts:
|
||||
return body
|
||||
@@ -313,6 +354,26 @@ class Action:
|
||||
{"type": "notification", "data": {"type": ntype, "content": content}}
|
||||
)
|
||||
|
||||
async def _emit_debug_log(self, emitter, title: str, data: dict):
|
||||
"""在浏览器控制台打印结构化调试日志"""
|
||||
if not self.valves.SHOW_DEBUG_LOG or not emitter:
|
||||
return
|
||||
|
||||
try:
|
||||
import json
|
||||
|
||||
js_code = f"""
|
||||
(async function() {{
|
||||
console.group("🛠️ {title}");
|
||||
console.log({json.dumps(data, ensure_ascii=False)});
|
||||
console.groupEnd();
|
||||
}})();
|
||||
"""
|
||||
|
||||
await emitter({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
print(f"Error emitting debug log: {e}")
|
||||
|
||||
def _remove_existing_html(self, content: str) -> str:
|
||||
"""移除内容中已有的插件生成 HTML 代码块 (通过标记识别)。"""
|
||||
pattern = r"```html\s*<!-- OPENWEBUI_PLUGIN_OUTPUT -->[\s\S]*?```"
|
||||
@@ -1,25 +1,31 @@
|
||||
# 📊 Smart Infographic (AntV)
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.4.9 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
An Open WebUI plugin powered by the AntV Infographic engine. It transforms long text into professional, beautiful infographics with a single click.
|
||||
|
||||
## 🔥 What's New in v1.4.9
|
||||
|
||||
- 🎨 **70+ Official Templates**: Integrated comprehensive AntV infographic template library.
|
||||
- 🖼️ **Iconify & unDraw Support**: Richer visuals with official icons and illustrations.
|
||||
- 📏 **Visual Optimization**: Improved text wrapping, adaptive sizing, and layout refinement.
|
||||
- ✨ **PNG Upload**: Infographics now upload as PNG format for better Word export compatibility.
|
||||
- 🔧 **Canvas Conversion**: Uses browser canvas for high-quality SVG to PNG conversion (2x scale).
|
||||
|
||||
### Previous: v1.4.0
|
||||
|
||||
- ✨ **Default Mode Change**: Default output mode is now `image` (static image) for better compatibility.
|
||||
- 📱 **Responsive Sizing**: Images now auto-adapt to the chat container width.
|
||||
|
||||
## ✨ Key Features
|
||||
|
||||
- 🚀 **AI-Powered Transformation**: Automatically analyzes text logic, extracts key points, and generates structured charts.
|
||||
- 🎨 **Professional Templates**: Includes various AntV official templates: Lists, Trees, Mindmaps, Comparison Tables, Flowcharts, and Statistical Charts.
|
||||
- 🔍 **Auto-Icon Matching**: Built-in logic to search and match the most relevant Material Design Icons based on content.
|
||||
- 🎨 **70+ Professional Templates**: Includes various AntV official templates: Lists, Trees, Roadmaps, Timelines, Comparison Tables, SWOT, Quadrants, and Statistical Charts.
|
||||
- 🔍 **Auto-Icon Matching**: Built-in logic to search and match the most relevant icons (Iconify) and illustrations (unDraw).
|
||||
- 📥 **Multi-Format Export**: Download your infographics as **SVG**, **PNG**, or a **Standalone HTML** file.
|
||||
- 🌈 **Highly Customizable**: Supports Dark/Light modes, auto-adapts theme colors, with bold titles and refined card layouts.
|
||||
- 📱 **Responsive Design**: Generated charts look great on both desktop and mobile devices.
|
||||
|
||||
## 🛠️ Supported Template Types
|
||||
|
||||
| Category | Template Name | Use Case |
|
||||
| :--- | :--- | :--- |
|
||||
| **Lists & Hierarchy** | `list-grid`, `tree-vertical`, `mindmap` | Features, Org Charts, Brainstorming |
|
||||
| **Sequence & Relation** | `sequence-roadmap`, `relation-circle` | Roadmaps, Circular Flows, Steps |
|
||||
| **Comparison & Analysis** | `compare-binary`, `compare-swot`, `quadrant-quarter` | Pros/Cons, SWOT, Quadrants |
|
||||
| **Charts & Data** | `chart-bar`, `chart-line`, `chart-pie` | Trends, Distributions, Metrics |
|
||||
|
||||
## 🚀 How to Use
|
||||
|
||||
1. **Install**: Search for "Smart Infographic" in the Open WebUI Community and install.
|
||||
@@ -38,6 +44,25 @@ You can adjust the following parameters in the plugin settings to optimize the g
|
||||
| **Min Text Length (MIN_TEXT_LENGTH)** | `100` | Minimum characters required to trigger analysis, preventing accidental triggers on short text. |
|
||||
| **Clear Previous (CLEAR_PREVIOUS_HTML)** | `False` | Whether to clear previous charts. If `False`, new charts will be appended below. |
|
||||
| **Message Count (MESSAGE_COUNT)** | `1` | Number of recent messages to use for analysis. Increase this for more context. |
|
||||
| **Output Mode (OUTPUT_MODE)** | `image` | `image` for static image embedding (default, better compatibility), `html` for interactive chart. |
|
||||
|
||||
## 🛠️ Supported Template Types
|
||||
|
||||
| Category | Template Name | Use Case |
|
||||
| :--- | :--- | :--- |
|
||||
| **Sequence** | `sequence-timeline-simple`, `sequence-roadmap-vertical-simple`, `sequence-snake-steps-compact-card` | Timelines, Roadmaps, Processes |
|
||||
| **Lists** | `list-grid-candy-card-lite`, `list-row-horizontal-icon-arrow`, `list-column-simple-vertical-arrow` | Features, Bullet Points, Lists |
|
||||
| **Comparison** | `compare-binary-horizontal-underline-text-vs`, `compare-swot`, `quadrant-quarter-simple-card` | Pros/Cons, SWOT, Quadrants |
|
||||
| **Hierarchy** | `hierarchy-tree-tech-style-capsule-item`, `hierarchy-structure` | Org Charts, Structures |
|
||||
| **Charts** | `chart-column-simple`, `chart-bar-plain-text`, `chart-line-plain-text`, `chart-wordcloud` | Trends, Distributions, Metrics |
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
- **Plugin not working?**: Check if the filter/action is enabled in the model settings.
|
||||
- **Debug Logs**: Enable `SHOW_STATUS` in Valves to see progress updates.
|
||||
- **Error Messages**: If you see an error, please copy the full error message and report it.
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
|
||||
## 📝 Syntax Example (For Advanced Users)
|
||||
|
||||
@@ -54,12 +79,3 @@ data
|
||||
- label Beautiful Design
|
||||
desc Uses AntV professional design standards
|
||||
```
|
||||
|
||||
## 👨💻 Author
|
||||
|
||||
**jeff**
|
||||
- GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## 📄 License
|
||||
|
||||
MIT License
|
||||
|
||||
@@ -1,25 +1,31 @@
|
||||
# 📊 智能信息图 (AntV Infographic)
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.4.9 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
基于 AntV Infographic 引擎的 Open WebUI 插件,能够将长文本内容一键转换为专业、美观的信息图表。
|
||||
|
||||
## 🔥 v1.4.9 更新日志
|
||||
|
||||
- 🎨 **70+ 官方模板**:全面集成 AntV 官方信息图模板库。
|
||||
- 🖼️ **图标与插图支持**:支持 Iconify 图标库与 unDraw 插图库,视觉效果更丰富。
|
||||
- 📏 **视觉优化**:改进文本换行逻辑,优化自适应尺寸,提升卡片布局精细度。
|
||||
- ✨ **PNG 上传**:信息图现在以 PNG 格式上传,与 Word 导出完美兼容。
|
||||
- 🔧 **Canvas 转换**:使用浏览器 Canvas 高质量转换 SVG 为 PNG(2倍缩放)。
|
||||
|
||||
### 此前: v1.4.0
|
||||
|
||||
- ✨ **默认模式变更**:默认输出模式调整为 `image`(静态图片)。
|
||||
- 📱 **响应式尺寸**:图片模式下自动适应聊天容器宽度。
|
||||
|
||||
## ✨ 核心特性
|
||||
|
||||
- 🚀 **智能转换**:自动分析文本核心逻辑,提取关键点并生成结构化图表。
|
||||
- 🎨 **专业模板**:内置多种 AntV 官方模板,包括列表、树图、思维导图、对比图、流程图及统计图表等。
|
||||
- 🔍 **自动图标匹配**:内置图标搜索逻辑,根据内容自动匹配最相关的 Material Design Icons。
|
||||
- 🎨 **70+ 专业模板**:内置多种 AntV 官方模板,包括列表、树图、路线图、时间线、对比图、SWOT、象限图及统计图表等。
|
||||
- 🔍 **自动图标匹配**:内置图标搜索逻辑,支持 Iconify 图标和 unDraw 插图自动匹配。
|
||||
- 📥 **多格式导出**:支持一键下载为 **SVG**、**PNG** 或 **独立 HTML** 文件。
|
||||
- 🌈 **高度自定义**:支持深色/浅色模式,自动适配主题颜色,主标题加粗突出,卡片布局精美。
|
||||
- 📱 **响应式设计**:生成的图表在桌面端和移动端均有良好的展示效果。
|
||||
|
||||
## 🛠️ 支持的模板类型
|
||||
|
||||
| 分类 | 模板名称 | 适用场景 |
|
||||
| :--- | :--- | :--- |
|
||||
| **列表与层级** | `list-grid`, `tree-vertical`, `mindmap` | 功能亮点、组织架构、思维导图 |
|
||||
| **顺序与关系** | `sequence-roadmap`, `relation-circle` | 发展历程、循环关系、步骤说明 |
|
||||
| **对比与分析** | `compare-binary`, `compare-swot`, `quadrant-quarter` | 优劣势对比、SWOT 分析、象限图 |
|
||||
| **图表与数据** | `chart-bar`, `chart-line`, `chart-pie` | 数据趋势、比例分布、数值对比 |
|
||||
|
||||
## 🚀 使用方法
|
||||
|
||||
1. **安装插件**:在 Open WebUI 插件市场搜索并安装。
|
||||
@@ -38,6 +44,25 @@
|
||||
| **最小文本长度 (MIN_TEXT_LENGTH)** | `100` | 触发分析所需的最小字符数,防止对过短的对话误操作。 |
|
||||
| **清除旧结果 (CLEAR_PREVIOUS_HTML)** | `False` | 每次生成是否清除之前的图表。若为 `False`,新图表将追加在下方。 |
|
||||
| **上下文消息数 (MESSAGE_COUNT)** | `1` | 用于分析的最近消息条数。增加此值可让 AI 参考更多对话背景。 |
|
||||
| **输出模式 (OUTPUT_MODE)** | `image` | `image` 为静态图片嵌入(默认,兼容性好),`html` 为交互式图表。 |
|
||||
|
||||
## 🛠️ 支持的模板类型
|
||||
|
||||
| 分类 | 模板名称 | 适用场景 |
|
||||
| :--- | :--- | :--- |
|
||||
| **时序与流程** | `sequence-timeline-simple`, `sequence-roadmap-vertical-simple`, `sequence-snake-steps-compact-card` | 时间线、路线图、步骤说明 |
|
||||
| **列表与网格** | `list-grid-candy-card-lite`, `list-row-horizontal-icon-arrow`, `list-column-simple-vertical-arrow` | 功能亮点、要点列举、清单 |
|
||||
| **对比与分析** | `compare-binary-horizontal-underline-text-vs`, `compare-swot`, `quadrant-quarter-simple-card` | 优劣势对比、SWOT 分析、象限图 |
|
||||
| **层级与结构** | `hierarchy-tree-tech-style-capsule-item`, `hierarchy-structure` | 组织架构、层级关系 |
|
||||
| **图表与数据** | `chart-column-simple`, `chart-bar-plain-text`, `chart-line-plain-text`, `chart-wordcloud` | 数据趋势、比例分布、数值对比 |
|
||||
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
- **插件不工作?**: 请检查是否在模型设置中启用了该过滤器/动作。
|
||||
- **调试日志**: 在 Valves 中启用 `SHOW_STATUS` 以查看进度更新。
|
||||
- **错误信息**: 如果看到错误,请复制完整的错误信息并报告。
|
||||
- **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
|
||||
## 📝 语法示例 (高级用户)
|
||||
|
||||
@@ -54,12 +79,3 @@ data
|
||||
- label 视觉精美
|
||||
desc 采用 AntV 专业设计规范
|
||||
```
|
||||
|
||||
## 👨💻 作者
|
||||
|
||||
**jeff**
|
||||
- GitHub: [Fu-Jie/awesome-openwebui](https://github.com/Fu-Jie/awesome-openwebui)
|
||||
|
||||
## 📄 许可证
|
||||
|
||||
MIT License
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user