Compare commits
46 Commits
v2026.01.1
...
v2026.01.2
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
500e090b11 | ||
|
|
a75ee555fa | ||
|
|
6a8c2164cd | ||
|
|
7f7efa325a | ||
|
|
9ba6cb08fc | ||
|
|
1872271a2d | ||
|
|
813b50864a | ||
|
|
b18cefe320 | ||
|
|
a54c359fcf | ||
|
|
8d83221a4a | ||
|
|
1879000720 | ||
|
|
ba92649a98 | ||
|
|
d2276dcaae | ||
|
|
25c9d20f3d | ||
|
|
0d853577df | ||
|
|
f91f3d8692 | ||
|
|
0f7cad8dfa | ||
|
|
db1a1e7ef0 | ||
|
|
e7de80a059 | ||
|
|
0d8c4e048e | ||
|
|
014a5a9d1f | ||
|
|
a6dd970859 | ||
|
|
aac730f5b1 | ||
|
|
ff95d9328e | ||
|
|
afe1d8cf52 | ||
|
|
67b819f3de | ||
|
|
9b6acb6b95 | ||
|
|
a9a59e1e34 | ||
|
|
5b05397356 | ||
|
|
7a7dbc0cfa | ||
|
|
6ac0ba6efe | ||
|
|
d3d008efb4 | ||
|
|
4f1528128a | ||
|
|
93c4326206 | ||
|
|
0fca7fe524 | ||
|
|
afdcab10c6 | ||
|
|
f8cc5eabe6 | ||
|
|
f304eb7633 | ||
|
|
827204e082 | ||
|
|
641d7ee8c8 | ||
|
|
3b11537b5e | ||
|
|
e51d87ae80 | ||
|
|
f16e7c996c | ||
|
|
55eb295c12 | ||
|
|
4767351c5e | ||
|
|
1d2502eb3f |
@@ -90,6 +90,9 @@ Reference: `.github/workflows/release.yml`
|
||||
- Action: Automatically updates the plugin code and metadata on OpenWebUI.com using `scripts/publish_plugin.py`.
|
||||
- **Auto-Sync**: If a local plugin has no ID but matches an existing published plugin by **Title**, the script will automatically fetch the ID, update the local file, and proceed with the update.
|
||||
- Requirement: `OPENWEBUI_API_KEY` secret must be set.
|
||||
- **README Link**: When announcing a release, always include the GitHub README URL for the plugin:
|
||||
- Format: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/{type}/{name}/README.md`
|
||||
- Example: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/README.md`
|
||||
|
||||
### Pull Request Check
|
||||
- Workflow: `.github/workflows/plugin-version-check.yml`
|
||||
|
||||
@@ -36,6 +36,15 @@
|
||||
"bug",
|
||||
"ideas"
|
||||
]
|
||||
},
|
||||
{
|
||||
"login": "nahoj",
|
||||
"name": "Johan Grande",
|
||||
"avatar_url": "https://avatars.githubusercontent.com/u/469017?v=4",
|
||||
"profile": "https://perso.crans.org/grande/",
|
||||
"contributions": [
|
||||
"ideas"
|
||||
]
|
||||
}
|
||||
],
|
||||
"contributorsPerLine": 7,
|
||||
|
||||
16
.github/copilot-instructions.md
vendored
16
.github/copilot-instructions.md
vendored
@@ -822,6 +822,22 @@ Filter 实例是**单例 (Singleton)**。
|
||||
|
||||
#### Commit Message 规范
|
||||
使用 Conventional Commits 格式 (`feat`, `fix`, `docs`, etc.)。
|
||||
**必须**在提交标题与正文中清晰描述变更内容,确保在 Release 页面可读且可追踪。
|
||||
|
||||
要求:
|
||||
- 标题必须包含“做了什么”与影响范围(避免含糊词)。
|
||||
- 正文必须列出关键变更点(1-3 条),与实际改动一一对应。
|
||||
- 若影响用户或插件行为,必须在正文标明影响与迁移说明。
|
||||
|
||||
推荐格式:
|
||||
- `feat(actions): add export settings panel`
|
||||
- `fix(filters): handle empty metadata to avoid crash`
|
||||
- `docs(plugins): update bilingual README structure`
|
||||
|
||||
正文示例:
|
||||
- Add valves for export format selection
|
||||
- Update README/README_CN to include What's New section
|
||||
- Migration: default TITLE_SOURCE changed to chat_title
|
||||
|
||||
### 4. 🤖 Git Operations (Agent Rules)
|
||||
|
||||
|
||||
24
README.md
24
README.md
@@ -1,6 +1,6 @@
|
||||
# OpenWebUI Extras
|
||||
<!-- ALL-CONTRIBUTORS-BADGE:START - Do not remove or modify this section -->
|
||||
[](#contributors-)
|
||||
[](#contributors-)
|
||||
<!-- ALL-CONTRIBUTORS-BADGE:END -->
|
||||
|
||||
English | [中文](./README_CN.md)
|
||||
@@ -10,28 +10,28 @@ A collection of enhancements, plugins, and prompts for [OpenWebUI](https://githu
|
||||
<!-- STATS_START -->
|
||||
## 📊 Community Stats
|
||||
|
||||
> 🕐 Auto-updated: 2026-01-17 12:15
|
||||
> 🕐 Auto-updated: 2026-01-21 21:22
|
||||
|
||||
| 👤 Author | 👥 Followers | ⭐ Points | 🏆 Contributions |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **118** | **108** | **25** |
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **143** | **135** | **26** |
|
||||
|
||||
| 📝 Posts | ⬇️ Downloads | 👁️ Views | 👍 Upvotes | 💾 Saves |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| **16** | **1609** | **19531** | **94** | **123** |
|
||||
| **17** | **1974** | **22983** | **121** | **153** |
|
||||
|
||||
### 🔥 Top 6 Popular Plugins
|
||||
|
||||
> 🕐 Auto-updated: 2026-01-17 12:15
|
||||
> 🕐 Auto-updated: 2026-01-21 21:22
|
||||
|
||||
| Rank | Plugin | Version | Downloads | Views | Updated |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 502 | 4566 | 2026-01-16 |
|
||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 215 | 2215 | 2026-01-14 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 201 | 738 | 2026-01-07 |
|
||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.1.3 | 171 | 1880 | 2026-01-14 |
|
||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 128 | 1214 | 2026-01-14 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 128 | 2241 | 2026-01-07 |
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 562 | 5047 | 2026-01-17 |
|
||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 298 | 2777 | 2026-01-18 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 227 | 897 | 2026-01-07 |
|
||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.1 | 197 | 2137 | 2026-01-20 |
|
||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 179 | 1509 | 2026-01-17 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 147 | 2434 | 2026-01-17 |
|
||||
|
||||
*See full stats in [Community Stats Report](./docs/community-stats.md)*
|
||||
<!-- STATS_END -->
|
||||
@@ -53,6 +53,7 @@ Located in the `plugins/` directory, containing Python-based enhancements:
|
||||
#### Filters
|
||||
- **Async Context Compression** (`async-context-compression`): Optimizes token usage via context compression.
|
||||
- **Context Enhancement** (`context_enhancement_filter`): Enhances chat context.
|
||||
- **Folder Memory** (`folder-memory`): Automatically extracts project rules from conversations and injects them into the folder's system prompt.
|
||||
- **Markdown Normalizer** (`markdown_normalizer`): Fixes common Markdown formatting issues in LLM outputs.
|
||||
|
||||
#### Pipelines
|
||||
@@ -119,6 +120,7 @@ Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/d
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://github.com/rbb-dev"><img src="https://avatars.githubusercontent.com/u/37469229?v=4?s=100" width="100px;" alt="rbb-dev"/><br /><sub><b>rbb-dev</b></sub></a><br /><a href="#ideas-rbb-dev" title="Ideas, Planning, & Feedback">🤔</a> <a href="https://github.com/Fu-Jie/awesome-openwebui/commits?author=rbb-dev" title="Code">💻</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://trade.xyz/?ref=BZ1RJRXWO"><img src="https://avatars.githubusercontent.com/u/7317522?v=4?s=100" width="100px;" alt="Raxxoor"/><br /><sub><b>Raxxoor</b></sub></a><br /><a href="https://github.com/Fu-Jie/awesome-openwebui/issues?q=author%3Adhaern" title="Bug reports">🐛</a> <a href="#ideas-dhaern" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://github.com/i-iooi-i"><img src="https://avatars.githubusercontent.com/u/1827701?v=4?s=100" width="100px;" alt="ZOLO"/><br /><sub><b>ZOLO</b></sub></a><br /><a href="https://github.com/Fu-Jie/awesome-openwebui/issues?q=author%3Ai-iooi-i" title="Bug reports">🐛</a> <a href="#ideas-i-iooi-i" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
<td align="center" valign="top" width="14.28%"><a href="https://perso.crans.org/grande/"><img src="https://avatars.githubusercontent.com/u/469017?v=4?s=100" width="100px;" alt="Johan Grande"/><br /><sub><b>Johan Grande</b></sub></a><br /><a href="#ideas-nahoj" title="Ideas, Planning, & Feedback">🤔</a></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
21
README_CN.md
21
README_CN.md
@@ -7,28 +7,28 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
||||
<!-- STATS_START -->
|
||||
## 📊 社区统计
|
||||
|
||||
> 🕐 自动更新于 2026-01-17 12:15
|
||||
> 🕐 自动更新于 2026-01-21 21:22
|
||||
|
||||
| 👤 作者 | 👥 粉丝 | ⭐ 积分 | 🏆 贡献 |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **118** | **108** | **25** |
|
||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **143** | **135** | **26** |
|
||||
|
||||
| 📝 发布 | ⬇️ 下载 | 👁️ 浏览 | 👍 点赞 | 💾 收藏 |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| **16** | **1609** | **19531** | **94** | **123** |
|
||||
| **17** | **1974** | **22983** | **121** | **153** |
|
||||
|
||||
### 🔥 热门插件 Top 6
|
||||
|
||||
> 🕐 自动更新于 2026-01-17 12:15
|
||||
> 🕐 自动更新于 2026-01-21 21:22
|
||||
|
||||
| 排名 | 插件 | 版本 | 下载 | 浏览 | 更新日期 |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 502 | 4566 | 2026-01-16 |
|
||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 215 | 2215 | 2026-01-14 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 201 | 738 | 2026-01-07 |
|
||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.1.3 | 171 | 1880 | 2026-01-14 |
|
||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 128 | 1214 | 2026-01-14 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 128 | 2241 | 2026-01-07 |
|
||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 562 | 5047 | 2026-01-17 |
|
||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 298 | 2777 | 2026-01-18 |
|
||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 227 | 897 | 2026-01-07 |
|
||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.1 | 197 | 2137 | 2026-01-20 |
|
||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 179 | 1509 | 2026-01-17 |
|
||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 147 | 2434 | 2026-01-17 |
|
||||
|
||||
*完整统计请查看 [社区统计报告](./docs/community-stats.zh.md)*
|
||||
<!-- STATS_END -->
|
||||
@@ -50,6 +50,7 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
||||
#### Filters (消息处理)
|
||||
- **Async Context Compression** (`async-context-compression`): 异步上下文压缩,优化 Token 使用。
|
||||
- **Context Enhancement** (`context_enhancement_filter`): 上下文增强过滤器。
|
||||
- **Folder Memory** (`folder-memory`): 自动从对话中提取项目规则并注入到文件夹系统提示词中。
|
||||
- **Gemini Manifold Companion** (`gemini_manifold_companion`): Gemini Manifold 配套增强。
|
||||
- **Gemini Multimodal Filter** (`web_gemini_multimodel_filter`): 为任意模型提供多模态能力(PDF、Office、视频等),支持智能路由和字幕精修。
|
||||
- **Markdown Normalizer** (`markdown_normalizer`): 修复 LLM 输出中常见的 Markdown 格式问题。
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "downloads",
|
||||
"message": "1.6k",
|
||||
"message": "2.0k",
|
||||
"color": "blue",
|
||||
"namedLogo": "openwebui"
|
||||
}
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "followers",
|
||||
"message": "118",
|
||||
"message": "143",
|
||||
"color": "blue"
|
||||
}
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "plugins",
|
||||
"message": "16",
|
||||
"message": "17",
|
||||
"color": "green"
|
||||
}
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "points",
|
||||
"message": "108",
|
||||
"message": "135",
|
||||
"color": "orange"
|
||||
}
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"schemaVersion": 1,
|
||||
"label": "upvotes",
|
||||
"message": "94",
|
||||
"message": "121",
|
||||
"color": "brightgreen"
|
||||
}
|
||||
@@ -1,12 +1,13 @@
|
||||
{
|
||||
"total_posts": 16,
|
||||
"total_downloads": 1609,
|
||||
"total_views": 19531,
|
||||
"total_upvotes": 94,
|
||||
"total_posts": 17,
|
||||
"total_downloads": 1974,
|
||||
"total_views": 22983,
|
||||
"total_upvotes": 121,
|
||||
"total_downvotes": 2,
|
||||
"total_saves": 123,
|
||||
"total_comments": 23,
|
||||
"total_saves": 153,
|
||||
"total_comments": 24,
|
||||
"by_type": {
|
||||
"filter": 1,
|
||||
"action": 14,
|
||||
"unknown": 2
|
||||
},
|
||||
@@ -18,13 +19,13 @@
|
||||
"version": "0.9.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Intelligently analyzes text content and generates interactive mind maps to help users structure and visualize knowledge.",
|
||||
"downloads": 502,
|
||||
"views": 4566,
|
||||
"upvotes": 13,
|
||||
"saves": 28,
|
||||
"downloads": 562,
|
||||
"views": 5047,
|
||||
"upvotes": 15,
|
||||
"saves": 31,
|
||||
"comments": 11,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-16",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a"
|
||||
},
|
||||
{
|
||||
@@ -34,13 +35,13 @@
|
||||
"version": "1.4.9",
|
||||
"author": "Fu-Jie",
|
||||
"description": "AI-powered infographic generator based on AntV Infographic. Supports professional templates, auto-icon matching, and SVG/PNG downloads.",
|
||||
"downloads": 215,
|
||||
"views": 2215,
|
||||
"upvotes": 10,
|
||||
"saves": 15,
|
||||
"comments": 2,
|
||||
"downloads": 298,
|
||||
"views": 2777,
|
||||
"upvotes": 14,
|
||||
"saves": 22,
|
||||
"comments": 3,
|
||||
"created_at": "2025-12-28",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-18",
|
||||
"url": "https://openwebui.com/posts/smart_infographic_ad6f0c7f"
|
||||
},
|
||||
{
|
||||
@@ -50,10 +51,10 @@
|
||||
"version": "0.3.7",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Extracts tables from chat messages and exports them to Excel (.xlsx) files with smart formatting.",
|
||||
"downloads": 201,
|
||||
"views": 738,
|
||||
"upvotes": 3,
|
||||
"saves": 5,
|
||||
"downloads": 227,
|
||||
"views": 897,
|
||||
"upvotes": 4,
|
||||
"saves": 6,
|
||||
"comments": 0,
|
||||
"created_at": "2025-05-30",
|
||||
"updated_at": "2026-01-07",
|
||||
@@ -63,16 +64,16 @@
|
||||
"title": "Async Context Compression",
|
||||
"slug": "async_context_compression_b1655bc8",
|
||||
"type": "action",
|
||||
"version": "1.1.3",
|
||||
"version": "1.2.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.",
|
||||
"downloads": 171,
|
||||
"views": 1880,
|
||||
"upvotes": 7,
|
||||
"saves": 18,
|
||||
"downloads": 197,
|
||||
"views": 2137,
|
||||
"upvotes": 9,
|
||||
"saves": 23,
|
||||
"comments": 0,
|
||||
"created_at": "2025-11-08",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-20",
|
||||
"url": "https://openwebui.com/posts/async_context_compression_b1655bc8"
|
||||
},
|
||||
{
|
||||
@@ -82,13 +83,13 @@
|
||||
"version": "0.4.3",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Export current conversation from Markdown to Word (.docx) with Mermaid diagrams rendered client-side (Mermaid.js, SVG+PNG), LaTeX math, real hyperlinks, improved tables, syntax highlighting, and blockquote support.",
|
||||
"downloads": 128,
|
||||
"views": 1214,
|
||||
"upvotes": 6,
|
||||
"saves": 14,
|
||||
"downloads": 179,
|
||||
"views": 1509,
|
||||
"upvotes": 8,
|
||||
"saves": 18,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-03",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315"
|
||||
},
|
||||
{
|
||||
@@ -98,15 +99,31 @@
|
||||
"version": "0.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Quickly generates beautiful flashcards from text, extracting key points and categories.",
|
||||
"downloads": 128,
|
||||
"views": 2241,
|
||||
"upvotes": 8,
|
||||
"saves": 10,
|
||||
"downloads": 147,
|
||||
"views": 2434,
|
||||
"upvotes": 10,
|
||||
"saves": 12,
|
||||
"comments": 2,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-07",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/flash_card_65a2ea8f"
|
||||
},
|
||||
{
|
||||
"title": "Markdown Normalizer",
|
||||
"slug": "markdown_normalizer_baaa8732",
|
||||
"type": "action",
|
||||
"version": "1.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.",
|
||||
"downloads": 100,
|
||||
"views": 2311,
|
||||
"upvotes": 10,
|
||||
"saves": 17,
|
||||
"comments": 5,
|
||||
"created_at": "2026-01-12",
|
||||
"updated_at": "2026-01-19",
|
||||
"url": "https://openwebui.com/posts/markdown_normalizer_baaa8732"
|
||||
},
|
||||
{
|
||||
"title": "Deep Dive",
|
||||
"slug": "deep_dive_c0b846e4",
|
||||
@@ -114,10 +131,10 @@
|
||||
"version": "1.0.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.",
|
||||
"downloads": 57,
|
||||
"views": 596,
|
||||
"upvotes": 3,
|
||||
"saves": 5,
|
||||
"downloads": 76,
|
||||
"views": 740,
|
||||
"upvotes": 4,
|
||||
"saves": 7,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-08",
|
||||
"updated_at": "2026-01-08",
|
||||
@@ -130,31 +147,15 @@
|
||||
"version": "0.4.3",
|
||||
"author": "Fu-Jie",
|
||||
"description": "将对话导出为 Word (.docx),支持 Mermaid 图表 (客户端渲染 SVG+PNG)、LaTeX 数学公式、真实超链接、增强表格格式、代码高亮和引用块。",
|
||||
"downloads": 56,
|
||||
"views": 1231,
|
||||
"upvotes": 9,
|
||||
"downloads": 69,
|
||||
"views": 1392,
|
||||
"upvotes": 11,
|
||||
"saves": 3,
|
||||
"comments": 1,
|
||||
"created_at": "2026-01-04",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0"
|
||||
},
|
||||
{
|
||||
"title": "Markdown Normalizer",
|
||||
"slug": "markdown_normalizer_baaa8732",
|
||||
"type": "action",
|
||||
"version": "1.1.2",
|
||||
"author": "Fu-Jie",
|
||||
"description": "A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.",
|
||||
"downloads": 55,
|
||||
"views": 1642,
|
||||
"upvotes": 8,
|
||||
"saves": 14,
|
||||
"comments": 5,
|
||||
"created_at": "2026-01-12",
|
||||
"updated_at": "2026-01-13",
|
||||
"url": "https://openwebui.com/posts/markdown_normalizer_baaa8732"
|
||||
},
|
||||
{
|
||||
"title": "📊 智能信息图 (AntV Infographic)",
|
||||
"slug": "智能信息图_e04a48ff",
|
||||
@@ -162,13 +163,13 @@
|
||||
"version": "1.4.9",
|
||||
"author": "Fu-Jie",
|
||||
"description": "基于 AntV Infographic 的智能信息图生成插件。支持多种专业模板,自动图标匹配,并提供 SVG/PNG 下载功能。",
|
||||
"downloads": 41,
|
||||
"views": 644,
|
||||
"upvotes": 4,
|
||||
"downloads": 45,
|
||||
"views": 718,
|
||||
"upvotes": 6,
|
||||
"saves": 0,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-28",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/智能信息图_e04a48ff"
|
||||
},
|
||||
{
|
||||
@@ -178,31 +179,15 @@
|
||||
"version": "0.9.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "智能分析文本内容,生成交互式思维导图,帮助用户结构化和可视化知识。",
|
||||
"downloads": 22,
|
||||
"views": 385,
|
||||
"upvotes": 2,
|
||||
"downloads": 27,
|
||||
"views": 417,
|
||||
"upvotes": 3,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-31",
|
||||
"updated_at": "2026-01-14",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b"
|
||||
},
|
||||
{
|
||||
"title": "异步上下文压缩",
|
||||
"slug": "异步上下文压缩_5c0617cb",
|
||||
"type": "action",
|
||||
"version": "1.1.3",
|
||||
"author": "Fu-Jie",
|
||||
"description": "通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。",
|
||||
"downloads": 14,
|
||||
"views": 332,
|
||||
"upvotes": 4,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-11-08",
|
||||
"updated_at": "2026-01-14",
|
||||
"url": "https://openwebui.com/posts/异步上下文压缩_5c0617cb"
|
||||
},
|
||||
{
|
||||
"title": "闪记卡 (Flash Card)",
|
||||
"slug": "闪记卡生成插件_4a31eac3",
|
||||
@@ -210,15 +195,31 @@
|
||||
"version": "0.2.4",
|
||||
"author": "Fu-Jie",
|
||||
"description": "快速将文本提炼为精美的学习记忆卡片,支持核心要点提取与分类。",
|
||||
"downloads": 13,
|
||||
"views": 420,
|
||||
"upvotes": 4,
|
||||
"downloads": 19,
|
||||
"views": 471,
|
||||
"upvotes": 5,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-12-30",
|
||||
"updated_at": "2026-01-07",
|
||||
"updated_at": "2026-01-17",
|
||||
"url": "https://openwebui.com/posts/闪记卡生成插件_4a31eac3"
|
||||
},
|
||||
{
|
||||
"title": "异步上下文压缩",
|
||||
"slug": "异步上下文压缩_5c0617cb",
|
||||
"type": "action",
|
||||
"version": "1.2.1",
|
||||
"author": "Fu-Jie",
|
||||
"description": "通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。",
|
||||
"downloads": 14,
|
||||
"views": 401,
|
||||
"upvotes": 5,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2025-11-08",
|
||||
"updated_at": "2026-01-20",
|
||||
"url": "https://openwebui.com/posts/异步上下文压缩_5c0617cb"
|
||||
},
|
||||
{
|
||||
"title": "精读",
|
||||
"slug": "精读_99830b0f",
|
||||
@@ -226,15 +227,31 @@
|
||||
"version": "1.0.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。",
|
||||
"downloads": 6,
|
||||
"views": 254,
|
||||
"upvotes": 2,
|
||||
"downloads": 8,
|
||||
"views": 276,
|
||||
"upvotes": 3,
|
||||
"saves": 1,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-08",
|
||||
"updated_at": "2026-01-08",
|
||||
"url": "https://openwebui.com/posts/精读_99830b0f"
|
||||
},
|
||||
{
|
||||
"title": "📂 Folder Memory – Auto-Evolving Project Context",
|
||||
"slug": "folder_memory_auto_evolving_project_context_4a9875b2",
|
||||
"type": "filter",
|
||||
"version": "0.1.0",
|
||||
"author": "Fu-Jie",
|
||||
"description": "Automatically extracts project rules from conversations and injects them into the folder's system prompt.",
|
||||
"downloads": 6,
|
||||
"views": 162,
|
||||
"upvotes": 1,
|
||||
"saves": 2,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-20",
|
||||
"updated_at": "2026-01-20",
|
||||
"url": "https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2"
|
||||
},
|
||||
{
|
||||
"title": "Review of Claude Haiku 4.5",
|
||||
"slug": "review_of_claude_haiku_45_41b0db39",
|
||||
@@ -243,8 +260,8 @@
|
||||
"author": "",
|
||||
"description": "",
|
||||
"downloads": 0,
|
||||
"views": 41,
|
||||
"upvotes": 0,
|
||||
"views": 71,
|
||||
"upvotes": 1,
|
||||
"saves": 0,
|
||||
"comments": 0,
|
||||
"created_at": "2026-01-14",
|
||||
@@ -259,9 +276,9 @@
|
||||
"author": "",
|
||||
"description": "",
|
||||
"downloads": 0,
|
||||
"views": 1132,
|
||||
"upvotes": 11,
|
||||
"saves": 7,
|
||||
"views": 1223,
|
||||
"upvotes": 12,
|
||||
"saves": 8,
|
||||
"comments": 2,
|
||||
"created_at": "2026-01-10",
|
||||
"updated_at": "2026-01-10",
|
||||
@@ -273,11 +290,11 @@
|
||||
"name": "Fu-Jie",
|
||||
"profile_url": "https://openwebui.com/u/Fu-Jie",
|
||||
"profile_image": "https://community.s3.openwebui.com/uploads/users/b15d1348-4347-42b4-b815-e053342d6cb0/profile_d9510745-4bd4-4f8f-a997-4a21847d9300.webp",
|
||||
"followers": 118,
|
||||
"followers": 143,
|
||||
"following": 2,
|
||||
"total_points": 108,
|
||||
"post_points": 92,
|
||||
"total_points": 135,
|
||||
"post_points": 119,
|
||||
"comment_points": 16,
|
||||
"contributions": 25
|
||||
"contributions": 26
|
||||
}
|
||||
}
|
||||
@@ -1,20 +1,21 @@
|
||||
# 📊 OpenWebUI Community Stats Report
|
||||
|
||||
> 📅 Updated: 2026-01-17 12:15
|
||||
> 📅 Updated: 2026-01-21 21:22
|
||||
|
||||
## 📈 Overview
|
||||
|
||||
| Metric | Value |
|
||||
|------|------|
|
||||
| 📝 Total Posts | 16 |
|
||||
| ⬇️ Total Downloads | 1609 |
|
||||
| 👁️ Total Views | 19531 |
|
||||
| 👍 Total Upvotes | 94 |
|
||||
| 💾 Total Saves | 123 |
|
||||
| 💬 Total Comments | 23 |
|
||||
| 📝 Total Posts | 17 |
|
||||
| ⬇️ Total Downloads | 1974 |
|
||||
| 👁️ Total Views | 22983 |
|
||||
| 👍 Total Upvotes | 121 |
|
||||
| 💾 Total Saves | 153 |
|
||||
| 💬 Total Comments | 24 |
|
||||
|
||||
## 📂 By Type
|
||||
|
||||
- **filter**: 1
|
||||
- **action**: 14
|
||||
- **unknown**: 2
|
||||
|
||||
@@ -22,19 +23,20 @@
|
||||
|
||||
| Rank | Title | Type | Version | Downloads | Views | Upvotes | Saves | Updated |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 502 | 4566 | 13 | 28 | 2026-01-16 |
|
||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 215 | 2215 | 10 | 15 | 2026-01-14 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 201 | 738 | 3 | 5 | 2026-01-07 |
|
||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.1.3 | 171 | 1880 | 7 | 18 | 2026-01-14 |
|
||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 128 | 1214 | 6 | 14 | 2026-01-14 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 128 | 2241 | 8 | 10 | 2026-01-07 |
|
||||
| 7 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 57 | 596 | 3 | 5 | 2026-01-08 |
|
||||
| 8 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 56 | 1231 | 9 | 3 | 2026-01-14 |
|
||||
| 9 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.1.2 | 55 | 1642 | 8 | 14 | 2026-01-13 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 41 | 644 | 4 | 0 | 2026-01-14 |
|
||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 22 | 385 | 2 | 1 | 2026-01-14 |
|
||||
| 12 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.1.3 | 14 | 332 | 4 | 1 | 2026-01-14 |
|
||||
| 13 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 13 | 420 | 4 | 1 | 2026-01-07 |
|
||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 6 | 254 | 2 | 1 | 2026-01-08 |
|
||||
| 15 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 41 | 0 | 0 | 2026-01-14 |
|
||||
| 16 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1132 | 11 | 7 | 2026-01-10 |
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 562 | 5047 | 15 | 31 | 2026-01-17 |
|
||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 298 | 2777 | 14 | 22 | 2026-01-18 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 227 | 897 | 4 | 6 | 2026-01-07 |
|
||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.1 | 197 | 2137 | 9 | 23 | 2026-01-20 |
|
||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 179 | 1509 | 8 | 18 | 2026-01-17 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 147 | 2434 | 10 | 12 | 2026-01-17 |
|
||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 100 | 2311 | 10 | 17 | 2026-01-19 |
|
||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 76 | 740 | 4 | 7 | 2026-01-08 |
|
||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 69 | 1392 | 11 | 3 | 2026-01-17 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 45 | 718 | 6 | 0 | 2026-01-17 |
|
||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 417 | 3 | 1 | 2026-01-17 |
|
||||
| 12 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 471 | 5 | 1 | 2026-01-17 |
|
||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.1 | 14 | 401 | 5 | 1 | 2026-01-20 |
|
||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 8 | 276 | 3 | 1 | 2026-01-08 |
|
||||
| 15 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 6 | 162 | 1 | 2 | 2026-01-20 |
|
||||
| 16 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 71 | 1 | 0 | 2026-01-14 |
|
||||
| 17 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1223 | 12 | 8 | 2026-01-10 |
|
||||
|
||||
@@ -1,20 +1,21 @@
|
||||
# 📊 OpenWebUI 社区统计报告
|
||||
|
||||
> 📅 更新时间: 2026-01-17 12:15
|
||||
> 📅 更新时间: 2026-01-21 21:22
|
||||
|
||||
## 📈 总览
|
||||
|
||||
| 指标 | 数值 |
|
||||
|------|------|
|
||||
| 📝 发布数量 | 16 |
|
||||
| ⬇️ 总下载量 | 1609 |
|
||||
| 👁️ 总浏览量 | 19531 |
|
||||
| 👍 总点赞数 | 94 |
|
||||
| 💾 总收藏数 | 123 |
|
||||
| 💬 总评论数 | 23 |
|
||||
| 📝 发布数量 | 17 |
|
||||
| ⬇️ 总下载量 | 1974 |
|
||||
| 👁️ 总浏览量 | 22983 |
|
||||
| 👍 总点赞数 | 121 |
|
||||
| 💾 总收藏数 | 153 |
|
||||
| 💬 总评论数 | 24 |
|
||||
|
||||
## 📂 按类型分类
|
||||
|
||||
- **filter**: 1
|
||||
- **action**: 14
|
||||
- **unknown**: 2
|
||||
|
||||
@@ -22,19 +23,20 @@
|
||||
|
||||
| 排名 | 标题 | 类型 | 版本 | 下载 | 浏览 | 点赞 | 收藏 | 更新日期 |
|
||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 502 | 4566 | 13 | 28 | 2026-01-16 |
|
||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 215 | 2215 | 10 | 15 | 2026-01-14 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 201 | 738 | 3 | 5 | 2026-01-07 |
|
||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.1.3 | 171 | 1880 | 7 | 18 | 2026-01-14 |
|
||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 128 | 1214 | 6 | 14 | 2026-01-14 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 128 | 2241 | 8 | 10 | 2026-01-07 |
|
||||
| 7 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 57 | 596 | 3 | 5 | 2026-01-08 |
|
||||
| 8 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 56 | 1231 | 9 | 3 | 2026-01-14 |
|
||||
| 9 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.1.2 | 55 | 1642 | 8 | 14 | 2026-01-13 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 41 | 644 | 4 | 0 | 2026-01-14 |
|
||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 22 | 385 | 2 | 1 | 2026-01-14 |
|
||||
| 12 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.1.3 | 14 | 332 | 4 | 1 | 2026-01-14 |
|
||||
| 13 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 13 | 420 | 4 | 1 | 2026-01-07 |
|
||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 6 | 254 | 2 | 1 | 2026-01-08 |
|
||||
| 15 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 41 | 0 | 0 | 2026-01-14 |
|
||||
| 16 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1132 | 11 | 7 | 2026-01-10 |
|
||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 562 | 5047 | 15 | 31 | 2026-01-17 |
|
||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 298 | 2777 | 14 | 22 | 2026-01-18 |
|
||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 227 | 897 | 4 | 6 | 2026-01-07 |
|
||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.1 | 197 | 2137 | 9 | 23 | 2026-01-20 |
|
||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 179 | 1509 | 8 | 18 | 2026-01-17 |
|
||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 147 | 2434 | 10 | 12 | 2026-01-17 |
|
||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 100 | 2311 | 10 | 17 | 2026-01-19 |
|
||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 76 | 740 | 4 | 7 | 2026-01-08 |
|
||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 69 | 1392 | 11 | 3 | 2026-01-17 |
|
||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 45 | 718 | 6 | 0 | 2026-01-17 |
|
||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 417 | 3 | 1 | 2026-01-17 |
|
||||
| 12 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 471 | 5 | 1 | 2026-01-17 |
|
||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.1 | 14 | 401 | 5 | 1 | 2026-01-20 |
|
||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 8 | 276 | 3 | 1 | 2026-01-08 |
|
||||
| 15 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 6 | 162 | 1 | 2 | 2026-01-20 |
|
||||
| 16 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 71 | 1 | 0 | 2026-01-14 |
|
||||
| 17 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1223 | 12 | 8 | 2026-01-10 |
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Async Context Compression
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v1.1.3</span>
|
||||
<span class="version-badge">v1.2.2</span>
|
||||
|
||||
Reduces token consumption in long conversations through intelligent summarization while maintaining conversational coherence.
|
||||
|
||||
@@ -34,6 +34,12 @@ This is especially useful for:
|
||||
- :material-check-all: **Open WebUI v0.7.x Compatibility**: Dynamic DB session handling
|
||||
- :material-account-convert: **Improved Compatibility**: Summary role changed to `assistant`
|
||||
- :material-shield-check: **Enhanced Stability**: Resolved race conditions in state management
|
||||
- :material-ruler: **Preflight Context Check**: Validates context fit before sending
|
||||
- :material-format-align-justify: **Structure-Aware Trimming**: Preserves document structure
|
||||
- :material-content-cut: **Native Tool Output Trimming**: Trims verbose tool outputs (Note: Non-native tool outputs are not fully injected into context)
|
||||
- :material-chart-bar: **Detailed Token Logging**: Granular token breakdown
|
||||
- :material-account-search: **Smart Model Matching**: Inherit config from base models
|
||||
- :material-image-off: **Multimodal Support**: Images are preserved but tokens are **NOT** calculated
|
||||
|
||||
---
|
||||
|
||||
@@ -64,10 +70,14 @@ graph TD
|
||||
|
||||
| Option | Type | Default | Description |
|
||||
|--------|------|---------|-------------|
|
||||
| `token_threshold` | integer | `4000` | Trigger compression above this token count |
|
||||
| `preserve_recent` | integer | `5` | Number of recent messages to keep uncompressed |
|
||||
| `summary_model` | string | `"auto"` | Model to use for summarization |
|
||||
| `compression_ratio` | float | `0.3` | Target compression ratio |
|
||||
| `compression_threshold_tokens` | integer | `64000` | Trigger compression above this token count |
|
||||
| `max_context_tokens` | integer | `128000` | Hard limit for context |
|
||||
| `keep_first` | integer | `1` | Always keep the first N messages |
|
||||
| `keep_last` | integer | `6` | Always keep the last N messages |
|
||||
| `summary_model` | string | `None` | Model to use for summarization |
|
||||
| `summary_model_max_context` | integer | `0` | Max context tokens for summary model |
|
||||
| `max_summary_tokens` | integer | `16384` | Maximum tokens for the summary |
|
||||
| `enable_tool_output_trimming` | boolean | `false` | Enable trimming of large tool outputs |
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Async Context Compression(异步上下文压缩)
|
||||
|
||||
<span class="category-badge filter">Filter</span>
|
||||
<span class="version-badge">v1.1.3</span>
|
||||
<span class="version-badge">v1.2.2</span>
|
||||
|
||||
通过智能摘要减少长对话的 token 消耗,同时保持对话连贯。
|
||||
|
||||
@@ -34,6 +34,12 @@ Async Context Compression 过滤器通过以下方式帮助管理长对话的 to
|
||||
- :material-check-all: **Open WebUI v0.7.x 兼容性**:动态数据库会话处理
|
||||
- :material-account-convert: **兼容性提升**:摘要角色改为 `assistant`
|
||||
- :material-shield-check: **稳定性增强**:解决状态管理竞态条件
|
||||
- :material-ruler: **预检上下文检查**:发送前验证上下文是否超限
|
||||
- :material-format-align-justify: **结构感知裁剪**:保留文档结构的智能裁剪
|
||||
- :material-content-cut: **原生工具输出裁剪**:自动裁剪冗长的工具输出(注意:非原生工具调用输出不会完整注入上下文)
|
||||
- :material-chart-bar: **详细 Token 日志**:提供细粒度的 Token 统计
|
||||
- :material-account-search: **智能模型匹配**:自定义模型自动继承基础模型配置
|
||||
- :material-image-off: **多模态支持**:图片内容保留但 Token **不参与计算**
|
||||
|
||||
---
|
||||
|
||||
@@ -64,10 +70,14 @@ graph TD
|
||||
|
||||
| 选项 | 类型 | 默认值 | 说明 |
|
||||
|--------|------|---------|-------------|
|
||||
| `token_threshold` | integer | `4000` | 超过该 token 数触发压缩 |
|
||||
| `preserve_recent` | integer | `5` | 保留不压缩的最近消息数量 |
|
||||
| `summary_model` | string | `"auto"` | 用于摘要的模型 |
|
||||
| `compression_ratio` | float | `0.3` | 目标压缩比例 |
|
||||
| `compression_threshold_tokens` | integer | `64000` | 超过该 token 数触发压缩 |
|
||||
| `max_context_tokens` | integer | `128000` | 上下文硬性上限 |
|
||||
| `keep_first` | integer | `1` | 始终保留的前 N 条消息 |
|
||||
| `keep_last` | integer | `6` | 始终保留的后 N 条消息 |
|
||||
| `summary_model` | string | `None` | 用于摘要的模型 |
|
||||
| `summary_model_max_context` | integer | `0` | 摘要模型的最大上下文 Token 数 |
|
||||
| `max_summary_tokens` | integer | `16384` | 摘要的最大 token 数 |
|
||||
| `enable_tool_output_trimming` | boolean | `false` | 启用长工具输出裁剪 |
|
||||
|
||||
---
|
||||
|
||||
|
||||
57
docs/plugins/filters/folder-memory.md
Normal file
57
docs/plugins/filters/folder-memory.md
Normal file
@@ -0,0 +1,57 @@
|
||||
# Folder Memory
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 What's new in 0.1.0
|
||||
- **Initial Release**: Automated "Project Rules" management for OpenWebUI folders.
|
||||
- **Folder-Level Persistence**: Automatically updates folder system prompts with extracted rules.
|
||||
- **Optimized Performance**: Runs asynchronously and supports `PRIORITY` configuration for seamless integration with other filters.
|
||||
|
||||
---
|
||||
|
||||
**Folder Memory** is an intelligent context filter plugin for OpenWebUI. It automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||
|
||||
This ensures that all future conversations within that folder share the same evolved context and rules, without manual updates.
|
||||
|
||||
## Features
|
||||
|
||||
- **Automatic Extraction**: Analyzes chat history every N messages to extract project rules.
|
||||
- **Non-destructive Injection**: Updates only the specific "Project Rules" block in the system prompt, preserving other instructions.
|
||||
- **Async Processing**: Runs in the background without blocking the user's chat experience.
|
||||
- **ORM Integration**: Directly updates folder data using OpenWebUI's internal models for reliability.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- **Conversations must occur inside a folder.** This plugin only triggers when a chat belongs to a folder (i.e., you need to create a folder in OpenWebUI and start a conversation within it).
|
||||
|
||||
## Installation
|
||||
|
||||
1. Copy `folder_memory.py` to your OpenWebUI `plugins/filters/` directory (or upload via Admin UI).
|
||||
2. Enable the filter in your **Settings** -> **Filters**.
|
||||
3. (Optional) Configure the triggering threshold (default: every 10 messages).
|
||||
|
||||
## Configuration (Valves)
|
||||
|
||||
| Valve | Default | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | Priority level for the filter operations. |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | The number of messages required to trigger a rule analysis. |
|
||||
| `MODEL_ID` | `""` | The model used to generate rules. If empty, uses the current chat model. |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 Project Rules` | The title displayed above the injected rules block. |
|
||||
| `SHOW_DEBUG_LOG` | `False` | Show detailed debug logs in the browser console. |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | If enabled, finds and updates the root folder rules instead of the current subfolder. |
|
||||
|
||||
## How It Works
|
||||
|
||||
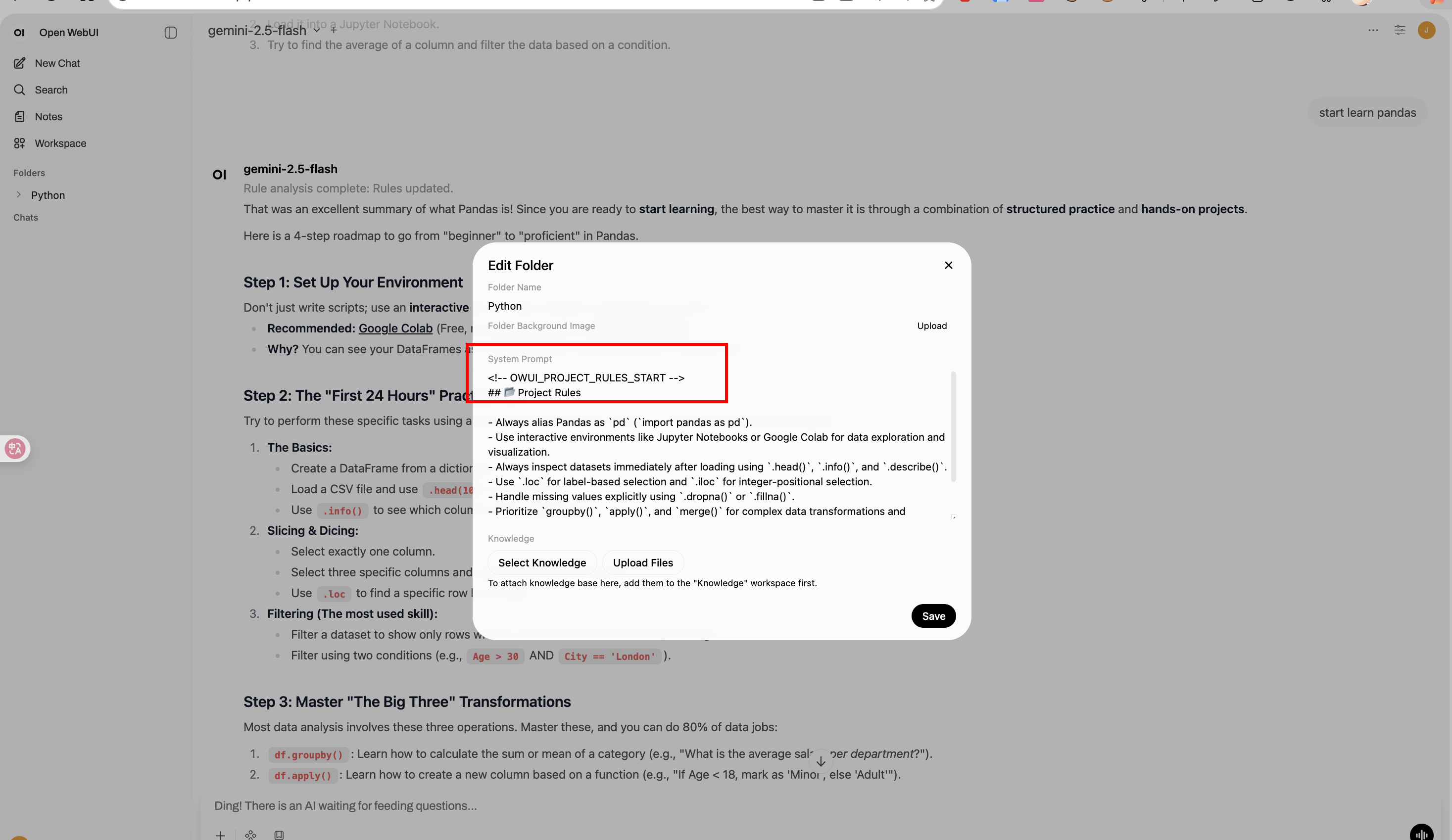
|
||||
|
||||
1. **Trigger**: When a conversation reaches `MESSAGE_TRIGGER_COUNT` (e.g., 10, 20 messages).
|
||||
2. **Analysis**: The plugin sends the recent conversation + existing rules to the LLM.
|
||||
3. **Synthesis**: The LLM merges new insights with old rules, removing obsolete ones.
|
||||
4. **Update**: The new rule set replaces the `<!-- OWUI_PROJECT_RULES_START -->` block in the folder's system prompt.
|
||||
|
||||
## Roadmap
|
||||
|
||||
See [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) for future plans, including "Project Knowledge" collection.
|
||||
57
docs/plugins/filters/folder-memory.zh.md
Normal file
57
docs/plugins/filters/folder-memory.zh.md
Normal file
@@ -0,0 +1,57 @@
|
||||
# 文件夹记忆 (Folder Memory)
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 0.1.0 版本特性
|
||||
- **首个版本发布**:专注于自动化的“项目规则”管理。
|
||||
- **文件夹级持久化**:自动将提取的规则回写到文件夹系统提示词中。
|
||||
- **性能优化**:采用异步处理机制,并支持 `PRIORITY` 配置,确保与其他过滤器(如上下文压缩)完美协作。
|
||||
|
||||
---
|
||||
|
||||
**文件夹记忆 (Folder Memory)** 是一个 OpenWebUI 的智能上下文过滤器插件。它能自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||
|
||||
这确保了该文件夹内的所有未来对话都能共享相同的进化上下文和规则,无需手动更新。
|
||||
|
||||
## 功能特性
|
||||
|
||||
- **自动提取**:每隔 N 条消息分析一次聊天记录,提取项目规则。
|
||||
- **无损注入**:仅更新系统提示词中的特定“项目规则”块,保留其他指令。
|
||||
- **异步处理**:在后台运行,不阻塞用户的聊天体验。
|
||||
- **ORM 集成**:直接使用 OpenWebUI 的内部模型更新文件夹数据,确保可靠性。
|
||||
|
||||
## 前置条件
|
||||
|
||||
- **对话必须在文件夹内进行。** 此插件仅在聊天属于某个文件夹时触发(即您需要先在 OpenWebUI 中创建一个文件夹,并在其内部开始对话)。
|
||||
|
||||
## 安装指南
|
||||
|
||||
1. 将 `folder_memory.py` (或中文版 `folder_memory_cn.py`) 复制到 OpenWebUI 的 `plugins/filters/` 目录(或通过管理员 UI 上传)。
|
||||
2. 在 **设置** -> **过滤器** 中启用该插件。
|
||||
3. (可选)配置触发阈值(默认:每 10 条消息)。
|
||||
|
||||
## 配置 (Valves)
|
||||
|
||||
| 参数 | 默认值 | 说明 |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | 过滤器操作的优先级。 |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | 触发规则分析的消息数量阈值。 |
|
||||
| `MODEL_ID` | `""` | 用于生成规则的模型 ID。若为空,则使用当前对话模型。 |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 项目规则` | 显示在注入规则块上方的标题。 |
|
||||
| `SHOW_DEBUG_LOG` | `False` | 在浏览器控制台显示详细调试日志。 |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | 如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。 |
|
||||
|
||||
## 工作原理
|
||||
|
||||

|
||||
|
||||
1. **触发**:当对话达到 `MESSAGE_TRIGGER_COUNT`(例如 10、20 条消息)时。
|
||||
2. **分析**:插件将最近的对话 + 现有规则发送给 LLM。
|
||||
3. **综合**:LLM 将新见解与旧规则合并,移除过时的规则。
|
||||
4. **更新**:新的规则集替换文件夹系统提示词中的 `<!-- OWUI_PROJECT_RULES_START -->` 块。
|
||||
|
||||
## 路线图
|
||||
|
||||
查看 [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) 了解未来计划,包括“项目知识”收集功能。
|
||||
@@ -22,7 +22,7 @@ Filters act as middleware in the message pipeline:
|
||||
|
||||
Reduces token consumption in long conversations through intelligent summarization while maintaining coherence.
|
||||
|
||||
**Version:** 1.1.3
|
||||
**Version:** 1.2.2
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](async-context-compression.md)
|
||||
|
||||
@@ -36,7 +36,15 @@ Filters act as middleware in the message pipeline:
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](context-enhancement.md)
|
||||
|
||||
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||
|
||||
---
|
||||
|
||||
Automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||
|
||||
**Version:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](folder-memory.md)
|
||||
|
||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||
|
||||
@@ -44,7 +52,7 @@ Filters act as middleware in the message pipeline:
|
||||
|
||||
Fixes common Markdown formatting issues in LLM outputs, including Mermaid syntax, code blocks, and LaTeX formulas.
|
||||
|
||||
**Version:** 1.1.2
|
||||
**Version:** 1.2.4
|
||||
|
||||
[:octicons-arrow-right-24: Documentation](markdown_normalizer.md)
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ Filter 充当消息管线中的中间件:
|
||||
|
||||
通过智能总结减少长对话的 token 消耗,同时保持连贯性。
|
||||
|
||||
**版本:** 1.1.3
|
||||
**版本:** 1.2.2
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](async-context-compression.md)
|
||||
|
||||
@@ -36,7 +36,15 @@ Filter 充当消息管线中的中间件:
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](context-enhancement.md)
|
||||
|
||||
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||
|
||||
---
|
||||
|
||||
自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||
|
||||
**版本:** 0.1.0
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](folder-memory.zh.md)
|
||||
|
||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||
|
||||
@@ -44,7 +52,7 @@ Filter 充当消息管线中的中间件:
|
||||
|
||||
修复 LLM 输出中常见的 Markdown 格式问题,包括 Mermaid 语法、代码块和 LaTeX 公式。
|
||||
|
||||
**版本:** 1.0.1
|
||||
**版本:** 1.2.4
|
||||
|
||||
[:octicons-arrow-right-24: 查看文档](markdown_normalizer.zh.md)
|
||||
|
||||
|
||||
@@ -1,50 +1,97 @@
|
||||
# Markdown Normalizer Filter
|
||||
|
||||
A production-grade content normalizer filter for Open WebUI that fixes common Markdown formatting issues in LLM outputs. It ensures that code blocks, LaTeX formulas, Mermaid diagrams, and other Markdown elements are rendered correctly.
|
||||
A content normalizer filter for Open WebUI that fixes common Markdown formatting issues in LLM outputs. It ensures that code blocks, LaTeX formulas, Mermaid diagrams, and other Markdown elements are rendered correctly.
|
||||
|
||||
## Features
|
||||
|
||||
* **Details Tag Normalization**: Ensures proper spacing for `<details>` tags (used for thought chains). Adds a blank line after `</details>` and ensures a newline after self-closing `<details />` tags to prevent rendering issues.
|
||||
* **Mermaid Syntax Fix**: Automatically fixes common Mermaid syntax errors, such as unquoted node labels (including multi-line labels and citations) and unclosed subgraphs, ensuring diagrams render correctly.
|
||||
* **Frontend Console Debugging**: Supports printing structured debug logs directly to the browser console (F12) for easier troubleshooting.
|
||||
* **Code Block Formatting**: Fixes broken code block prefixes, suffixes, and indentation.
|
||||
* **LaTeX Normalization**: Standardizes LaTeX formula delimiters (`\[` -> `$$`, `\(` -> `$`).
|
||||
* **Thought Tag Normalization**: Unifies thought tags (`<think>`, `<thinking>` -> `<thought>`).
|
||||
* **Escape Character Fix**: Cleans up excessive escape characters (`\\n`, `\\t`).
|
||||
* **List Formatting**: Ensures proper newlines in list items.
|
||||
* **Heading Fix**: Adds missing spaces in headings (`#Heading` -> `# Heading`).
|
||||
* **Table Fix**: Adds missing closing pipes in tables.
|
||||
* **XML Cleanup**: Removes leftover XML artifacts.
|
||||
* **Details Tag Normalization**: Ensures proper spacing for `<details>` tags (used for thought chains). Adds a blank line after `</details>` and ensures a newline after self-closing `<details />` tags to prevent rendering issues.
|
||||
* **Emphasis Spacing Fix**: Fixes extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`) which can cause rendering failures. Includes safeguards to protect math expressions (e.g., `2 * 3 * 4`) and list variables.
|
||||
* **Mermaid Syntax Fix**: Automatically fixes common Mermaid syntax errors, such as unquoted node labels (including multi-line labels and citations) and unclosed subgraphs. **New in v1.1.2**: Comprehensive protection for edge labels (text on connecting lines) across all link types (solid, dotted, thick).
|
||||
* **Frontend Console Debugging**: Supports printing structured debug logs directly to the browser console (F12) for easier troubleshooting.
|
||||
* **Code Block Formatting**: Fixes broken code block prefixes, suffixes, and indentation.
|
||||
* **LaTeX Normalization**: Standardizes LaTeX formula delimiters (`\[` -> `$$`, `\(` -> `$`).
|
||||
* **Thought Tag Normalization**: Unifies thought tags (`<think>`, `<thinking>` -> `<thought>`).
|
||||
* **Escape Character Fix**: Cleans up excessive escape characters (`\\n`, `\\t`).
|
||||
* **List Formatting**: Ensures proper newlines in list items.
|
||||
* **Heading Fix**: Adds missing spaces in headings (`#Heading` -> `# Heading`).
|
||||
* **Table Fix**: Adds missing closing pipes in tables.
|
||||
* **XML Cleanup**: Removes leftover XML artifacts.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Install the plugin in Open WebUI.
|
||||
2. Enable the filter globally or for specific models.
|
||||
3. Configure the enabled fixes in the **Valves** settings.
|
||||
4. (Optional) **Show Debug Log** is enabled by default in Valves. This prints structured logs to the browser console (F12).
|
||||
1. Install the plugin in Open WebUI.
|
||||
2. Enable the filter globally or for specific models.
|
||||
3. Configure the enabled fixes in the **Valves** settings.
|
||||
4. (Optional) **Show Debug Log** is enabled by default in Valves. This prints structured logs to the browser console (F12).
|
||||
> [!WARNING]
|
||||
> As this is an initial version, some "negative fixes" might occur (e.g., breaking valid Markdown). If you encounter issues, please check the console logs, copy the "Original" vs "Normalized" content, and submit an issue.
|
||||
|
||||
## Configuration (Valves)
|
||||
|
||||
* `priority`: Filter priority (default: 50).
|
||||
* `enable_escape_fix`: Fix excessive escape characters.
|
||||
* `enable_thought_tag_fix`: Normalize thought tags.
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_details_tag_fix`: Normalize details tags (default: True).
|
||||
* `enable_details_tag_fix`: 规范化 Details 标签 (默认: True)。
|
||||
* `enable_code_block_fix`: Fix code block formatting.
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: Normalize LaTeX formulas.
|
||||
* `enable_list_fix`: Fix list item newlines (Experimental).
|
||||
* `enable_unclosed_block_fix`: Auto-close unclosed code blocks.
|
||||
* `enable_fullwidth_symbol_fix`: Fix full-width symbols in code blocks.
|
||||
* `enable_mermaid_fix`: Fix Mermaid syntax errors.
|
||||
* `enable_heading_fix`: Fix missing space in headings.
|
||||
* `enable_table_fix`: Fix missing closing pipe in tables.
|
||||
* `enable_xml_tag_cleanup`: Cleanup leftover XML tags.
|
||||
* `show_status`: Show status notification when fixes are applied.
|
||||
* `show_debug_log`: Print debug logs to browser console.
|
||||
* `priority`: Filter priority (default: 50).
|
||||
* `enable_escape_fix`: Fix excessive escape characters.
|
||||
* `enable_thought_tag_fix`: Normalize thought tags.
|
||||
* `enable_details_tag_fix`: Normalize details tags (default: True).
|
||||
* `enable_code_block_fix`: Fix code block formatting.
|
||||
* `enable_latex_fix`: Normalize LaTeX formulas.
|
||||
* `enable_list_fix`: Fix list item newlines (Experimental).
|
||||
* `enable_unclosed_block_fix`: Auto-close unclosed code blocks.
|
||||
* `enable_fullwidth_symbol_fix`: Fix full-width symbols in code blocks.
|
||||
* `enable_mermaid_fix`: Fix Mermaid syntax errors.
|
||||
* `enable_heading_fix`: Fix missing space in headings.
|
||||
* `enable_table_fix`: Fix missing closing pipe in tables.
|
||||
* `enable_xml_tag_cleanup`: Cleanup leftover XML tags.
|
||||
* `enable_emphasis_spacing_fix`: Fix extra spaces in emphasis (default: True).
|
||||
* `show_status`: Show status notification when fixes are applied.
|
||||
* `show_debug_log`: Print debug logs to browser console.
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
* **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## Changelog
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **Documentation Updates**: Synchronized version numbers across all documentation and code files.
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **List Marker Protection Enhancement**: Fixed a bug where list markers (`*`) followed by plain text and emphasis were having their spaces incorrectly stripped (e.g., `* U16 forward` became `*U16 forward`).
|
||||
* **Placeholder Support**: Confirmed that 4 or more underscores (e.g., `____`) are correctly treated as placeholders and not modified by the emphasis fix.
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **Code Block Indentation Fix**: Fixed an issue where code blocks nested inside lists were having their indentation incorrectly stripped. Now preserves proper indentation for nested code blocks.
|
||||
* **Underscore Emphasis Support**: Extended emphasis spacing fix to support `__` (double underscore for bold) and `___` (triple underscore for bold+italic) syntax.
|
||||
* **List Marker Protection**: Fixed a bug where list markers (`*`) followed by emphasis markers (`**`) were incorrectly merged (e.g., `* **Yes**` became `***Yes**`). Added safeguard to prevent this.
|
||||
* **Test Suite**: Added comprehensive pytest test suite with 56 test cases covering all major features.
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **Emphasis Spacing Fix**: Added a new fix for extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`).
|
||||
* Uses a recursive approach to handle nested emphasis (e.g., `**bold _italic _**`).
|
||||
* Includes safeguards to prevent modifying math expressions (e.g., `2 * 3 * 4`) or list variables.
|
||||
* Controlled by the `enable_emphasis_spacing_fix` valve (default: True).
|
||||
|
||||
### v1.2.0
|
||||
|
||||
* **Details Tag Support**: Added normalization for `<details>` tags.
|
||||
* Ensures a blank line is added after `</details>` closing tags to separate thought content from the main response.
|
||||
* Ensures a newline is added after self-closing `<details ... />` tags to prevent them from interfering with subsequent Markdown headings (e.g., fixing `<details/>#Heading`).
|
||||
* Includes safeguard to prevent modification of `<details>` tags inside code blocks.
|
||||
|
||||
### v1.1.2
|
||||
|
||||
* **Mermaid Edge Label Protection**: Implemented comprehensive protection for edge labels (text on connecting lines) to prevent them from being incorrectly modified. Now supports all Mermaid link types including solid (`--`), dotted (`-.`), and thick (`==`) lines with or without arrows.
|
||||
* **Bug Fixes**: Fixed an issue where lines without arrows (e.g., `A -- text --- B`) were not correctly protected.
|
||||
|
||||
### v1.1.0
|
||||
|
||||
* **Mermaid Fix Refinement**: Improved regex to handle nested parentheses in node labels (e.g., `ID("Label (text)")`) and avoided matching connection labels.
|
||||
* **HTML Safeguard Optimization**: Refined `_contains_html` to allow common tags like `<br/>`, `<b>`, `<i>`, etc., ensuring Mermaid diagrams with these tags are still normalized.
|
||||
* **Full-width Symbol Cleanup**: Fixed duplicate keys and incorrect quote mapping in `FULLWIDTH_MAP`.
|
||||
* **Bug Fixes**: Fixed missing `Dict` import in Python files.
|
||||
|
||||
## License
|
||||
|
||||
|
||||
@@ -1,45 +1,97 @@
|
||||
# Markdown 格式化过滤器 (Markdown Normalizer)
|
||||
|
||||
这是一个用于 Open WebUI 的生产级内容格式化过滤器,旨在修复 LLM 输出中常见的 Markdown 格式问题。它能确保代码块、LaTeX 公式、Mermaid 图表和其他 Markdown 元素被正确渲染。
|
||||
这是一个用于 Open WebUI 的内容格式化过滤器,旨在修复 LLM 输出中常见的 Markdown 格式问题。它能确保代码块、LaTeX 公式、Mermaid 图表和其他 Markdown 元素被正确渲染。
|
||||
|
||||
## 功能特性
|
||||
|
||||
* **Mermaid 语法修复**: 自动修复常见的 Mermaid 语法错误,如未加引号的节点标签(支持多行标签和引用标记)和未闭合的子图 (Subgraph),确保图表能正确渲染。
|
||||
* **前端控制台调试**: 支持将结构化的调试日志直接打印到浏览器控制台 (F12),方便排查问题。
|
||||
* **代码块格式化**: 修复破损的代码块前缀、后缀和缩进问题。
|
||||
* **LaTeX 规范化**: 标准化 LaTeX 公式定界符 (`\[` -> `$$`, `\(` -> `$`)。
|
||||
* **思维标签规范化**: 统一思维链标签 (`<think>`, `<thinking>` -> `<thought>`)。
|
||||
* **转义字符修复**: 清理过度的转义字符 (`\\n`, `\\t`)。
|
||||
* **列表格式化**: 确保列表项有正确的换行。
|
||||
* **标题修复**: 修复标题中缺失的空格 (`#标题` -> `# 标题`)。
|
||||
* **表格修复**: 修复表格中缺失的闭合管道符。
|
||||
* **XML 清理**: 移除残留的 XML 标签。
|
||||
* **Details 标签规范化**: 确保 `<details>` 标签(常用于思维链)有正确的间距。在 `</details>` 后添加空行,并在自闭合 `<details />` 标签后添加换行,防止渲染问题。
|
||||
* **强调空格修复**: 修复强调标记内部的多余空格(例如 `** 文本 **` -> `**文本**`),这会导致 Markdown 渲染失败。包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* **Mermaid 语法修复**: 自动修复常见的 Mermaid 语法错误,如未加引号的节点标签(支持多行标签和引用标记)和未闭合的子图 (Subgraph)。**v1.1.2 新增**: 全面保护各种类型的连线标签(实线、虚线、粗线),防止被误修改。
|
||||
* **前端控制台调试**: 支持将结构化的调试日志直接打印到浏览器控制台 (F12),方便排查问题。
|
||||
* **代码块格式化**: 修复破损的代码块前缀、后缀和缩进问题。
|
||||
* **LaTeX 规范化**: 标准化 LaTeX 公式定界符 (`\[` -> `$$`, `\(` -> `$`)。
|
||||
* **思维标签规范化**: 统一思维链标签 (`<think>`, `<thinking>` -> `<thought>`)。
|
||||
* **转义字符修复**: 清理过度的转义字符 (`\\n`, `\\t`)。
|
||||
* **列表格式化**: 确保列表项有正确的换行。
|
||||
* **标题修复**: 修复标题中缺失的空格 (`#标题` -> `# 标题`)。
|
||||
* **表格修复**: 修复表格中缺失的闭合管道符。
|
||||
* **XML 清理**: 移除残留的 XML 标签。
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在 Open WebUI 中安装此插件。
|
||||
2. 全局启用或为特定模型启用此过滤器。
|
||||
3. 在 **Valves** 设置中配置需要启用的修复项。
|
||||
4. (可选) **显示调试日志 (Show Debug Log)** 在 Valves 中默认开启。这会将结构化的日志打印到浏览器控制台 (F12)。
|
||||
1. 在 Open WebUI 中安装此插件。
|
||||
2. 全局启用或为特定模型启用此过滤器。
|
||||
3. 在 **Valves** 设置中配置需要启用的修复项。
|
||||
4. (可选) **显示调试日志 (Show Debug Log)** 在 Valves 中默认开启。这会将结构化的日志打印到浏览器控制台 (F12)。
|
||||
> [!WARNING]
|
||||
> 由于这是初版,可能会出现“负向修复”的情况(例如破坏了原本正确的格式)。如果您遇到问题,请务必查看控制台日志,复制“原始 (Original)”与“规范化 (Normalized)”的内容对比,并提交 Issue 反馈。
|
||||
|
||||
## 配置项 (Valves)
|
||||
|
||||
* `priority`: 过滤器优先级 (默认: 50)。
|
||||
* `enable_escape_fix`: 修复过度的转义字符。
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: 规范化 LaTeX 公式。
|
||||
* `enable_list_fix`: 修复列表项换行 (实验性)。
|
||||
* `enable_unclosed_block_fix`: 自动闭合未闭合的代码块。
|
||||
* `enable_fullwidth_symbol_fix`: 修复代码块中的全角符号。
|
||||
* `enable_mermaid_fix`: 修复 Mermaid 语法错误。
|
||||
* `enable_heading_fix`: 修复标题中缺失的空格。
|
||||
* `enable_table_fix`: 修复表格中缺失的闭合管道符。
|
||||
* `enable_xml_tag_cleanup`: 清理残留的 XML 标签。
|
||||
* `show_status`: 应用修复时显示状态通知。
|
||||
* `show_debug_log`: 在浏览器控制台打印调试日志。
|
||||
* `priority`: 过滤器优先级 (默认: 50)。
|
||||
* `enable_escape_fix`: 修复过度的转义字符。
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_details_tag_fix`: 规范化 Details 标签 (默认: True)。
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: 规范化 LaTeX 公式。
|
||||
* `enable_list_fix`: 修复列表项换行 (实验性)。
|
||||
* `enable_unclosed_block_fix`: 自动闭合未闭合的代码块。
|
||||
* `enable_fullwidth_symbol_fix`: 修复代码块中的全角符号。
|
||||
* `enable_mermaid_fix`: 修复 Mermaid 语法错误。
|
||||
* `enable_heading_fix`: 修复标题中缺失的空格。
|
||||
* `enable_table_fix`: 修复表格中缺失的闭合管道符。
|
||||
* `enable_xml_tag_cleanup`: 清理残留的 XML 标签。
|
||||
* `enable_emphasis_spacing_fix`: 修复强调语法中的多余空格 (默认: True)。
|
||||
* `show_status`: 应用修复时显示状态通知。
|
||||
* `show_debug_log`: 在浏览器控制台打印调试日志。
|
||||
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
* **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## 更新日志
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **文档更新**: 同步了所有文档和代码文件的版本号。
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **列表标记保护增强**: 修复了列表标记 (`*`) 后跟普通文本和强调标记时,空格被错误剥离的问题(例如 `* U16 前锋` 变成 `*U16 前锋`)。
|
||||
* **占位符支持**: 确认 4 个或更多下划线(如 `____`)会被正确视为占位符,不会被强调修复逻辑修改。
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **代码块缩进修复**: 修复了列表中嵌套代码块的缩进被错误剥离的问题。现在会正确保留嵌套代码块的缩进。
|
||||
* **下划线强调语法支持**: 扩展强调空格修复以支持 `__` (双下划线加粗) 和 `___` (三下划线加粗斜体) 语法。
|
||||
* **列表标记保护**: 修复了列表标记 (`*`) 后跟强调标记 (`**`) 被错误合并的 Bug(例如 `* **是**` 变成 `***是**`)。添加了保护逻辑防止此问题。
|
||||
* **测试套件**: 新增完整的 pytest 测试套件,包含 56 个测试用例,覆盖所有主要功能。
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **强调空格修复**: 新增了对强调标记内部多余空格的修复(例如 `** 文本 **` -> `**文本**`)。
|
||||
* 采用递归方法处理嵌套强调(例如 `**加粗 _斜体 _**`)。
|
||||
* 包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* 通过 `enable_emphasis_spacing_fix` 开关控制(默认:开启)。
|
||||
|
||||
### v1.2.0
|
||||
|
||||
* **Details 标签支持**: 新增了对 `<details>` 标签的规范化支持。
|
||||
* 确保在 `</details>` 闭合标签后添加空行,将思维内容与正文分隔开。
|
||||
* 确保在自闭合 `<details ... />` 标签后添加换行,防止其干扰后续的 Markdown 标题(例如修复 `<details/>#标题`)。
|
||||
* 包含保护机制,防止修改代码块内部的 `<details>` 标签。
|
||||
|
||||
### v1.1.2
|
||||
|
||||
* **Mermaid 连线标签保护**: 实现了全面的连线标签保护机制,防止连接线上的文字被误修改。现在支持所有 Mermaid 连线类型,包括实线 (`--`)、虚线 (`-.`) 和粗线 (`==`),无论是否带有箭头。
|
||||
* **Bug 修复**: 修复了无箭头连线(如 `A -- text --- B`)未被正确保护的问题。
|
||||
|
||||
### v1.1.0
|
||||
|
||||
* **Mermaid 修复优化**: 改进了正则表达式以处理节点标签中的嵌套括号(如 `ID("标签 (文本)")`),并避免误匹配连接线上的文字。
|
||||
* **HTML 保护机制优化**: 优化了 `_contains_html` 检测,允许 `<br/>`, `<b>`, `<i>` 等常见标签,确保包含这些标签的 Mermaid 图表能被正常规范化。
|
||||
* **全角符号清理**: 修复了 `FULLWIDTH_MAP` 中的重复键名和错误的引号映射。
|
||||
* **Bug 修复**: 修复了 Python 文件中缺失的 `Dict` 类型导入。
|
||||
|
||||
## 许可证
|
||||
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 162 KiB After Width: | Height: | Size: 234 KiB |
@@ -1,26 +1,34 @@
|
||||
# Async Context Compression Filter
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.1.3 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.2.2 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
This filter reduces token consumption in long conversations through intelligent summarization and message compression while keeping conversations coherent.
|
||||
|
||||
## What's new in 1.2.2
|
||||
- **Critical Fix**: Resolved `TypeError: 'str' object is not callable` caused by variable name conflict in logging function.
|
||||
- **Compatibility**: Enhanced `params` handling to support Pydantic objects, improving compatibility with different OpenWebUI versions.
|
||||
|
||||
## What's new in 1.2.1
|
||||
|
||||
- **Smart Configuration**: Automatically detects base model settings for custom models and adds `summary_model_max_context` for independent summary limits.
|
||||
- **Performance & Refactoring**: Optimized threshold parsing with caching, removed redundant code, and improved LLM response handling (JSONResponse support).
|
||||
- **Bug Fixes & Modernization**: Fixed `datetime` deprecation warnings, corrected type annotations, and replaced print statements with proper logging.
|
||||
|
||||
## What's new in 1.2.0
|
||||
|
||||
- **Preflight Context Check**: Before sending to the model, validates that total tokens fit within the context window. Automatically trims or drops oldest messages if exceeded.
|
||||
- **Structure-Aware Assistant Trimming**: When context exceeds the limit, long AI responses are intelligently collapsed while preserving their structure (headers H1-H6, first line, last line).
|
||||
- **Native Tool Output Trimming**: Detects and trims native tool outputs (`function_calling: "native"`), extracting only the final answer. Enable via `enable_tool_output_trimming`. **Note**: Non-native tool outputs are not fully injected into context.
|
||||
- **Consolidated Status Notifications**: Unified "Context Usage" and "Context Summary Updated" notifications with appended warnings (e.g., `| ⚠️ High Usage`) for clearer feedback.
|
||||
- **Context Usage Warning**: Emits a warning notification when context usage exceeds 90%.
|
||||
- **Enhanced Header Detection**: Optimized regex (`^#{1,6}\s+`) to avoid false positives like `#hashtag`.
|
||||
- **Detailed Token Logging**: Logs now show token breakdown for System, Head, Summary, and Tail sections with total.
|
||||
|
||||
## What's new in 1.1.3
|
||||
- **Improved Compatibility**: Changed summary injection role from `user` to `assistant` for better compatibility across different LLMs.
|
||||
- **Enhanced Stability**: Fixed a race condition in state management that could cause "inlet state not found" warnings in high-concurrency scenarios.
|
||||
- **Bug Fixes**: Corrected default model handling to prevent misleading logs when no model is specified.
|
||||
|
||||
## What's new in 1.1.2
|
||||
|
||||
- **Open WebUI v0.7.x Compatibility**: Resolved a critical database session binding error affecting Open WebUI v0.7.x users. The plugin now dynamically discovers the database engine and session context, ensuring compatibility across versions.
|
||||
- **Enhanced Error Reporting**: Errors during background summary generation are now reported via both the status bar and browser console.
|
||||
- **Robust Model Handling**: Improved handling of missing or invalid model IDs to prevent crashes.
|
||||
|
||||
## What's new in 1.1.1
|
||||
|
||||
- **Frontend Debugging**: Added `show_debug_log` option to print debug info to the browser console (F12).
|
||||
- **Optimized Compression**: Improved token calculation logic to prevent aggressive truncation of history, ensuring more context is retained.
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
@@ -31,6 +39,12 @@ This filter reduces token consumption in long conversations through intelligent
|
||||
- ✅ Persistent storage via Open WebUI's shared database connection (PostgreSQL, SQLite, etc.).
|
||||
- ✅ Flexible retention policy to keep the first and last N messages.
|
||||
- ✅ Smart injection of historical summaries back into the context.
|
||||
- ✅ Structure-aware trimming that preserves document structure (headers, intro, conclusion).
|
||||
- ✅ Native tool output trimming for cleaner context when using function calling.
|
||||
- ✅ Real-time context usage monitoring with warning notifications (>90%).
|
||||
- ✅ Detailed token logging for precise debugging and optimization.
|
||||
- ✅ **Smart Model Matching**: Automatically inherits configuration from base models for custom presets.
|
||||
- ⚠ **Multimodal Support**: Images are preserved but their tokens are **NOT** calculated. Please adjust thresholds accordingly.
|
||||
|
||||
---
|
||||
|
||||
@@ -61,9 +75,11 @@ It is recommended to keep this filter early in the chain so it runs before filte
|
||||
| `keep_first` | `1` | Always keep the first N messages (protects system prompts). |
|
||||
| `keep_last` | `6` | Always keep the last N messages to preserve recent context. |
|
||||
| `summary_model` | `None` | Model for summaries. Strongly recommended to set a fast, economical model (e.g., `gemini-2.5-flash`, `deepseek-v3`). Falls back to the current chat model when empty. |
|
||||
| `max_summary_tokens` | `4000` | Maximum tokens for the generated summary. |
|
||||
| `summary_model_max_context` | `0` | Max context tokens for the summary model. If 0, falls back to `model_thresholds` or global `max_context_tokens`. |
|
||||
| `max_summary_tokens` | `16384` | Maximum tokens for the generated summary. |
|
||||
| `summary_temperature` | `0.3` | Randomness for summary generation. Lower is more deterministic. |
|
||||
| `model_thresholds` | `{}` | Per-model overrides for `compression_threshold_tokens` and `max_context_tokens` (useful for mixed models). |
|
||||
| `enable_tool_output_trimming` | `false` | When enabled and `function_calling: "native"` is active, trims verbose tool outputs to extract only the final answer. |
|
||||
| `debug_mode` | `true` | Log verbose debug info. Set to `false` in production. |
|
||||
| `show_debug_log` | `false` | Print debug logs to browser console (F12). Useful for frontend debugging. |
|
||||
|
||||
|
||||
@@ -1,28 +1,36 @@
|
||||
# 异步上下文压缩过滤器
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.1.3 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.2.2 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
> **重要提示**:为了确保所有过滤器的可维护性和易用性,每个过滤器都应附带清晰、完整的文档,以确保其功能、配置和使用方法得到充分说明。
|
||||
|
||||
本过滤器通过智能摘要和消息压缩技术,在保持对话连贯性的同时,显著降低长对话的 Token 消耗。
|
||||
|
||||
## 1.2.2 版本更新
|
||||
- **严重错误修复**: 解决了因日志函数变量名冲突导致的 `TypeError: 'str' object is not callable` 错误。
|
||||
- **兼容性增强**: 改进了 `params` 处理逻辑以支持 Pydantic 对象,提高了对不同 OpenWebUI 版本的兼容性。
|
||||
|
||||
## 1.2.1 版本更新
|
||||
|
||||
- **智能配置增强**: 自动检测自定义模型的基础模型配置,并新增 `summary_model_max_context` 参数以独立控制摘要模型的上下文限制。
|
||||
- **性能优化与重构**: 重构了阈值解析逻辑并增加缓存,移除了冗余的处理代码,并增强了 LLM 响应处理(支持 JSONResponse)。
|
||||
- **稳定性改进**: 修复了 `datetime` 弃用警告,修正了类型注解,并将 print 语句替换为标准日志记录。
|
||||
|
||||
## 1.2.0 版本更新
|
||||
|
||||
- **预检上下文检查 (Preflight Context Check)**: 在发送给模型之前,验证总 Token 是否符合上下文窗口。如果超出,自动裁剪或丢弃最旧的消息。
|
||||
- **结构感知助手裁剪 (Structure-Aware Assistant Trimming)**: 当上下文超出限制时,智能折叠过长的 AI 回复,同时保留其结构(标题 H1-H6、首行、尾行)。
|
||||
- **原生工具输出裁剪 (Native Tool Output Trimming)**: 检测并裁剪原生工具输出 (`function_calling: "native"`),仅提取最终答案。通过 `enable_tool_output_trimming` 启用。**注意**:非原生工具调用输出不会完整注入上下文。
|
||||
- **统一状态通知**: 统一了“上下文使用情况”和“上下文摘要更新”的通知,并附加警告(例如 `| ⚠️ 高负载`),反馈更清晰。
|
||||
- **上下文使用警告**: 当上下文使用率超过 90% 时发出警告通知。
|
||||
- **增强的标题检测**: 优化了正则表达式 (`^#{1,6}\s+`) 以避免误判(如 `#hashtag`)。
|
||||
- **详细 Token 日志**: 日志现在显示 System、Head、Summary 和 Tail 部分的 Token 细分及总计。
|
||||
|
||||
## 1.1.3 版本更新
|
||||
- **兼容性提升**: 将摘要注入角色从 `user` 改为 `assistant`,以提高在不同 LLM 之间的兼容性。
|
||||
- **稳定性增强**: 修复了状态管理中的竞态条件,解决了高并发场景下可能出现的“无法获取 inlet 状态”警告。
|
||||
- **Bug 修复**: 修正了默认模型处理逻辑,防止在未指定模型时产生误导性日志。
|
||||
|
||||
## 1.1.2 版本更新
|
||||
|
||||
- **Open WebUI v0.7.x 兼容性**: 修复了影响 Open WebUI v0.7.x 用户的严重数据库会话绑定错误。插件现在动态发现数据库引擎和会话上下文,确保跨版本兼容性。
|
||||
- **增强错误报告**: 后台摘要生成过程中的错误现在会通过状态栏和浏览器控制台同时报告。
|
||||
- **健壮的模型处理**: 改进了对缺失或无效模型 ID 的处理,防止程序崩溃。
|
||||
|
||||
## 1.1.1 版本更新
|
||||
|
||||
- **前端调试**: 新增 `show_debug_log` 选项,支持在浏览器控制台 (F12) 打印调试信息。
|
||||
- **压缩优化**: 优化 Token 计算逻辑,防止历史记录被过度截断,保留更多上下文。
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
@@ -33,6 +41,12 @@
|
||||
- ✅ **持久化存储**: 复用 Open WebUI 共享数据库连接,自动支持 PostgreSQL/SQLite 等。
|
||||
- ✅ **灵活保留策略**: 可配置保留对话头部和尾部消息,确保关键信息连贯。
|
||||
- ✅ **智能注入**: 将历史摘要智能注入到新上下文中。
|
||||
- ✅ **结构感知裁剪**: 智能折叠过长消息,保留文档骨架(标题、首尾)。
|
||||
- ✅ **原生工具输出裁剪**: 支持裁剪冗长的工具调用输出。
|
||||
- ✅ **实时监控**: 实时监控上下文使用情况,超过 90% 发出警告。
|
||||
- ✅ **详细日志**: 提供精确的 Token 统计日志,便于调试。
|
||||
- ✅ **智能模型匹配**: 自定义模型自动继承基础模型的阈值配置。
|
||||
- ⚠ **多模态支持**: 图片内容会被保留,但其 Token **不参与计算**。请相应调整阈值。
|
||||
|
||||
详细的工作原理和流程请参考 [工作流程指南](WORKFLOW_GUIDE_CN.md)。
|
||||
|
||||
@@ -74,6 +88,7 @@
|
||||
| 参数 | 默认值 | 描述 |
|
||||
| :-------------------- | :------ | :------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| `summary_model` | `None` | 用于生成摘要的模型 ID。**强烈建议**配置快速、经济、上下文窗口大的模型(如 `gemini-2.5-flash`、`deepseek-v3`)。留空则尝试复用当前对话模型。 |
|
||||
| `summary_model_max_context` | `0` | 摘要模型的最大上下文 Token 数。如果为 0,则回退到 `model_thresholds` 或全局 `max_context_tokens`。 |
|
||||
| `max_summary_tokens` | `16384` | 生成摘要时允许的最大 Token 数。 |
|
||||
| `summary_temperature` | `0.1` | 控制摘要生成的随机性,较低的值结果更稳定。 |
|
||||
|
||||
@@ -100,15 +115,12 @@
|
||||
}
|
||||
```
|
||||
|
||||
#### `debug_mode`
|
||||
|
||||
- **默认值**: `true`
|
||||
- **描述**: 是否在 Open WebUI 的控制台日志中打印详细的调试信息(如 Token 计数、压缩进度、数据库操作等)。生产环境建议设为 `false`。
|
||||
|
||||
#### `show_debug_log`
|
||||
|
||||
- **默认值**: `false`
|
||||
- **描述**: 是否在浏览器控制台 (F12) 打印调试日志。便于前端调试。
|
||||
| 参数 | 默认值 | 描述 |
|
||||
| :----------------------------- | :------- | :-------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enable_tool_output_trimming` | `false` | 启用时,若 `function_calling: "native"` 激活,将裁剪冗长的工具输出以仅提取最终答案。 |
|
||||
| `debug_mode` | `true` | 是否在 Open WebUI 的控制台日志中打印详细的调试信息(如 Token 计数、压缩进度、数据库操作等)。生产环境建议设为 `false`。 |
|
||||
| `show_debug_log` | `false` | 是否在浏览器控制台 (F12) 打印调试日志。便于前端调试。 |
|
||||
| `show_token_usage_status` | `true` | 是否在对话结束时显示 Token 使用情况的状态通知。 |
|
||||
|
||||
---
|
||||
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
60
plugins/filters/folder-memory/README.md
Normal file
60
plugins/filters/folder-memory/README.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# Folder Memory
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 What's new in 0.1.0
|
||||
- **Initial Release**: Automated "Project Rules" management for OpenWebUI folders.
|
||||
- **Folder-Level Persistence**: Automatically updates folder system prompts with extracted rules.
|
||||
- **Optimized Performance**: Runs asynchronously and supports `PRIORITY` configuration for seamless integration with other filters.
|
||||
|
||||
---
|
||||
|
||||
**Folder Memory** is an intelligent context filter plugin for OpenWebUI. It automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||
|
||||
## ✨ Features
|
||||
|
||||
- **Automatic Extraction**: Analyzes chat history every N messages to extract project rules.
|
||||
- **Non-destructive Injection**: Updates only the specific "Project Rules" block in the system prompt, preserving other instructions.
|
||||
- **Async Processing**: Runs in the background without blocking the user's chat experience.
|
||||
- **ORM Integration**: Directly updates folder data using OpenWebUI's internal models for reliability.
|
||||
|
||||
## ⚠️ Prerequisites
|
||||
|
||||
- **Conversations must occur inside a folder.** This plugin only triggers when a chat belongs to a folder (i.e., you need to create a folder in OpenWebUI and start a conversation within it).
|
||||
|
||||
## 📦 Installation
|
||||
|
||||
1. Copy `folder_memory.py` to your OpenWebUI `plugins/filters/` directory (or upload via Admin UI).
|
||||
2. Enable the filter in your **Settings** -> **Filters**.
|
||||
3. (Optional) Configure the triggering threshold (default: every 10 messages).
|
||||
|
||||
## ⚙️ Configuration (Valves)
|
||||
|
||||
| Valve | Default | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | Priority level for the filter operations. |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | The number of messages required to trigger a rule analysis. |
|
||||
| `MODEL_ID` | `""` | The model used to generate rules. If empty, uses the current chat model. |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 Project Rules` | The title displayed above the injected rules block. |
|
||||
| `SHOW_DEBUG_LOG` | `False` | Show detailed debug logs in the browser console. |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | If enabled, finds and updates the root folder rules instead of the current subfolder. |
|
||||
|
||||
## 🛠️ How It Works
|
||||
|
||||

|
||||
|
||||
1. **Trigger**: When a conversation reaches `MESSAGE_TRIGGER_COUNT` (e.g., 10, 20 messages).
|
||||
2. **Analysis**: The plugin sends the recent conversation + existing rules to the LLM.
|
||||
3. **Synthesis**: The LLM merges new insights with old rules, removing obsolete ones.
|
||||
4. **Update**: The new rule set replaces the `<!-- OWUI_PROJECT_RULES_START -->` block in the folder's system prompt.
|
||||
|
||||
## ⚠️ Notes
|
||||
|
||||
- This plugin modifies the `system_prompt` of your folders.
|
||||
- It uses a specific marker `<!-- OWUI_PROJECT_RULES_START -->` to locate its content. Do not manually remove these markers if you want the plugin to continue managing that section.
|
||||
|
||||
## 🗺️ Roadmap
|
||||
|
||||
See [ROADMAP.md](./ROADMAP.md) for future plans, including "Project Knowledge" collection.
|
||||
62
plugins/filters/folder-memory/README_CN.md
Normal file
62
plugins/filters/folder-memory/README_CN.md
Normal file
@@ -0,0 +1,62 @@
|
||||
# 文件夹记忆 (Folder Memory)
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
---
|
||||
|
||||
### 📌 0.1.0 版本特性
|
||||
- **首个版本发布**:专注于自动化的“项目规则”管理。
|
||||
- **文件夹级持久化**:自动将提取的规则回写到文件夹系统提示词中。
|
||||
- **性能优化**:采用异步处理机制,并支持 `PRIORITY` 配置,确保与其他过滤器(如上下文压缩)完美协作。
|
||||
|
||||
---
|
||||
|
||||
**文件夹记忆 (Folder Memory)** 是一个 OpenWebUI 的智能上下文过滤器插件。它能自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||
|
||||
这确保了该文件夹内的所有未来对话都能共享相同的进化上下文和规则,无需手动更新。
|
||||
|
||||
## ✨ 功能特性
|
||||
|
||||
- **自动提取**:每隔 N 条消息分析一次聊天记录,提取项目规则。
|
||||
- **无损注入**:仅更新系统提示词中的特定“项目规则”块,保留其他指令。
|
||||
- **异步处理**:在后台运行,不阻塞用户的聊天体验。
|
||||
- **ORM 集成**:直接使用 OpenWebUI 的内部模型更新文件夹数据,确保可靠性。
|
||||
|
||||
## ⚠️ 前置条件
|
||||
|
||||
- **对话必须在文件夹内进行。** 此插件仅在聊天属于某个文件夹时触发(即您需要先在 OpenWebUI 中创建一个文件夹,并在其内部开始对话)。
|
||||
|
||||
## 📦 安装指南
|
||||
|
||||
1. 将 `folder_memory.py` (或中文版 `folder_memory_cn.py`) 复制到 OpenWebUI 的 `plugins/filters/` 目录(或通过管理员 UI 上传)。
|
||||
2. 在 **设置** -> **过滤器** 中启用该插件。
|
||||
3. (可选)配置触发阈值(默认:每 10 条消息)。
|
||||
|
||||
## ⚙️ 配置 (Valves)
|
||||
|
||||
| 参数 | 默认值 | 说明 |
|
||||
| :--- | :--- | :--- |
|
||||
| `PRIORITY` | `20` | 过滤器操作的优先级。 |
|
||||
| `MESSAGE_TRIGGER_COUNT` | `10` | 触发规则分析的消息数量阈值。 |
|
||||
| `MODEL_ID` | `""` | 用于生成规则的模型 ID。若为空,则使用当前对话模型。 |
|
||||
| `RULES_BLOCK_TITLE` | `## 📂 项目规则` | 显示在注入规则块上方的标题。 |
|
||||
| `SHOW_DEBUG_LOG` | `False` | 在浏览器控制台显示详细调试日志。 |
|
||||
| `UPDATE_ROOT_FOLDER` | `False` | 如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。 |
|
||||
|
||||
## 🛠️ 工作原理
|
||||
|
||||

|
||||
|
||||
1. **触发**:当对话达到 `MESSAGE_TRIGGER_COUNT`(例如 10、20 条消息)时。
|
||||
2. **分析**:插件将最近的对话 + 现有规则发送给 LLM。
|
||||
3. **综合**:LLM 将新见解与旧规则合并,移除过时的规则。
|
||||
4. **更新**:新的规则集替换文件夹系统提示词中的 `<!-- OWUI_PROJECT_RULES_START -->` 块。
|
||||
|
||||
## ⚠️ 注意事项
|
||||
|
||||
- 此插件会修改文件夹的 `system_prompt`。
|
||||
- 它使用特定标记 `<!-- OWUI_PROJECT_RULES_START -->` 来定位内容。如果您希望插件继续管理该部分,请勿手动删除这些标记。
|
||||
|
||||
## 🗺️ 路线图
|
||||
|
||||
查看 [ROADMAP.md](./ROADMAP.md) 了解未来计划,包括“项目知识”收集功能。
|
||||
10
plugins/filters/folder-memory/ROADMAP.md
Normal file
10
plugins/filters/folder-memory/ROADMAP.md
Normal file
@@ -0,0 +1,10 @@
|
||||
# Roadmap
|
||||
|
||||
## Future Features
|
||||
|
||||
### 🧠 Project Knowledge (Planned)
|
||||
In future versions, we plan to introduce "Project Knowledge" collection. Unlike "Rules" which are strict instructions, "Knowledge" will capture reusable information, consensus, and context that helps the LLM understand the project better.
|
||||
|
||||
- **Knowledge Extraction**: Automatically extract reusable knowledge (terminology, style guides, business logic) from conversations.
|
||||
- **Long-term Memory**: Use the entire folder's chat history as a corpus for knowledge generation.
|
||||
- **Context Injection**: Inject summarized knowledge into the system prompt alongside rules.
|
||||
BIN
plugins/filters/folder-memory/folder-memory-demo.png
Normal file
BIN
plugins/filters/folder-memory/folder-memory-demo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 459 KiB |
483
plugins/filters/folder-memory/folder_memory.py
Normal file
483
plugins/filters/folder-memory/folder_memory.py
Normal file
@@ -0,0 +1,483 @@
|
||||
"""
|
||||
title: 📂 Folder Memory
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 0.1.0
|
||||
description: Automatically extracts project rules from conversations and injects them into the folder's system prompt.
|
||||
requirements:
|
||||
"""
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from typing import Optional, Dict, List
|
||||
from fastapi import Request
|
||||
import logging
|
||||
import json
|
||||
import re
|
||||
import asyncio
|
||||
from datetime import datetime
|
||||
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from open_webui.models.users import Users
|
||||
from open_webui.models.folders import Folders, FolderUpdateForm
|
||||
from open_webui.models.chats import Chats
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Markers for rule injection
|
||||
RULES_BLOCK_START = "<!-- OWUI_PROJECT_RULES_START -->"
|
||||
RULES_BLOCK_END = "<!-- OWUI_PROJECT_RULES_END -->"
|
||||
|
||||
# System Prompt for Rule Generation
|
||||
SYSTEM_PROMPT_RULE_GENERATOR = """
|
||||
You are a project rule extractor. Your task is to extract "Project Rules" from the conversation and merge them with existing rules.
|
||||
|
||||
### Input
|
||||
1. **Existing Rules**: Current rules in the folder system prompt.
|
||||
2. **Conversation**: Recent chat history.
|
||||
|
||||
### Goal
|
||||
Synthesize a concise list of rules that apply to this project/folder.
|
||||
- **Remove** rules that are no longer relevant or were one-off instructions.
|
||||
- **Add** new consistent requirements found in the conversation.
|
||||
- **Merge** similar rules.
|
||||
- **Format**: Concise bullet points (Markdown).
|
||||
|
||||
### Output Format
|
||||
ONLY output the rules list as Markdown bullet points. Do not include any intro/outro text.
|
||||
Example:
|
||||
- Always use Python 3.11 for type hinting.
|
||||
- Docstrings must follow Google style.
|
||||
- Commit messages should be in English.
|
||||
"""
|
||||
|
||||
|
||||
class Filter:
|
||||
class Valves(BaseModel):
|
||||
PRIORITY: int = Field(
|
||||
default=20, description="Priority level for the filter operations."
|
||||
)
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False, description="Show debug logs in console."
|
||||
)
|
||||
MESSAGE_TRIGGER_COUNT: int = Field(
|
||||
default=10, description="Analyze rules after every N messages in a chat."
|
||||
)
|
||||
MODEL_ID: str = Field(
|
||||
default="",
|
||||
description="Model used for rule extraction. If empty, uses the current chat model.",
|
||||
)
|
||||
RULES_BLOCK_TITLE: str = Field(
|
||||
default="## 📂 Project Rules",
|
||||
description="Title displayed above the rules block.",
|
||||
)
|
||||
UPDATE_ROOT_FOLDER: bool = Field(
|
||||
default=False,
|
||||
description="If enabled, finds and updates the root folder rules instead of the current subfolder.",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
|
||||
# ==================== Helper Methods ====================
|
||||
|
||||
def _get_user_context(self, __user__: Optional[dict]) -> Dict[str, str]:
|
||||
"""Safely extracts user context information."""
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_data = __user__[0] if __user__ else {}
|
||||
elif isinstance(__user__, dict):
|
||||
user_data = __user__
|
||||
else:
|
||||
user_data = {}
|
||||
|
||||
return {
|
||||
"user_id": user_data.get("id", ""),
|
||||
"user_name": user_data.get("name", "User"),
|
||||
"user_language": user_data.get("language", "en-US"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""Unified extraction of chat context information (chat_id, message_id)."""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "")
|
||||
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
async def _emit_debug_log(self, __event_emitter__, title: str, data: dict):
|
||||
if self.valves.SHOW_DEBUG_LOG and __event_emitter__:
|
||||
try:
|
||||
# Flat log format as requested
|
||||
js_code = f"""
|
||||
console.log("[Folder Memory] {title}", {json.dumps(data, ensure_ascii=False)});
|
||||
"""
|
||||
await __event_emitter__({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
logger.error(f"Error emitting log: {e}")
|
||||
|
||||
async def _emit_status(
|
||||
self, __event_emitter__, description: str, done: bool = False
|
||||
):
|
||||
if __event_emitter__:
|
||||
await __event_emitter__(
|
||||
{"type": "status", "data": {"description": description, "done": done}}
|
||||
)
|
||||
|
||||
def _get_folder_id(self, body: dict) -> Optional[str]:
|
||||
# 1. Try retrieving folder_id specifically from metadata
|
||||
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||
if "folder_id" in body["metadata"]:
|
||||
return body["metadata"]["folder_id"]
|
||||
|
||||
# 2. Check regular body chat object if available
|
||||
if "chat" in body and isinstance(body["chat"], dict):
|
||||
if "folder_id" in body["chat"]:
|
||||
return body["chat"]["folder_id"]
|
||||
|
||||
# 3. Try fallback via Chat ID (Most reliable)
|
||||
chat_id = body.get("chat_id")
|
||||
if not chat_id:
|
||||
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||
chat_id = body["metadata"].get("chat_id")
|
||||
|
||||
if chat_id:
|
||||
try:
|
||||
chat = Chats.get_chat_by_id(chat_id)
|
||||
if chat and chat.folder_id:
|
||||
return chat.folder_id
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to fetch chat {chat_id}: {e}")
|
||||
|
||||
return None
|
||||
|
||||
def _extract_existing_rules(self, system_prompt: str) -> str:
|
||||
pattern = re.compile(
|
||||
re.escape(RULES_BLOCK_START) + r"([\s\S]*?)" + re.escape(RULES_BLOCK_END)
|
||||
)
|
||||
match = pattern.search(system_prompt)
|
||||
if match:
|
||||
# Remove title if it's inside the block
|
||||
content = match.group(1).strip()
|
||||
# Simple cleanup of the title if user formatted it inside
|
||||
title_pat = re.compile(r"^#+\s+.*$", re.MULTILINE)
|
||||
return title_pat.sub("", content).strip()
|
||||
return ""
|
||||
|
||||
def _inject_rules(self, system_prompt: str, new_rules: str, title: str) -> str:
|
||||
new_block_content = f"\n{title}\n\n{new_rules}\n"
|
||||
new_block = f"{RULES_BLOCK_START}{new_block_content}{RULES_BLOCK_END}"
|
||||
|
||||
system_prompt = system_prompt or ""
|
||||
pattern = re.compile(
|
||||
re.escape(RULES_BLOCK_START) + r"[\s\S]*?" + re.escape(RULES_BLOCK_END)
|
||||
)
|
||||
|
||||
if pattern.search(system_prompt):
|
||||
return pattern.sub(new_block, system_prompt).strip()
|
||||
else:
|
||||
# Append if not found
|
||||
if system_prompt:
|
||||
return f"{system_prompt}\n\n{new_block}"
|
||||
else:
|
||||
return new_block
|
||||
|
||||
async def _generate_new_rules(
|
||||
self,
|
||||
current_rules: str,
|
||||
messages: List[Dict],
|
||||
user_id: str,
|
||||
__request__: Request,
|
||||
) -> str:
|
||||
# Prepare context
|
||||
conversation_text = "\n".join(
|
||||
[
|
||||
f"{msg['role'].upper()}: {msg['content']}"
|
||||
for msg in messages[-20:] # Analyze last 20 messages context
|
||||
]
|
||||
)
|
||||
|
||||
prompt = f"""
|
||||
Existing Rules:
|
||||
{current_rules if current_rules else "None"}
|
||||
|
||||
Conversation Excerpt:
|
||||
{conversation_text}
|
||||
|
||||
Please output the updated Project Rules:
|
||||
"""
|
||||
|
||||
payload = {
|
||||
"model": self.valves.MODEL_ID,
|
||||
"messages": [
|
||||
{"role": "system", "content": SYSTEM_PROMPT_RULE_GENERATOR},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
try:
|
||||
# We need a user object for permission checks in generate_chat_completion
|
||||
user = Users.get_user_by_id(user_id)
|
||||
if not user:
|
||||
return current_rules
|
||||
|
||||
completion = await generate_chat_completion(__request__, payload, user)
|
||||
if "choices" in completion and len(completion["choices"]) > 0:
|
||||
content = completion["choices"][0]["message"]["content"].strip()
|
||||
# Basic validation: ensure it looks like a list
|
||||
if (
|
||||
content.startswith("-")
|
||||
or content.startswith("*")
|
||||
or content.startswith("1.")
|
||||
):
|
||||
return content
|
||||
except Exception as e:
|
||||
logger.error(f"Rule generation failed: {e}")
|
||||
|
||||
return current_rules
|
||||
|
||||
async def _process_rules_update(
|
||||
self,
|
||||
folder_id: str,
|
||||
body: dict,
|
||||
user_id: str,
|
||||
__request__: Request,
|
||||
__event_emitter__,
|
||||
):
|
||||
try:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Start Processing",
|
||||
{"step": "start", "initial_folder_id": folder_id, "user_id": user_id},
|
||||
)
|
||||
|
||||
# 1. Fetch Folder Data (ORM)
|
||||
initial_folder = Folders.get_folder_by_id_and_user_id(folder_id, user_id)
|
||||
if not initial_folder:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Error: Initial folder not found",
|
||||
{
|
||||
"step": "fetch_initial_folder",
|
||||
"initial_folder_id": folder_id,
|
||||
"user_id": user_id,
|
||||
},
|
||||
)
|
||||
return
|
||||
|
||||
# Subfolder handling logic
|
||||
target_folder = initial_folder
|
||||
if self.valves.UPDATE_ROOT_FOLDER:
|
||||
# Traverse up until a folder with no parent_id is found
|
||||
while target_folder and getattr(target_folder, "parent_id", None):
|
||||
try:
|
||||
parent = Folders.get_folder_by_id_and_user_id(
|
||||
target_folder.parent_id, user_id
|
||||
)
|
||||
if parent:
|
||||
target_folder = parent
|
||||
else:
|
||||
break
|
||||
except Exception as e:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Warning: Failed to traverse parent folder",
|
||||
{"step": "traverse_root", "error": str(e)},
|
||||
)
|
||||
break
|
||||
|
||||
target_folder_id = target_folder.id
|
||||
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Target Folder Resolved",
|
||||
{
|
||||
"step": "target_resolved",
|
||||
"target_folder_id": target_folder_id,
|
||||
"target_folder_name": target_folder.name,
|
||||
"is_root_update": target_folder_id != folder_id,
|
||||
},
|
||||
)
|
||||
|
||||
existing_data = target_folder.data if target_folder.data else {}
|
||||
existing_sys_prompt = existing_data.get("system_prompt", "")
|
||||
|
||||
# 2. Extract Existing Rules
|
||||
current_rules_content = self._extract_existing_rules(existing_sys_prompt)
|
||||
|
||||
# 3. Generate New Rules
|
||||
await self._emit_status(
|
||||
__event_emitter__, "Analyzing project rules...", done=False
|
||||
)
|
||||
|
||||
messages = body.get("messages", [])
|
||||
new_rules_content = await self._generate_new_rules(
|
||||
current_rules_content, messages, user_id, __request__
|
||||
)
|
||||
|
||||
rules_changed = new_rules_content != current_rules_content
|
||||
|
||||
# 4. If no change, skip
|
||||
if not rules_changed:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"No Changes",
|
||||
{
|
||||
"step": "check_changes",
|
||||
"reason": "content_identical_or_generation_failed",
|
||||
},
|
||||
)
|
||||
await self._emit_status(
|
||||
__event_emitter__,
|
||||
"Rule analysis complete: No new content.",
|
||||
done=True,
|
||||
)
|
||||
return
|
||||
|
||||
# 5. Inject Rules into System Prompt
|
||||
updated_sys_prompt = existing_sys_prompt
|
||||
if rules_changed:
|
||||
updated_sys_prompt = self._inject_rules(
|
||||
updated_sys_prompt,
|
||||
new_rules_content,
|
||||
self.valves.RULES_BLOCK_TITLE,
|
||||
)
|
||||
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Ready to Update DB",
|
||||
{"step": "pre_db_update", "target_folder_id": target_folder_id},
|
||||
)
|
||||
|
||||
# 6. Update Folder (ORM) - Only update 'data' field
|
||||
existing_data["system_prompt"] = updated_sys_prompt
|
||||
|
||||
updated_folder = Folders.update_folder_by_id_and_user_id(
|
||||
target_folder_id,
|
||||
user_id,
|
||||
FolderUpdateForm(data=existing_data),
|
||||
)
|
||||
|
||||
if not updated_folder:
|
||||
raise Exception("Update folder failed (ORM returned None)")
|
||||
|
||||
await self._emit_status(
|
||||
__event_emitter__, "Rule analysis complete: Rules updated.", done=True
|
||||
)
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Rule Generation Process & Change Details",
|
||||
{
|
||||
"step": "success",
|
||||
"folder_id": target_folder_id,
|
||||
"target_is_root": target_folder_id != folder_id,
|
||||
"model_used": self.valves.MODEL_ID,
|
||||
"analyzed_messages_count": len(messages),
|
||||
"old_rules_length": len(current_rules_content),
|
||||
"new_rules_length": len(new_rules_content),
|
||||
"changes_digest": {
|
||||
"old_rules_preview": (
|
||||
current_rules_content[:100] + "..."
|
||||
if current_rules_content
|
||||
else "None"
|
||||
),
|
||||
"new_rules_preview": (
|
||||
new_rules_content[:100] + "..."
|
||||
if new_rules_content
|
||||
else "None"
|
||||
),
|
||||
},
|
||||
"timestamp": datetime.now().isoformat(),
|
||||
},
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Async rule processing error: {e}")
|
||||
await self._emit_status(
|
||||
__event_emitter__, "Failed to update rules.", done=True
|
||||
)
|
||||
# Emit error to console for debugging
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Execution Error",
|
||||
{"error": str(e), "folder_id": folder_id},
|
||||
)
|
||||
|
||||
# ==================== Filter Hooks ====================
|
||||
|
||||
async def inlet(
|
||||
self, body: dict, __user__: Optional[dict] = None, __event_emitter__=None
|
||||
) -> dict:
|
||||
return body
|
||||
|
||||
async def outlet(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: Optional[dict] = None,
|
||||
__event_emitter__=None,
|
||||
__request__: Optional[Request] = None,
|
||||
) -> dict:
|
||||
user_ctx = self._get_user_context(__user__)
|
||||
chat_ctx = self._get_chat_context(body)
|
||||
|
||||
messages = body.get("messages", [])
|
||||
if not messages:
|
||||
return body
|
||||
|
||||
# Trigger logic: Message Count threshold
|
||||
if len(messages) % self.valves.MESSAGE_TRIGGER_COUNT != 0:
|
||||
return body
|
||||
|
||||
folder_id = self._get_folder_id(body)
|
||||
if not folder_id:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"Skipping Analysis",
|
||||
{
|
||||
"reason": "Chat does not belong to any folder",
|
||||
"chat_id": chat_ctx.get("chat_id"),
|
||||
},
|
||||
)
|
||||
return body
|
||||
|
||||
# User Info
|
||||
user_id = user_ctx.get("user_id")
|
||||
if not user_id:
|
||||
return body
|
||||
|
||||
# Async Task
|
||||
if self.valves.MODEL_ID == "":
|
||||
self.valves.MODEL_ID = body.get("model", "")
|
||||
|
||||
asyncio.create_task(
|
||||
self._process_rules_update(
|
||||
folder_id, body, user_id, __request__, __event_emitter__
|
||||
)
|
||||
)
|
||||
|
||||
return body
|
||||
470
plugins/filters/folder-memory/folder_memory_cn.py
Normal file
470
plugins/filters/folder-memory/folder_memory_cn.py
Normal file
@@ -0,0 +1,470 @@
|
||||
"""
|
||||
title: 📂 文件夹记忆 (Folder Memory)
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 0.1.0
|
||||
description: 自动从对话中提取项目规则,并将其注入到文件夹的系统提示词中。
|
||||
requirements:
|
||||
"""
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from typing import Optional, Dict, List
|
||||
from fastapi import Request
|
||||
import logging
|
||||
import json
|
||||
import re
|
||||
import asyncio
|
||||
from datetime import datetime
|
||||
|
||||
from open_webui.utils.chat import generate_chat_completion
|
||||
from open_webui.models.users import Users
|
||||
from open_webui.models.folders import Folders, FolderUpdateForm
|
||||
from open_webui.models.chats import Chats
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# 规则注入标记
|
||||
RULES_BLOCK_START = "<!-- OWUI_PROJECT_RULES_START -->"
|
||||
RULES_BLOCK_END = "<!-- OWUI_PROJECT_RULES_END -->"
|
||||
|
||||
# 规则生成系统提示词
|
||||
SYSTEM_PROMPT_RULE_GENERATOR = """
|
||||
你是一个项目规则提取器。你的任务是从对话中提取“项目规则”,并与现有规则合并。
|
||||
|
||||
### 输入
|
||||
1. **现有规则 (Existing Rules)**:当前文件夹系统提示词中的规则。
|
||||
2. **对话片段 (Conversation)**:最近的聊天记录。
|
||||
|
||||
### 目标
|
||||
综合生成一份适用于当前项目/文件夹的简洁规则列表。
|
||||
- **移除** 不再相关或仅是一次性指令的规则。
|
||||
- **添加** 对话中发现的新的、一致性的要求。
|
||||
- **合并** 相似的规则。
|
||||
- **格式**:简洁的 Markdown 项目符号列表。
|
||||
|
||||
### 输出格式
|
||||
仅输出 Markdown 项目符号列表形式的规则。不要包含任何开头或结尾的说明文字。
|
||||
示例:
|
||||
- 始终使用 Python 3.11 进行类型提示。
|
||||
- 文档字符串必须遵循 Google 风格。
|
||||
- 提交信息必须使用英文。
|
||||
"""
|
||||
|
||||
|
||||
class Filter:
|
||||
class Valves(BaseModel):
|
||||
PRIORITY: int = Field(default=20, description="过滤器操作的优先级。")
|
||||
SHOW_DEBUG_LOG: bool = Field(
|
||||
default=False, description="在控制台显示调试日志。"
|
||||
)
|
||||
MESSAGE_TRIGGER_COUNT: int = Field(
|
||||
default=10, description="每隔 N 条消息分析一次规则。"
|
||||
)
|
||||
MODEL_ID: str = Field(
|
||||
default="", description="用于提取规则的模型 ID。为空则使用当前对话模型。"
|
||||
)
|
||||
RULES_BLOCK_TITLE: str = Field(
|
||||
default="## 📂 项目规则", description="显示在规则块上方的标题。"
|
||||
)
|
||||
UPDATE_ROOT_FOLDER: bool = Field(
|
||||
default=False,
|
||||
description="如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。",
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
|
||||
# ==================== 辅助方法 ====================
|
||||
|
||||
def _get_user_context(self, __user__: Optional[dict]) -> Dict[str, str]:
|
||||
"""安全提取用户上下文信息。"""
|
||||
if isinstance(__user__, (list, tuple)):
|
||||
user_data = __user__[0] if __user__ else {}
|
||||
elif isinstance(__user__, dict):
|
||||
user_data = __user__
|
||||
else:
|
||||
user_data = {}
|
||||
|
||||
return {
|
||||
"user_id": user_data.get("id", ""),
|
||||
"user_name": user_data.get("name", "User"),
|
||||
"user_language": user_data.get("language", "zh-CN"),
|
||||
}
|
||||
|
||||
def _get_chat_context(
|
||||
self, body: dict, __metadata__: Optional[dict] = None
|
||||
) -> Dict[str, str]:
|
||||
"""统一提取聊天上下文信息 (chat_id, message_id)。"""
|
||||
chat_id = ""
|
||||
message_id = ""
|
||||
|
||||
if isinstance(body, dict):
|
||||
chat_id = body.get("chat_id", "")
|
||||
message_id = body.get("id", "")
|
||||
|
||||
if not chat_id or not message_id:
|
||||
body_metadata = body.get("metadata", {})
|
||||
if isinstance(body_metadata, dict):
|
||||
if not chat_id:
|
||||
chat_id = body_metadata.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = body_metadata.get("message_id", "")
|
||||
|
||||
if __metadata__ and isinstance(__metadata__, dict):
|
||||
if not chat_id:
|
||||
chat_id = __metadata__.get("chat_id", "")
|
||||
if not message_id:
|
||||
message_id = __metadata__.get("message_id", "")
|
||||
|
||||
return {
|
||||
"chat_id": str(chat_id).strip(),
|
||||
"message_id": str(message_id).strip(),
|
||||
}
|
||||
|
||||
async def _emit_debug_log(self, __event_emitter__, title: str, data: dict):
|
||||
if self.valves.SHOW_DEBUG_LOG and __event_emitter__:
|
||||
try:
|
||||
# 按照用户要求的格式输出展平的日志
|
||||
js_code = f"""
|
||||
console.log("[Folder Memory] {title}", {json.dumps(data, ensure_ascii=False)});
|
||||
"""
|
||||
await __event_emitter__({"type": "execute", "data": {"code": js_code}})
|
||||
except Exception as e:
|
||||
logger.error(f"发出日志错误: {e}")
|
||||
|
||||
async def _emit_status(
|
||||
self, __event_emitter__, description: str, done: bool = False
|
||||
):
|
||||
if __event_emitter__:
|
||||
await __event_emitter__(
|
||||
{"type": "status", "data": {"description": description, "done": done}}
|
||||
)
|
||||
|
||||
def _get_folder_id(self, body: dict) -> Optional[str]:
|
||||
# 1. 尝试从 metadata 获取 folder_id
|
||||
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||
if "folder_id" in body["metadata"]:
|
||||
return body["metadata"]["folder_id"]
|
||||
|
||||
# 2. 检查 chat 对象
|
||||
if "chat" in body and isinstance(body["chat"], dict):
|
||||
if "folder_id" in body["chat"]:
|
||||
return body["chat"]["folder_id"]
|
||||
|
||||
# 3. 尝试通过 Chat ID 查找 (最可靠的方法)
|
||||
chat_id = body.get("chat_id")
|
||||
if not chat_id:
|
||||
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||
chat_id = body["metadata"].get("chat_id")
|
||||
|
||||
if chat_id:
|
||||
try:
|
||||
chat = Chats.get_chat_by_id(chat_id)
|
||||
if chat and chat.folder_id:
|
||||
return chat.folder_id
|
||||
except Exception as e:
|
||||
logger.error(f"获取聊天信息失败 chat_id={chat_id}: {e}")
|
||||
|
||||
return None
|
||||
|
||||
def _extract_existing_rules(self, system_prompt: str) -> str:
|
||||
pattern = re.compile(
|
||||
re.escape(RULES_BLOCK_START) + r"([\s\S]*?)" + re.escape(RULES_BLOCK_END)
|
||||
)
|
||||
match = pattern.search(system_prompt)
|
||||
if match:
|
||||
# 如果标题在块内,将其移除以便纯净合并
|
||||
content = match.group(1).strip()
|
||||
title_pat = re.compile(r"^#+\s+.*$", re.MULTILINE)
|
||||
return title_pat.sub("", content).strip()
|
||||
return ""
|
||||
|
||||
def _inject_rules(self, system_prompt: str, new_rules: str, title: str) -> str:
|
||||
new_block_content = f"\n{title}\n\n{new_rules}\n"
|
||||
new_block = f"{RULES_BLOCK_START}{new_block_content}{RULES_BLOCK_END}"
|
||||
|
||||
system_prompt = system_prompt or ""
|
||||
pattern = re.compile(
|
||||
re.escape(RULES_BLOCK_START) + r"[\s\S]*?" + re.escape(RULES_BLOCK_END)
|
||||
)
|
||||
|
||||
if pattern.search(system_prompt):
|
||||
# 替换现有块
|
||||
return pattern.sub(new_block, system_prompt).strip()
|
||||
else:
|
||||
# 追加到末尾
|
||||
if system_prompt:
|
||||
return f"{system_prompt}\n\n{new_block}"
|
||||
else:
|
||||
return new_block
|
||||
|
||||
async def _generate_new_rules(
|
||||
self,
|
||||
current_rules: str,
|
||||
messages: List[Dict],
|
||||
user_id: str,
|
||||
__request__: Request,
|
||||
) -> str:
|
||||
# 准备上下文
|
||||
conversation_text = "\n".join(
|
||||
[
|
||||
f"{msg['role'].upper()}: {msg['content']}"
|
||||
for msg in messages[-20:] # 分析最近 20 条消息上下文
|
||||
]
|
||||
)
|
||||
|
||||
prompt = f"""
|
||||
Existing Rules (现有规则):
|
||||
{current_rules if current_rules else "无"}
|
||||
|
||||
Conversation Excerpt (对话片段):
|
||||
{conversation_text}
|
||||
|
||||
Please output the updated Project Rules (请输出更新后的项目规则):
|
||||
"""
|
||||
|
||||
payload = {
|
||||
"model": self.valves.MODEL_ID,
|
||||
"messages": [
|
||||
{"role": "system", "content": SYSTEM_PROMPT_RULE_GENERATOR},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
"stream": False,
|
||||
}
|
||||
|
||||
try:
|
||||
# 需要用户对象进行权限检查
|
||||
user = Users.get_user_by_id(user_id)
|
||||
if not user:
|
||||
return current_rules
|
||||
|
||||
completion = await generate_chat_completion(__request__, payload, user)
|
||||
if "choices" in completion and len(completion["choices"]) > 0:
|
||||
content = completion["choices"][0]["message"]["content"].strip()
|
||||
# 简单验证:确保看起来像个列表
|
||||
if (
|
||||
content.startswith("-")
|
||||
or content.startswith("*")
|
||||
or content.startswith("1.")
|
||||
):
|
||||
return content
|
||||
except Exception as e:
|
||||
logger.error(f"规则生成失败: {e}")
|
||||
|
||||
return current_rules
|
||||
|
||||
async def _process_rules_update(
|
||||
self,
|
||||
folder_id: str,
|
||||
body: dict,
|
||||
user_id: str,
|
||||
__request__: Request,
|
||||
__event_emitter__,
|
||||
):
|
||||
try:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"开始处理",
|
||||
{"step": "start", "initial_folder_id": folder_id, "user_id": user_id},
|
||||
)
|
||||
|
||||
# 1. 获取文件夹数据 (ORM)
|
||||
initial_folder = Folders.get_folder_by_id_and_user_id(folder_id, user_id)
|
||||
if not initial_folder:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"错误:未找到初始文件夹",
|
||||
{
|
||||
"step": "fetch_initial_folder",
|
||||
"initial_folder_id": folder_id,
|
||||
"user_id": user_id,
|
||||
},
|
||||
)
|
||||
return
|
||||
|
||||
# 处理子文件夹逻辑:决定是更新当前文件夹还是根文件夹
|
||||
target_folder = initial_folder
|
||||
if self.valves.UPDATE_ROOT_FOLDER:
|
||||
# 向上遍历直到找到没有 parent_id 的根文件夹
|
||||
while target_folder and getattr(target_folder, "parent_id", None):
|
||||
try:
|
||||
parent = Folders.get_folder_by_id_and_user_id(
|
||||
target_folder.parent_id, user_id
|
||||
)
|
||||
if parent:
|
||||
target_folder = parent
|
||||
else:
|
||||
break
|
||||
except Exception as e:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"警告:向上查找父文件夹失败",
|
||||
{"step": "traverse_root", "error": str(e)},
|
||||
)
|
||||
break
|
||||
|
||||
target_folder_id = target_folder.id
|
||||
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"定目标文件夹",
|
||||
{
|
||||
"step": "target_resolved",
|
||||
"target_folder_id": target_folder_id,
|
||||
"target_folder_name": target_folder.name,
|
||||
"is_root_update": target_folder_id != folder_id,
|
||||
},
|
||||
)
|
||||
|
||||
existing_data = target_folder.data if target_folder.data else {}
|
||||
existing_sys_prompt = existing_data.get("system_prompt", "")
|
||||
|
||||
# 2. 提取现有规则
|
||||
current_rules_content = self._extract_existing_rules(existing_sys_prompt)
|
||||
|
||||
# 3. 生成新规则
|
||||
await self._emit_status(
|
||||
__event_emitter__, "正在分析项目规则...", done=False
|
||||
)
|
||||
|
||||
messages = body.get("messages", [])
|
||||
new_rules_content = await self._generate_new_rules(
|
||||
current_rules_content, messages, user_id, __request__
|
||||
)
|
||||
|
||||
rules_changed = new_rules_content != current_rules_content
|
||||
|
||||
# 如果生成结果无变更
|
||||
if not rules_changed:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"无变更",
|
||||
{
|
||||
"step": "check_changes",
|
||||
"reason": "content_identical_or_generation_failed",
|
||||
},
|
||||
)
|
||||
await self._emit_status(
|
||||
__event_emitter__, "规则分析完成:无新增内容。", done=True
|
||||
)
|
||||
return
|
||||
|
||||
# 5. 注入规则到 System Prompt
|
||||
updated_sys_prompt = existing_sys_prompt
|
||||
if rules_changed:
|
||||
updated_sys_prompt = self._inject_rules(
|
||||
updated_sys_prompt,
|
||||
new_rules_content,
|
||||
self.valves.RULES_BLOCK_TITLE,
|
||||
)
|
||||
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"准备更新数据库",
|
||||
{"step": "pre_db_update", "target_folder_id": target_folder_id},
|
||||
)
|
||||
|
||||
# 6. 更新文件夹 (ORM) - 仅更新 'data' 字段
|
||||
existing_data["system_prompt"] = updated_sys_prompt
|
||||
|
||||
updated_folder = Folders.update_folder_by_id_and_user_id(
|
||||
target_folder_id,
|
||||
user_id,
|
||||
FolderUpdateForm(data=existing_data),
|
||||
)
|
||||
|
||||
if not updated_folder:
|
||||
raise Exception("Update folder failed (ORM returned None)")
|
||||
|
||||
await self._emit_status(
|
||||
__event_emitter__, "规则分析完成:规则已更新。", done=True
|
||||
)
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"规则生成过程和变更详情",
|
||||
{
|
||||
"step": "success",
|
||||
"folder_id": target_folder_id,
|
||||
"target_is_root": target_folder_id != folder_id,
|
||||
"model_used": self.valves.MODEL_ID,
|
||||
"analyzed_messages_count": len(messages),
|
||||
"old_rules_length": len(current_rules_content),
|
||||
"new_rules_length": len(new_rules_content),
|
||||
"changes_digest": {
|
||||
"old_rules_preview": (
|
||||
current_rules_content[:100] + "..."
|
||||
if current_rules_content
|
||||
else "None"
|
||||
),
|
||||
"new_rules_preview": (
|
||||
new_rules_content[:100] + "..."
|
||||
if new_rules_content
|
||||
else "None"
|
||||
),
|
||||
},
|
||||
"timestamp": datetime.now().isoformat(),
|
||||
},
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"异步规则处理错误: {e}")
|
||||
await self._emit_status(__event_emitter__, "更新规则失败。", done=True)
|
||||
# 在控制台也输出错误信息,方便调试
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__, "执行出错", {"error": str(e), "folder_id": folder_id}
|
||||
)
|
||||
|
||||
# ==================== Filter Hooks ====================
|
||||
|
||||
async def inlet(
|
||||
self, body: dict, __user__: Optional[dict] = None, __event_emitter__=None
|
||||
) -> dict:
|
||||
return body
|
||||
|
||||
async def outlet(
|
||||
self,
|
||||
body: dict,
|
||||
__user__: Optional[dict] = None,
|
||||
__event_emitter__=None,
|
||||
__request__: Optional[Request] = None,
|
||||
) -> dict:
|
||||
user_ctx = self._get_user_context(__user__)
|
||||
chat_ctx = self._get_chat_context(body)
|
||||
|
||||
messages = body.get("messages", [])
|
||||
if not messages:
|
||||
return body
|
||||
|
||||
# 触发逻辑:消息计数阈值
|
||||
if len(messages) % self.valves.MESSAGE_TRIGGER_COUNT != 0:
|
||||
return body
|
||||
|
||||
folder_id = self._get_folder_id(body)
|
||||
if not folder_id:
|
||||
await self._emit_debug_log(
|
||||
__event_emitter__,
|
||||
"跳过分析",
|
||||
{"reason": "对话不属于任何文件夹", "chat_id": chat_ctx.get("chat_id")},
|
||||
)
|
||||
return body
|
||||
|
||||
# 用户信息
|
||||
user_id = user_ctx.get("user_id")
|
||||
if not user_id:
|
||||
return body
|
||||
|
||||
# 异步任务
|
||||
if self.valves.MODEL_ID == "":
|
||||
self.valves.MODEL_ID = body.get("model", "")
|
||||
|
||||
asyncio.create_task(
|
||||
self._process_rules_update(
|
||||
folder_id, body, user_id, __request__, __event_emitter__
|
||||
)
|
||||
)
|
||||
|
||||
return body
|
||||
@@ -1,69 +1,96 @@
|
||||
# Markdown Normalizer Filter
|
||||
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.2.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.2.4 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||
|
||||
A content normalizer filter for Open WebUI that fixes common Markdown formatting issues in LLM outputs. It ensures that code blocks, LaTeX formulas, Mermaid diagrams, and other Markdown elements are rendered correctly.
|
||||
|
||||
## Features
|
||||
|
||||
* **Details Tag Normalization**: Ensures proper spacing for `<details>` tags (used for thought chains). Adds a blank line after `</details>` and ensures a newline after self-closing `<details />` tags to prevent rendering issues.
|
||||
* **Mermaid Syntax Fix**: Automatically fixes common Mermaid syntax errors, such as unquoted node labels (including multi-line labels and citations) and unclosed subgraphs. **New in v1.1.2**: Comprehensive protection for edge labels (text on connecting lines) across all link types (solid, dotted, thick).
|
||||
* **Frontend Console Debugging**: Supports printing structured debug logs directly to the browser console (F12) for easier troubleshooting.
|
||||
* **Code Block Formatting**: Fixes broken code block prefixes, suffixes, and indentation.
|
||||
* **LaTeX Normalization**: Standardizes LaTeX formula delimiters (`\[` -> `$$`, `\(` -> `$`).
|
||||
* **Thought Tag Normalization**: Unifies thought tags (`<think>`, `<thinking>` -> `<thought>`).
|
||||
* **Escape Character Fix**: Cleans up excessive escape characters (`\\n`, `\\t`).
|
||||
* **List Formatting**: Ensures proper newlines in list items.
|
||||
* **Heading Fix**: Adds missing spaces in headings (`#Heading` -> `# Heading`).
|
||||
* **Table Fix**: Adds missing closing pipes in tables.
|
||||
* **XML Cleanup**: Removes leftover XML artifacts.
|
||||
* **Details Tag Normalization**: Ensures proper spacing for `<details>` tags (used for thought chains). Adds a blank line after `</details>` and ensures a newline after self-closing `<details />` tags to prevent rendering issues.
|
||||
* **Emphasis Spacing Fix**: Fixes extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`) which can cause rendering failures. Includes safeguards to protect math expressions (e.g., `2 * 3 * 4`) and list variables.
|
||||
* **Mermaid Syntax Fix**: Automatically fixes common Mermaid syntax errors, such as unquoted node labels (including multi-line labels and citations) and unclosed subgraphs. **New in v1.1.2**: Comprehensive protection for edge labels (text on connecting lines) across all link types (solid, dotted, thick).
|
||||
* **Frontend Console Debugging**: Supports printing structured debug logs directly to the browser console (F12) for easier troubleshooting.
|
||||
* **Code Block Formatting**: Fixes broken code block prefixes, suffixes, and indentation.
|
||||
* **LaTeX Normalization**: Standardizes LaTeX formula delimiters (`\[` -> `$$`, `\(` -> `$`).
|
||||
* **Thought Tag Normalization**: Unifies thought tags (`<think>`, `<thinking>` -> `<thought>`).
|
||||
* **Escape Character Fix**: Cleans up excessive escape characters (`\\n`, `\\t`).
|
||||
* **List Formatting**: Ensures proper newlines in list items.
|
||||
* **Heading Fix**: Adds missing spaces in headings (`#Heading` -> `# Heading`).
|
||||
* **Table Fix**: Adds missing closing pipes in tables.
|
||||
* **XML Cleanup**: Removes leftover XML artifacts.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Install the plugin in Open WebUI.
|
||||
2. Enable the filter globally or for specific models.
|
||||
3. Configure the enabled fixes in the **Valves** settings.
|
||||
4. (Optional) **Show Debug Log** is enabled by default in Valves. This prints structured logs to the browser console (F12).
|
||||
1. Install the plugin in Open WebUI.
|
||||
2. Enable the filter globally or for specific models.
|
||||
3. Configure the enabled fixes in the **Valves** settings.
|
||||
4. (Optional) **Show Debug Log** is enabled by default in Valves. This prints structured logs to the browser console (F12).
|
||||
> [!WARNING]
|
||||
> As this is an initial version, some "negative fixes" might occur (e.g., breaking valid Markdown). If you encounter issues, please check the console logs, copy the "Original" vs "Normalized" content, and submit an issue.
|
||||
|
||||
## Configuration (Valves)
|
||||
|
||||
* `priority`: Filter priority (default: 50).
|
||||
* `enable_escape_fix`: Fix excessive escape characters.
|
||||
* `enable_thought_tag_fix`: Normalize thought tags.
|
||||
* `enable_details_tag_fix`: Normalize details tags (default: True).
|
||||
* `enable_code_block_fix`: Fix code block formatting.
|
||||
* `enable_latex_fix`: Normalize LaTeX formulas.
|
||||
* `enable_list_fix`: Fix list item newlines (Experimental).
|
||||
* `enable_unclosed_block_fix`: Auto-close unclosed code blocks.
|
||||
* `enable_fullwidth_symbol_fix`: Fix full-width symbols in code blocks.
|
||||
* `enable_mermaid_fix`: Fix Mermaid syntax errors.
|
||||
* `enable_heading_fix`: Fix missing space in headings.
|
||||
* `enable_table_fix`: Fix missing closing pipe in tables.
|
||||
* `enable_xml_tag_cleanup`: Cleanup leftover XML tags.
|
||||
* `show_status`: Show status notification when fixes are applied.
|
||||
* `show_debug_log`: Print debug logs to browser console.
|
||||
* `priority`: Filter priority (default: 50).
|
||||
* `enable_escape_fix`: Fix excessive escape characters.
|
||||
* `enable_thought_tag_fix`: Normalize thought tags.
|
||||
* `enable_details_tag_fix`: Normalize details tags (default: True).
|
||||
* `enable_code_block_fix`: Fix code block formatting.
|
||||
* `enable_latex_fix`: Normalize LaTeX formulas.
|
||||
* `enable_list_fix`: Fix list item newlines (Experimental).
|
||||
* `enable_unclosed_block_fix`: Auto-close unclosed code blocks.
|
||||
* `enable_fullwidth_symbol_fix`: Fix full-width symbols in code blocks.
|
||||
* `enable_mermaid_fix`: Fix Mermaid syntax errors.
|
||||
* `enable_heading_fix`: Fix missing space in headings.
|
||||
* `enable_table_fix`: Fix missing closing pipe in tables.
|
||||
* `enable_xml_tag_cleanup`: Cleanup leftover XML tags.
|
||||
* `enable_emphasis_spacing_fix`: Fix extra spaces in emphasis (default: False).
|
||||
* `show_status`: Show status notification when fixes are applied.
|
||||
* `show_debug_log`: Print debug logs to browser console.
|
||||
|
||||
## Troubleshooting ❓
|
||||
|
||||
- **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
* **Submit an Issue**: If you encounter any problems, please submit an issue on GitHub: [Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## Changelog
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **Documentation Updates**: Synchronized version numbers across all documentation and code files.
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **List Marker Protection Enhancement**: Fixed a bug where list markers (`*`) followed by plain text and emphasis were having their spaces incorrectly stripped (e.g., `* U16 forward` became `*U16 forward`).
|
||||
* **Placeholder Support**: Confirmed that 4 or more underscores (e.g., `____`) are correctly treated as placeholders and not modified by the emphasis fix.
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **Code Block Indentation Fix**: Fixed an issue where code blocks nested inside lists were having their indentation incorrectly stripped. Now preserves proper indentation for nested code blocks.
|
||||
* **Underscore Emphasis Support**: Extended emphasis spacing fix to support `__` (double underscore for bold) and `___` (triple underscore for bold+italic) syntax.
|
||||
* **List Marker Protection**: Fixed a bug where list markers (`*`) followed by emphasis markers (`**`) were incorrectly merged (e.g., `* **Yes**` became `***Yes**`). Added safeguard to prevent this.
|
||||
* **Test Suite**: Added comprehensive pytest test suite with 56 test cases covering all major features.
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **Emphasis Spacing Fix**: Added a new fix for extra spaces inside emphasis markers (e.g., `** text **` -> `**text**`).
|
||||
* Uses a recursive approach to handle nested emphasis (e.g., `**bold _italic _**`).
|
||||
* Includes safeguards to prevent modifying math expressions (e.g., `2 * 3 * 4`) or list variables.
|
||||
* Controlled by the `enable_emphasis_spacing_fix` valve (default: True).
|
||||
|
||||
### v1.2.0
|
||||
* **Details Tag Support**: Added normalization for `<details>` tags.
|
||||
* Ensures a blank line is added after `</details>` closing tags to separate thought content from the main response.
|
||||
* Ensures a newline is added after self-closing `<details ... />` tags to prevent them from interfering with subsequent Markdown headings (e.g., fixing `<details/>#Heading`).
|
||||
* Includes safeguard to prevent modification of `<details>` tags inside code blocks.
|
||||
|
||||
* **Details Tag Support**: Added normalization for `<details>` tags.
|
||||
* Ensures a blank line is added after `</details>` closing tags to separate thought content from the main response.
|
||||
* Ensures a newline is added after self-closing `<details ... />` tags to prevent them from interfering with subsequent Markdown headings (e.g., fixing `<details/>#Heading`).
|
||||
* Includes safeguard to prevent modification of `<details>` tags inside code blocks.
|
||||
|
||||
### v1.1.2
|
||||
* **Mermaid Edge Label Protection**: Implemented comprehensive protection for edge labels (text on connecting lines) to prevent them from being incorrectly modified. Now supports all Mermaid link types including solid (`--`), dotted (`-.`), and thick (`==`) lines with or without arrows.
|
||||
* **Bug Fixes**: Fixed an issue where lines without arrows (e.g., `A -- text --- B`) were not correctly protected.
|
||||
|
||||
* **Mermaid Edge Label Protection**: Implemented comprehensive protection for edge labels (text on connecting lines) to prevent them from being incorrectly modified. Now supports all Mermaid link types including solid (`--`), dotted (`-.`), and thick (`==`) lines with or without arrows.
|
||||
* **Bug Fixes**: Fixed an issue where lines without arrows (e.g., `A -- text --- B`) were not correctly protected.
|
||||
|
||||
### v1.1.0
|
||||
* **Mermaid Fix Refinement**: Improved regex to handle nested parentheses in node labels (e.g., `ID("Label (text)")`) and avoided matching connection labels.
|
||||
* **HTML Safeguard Optimization**: Refined `_contains_html` to allow common tags like `<br/>`, `<b>`, `<i>`, etc., ensuring Mermaid diagrams with these tags are still normalized.
|
||||
* **Full-width Symbol Cleanup**: Fixed duplicate keys and incorrect quote mapping in `FULLWIDTH_MAP`.
|
||||
* **Bug Fixes**: Fixed missing `Dict` import in Python files.
|
||||
|
||||
* **Mermaid Fix Refinement**: Improved regex to handle nested parentheses in node labels (e.g., `ID("Label (text)")`) and avoided matching connection labels.
|
||||
* **HTML Safeguard Optimization**: Refined `_contains_html` to allow common tags like `<br/>`, `<b>`, `<i>`, etc., ensuring Mermaid diagrams with these tags are still normalized.
|
||||
* **Full-width Symbol Cleanup**: Fixed duplicate keys and incorrect quote mapping in `FULLWIDTH_MAP`.
|
||||
* **Bug Fixes**: Fixed missing `Dict` import in Python files.
|
||||
|
||||
@@ -1,69 +1,96 @@
|
||||
# Markdown 格式化过滤器 (Markdown Normalizer)
|
||||
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.2.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.2.4 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||
|
||||
这是一个用于 Open WebUI 的内容格式化过滤器,旨在修复 LLM 输出中常见的 Markdown 格式问题。它能确保代码块、LaTeX 公式、Mermaid 图表和其他 Markdown 元素被正确渲染。
|
||||
|
||||
## 功能特性
|
||||
|
||||
* **Details 标签规范化**: 确保 `<details>` 标签(常用于思维链)有正确的间距。在 `</details>` 后添加空行,并在自闭合 `<details />` 标签后添加换行,防止渲染问题。
|
||||
* **Mermaid 语法修复**: 自动修复常见的 Mermaid 语法错误,如未加引号的节点标签(支持多行标签和引用标记)和未闭合的子图 (Subgraph)。**v1.1.2 新增**: 全面保护各种类型的连线标签(实线、虚线、粗线),防止被误修改。
|
||||
* **前端控制台调试**: 支持将结构化的调试日志直接打印到浏览器控制台 (F12),方便排查问题。
|
||||
* **代码块格式化**: 修复破损的代码块前缀、后缀和缩进问题。
|
||||
* **LaTeX 规范化**: 标准化 LaTeX 公式定界符 (`\[` -> `$$`, `\(` -> `$`)。
|
||||
* **思维标签规范化**: 统一思维链标签 (`<think>`, `<thinking>` -> `<thought>`)。
|
||||
* **转义字符修复**: 清理过度的转义字符 (`\\n`, `\\t`)。
|
||||
* **列表格式化**: 确保列表项有正确的换行。
|
||||
* **标题修复**: 修复标题中缺失的空格 (`#标题` -> `# 标题`)。
|
||||
* **表格修复**: 修复表格中缺失的闭合管道符。
|
||||
* **XML 清理**: 移除残留的 XML 标签。
|
||||
* **Details 标签规范化**: 确保 `<details>` 标签(常用于思维链)有正确的间距。在 `</details>` 后添加空行,并在自闭合 `<details />` 标签后添加换行,防止渲染问题。
|
||||
* **强调空格修复**: 修复强调标记内部的多余空格(例如 `** 文本 **` -> `**文本**`),这会导致 Markdown 渲染失败。包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* **Mermaid 语法修复**: 自动修复常见的 Mermaid 语法错误,如未加引号的节点标签(支持多行标签和引用标记)和未闭合的子图 (Subgraph)。**v1.1.2 新增**: 全面保护各种类型的连线标签(实线、虚线、粗线),防止被误修改。
|
||||
* **前端控制台调试**: 支持将结构化的调试日志直接打印到浏览器控制台 (F12),方便排查问题。
|
||||
* **代码块格式化**: 修复破损的代码块前缀、后缀和缩进问题。
|
||||
* **LaTeX 规范化**: 标准化 LaTeX 公式定界符 (`\[` -> `$$`, `\(` -> `$`)。
|
||||
* **思维标签规范化**: 统一思维链标签 (`<think>`, `<thinking>` -> `<thought>`)。
|
||||
* **转义字符修复**: 清理过度的转义字符 (`\\n`, `\\t`)。
|
||||
* **列表格式化**: 确保列表项有正确的换行。
|
||||
* **标题修复**: 修复标题中缺失的空格 (`#标题` -> `# 标题`)。
|
||||
* **表格修复**: 修复表格中缺失的闭合管道符。
|
||||
* **XML 清理**: 移除残留的 XML 标签。
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 在 Open WebUI 中安装此插件。
|
||||
2. 全局启用或为特定模型启用此过滤器。
|
||||
3. 在 **Valves** 设置中配置需要启用的修复项。
|
||||
4. (可选) **显示调试日志 (Show Debug Log)** 在 Valves 中默认开启。这会将结构化的日志打印到浏览器控制台 (F12)。
|
||||
1. 在 Open WebUI 中安装此插件。
|
||||
2. 全局启用或为特定模型启用此过滤器。
|
||||
3. 在 **Valves** 设置中配置需要启用的修复项。
|
||||
4. (可选) **显示调试日志 (Show Debug Log)** 在 Valves 中默认开启。这会将结构化的日志打印到浏览器控制台 (F12)。
|
||||
> [!WARNING]
|
||||
> 由于这是初版,可能会出现“负向修复”的情况(例如破坏了原本正确的格式)。如果您遇到问题,请务必查看控制台日志,复制“原始 (Original)”与“规范化 (Normalized)”的内容对比,并提交 Issue 反馈。
|
||||
|
||||
## 配置项 (Valves)
|
||||
|
||||
* `priority`: 过滤器优先级 (默认: 50)。
|
||||
* `enable_escape_fix`: 修复过度的转义字符。
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_details_tag_fix`: 规范化 Details 标签 (默认: True)。
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: 规范化 LaTeX 公式。
|
||||
* `enable_list_fix`: 修复列表项换行 (实验性)。
|
||||
* `enable_unclosed_block_fix`: 自动闭合未闭合的代码块。
|
||||
* `enable_fullwidth_symbol_fix`: 修复代码块中的全角符号。
|
||||
* `enable_mermaid_fix`: 修复 Mermaid 语法错误。
|
||||
* `enable_heading_fix`: 修复标题中缺失的空格。
|
||||
* `enable_table_fix`: 修复表格中缺失的闭合管道符。
|
||||
* `enable_xml_tag_cleanup`: 清理残留的 XML 标签。
|
||||
* `show_status`: 应用修复时显示状态通知。
|
||||
* `show_debug_log`: 在浏览器控制台打印调试日志。
|
||||
* `priority`: 过滤器优先级 (默认: 50)。
|
||||
* `enable_escape_fix`: 修复过度的转义字符。
|
||||
* `enable_thought_tag_fix`: 规范化思维标签。
|
||||
* `enable_details_tag_fix`: 规范化 Details 标签 (默认: True)。
|
||||
* `enable_code_block_fix`: 修复代码块格式。
|
||||
* `enable_latex_fix`: 规范化 LaTeX 公式。
|
||||
* `enable_list_fix`: 修复列表项换行 (实验性)。
|
||||
* `enable_unclosed_block_fix`: 自动闭合未闭合的代码块。
|
||||
* `enable_fullwidth_symbol_fix`: 修复代码块中的全角符号。
|
||||
* `enable_mermaid_fix`: 修复 Mermaid 语法错误。
|
||||
* `enable_heading_fix`: 修复标题中缺失的空格。
|
||||
* `enable_table_fix`: 修复表格中缺失的闭合管道符。
|
||||
* `enable_xml_tag_cleanup`: 清理残留的 XML 标签。
|
||||
* `enable_emphasis_spacing_fix`: 修复强调语法中的多余空格 (默认: True)。
|
||||
* `show_status`: 应用修复时显示状态通知。
|
||||
* `show_debug_log`: 在浏览器控制台打印调试日志。
|
||||
|
||||
## 故障排除 (Troubleshooting) ❓
|
||||
|
||||
- **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
* **提交 Issue**: 如果遇到任何问题,请在 GitHub 上提交 Issue:[Awesome OpenWebUI Issues](https://github.com/Fu-Jie/awesome-openwebui/issues)
|
||||
|
||||
## 更新日志
|
||||
|
||||
### v1.2.4
|
||||
|
||||
* **文档更新**: 同步了所有文档和代码文件的版本号。
|
||||
|
||||
### v1.2.3
|
||||
|
||||
* **列表标记保护增强**: 修复了列表标记 (`*`) 后跟普通文本和强调标记时,空格被错误剥离的问题(例如 `* U16 前锋` 变成 `*U16 前锋`)。
|
||||
* **占位符支持**: 确认 4 个或更多下划线(如 `____`)会被正确视为占位符,不会被强调修复逻辑修改。
|
||||
|
||||
### v1.2.2
|
||||
|
||||
* **代码块缩进修复**: 修复了列表中嵌套代码块的缩进被错误剥离的问题。现在会正确保留嵌套代码块的缩进。
|
||||
* **下划线强调语法支持**: 扩展强调空格修复以支持 `__` (双下划线加粗) 和 `___` (三下划线加粗斜体) 语法。
|
||||
* **列表标记保护**: 修复了列表标记 (`*`) 后跟强调标记 (`**`) 被错误合并的 Bug(例如 `* **是**` 变成 `***是**`)。添加了保护逻辑防止此问题。
|
||||
* **测试套件**: 新增完整的 pytest 测试套件,包含 56 个测试用例,覆盖所有主要功能。
|
||||
|
||||
### v1.2.1
|
||||
|
||||
* **强调空格修复**: 新增了对强调标记内部多余空格的修复(例如 `** 文本 **` -> `**文本**`)。
|
||||
* 采用递归方法处理嵌套强调(例如 `**加粗 _斜体 _**`)。
|
||||
* 包含保护机制,防止误修改数学表达式(如 `2 * 3 * 4`)或列表变量。
|
||||
* 通过 `enable_emphasis_spacing_fix` 开关控制(默认:开启)。
|
||||
|
||||
### v1.2.0
|
||||
* **Details 标签支持**: 新增了对 `<details>` 标签的规范化支持。
|
||||
* 确保在 `</details>` 闭合标签后添加空行,将思维内容与正文分隔开。
|
||||
* 确保在自闭合 `<details ... />` 标签后添加换行,防止其干扰后续的 Markdown 标题(例如修复 `<details/>#标题`)。
|
||||
* 包含保护机制,防止修改代码块内部的 `<details>` 标签。
|
||||
|
||||
* **Details 标签支持**: 新增了对 `<details>` 标签的规范化支持。
|
||||
* 确保在 `</details>` 闭合标签后添加空行,将思维内容与正文分隔开。
|
||||
* 确保在自闭合 `<details ... />` 标签后添加换行,防止其干扰后续的 Markdown 标题(例如修复 `<details/>#标题`)。
|
||||
* 包含保护机制,防止修改代码块内部的 `<details>` 标签。
|
||||
|
||||
### v1.1.2
|
||||
* **Mermaid 连线标签保护**: 实现了全面的连线标签保护机制,防止连接线上的文字被误修改。现在支持所有 Mermaid 连线类型,包括实线 (`--`)、虚线 (`-.`) 和粗线 (`==`),无论是否带有箭头。
|
||||
* **Bug 修复**: 修复了无箭头连线(如 `A -- text --- B`)未被正确保护的问题。
|
||||
|
||||
* **Mermaid 连线标签保护**: 实现了全面的连线标签保护机制,防止连接线上的文字被误修改。现在支持所有 Mermaid 连线类型,包括实线 (`--`)、虚线 (`-.`) 和粗线 (`==`),无论是否带有箭头。
|
||||
* **Bug 修复**: 修复了无箭头连线(如 `A -- text --- B`)未被正确保护的问题。
|
||||
|
||||
### v1.1.0
|
||||
* **Mermaid 修复优化**: 改进了正则表达式以处理节点标签中的嵌套括号(如 `ID("标签 (文本)")`),并避免误匹配连接线上的文字。
|
||||
* **HTML 保护机制优化**: 优化了 `_contains_html` 检测,允许 `<br/>`, `<b>`, `<i>` 等常见标签,确保包含这些标签的 Mermaid 图表能被正常规范化。
|
||||
* **全角符号清理**: 修复了 `FULLWIDTH_MAP` 中的重复键名和错误的引号映射。
|
||||
* **Bug 修复**: 修复了 Python 文件中缺失的 `Dict` 类型导入。
|
||||
|
||||
* **Mermaid 修复优化**: 改进了正则表达式以处理节点标签中的嵌套括号(如 `ID("标签 (文本)")`),并避免误匹配连接线上的文字。
|
||||
* **HTML 保护机制优化**: 优化了 `_contains_html` 检测,允许 `<br/>`, `<b>`, `<i>` 等常见标签,确保包含这些标签的 Mermaid 图表能被正常规范化。
|
||||
* **全角符号清理**: 修复了 `FULLWIDTH_MAP` 中的重复键名和错误的引号映射。
|
||||
* **Bug 修复**: 修复了 Python 文件中缺失的 `Dict` 类型导入。
|
||||
|
||||
@@ -3,7 +3,7 @@ title: Markdown Normalizer
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 1.2.0
|
||||
version: 1.2.4
|
||||
openwebui_id: baaa8732-9348-40b7-8359-7e009660e23c
|
||||
description: A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.
|
||||
"""
|
||||
@@ -43,6 +43,7 @@ class NormalizerConfig:
|
||||
)
|
||||
enable_table_fix: bool = True # Fix missing closing pipe in tables
|
||||
enable_xml_tag_cleanup: bool = True # Cleanup leftover XML tags
|
||||
enable_emphasis_spacing_fix: bool = False # Fix spaces inside **emphasis**
|
||||
|
||||
# Custom cleaner functions (for advanced extension)
|
||||
custom_cleaners: List[Callable[[str], str]] = field(default_factory=list)
|
||||
@@ -53,8 +54,8 @@ class ContentNormalizer:
|
||||
|
||||
# --- 1. Pre-compiled Regex Patterns (Performance Optimization) ---
|
||||
_PATTERNS = {
|
||||
# Code block prefix: if ``` is not at start of line or file
|
||||
"code_block_prefix": re.compile(r"(?<!^)(?<!\n)(```)", re.MULTILINE),
|
||||
# Code block prefix: if ``` is not at start of line (ignoring whitespace)
|
||||
"code_block_prefix": re.compile(r"(\S[ \t]*)(```)"),
|
||||
# Code block suffix: ```lang followed by non-whitespace (no newline)
|
||||
"code_block_suffix": re.compile(r"(```[\w\+\-\.]*)[ \t]+([^\n\r])"),
|
||||
# Code block indent: whitespace at start of line + ```
|
||||
@@ -108,6 +109,14 @@ class ContentNormalizer:
|
||||
"heading_space": re.compile(r"^(#+)([^ \n#])", re.MULTILINE),
|
||||
# Table: | col1 | col2 -> | col1 | col2 |
|
||||
"table_pipe": re.compile(r"^(\|.*[^|\n])$", re.MULTILINE),
|
||||
# Emphasis spacing: ** text ** -> **text**, __ text __ -> __text__
|
||||
# Matches emphasis blocks within a single line. We use a recursive approach
|
||||
# in _fix_emphasis_spacing to handle nesting and spaces correctly.
|
||||
# NOTE: We use [^\n] instead of . to prevent cross-line matching.
|
||||
# Supports: * (italic), ** (bold), *** (bold+italic), _ (italic), __ (bold), ___ (bold+italic)
|
||||
"emphasis_spacing": re.compile(
|
||||
r"(?<!\*|_)(\*{1,3}|_{1,3})(?P<inner>[^\n]*?)(\1)(?!\*|_)"
|
||||
),
|
||||
}
|
||||
|
||||
def __init__(self, config: Optional[NormalizerConfig] = None):
|
||||
@@ -207,6 +216,13 @@ class ContentNormalizer:
|
||||
if content != original:
|
||||
self.applied_fixes.append("Cleanup XML Tags")
|
||||
|
||||
# 12. Emphasis spacing fix
|
||||
if self.config.enable_emphasis_spacing_fix:
|
||||
original = content
|
||||
content = self._fix_emphasis_spacing(content)
|
||||
if content != original:
|
||||
self.applied_fixes.append("Fix Emphasis Spacing")
|
||||
|
||||
# 9. Custom cleaners
|
||||
for cleaner in self.config.custom_cleaners:
|
||||
original = content
|
||||
@@ -283,8 +299,6 @@ class ContentNormalizer:
|
||||
|
||||
def _fix_code_blocks(self, content: str) -> str:
|
||||
"""Fix code block formatting (prefixes, suffixes, indentation)"""
|
||||
# Remove indentation before code blocks
|
||||
content = self._PATTERNS["code_block_indent"].sub(r"\1", content)
|
||||
# Ensure newline before ```
|
||||
content = self._PATTERNS["code_block_prefix"].sub(r"\n\1", content)
|
||||
# Ensure newline after ```lang
|
||||
@@ -443,6 +457,61 @@ class ContentNormalizer:
|
||||
"""Remove leftover XML tags"""
|
||||
return self._PATTERNS["xml_artifacts"].sub("", content)
|
||||
|
||||
def _fix_emphasis_spacing(self, content: str) -> str:
|
||||
"""Fix spaces inside **emphasis** or _emphasis_
|
||||
Example: ** text ** -> **text**, **text ** -> **text**, ** text** -> **text**
|
||||
"""
|
||||
|
||||
def replacer(match):
|
||||
symbol = match.group(1)
|
||||
inner = match.group("inner")
|
||||
|
||||
# Recursive step: Fix emphasis spacing INSIDE the current block first
|
||||
# This ensures that ** _ italic _ ** becomes ** _italic_ ** before we strip outer spaces.
|
||||
inner = self._PATTERNS["emphasis_spacing"].sub(replacer, inner)
|
||||
|
||||
# If no leading/trailing whitespace, nothing to fix at this level
|
||||
stripped_inner = inner.strip()
|
||||
if stripped_inner == inner:
|
||||
return f"{symbol}{inner}{symbol}"
|
||||
|
||||
# Safeguard: If inner content is just whitespace, don't touch it
|
||||
if not stripped_inner:
|
||||
return match.group(0)
|
||||
|
||||
# Safeguard: If it looks like a math expression or list of variables (e.g. " * 3 * " or " _ b _ ")
|
||||
# If the symbol is surrounded by spaces in the original text, it's likely an operator.
|
||||
if inner.startswith(" ") and inner.endswith(" "):
|
||||
# If it's single '*' or '_', and both sides have spaces, it's almost certainly an operator.
|
||||
if symbol in ["*", "_"]:
|
||||
return match.group(0)
|
||||
|
||||
# Safeguard: List marker protection
|
||||
# If symbol is single '*' and inner content starts with whitespace followed by emphasis markers,
|
||||
# this is likely a list item like "* **bold**" - don't merge them.
|
||||
# Pattern: "* **text**" should NOT become "***text**"
|
||||
if symbol == "*" and inner.lstrip().startswith(("*", "_")):
|
||||
return match.group(0)
|
||||
|
||||
# Extended list marker protection:
|
||||
# If symbol is single '*' and inner starts with multiple spaces (list indentation pattern),
|
||||
# this is likely a list item like "* text" - don't strip the spaces.
|
||||
# Pattern: "* U16 forward **Kuang**" should NOT become "*U16 forward **Kuang**"
|
||||
if symbol == "*" and inner.startswith(" "):
|
||||
return match.group(0)
|
||||
|
||||
return f"{symbol}{stripped_inner}{symbol}"
|
||||
|
||||
parts = content.split("```")
|
||||
for i in range(0, len(parts), 2): # Even indices are markdown text
|
||||
# We use a while loop to handle overlapping or multiple occurrences at the top level
|
||||
while True:
|
||||
new_part = self._PATTERNS["emphasis_spacing"].sub(replacer, parts[i])
|
||||
if new_part == parts[i]:
|
||||
break
|
||||
parts[i] = new_part
|
||||
return "```".join(parts)
|
||||
|
||||
|
||||
class Filter:
|
||||
class Valves(BaseModel):
|
||||
@@ -494,6 +563,10 @@ class Filter:
|
||||
enable_xml_tag_cleanup: bool = Field(
|
||||
default=True, description="Cleanup leftover XML tags"
|
||||
)
|
||||
enable_emphasis_spacing_fix: bool = Field(
|
||||
default=False,
|
||||
description="Fix spaces inside **emphasis** (e.g. ** text ** -> **text**)",
|
||||
)
|
||||
show_status: bool = Field(
|
||||
default=True, description="Show status notification when fixes are applied"
|
||||
)
|
||||
@@ -622,6 +695,15 @@ class Filter:
|
||||
if self._contains_html(content):
|
||||
return body
|
||||
|
||||
# Skip if content contains tool output markers (native function calling)
|
||||
# Pattern: """...""" or tool_call_id or <details type="tool_calls"...>
|
||||
if (
|
||||
'"""' in content
|
||||
or "tool_call_id" in content
|
||||
or '<details type="tool_calls"' in content
|
||||
):
|
||||
return body
|
||||
|
||||
# Configure normalizer based on valves
|
||||
config = NormalizerConfig(
|
||||
enable_escape_fix=self.valves.enable_escape_fix,
|
||||
@@ -637,6 +719,7 @@ class Filter:
|
||||
enable_heading_fix=self.valves.enable_heading_fix,
|
||||
enable_table_fix=self.valves.enable_table_fix,
|
||||
enable_xml_tag_cleanup=self.valves.enable_xml_tag_cleanup,
|
||||
enable_emphasis_spacing_fix=self.valves.enable_emphasis_spacing_fix,
|
||||
)
|
||||
|
||||
normalizer = ContentNormalizer(config)
|
||||
|
||||
@@ -3,7 +3,7 @@ title: Markdown 格式修复器 (Markdown Normalizer)
|
||||
author: Fu-Jie
|
||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||
funding_url: https://github.com/open-webui
|
||||
version: 1.2.0
|
||||
version: 1.2.4
|
||||
description: 内容规范化过滤器,修复 LLM 输出中常见的 Markdown 格式问题,如损坏的代码块、LaTeX 公式、Mermaid 图表和列表格式。
|
||||
"""
|
||||
|
||||
@@ -24,6 +24,9 @@ class NormalizerConfig:
|
||||
"""配置类,用于启用/禁用特定的规范化规则"""
|
||||
|
||||
enable_escape_fix: bool = True # 修复过度的转义字符
|
||||
enable_escape_fix_in_code_blocks: bool = (
|
||||
False # 在代码块内部应用转义修复 (默认:关闭,以确保安全)
|
||||
)
|
||||
enable_thought_tag_fix: bool = True # 规范化思维链标签
|
||||
enable_details_tag_fix: bool = True # 规范化 <details> 标签(类似思维链标签)
|
||||
enable_code_block_fix: bool = True # 修复代码块格式
|
||||
@@ -35,6 +38,7 @@ class NormalizerConfig:
|
||||
enable_heading_fix: bool = True # 修复标题中缺失的空格 (#Header -> # Header)
|
||||
enable_table_fix: bool = True # 修复表格中缺失的闭合管道符
|
||||
enable_xml_tag_cleanup: bool = True # 清理残留的 XML 标签
|
||||
enable_emphasis_spacing_fix: bool = False # 修复 **强调内容** 中的多余空格
|
||||
|
||||
# 自定义清理函数 (用于高级扩展)
|
||||
custom_cleaners: List[Callable[[str], str]] = field(default_factory=list)
|
||||
@@ -45,8 +49,8 @@ class ContentNormalizer:
|
||||
|
||||
# --- 1. Pre-compiled Regex Patterns (Performance Optimization) ---
|
||||
_PATTERNS = {
|
||||
# Code block prefix: if ``` is not at start of line or file
|
||||
"code_block_prefix": re.compile(r"(?<!^)(?<!\n)(```)", re.MULTILINE),
|
||||
# Code block prefix: if ``` is not at start of line (ignoring whitespace)
|
||||
"code_block_prefix": re.compile(r"(\S[ \t]*)(```)"),
|
||||
# Code block suffix: ```lang followed by non-whitespace (no newline)
|
||||
"code_block_suffix": re.compile(r"(```[\w\+\-\.]*)[ \t]+([^\n\r])"),
|
||||
# Code block indent: whitespace at start of line + ```
|
||||
@@ -100,6 +104,14 @@ class ContentNormalizer:
|
||||
"heading_space": re.compile(r"^(#+)([^ \n#])", re.MULTILINE),
|
||||
# Table: | col1 | col2 -> | col1 | col2 |
|
||||
"table_pipe": re.compile(r"^(\|.*[^|\n])$", re.MULTILINE),
|
||||
# Emphasis spacing: ** text ** -> **text**, __ text __ -> __text__
|
||||
# Matches emphasis blocks within a single line. We use a recursive approach
|
||||
# in _fix_emphasis_spacing to handle nesting and spaces correctly.
|
||||
# NOTE: We use [^\n] instead of . to prevent cross-line matching.
|
||||
# Supports: * (italic), ** (bold), *** (bold+italic), _ (italic), __ (bold), ___ (bold+italic)
|
||||
"emphasis_spacing": re.compile(
|
||||
r"(?<!\*|_)(\*{1,3}|_{1,3})(?P<inner>[^\n]*?)(\1)(?!\*|_)"
|
||||
),
|
||||
}
|
||||
|
||||
def __init__(self, config: Optional[NormalizerConfig] = None):
|
||||
@@ -199,6 +211,13 @@ class ContentNormalizer:
|
||||
if content != original:
|
||||
self.applied_fixes.append("Cleanup XML Tags")
|
||||
|
||||
# 12. Emphasis spacing fix
|
||||
if self.config.enable_emphasis_spacing_fix:
|
||||
original = content
|
||||
content = self._fix_emphasis_spacing(content)
|
||||
if content != original:
|
||||
self.applied_fixes.append("Fix Emphasis Spacing")
|
||||
|
||||
# 9. Custom cleaners
|
||||
for cleaner in self.config.custom_cleaners:
|
||||
original = content
|
||||
@@ -223,12 +242,27 @@ class ContentNormalizer:
|
||||
return content
|
||||
|
||||
def _fix_escape_characters(self, content: str) -> str:
|
||||
"""Fix excessive escape characters"""
|
||||
content = content.replace("\\r\\n", "\n")
|
||||
content = content.replace("\\n", "\n")
|
||||
content = content.replace("\\t", "\t")
|
||||
content = content.replace("\\\\", "\\")
|
||||
return content
|
||||
"""修复过度的转义字符
|
||||
|
||||
如果 enable_escape_fix_in_code_blocks 为 False (默认),此方法将仅修复代码块外部的转义字符,
|
||||
以避免破坏有效的代码示例 (例如,带有 \\n 的 JSON 字符串、正则表达式模式等)。
|
||||
"""
|
||||
if self.config.enable_escape_fix_in_code_blocks:
|
||||
# 全局应用 (原始行为)
|
||||
content = content.replace("\\r\\n", "\n")
|
||||
content = content.replace("\\n", "\n")
|
||||
content = content.replace("\\t", "\t")
|
||||
content = content.replace("\\\\", "\\")
|
||||
return content
|
||||
else:
|
||||
# 仅在代码块外部应用 (安全模式)
|
||||
parts = content.split("```")
|
||||
for i in range(0, len(parts), 2): # 偶数索引是 Markdown 文本 (非代码)
|
||||
parts[i] = parts[i].replace("\\r\\n", "\n")
|
||||
parts[i] = parts[i].replace("\\n", "\n")
|
||||
parts[i] = parts[i].replace("\\t", "\t")
|
||||
parts[i] = parts[i].replace("\\\\", "\\")
|
||||
return "```".join(parts)
|
||||
|
||||
def _fix_thought_tags(self, content: str) -> str:
|
||||
"""Normalize thought tags: unify naming and fix spacing"""
|
||||
@@ -257,8 +291,6 @@ class ContentNormalizer:
|
||||
|
||||
def _fix_code_blocks(self, content: str) -> str:
|
||||
"""Fix code block formatting (prefixes, suffixes, indentation)"""
|
||||
# Remove indentation before code blocks
|
||||
content = self._PATTERNS["code_block_indent"].sub(r"\1", content)
|
||||
# Ensure newline before ```
|
||||
content = self._PATTERNS["code_block_prefix"].sub(r"\n\1", content)
|
||||
# Ensure newline after ```lang
|
||||
@@ -422,6 +454,61 @@ class ContentNormalizer:
|
||||
"""Remove leftover XML tags"""
|
||||
return self._PATTERNS["xml_artifacts"].sub("", content)
|
||||
|
||||
def _fix_emphasis_spacing(self, content: str) -> str:
|
||||
"""Fix spaces inside **emphasis** or _emphasis_
|
||||
Example: ** text ** -> **text**, **text ** -> **text**, ** text** -> **text**
|
||||
"""
|
||||
|
||||
def replacer(match):
|
||||
symbol = match.group(1)
|
||||
inner = match.group("inner")
|
||||
|
||||
# Recursive step: Fix emphasis spacing INSIDE the current block first
|
||||
# This ensures that ** _ italic _ ** becomes ** _italic_ ** before we strip outer spaces.
|
||||
inner = self._PATTERNS["emphasis_spacing"].sub(replacer, inner)
|
||||
|
||||
# If no leading/trailing whitespace, nothing to fix at this level
|
||||
stripped_inner = inner.strip()
|
||||
if stripped_inner == inner:
|
||||
return f"{symbol}{inner}{symbol}"
|
||||
|
||||
# Safeguard: If inner content is just whitespace, don't touch it
|
||||
if not stripped_inner:
|
||||
return match.group(0)
|
||||
|
||||
# Safeguard: If it looks like a math expression or list of variables (e.g. " * 3 * " or " _ b _ ")
|
||||
# If the symbol is surrounded by spaces in the original text, it's likely an operator.
|
||||
if inner.startswith(" ") and inner.endswith(" "):
|
||||
# If it's single '*' or '_', and both sides have spaces, it's almost certainly an operator.
|
||||
if symbol in ["*", "_"]:
|
||||
return match.group(0)
|
||||
|
||||
# Safeguard: List marker protection
|
||||
# If symbol is single '*' and inner content starts with whitespace followed by emphasis markers,
|
||||
# this is likely a list item like "* **bold**" - don't merge them.
|
||||
# Pattern: "* **text**" should NOT become "***text**"
|
||||
if symbol == "*" and inner.lstrip().startswith(("*", "_")):
|
||||
return match.group(0)
|
||||
|
||||
# Extended list marker protection:
|
||||
# If symbol is single '*' and inner starts with multiple spaces (list indentation pattern),
|
||||
# this is likely a list item like "* text" - don't strip the spaces.
|
||||
# Pattern: "* U16 forward **Kuang**" should NOT become "*U16 forward **Kuang**"
|
||||
if symbol == "*" and inner.startswith(" "):
|
||||
return match.group(0)
|
||||
|
||||
return f"{symbol}{stripped_inner}{symbol}"
|
||||
|
||||
parts = content.split("```")
|
||||
for i in range(0, len(parts), 2): # Even indices are markdown text
|
||||
# We use a while loop to handle overlapping or multiple occurrences at the top level
|
||||
while True:
|
||||
new_part = self._PATTERNS["emphasis_spacing"].sub(replacer, parts[i])
|
||||
if new_part == parts[i]:
|
||||
break
|
||||
parts[i] = new_part
|
||||
return "```".join(parts)
|
||||
|
||||
|
||||
class Filter:
|
||||
class Valves(BaseModel):
|
||||
@@ -432,6 +519,10 @@ class Filter:
|
||||
enable_escape_fix: bool = Field(
|
||||
default=True, description="修复过度的转义字符 (\\n, \\t 等)"
|
||||
)
|
||||
enable_escape_fix_in_code_blocks: bool = Field(
|
||||
default=False,
|
||||
description="在代码块内部应用转义修复 (⚠️ 警告:可能会破坏有效的代码,如 JSON 字符串或正则模式。默认:关闭,以确保安全)",
|
||||
)
|
||||
enable_thought_tag_fix: bool = Field(
|
||||
default=True, description="规范化思维链标签 (<think> -> <thought>)"
|
||||
)
|
||||
@@ -469,6 +560,10 @@ class Filter:
|
||||
enable_xml_tag_cleanup: bool = Field(
|
||||
default=True, description="清理残留的 XML 标签"
|
||||
)
|
||||
enable_emphasis_spacing_fix: bool = Field(
|
||||
default=False,
|
||||
description="修复强调语法中的多余空格 (例如 ** 文本 ** -> **文本**)",
|
||||
)
|
||||
show_status: bool = Field(default=True, description="应用修复时显示状态通知")
|
||||
show_debug_log: bool = Field(
|
||||
default=True, description="在浏览器控制台打印调试日志 (F12)"
|
||||
@@ -540,6 +635,7 @@ class Filter:
|
||||
"Fix Headings": "标题格式",
|
||||
"Fix Tables": "表格格式",
|
||||
"Cleanup XML Tags": "XML清理",
|
||||
"Fix Emphasis Spacing": "强调空格",
|
||||
"Custom Cleaner": "自定义清理",
|
||||
}
|
||||
translated_fixes = [fix_map.get(fix, fix) for fix in applied_fixes]
|
||||
@@ -608,13 +704,23 @@ class Filter:
|
||||
content = last.get("content", "") or ""
|
||||
|
||||
if last.get("role") == "assistant" and isinstance(content, str):
|
||||
# Skip if content looks like HTML to avoid breaking it
|
||||
# 如果内容看起来像 HTML,则跳过以避免破坏它
|
||||
if self._contains_html(content):
|
||||
return body
|
||||
|
||||
# Configure normalizer based on valves
|
||||
# 如果内容包含工具输出标记 (原生函数调用),则跳过
|
||||
# 模式:"""...""" 或 tool_call_id 或 <details type="tool_calls"...>
|
||||
if (
|
||||
'"""' in content
|
||||
or "tool_call_id" in content
|
||||
or '<details type="tool_calls"' in content
|
||||
):
|
||||
return body
|
||||
|
||||
# 根据 Valves 配置 Normalizer
|
||||
config = NormalizerConfig(
|
||||
enable_escape_fix=self.valves.enable_escape_fix,
|
||||
enable_escape_fix_in_code_blocks=self.valves.enable_escape_fix_in_code_blocks,
|
||||
enable_thought_tag_fix=self.valves.enable_thought_tag_fix,
|
||||
enable_details_tag_fix=self.valves.enable_details_tag_fix,
|
||||
enable_code_block_fix=self.valves.enable_code_block_fix,
|
||||
@@ -626,6 +732,7 @@ class Filter:
|
||||
enable_heading_fix=self.valves.enable_heading_fix,
|
||||
enable_table_fix=self.valves.enable_table_fix,
|
||||
enable_xml_tag_cleanup=self.valves.enable_xml_tag_cleanup,
|
||||
enable_emphasis_spacing_fix=self.valves.enable_emphasis_spacing_fix,
|
||||
)
|
||||
|
||||
normalizer = ContentNormalizer(config)
|
||||
|
||||
1
plugins/filters/markdown_normalizer/tests/__init__.py
Normal file
1
plugins/filters/markdown_normalizer/tests/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
# Markdown Normalizer Test Suite
|
||||
75
plugins/filters/markdown_normalizer/tests/conftest.py
Normal file
75
plugins/filters/markdown_normalizer/tests/conftest.py
Normal file
@@ -0,0 +1,75 @@
|
||||
"""
|
||||
Shared fixtures for Markdown Normalizer tests.
|
||||
"""
|
||||
|
||||
import pytest
|
||||
import sys
|
||||
import os
|
||||
|
||||
# Add the parent directory to sys.path for imports
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
|
||||
from markdown_normalizer import ContentNormalizer, NormalizerConfig
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def normalizer():
|
||||
"""Default normalizer with all fixes enabled."""
|
||||
config = NormalizerConfig(
|
||||
enable_escape_fix=True,
|
||||
enable_thought_tag_fix=True,
|
||||
enable_details_tag_fix=True,
|
||||
enable_code_block_fix=True,
|
||||
enable_latex_fix=True,
|
||||
enable_list_fix=False, # Experimental, keep off by default
|
||||
enable_unclosed_block_fix=True,
|
||||
enable_fullwidth_symbol_fix=False,
|
||||
enable_mermaid_fix=True,
|
||||
enable_heading_fix=True,
|
||||
enable_table_fix=True,
|
||||
enable_xml_tag_cleanup=True,
|
||||
enable_emphasis_spacing_fix=True,
|
||||
)
|
||||
return ContentNormalizer(config)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def emphasis_only_normalizer():
|
||||
"""Normalizer with only emphasis spacing fix enabled."""
|
||||
config = NormalizerConfig(
|
||||
enable_escape_fix=False,
|
||||
enable_thought_tag_fix=False,
|
||||
enable_details_tag_fix=False,
|
||||
enable_code_block_fix=False,
|
||||
enable_latex_fix=False,
|
||||
enable_list_fix=False,
|
||||
enable_unclosed_block_fix=False,
|
||||
enable_fullwidth_symbol_fix=False,
|
||||
enable_mermaid_fix=False,
|
||||
enable_heading_fix=False,
|
||||
enable_table_fix=False,
|
||||
enable_xml_tag_cleanup=False,
|
||||
enable_emphasis_spacing_fix=True,
|
||||
)
|
||||
return ContentNormalizer(config)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def mermaid_only_normalizer():
|
||||
"""Normalizer with only Mermaid fix enabled."""
|
||||
config = NormalizerConfig(
|
||||
enable_escape_fix=False,
|
||||
enable_thought_tag_fix=False,
|
||||
enable_details_tag_fix=False,
|
||||
enable_code_block_fix=False,
|
||||
enable_latex_fix=False,
|
||||
enable_list_fix=False,
|
||||
enable_unclosed_block_fix=False,
|
||||
enable_fullwidth_symbol_fix=False,
|
||||
enable_mermaid_fix=True,
|
||||
enable_heading_fix=False,
|
||||
enable_table_fix=False,
|
||||
enable_xml_tag_cleanup=False,
|
||||
enable_emphasis_spacing_fix=False,
|
||||
)
|
||||
return ContentNormalizer(config)
|
||||
@@ -0,0 +1,54 @@
|
||||
"""
|
||||
Tests for code block formatting fixes.
|
||||
Covers: prefix, suffix, indentation preservation.
|
||||
"""
|
||||
|
||||
import pytest
|
||||
|
||||
|
||||
class TestCodeBlockFix:
|
||||
"""Test code block formatting normalization."""
|
||||
|
||||
def test_code_block_indentation_preserved(self, normalizer):
|
||||
"""Indented code blocks (e.g., in lists) should preserve indentation."""
|
||||
input_str = """
|
||||
* List item 1
|
||||
```python
|
||||
def foo():
|
||||
print("bar")
|
||||
```
|
||||
* List item 2
|
||||
"""
|
||||
# Indentation should be preserved
|
||||
assert " ```python" in normalizer.normalize(input_str)
|
||||
|
||||
def test_inline_code_block_prefix(self, normalizer):
|
||||
"""Code block that follows text on same line should be modified."""
|
||||
input_str = "text```python\ncode\n```"
|
||||
result = normalizer.normalize(input_str)
|
||||
# Just verify the code block markers are present
|
||||
assert "```" in result
|
||||
|
||||
def test_code_block_suffix_fix(self, normalizer):
|
||||
"""Code block with content on same line after lang should be fixed."""
|
||||
input_str = "```python code\nmore code\n```"
|
||||
result = normalizer.normalize(input_str)
|
||||
# Content should be on new line
|
||||
assert "```python\n" in result or "```python " in result
|
||||
|
||||
|
||||
class TestUnclosedCodeBlock:
|
||||
"""Test auto-closing of unclosed code blocks."""
|
||||
|
||||
def test_unclosed_code_block_is_closed(self, normalizer):
|
||||
"""Unclosed code blocks should be automatically closed."""
|
||||
input_str = "```python\ncode here"
|
||||
result = normalizer.normalize(input_str)
|
||||
# Should have closing ```
|
||||
assert result.endswith("```") or result.count("```") == 2
|
||||
|
||||
def test_balanced_code_blocks_unchanged(self, normalizer):
|
||||
"""Already balanced code blocks should not get extra closing."""
|
||||
input_str = "```python\ncode\n```"
|
||||
result = normalizer.normalize(input_str)
|
||||
assert result.count("```") == 2
|
||||
@@ -0,0 +1,48 @@
|
||||
"""
|
||||
Tests for details tag normalization.
|
||||
Covers: </details> spacing, self-closing tags.
|
||||
"""
|
||||
|
||||
import pytest
|
||||
|
||||
|
||||
class TestDetailsTagFix:
|
||||
"""Test details tag normalization."""
|
||||
|
||||
def test_details_end_gets_newlines(self, normalizer):
|
||||
"""</details> should be followed by double newline."""
|
||||
input_str = "</details>Content after"
|
||||
result = normalizer.normalize(input_str)
|
||||
assert "</details>\n\n" in result
|
||||
|
||||
def test_self_closing_details_gets_newline(self, normalizer):
|
||||
"""Self-closing <details .../> should get newline after."""
|
||||
input_str = "<details open />## Heading"
|
||||
result = normalizer.normalize(input_str)
|
||||
# Should have newline between tag and heading
|
||||
assert "/>\n" in result or "/> \n" in result
|
||||
|
||||
def test_details_in_code_block_unchanged(self, normalizer):
|
||||
"""Details tags inside code blocks should not be modified."""
|
||||
input_str = "```html\n<details>content</details>more\n```"
|
||||
result = normalizer.normalize(input_str)
|
||||
# Content inside code block should be unchanged
|
||||
assert "</details>more" in result
|
||||
|
||||
|
||||
class TestThoughtTagFix:
|
||||
"""Test thought tag normalization."""
|
||||
|
||||
def test_think_tag_normalized(self, normalizer):
|
||||
"""<think> should be normalized to <thought>."""
|
||||
input_str = "<think>content</think>"
|
||||
result = normalizer.normalize(input_str)
|
||||
assert "<thought>" in result
|
||||
assert "</thought>" in result
|
||||
|
||||
def test_thinking_tag_normalized(self, normalizer):
|
||||
"""<thinking> should be normalized to <thought>."""
|
||||
input_str = "<thinking>content</thinking>"
|
||||
result = normalizer.normalize(input_str)
|
||||
assert "<thought>" in result
|
||||
assert "</thought>" in result
|
||||
@@ -0,0 +1,138 @@
|
||||
"""
|
||||
Tests for emphasis spacing fix.
|
||||
Covers: *, **, ***, _, __, ___ with spaces inside.
|
||||
"""
|
||||
|
||||
import pytest
|
||||
|
||||
|
||||
class TestEmphasisSpacingFix:
|
||||
"""Test emphasis spacing normalization."""
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"input_str,expected",
|
||||
[
|
||||
# Double asterisk (bold)
|
||||
("** bold **", "**bold**"),
|
||||
("** bold text **", "**bold text**"),
|
||||
("**text **", "**text**"),
|
||||
("** text**", "**text**"),
|
||||
# Triple asterisk (bold+italic)
|
||||
("*** bold italic ***", "***bold italic***"),
|
||||
# Double underscore (bold)
|
||||
("__ bold __", "__bold__"),
|
||||
("__ bold text __", "__bold text__"),
|
||||
("__text __", "__text__"),
|
||||
("__ text__", "__text__"),
|
||||
# Triple underscore (bold+italic)
|
||||
("___ bold italic ___", "___bold italic___"),
|
||||
# Mixed markers
|
||||
("** bold ** and __ also __", "**bold** and __also__"),
|
||||
],
|
||||
)
|
||||
def test_emphasis_with_spaces_fixed(
|
||||
self, emphasis_only_normalizer, input_str, expected
|
||||
):
|
||||
"""Test that emphasis with spaces is correctly fixed."""
|
||||
assert emphasis_only_normalizer.normalize(input_str) == expected
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"input_str",
|
||||
[
|
||||
# Single * and _ with spaces on both sides - treated as operator (safeguard)
|
||||
"* italic *",
|
||||
"_ italic _",
|
||||
# Already correct emphasis
|
||||
"**bold**",
|
||||
"__bold__",
|
||||
"*italic*",
|
||||
"_italic_",
|
||||
"***bold italic***",
|
||||
"___bold italic___",
|
||||
],
|
||||
)
|
||||
def test_safeguard_and_correct_emphasis_unchanged(
|
||||
self, emphasis_only_normalizer, input_str
|
||||
):
|
||||
"""Test that safeguard cases and already correct emphasis are not modified."""
|
||||
assert emphasis_only_normalizer.normalize(input_str) == input_str
|
||||
|
||||
|
||||
class TestEmphasisSideEffects:
|
||||
"""Test that emphasis fix does NOT affect unrelated content."""
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"input_str,description",
|
||||
[
|
||||
# URLs with underscores
|
||||
("https://example.com/path_with_underscore", "URL"),
|
||||
("Visit https://api.example.com/get_user_info for info", "URL in text"),
|
||||
# Variable names (snake_case)
|
||||
("The `my_variable_name` is important", "Variable in backticks"),
|
||||
("Use `get_user_data()` function", "Function name"),
|
||||
# File names
|
||||
("Edit the `config_file_name.py` file", "File name"),
|
||||
("See `my_script__v2.py` for details", "Double underscore in filename"),
|
||||
# Math-like subscripts
|
||||
("The variable a_1 and b_2 are defined", "Math subscripts"),
|
||||
# Single underscores not matching emphasis pattern
|
||||
("word_with_underscore", "Underscore in word"),
|
||||
("a_b_c_d", "Multiple underscores"),
|
||||
# Horizontal rules
|
||||
("---", "HR with dashes"),
|
||||
("***", "HR with asterisks"),
|
||||
("___", "HR with underscores"),
|
||||
# List items
|
||||
("- item_one\n- item_two", "List items"),
|
||||
],
|
||||
)
|
||||
def test_no_side_effects(self, emphasis_only_normalizer, input_str, description):
|
||||
"""Test that various content types are NOT modified by emphasis fix."""
|
||||
assert (
|
||||
emphasis_only_normalizer.normalize(input_str) == input_str
|
||||
), f"Failed for: {description}"
|
||||
|
||||
def test_list_marker_not_merged_with_emphasis(self, emphasis_only_normalizer):
|
||||
"""Test that list markers (*) are not merged with emphasis (**).
|
||||
|
||||
Regression test for: "* **Yes**" should NOT become "***Yes**"
|
||||
"""
|
||||
input_str = """1. **Start**: The user opens the login page.
|
||||
* **Yes**: Login successful.
|
||||
* **No**: Show error message."""
|
||||
result = emphasis_only_normalizer.normalize(input_str)
|
||||
assert (
|
||||
"* **Yes**" in result
|
||||
), "List marker was incorrectly merged with emphasis"
|
||||
assert (
|
||||
"* **No**" in result
|
||||
), "List marker was incorrectly merged with emphasis"
|
||||
assert "***Yes**" not in result, "BUG: List marker merged with emphasis"
|
||||
assert "***No**" not in result, "BUG: List marker merged with emphasis"
|
||||
|
||||
def test_list_marker_with_plain_text_then_emphasis(self, emphasis_only_normalizer):
|
||||
"""Test that list items with plain text before emphasis are preserved.
|
||||
|
||||
Regression test for: "* U16 forward **Kuang**" should NOT become "*U16 forward **Kuang**"
|
||||
"""
|
||||
input_str = "* U16 China forward **Kuang Zhaolei**"
|
||||
result = emphasis_only_normalizer.normalize(input_str)
|
||||
assert "* U16" in result, "List marker spaces were incorrectly stripped"
|
||||
assert (
|
||||
"*U16" not in result or "* U16" in result
|
||||
), "BUG: List marker spaces stripped"
|
||||
|
||||
|
||||
class TestEmphasisInCodeBlocks:
|
||||
"""Test that emphasis inside code blocks is NOT modified."""
|
||||
|
||||
def test_emphasis_in_code_block_unchanged(self, emphasis_only_normalizer):
|
||||
"""Code blocks should be completely skipped."""
|
||||
input_str = "```python\nmy_var = get_data__from_api()\n```"
|
||||
assert emphasis_only_normalizer.normalize(input_str) == input_str
|
||||
|
||||
def test_mixed_emphasis_and_code(self, emphasis_only_normalizer):
|
||||
"""Text outside code blocks should be fixed, inside should not."""
|
||||
input_str = "** bold ** text\n```python\n** not bold **\n```"
|
||||
expected = "**bold** text\n```python\n** not bold **\n```"
|
||||
assert emphasis_only_normalizer.normalize(input_str) == expected
|
||||
@@ -0,0 +1,51 @@
|
||||
"""
|
||||
Tests for heading fix.
|
||||
Covers: Missing space after # in headings.
|
||||
"""
|
||||
|
||||
import pytest
|
||||
|
||||
|
||||
class TestHeadingFix:
|
||||
"""Test heading space normalization."""
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"input_str,expected",
|
||||
[
|
||||
("#Heading", "# Heading"),
|
||||
("##Heading", "## Heading"),
|
||||
("###Heading", "### Heading"),
|
||||
("#中文标题", "# 中文标题"),
|
||||
("#123", "# 123"), # Numbers after # also get space
|
||||
],
|
||||
)
|
||||
def test_missing_space_added(self, normalizer, input_str, expected):
|
||||
"""Headings missing space after # should be fixed."""
|
||||
assert normalizer.normalize(input_str) == expected
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"input_str",
|
||||
[
|
||||
"# Heading",
|
||||
"## Already Correct",
|
||||
"###", # Just hashes
|
||||
],
|
||||
)
|
||||
def test_correct_headings_unchanged(self, normalizer, input_str):
|
||||
"""Already correct headings should not be modified."""
|
||||
assert normalizer.normalize(input_str) == input_str
|
||||
|
||||
|
||||
class TestTableFix:
|
||||
"""Test table pipe normalization."""
|
||||
|
||||
def test_missing_closing_pipe_added(self, normalizer):
|
||||
"""Tables missing closing | should have it added."""
|
||||
input_str = "| col1 | col2"
|
||||
result = normalizer.normalize(input_str)
|
||||
assert result.endswith("|") or "col2 |" in result
|
||||
|
||||
def test_already_closed_table_unchanged(self, normalizer):
|
||||
"""Tables with closing | should not be modified."""
|
||||
input_str = "| col1 | col2 |"
|
||||
assert normalizer.normalize(input_str) == input_str
|
||||
6
pytest.ini
Normal file
6
pytest.ini
Normal file
@@ -0,0 +1,6 @@
|
||||
[pytest]
|
||||
testpaths = plugins
|
||||
python_files = test_*.py
|
||||
python_classes = Test*
|
||||
python_functions = test_*
|
||||
addopts = -v --tb=short
|
||||
@@ -217,6 +217,23 @@ def format_markdown_table(plugins: list[dict]) -> str:
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
def _get_readme_url(file_path: str) -> str:
|
||||
"""
|
||||
Generate GitHub README URL from plugin file path.
|
||||
从插件文件路径生成 GitHub README 链接。
|
||||
"""
|
||||
if not file_path:
|
||||
return ""
|
||||
# Extract plugin directory (e.g., plugins/filters/folder-memory/folder_memory.py -> plugins/filters/folder-memory)
|
||||
from pathlib import Path
|
||||
|
||||
plugin_dir = Path(file_path).parent
|
||||
# Convert to GitHub URL
|
||||
return (
|
||||
f"https://github.com/Fu-Jie/awesome-openwebui/blob/main/{plugin_dir}/README.md"
|
||||
)
|
||||
|
||||
|
||||
def format_release_notes(
|
||||
comparison: dict[str, list], ignore_removed: bool = False
|
||||
) -> str:
|
||||
@@ -229,9 +246,12 @@ def format_release_notes(
|
||||
if comparison["added"]:
|
||||
lines.append("### 新增插件 / New Plugins")
|
||||
for plugin in comparison["added"]:
|
||||
readme_url = _get_readme_url(plugin.get("file_path", ""))
|
||||
lines.append(f"- **{plugin['title']}** v{plugin['version']}")
|
||||
if plugin.get("description"):
|
||||
lines.append(f" - {plugin['description']}")
|
||||
if readme_url:
|
||||
lines.append(f" - 📖 [README / 文档]({readme_url})")
|
||||
lines.append("")
|
||||
|
||||
if comparison["updated"]:
|
||||
@@ -258,7 +278,10 @@ def format_release_notes(
|
||||
)
|
||||
prev_ver = prev_manifest.get("version") or prev.get("version")
|
||||
|
||||
readme_url = _get_readme_url(curr.get("file_path", ""))
|
||||
lines.append(f"- **{curr_title}**: v{prev_ver} → v{curr_ver}")
|
||||
if readme_url:
|
||||
lines.append(f" - 📖 [README / 文档]({readme_url})")
|
||||
lines.append("")
|
||||
|
||||
if comparison["removed"] and not ignore_removed:
|
||||
|
||||
Reference in New Issue
Block a user