Compare commits
44 Commits
v2026.01.1
...
v2026.01.2
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
813b019653 | ||
|
|
b0b1542939 | ||
|
|
15f19d8b8d | ||
|
|
82253b114c | ||
|
|
e0bfbf6dd4 | ||
|
|
4689e80e7a | ||
|
|
556e6c1c67 | ||
|
|
3ab84a526d | ||
|
|
bdce96f912 | ||
|
|
4811b99a4b | ||
|
|
fb2a64c07a | ||
|
|
e023e4f2e2 | ||
|
|
0b16b1e0f4 | ||
|
|
59073ad7ac | ||
|
|
8248644c45 | ||
|
|
f38e6394c9 | ||
|
|
0aaa529c6b | ||
|
|
b81a6562a1 | ||
|
|
c5b10db23a | ||
|
|
d16e444643 | ||
|
|
8202468099 | ||
|
|
766e8bd20f | ||
|
|
1214ab5a8c | ||
|
|
ebddbb25f8 | ||
|
|
59545e1110 | ||
|
|
500e090b11 | ||
|
|
a75ee555fa | ||
|
|
6a8c2164cd | ||
|
|
7f7efa325a | ||
|
|
9ba6cb08fc | ||
|
|
1872271a2d | ||
|
|
813b50864a | ||
|
|
b18cefe320 | ||
|
|
a54c359fcf | ||
|
|
8d83221a4a | ||
|
|
1879000720 | ||
|
|
ba92649a98 | ||
|
|
d2276dcaae | ||
|
|
25c9d20f3d | ||
|
|
0d853577df | ||
|
|
f91f3d8692 | ||
|
|
0f7cad8dfa | ||
|
|
db1a1e7ef0 | ||
|
|
e7de80a059 |
@@ -90,6 +90,9 @@ Reference: `.github/workflows/release.yml`
|
|||||||
- Action: Automatically updates the plugin code and metadata on OpenWebUI.com using `scripts/publish_plugin.py`.
|
- Action: Automatically updates the plugin code and metadata on OpenWebUI.com using `scripts/publish_plugin.py`.
|
||||||
- **Auto-Sync**: If a local plugin has no ID but matches an existing published plugin by **Title**, the script will automatically fetch the ID, update the local file, and proceed with the update.
|
- **Auto-Sync**: If a local plugin has no ID but matches an existing published plugin by **Title**, the script will automatically fetch the ID, update the local file, and proceed with the update.
|
||||||
- Requirement: `OPENWEBUI_API_KEY` secret must be set.
|
- Requirement: `OPENWEBUI_API_KEY` secret must be set.
|
||||||
|
- **README Link**: When announcing a release, always include the GitHub README URL for the plugin:
|
||||||
|
- Format: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/{type}/{name}/README.md`
|
||||||
|
- Example: `https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/README.md`
|
||||||
|
|
||||||
### Pull Request Check
|
### Pull Request Check
|
||||||
- Workflow: `.github/workflows/plugin-version-check.yml`
|
- Workflow: `.github/workflows/plugin-version-check.yml`
|
||||||
|
|||||||
19
.github/copilot-instructions.md
vendored
19
.github/copilot-instructions.md
vendored
@@ -100,13 +100,14 @@ description: 插件功能的简短描述。Brief description of plugin functiona
|
|||||||
| `author_url` | 作者主页链接 | `https://github.com/Fu-Jie/awesome-openwebui` |
|
| `author_url` | 作者主页链接 | `https://github.com/Fu-Jie/awesome-openwebui` |
|
||||||
| `funding_url` | 赞助/项目链接 | `https://github.com/open-webui` |
|
| `funding_url` | 赞助/项目链接 | `https://github.com/open-webui` |
|
||||||
| `version` | 语义化版本号 | `0.1.0`, `1.2.3` |
|
| `version` | 语义化版本号 | `0.1.0`, `1.2.3` |
|
||||||
| `icon_url` | 图标 (Base64 编码的 SVG) | 见下方图标规范 |
|
| `icon_url` | 图标 (Base64 编码的 SVG) | 仅 Action 插件**必须**提供。其他类型可选。 |
|
||||||
| `requirements` | 额外依赖 (仅 OpenWebUI 环境未安装的) | `python-docx==1.1.2` |
|
| `requirements` | 额外依赖 (仅 OpenWebUI 环境未安装的) | `python-docx==1.1.2` |
|
||||||
| `description` | 功能描述 | `将对话导出为 Word 文档` |
|
| `description` | 功能描述 | `将对话导出为 Word 文档` |
|
||||||
|
|
||||||
#### 图标规范 (Icon Guidelines)
|
#### 图标规范 (Icon Guidelines)
|
||||||
|
|
||||||
- 图标来源:从 [Lucide Icons](https://lucide.dev/icons/) 获取符合插件功能的图标
|
- 图标来源:从 [Lucide Icons](https://lucide.dev/icons/) 获取符合插件功能的图标
|
||||||
|
- 适用范围:Action 插件**必须**提供,其他插件可选
|
||||||
- 格式:Base64 编码的 SVG
|
- 格式:Base64 编码的 SVG
|
||||||
- 获取方法:从 Lucide 下载 SVG,然后使用 Base64 编码
|
- 获取方法:从 Lucide 下载 SVG,然后使用 Base64 编码
|
||||||
- 示例格式:
|
- 示例格式:
|
||||||
@@ -822,6 +823,22 @@ Filter 实例是**单例 (Singleton)**。
|
|||||||
|
|
||||||
#### Commit Message 规范
|
#### Commit Message 规范
|
||||||
使用 Conventional Commits 格式 (`feat`, `fix`, `docs`, etc.)。
|
使用 Conventional Commits 格式 (`feat`, `fix`, `docs`, etc.)。
|
||||||
|
**必须**在提交标题与正文中清晰描述变更内容,确保在 Release 页面可读且可追踪。
|
||||||
|
|
||||||
|
要求:
|
||||||
|
- 标题必须包含“做了什么”与影响范围(避免含糊词)。
|
||||||
|
- 正文必须列出关键变更点(1-3 条),与实际改动一一对应。
|
||||||
|
- 若影响用户或插件行为,必须在正文标明影响与迁移说明。
|
||||||
|
|
||||||
|
推荐格式:
|
||||||
|
- `feat(actions): add export settings panel`
|
||||||
|
- `fix(filters): handle empty metadata to avoid crash`
|
||||||
|
- `docs(plugins): update bilingual README structure`
|
||||||
|
|
||||||
|
正文示例:
|
||||||
|
- Add valves for export format selection
|
||||||
|
- Update README/README_CN to include What's New section
|
||||||
|
- Migration: default TITLE_SOURCE changed to chat_title
|
||||||
|
|
||||||
### 4. 🤖 Git Operations (Agent Rules)
|
### 4. 🤖 Git Operations (Agent Rules)
|
||||||
|
|
||||||
|
|||||||
29
README.md
29
README.md
@@ -10,28 +10,28 @@ A collection of enhancements, plugins, and prompts for [OpenWebUI](https://githu
|
|||||||
<!-- STATS_START -->
|
<!-- STATS_START -->
|
||||||
## 📊 Community Stats
|
## 📊 Community Stats
|
||||||
|
|
||||||
> 🕐 Auto-updated: 2026-01-19 18:11
|
> 🕐 Auto-updated: 2026-01-26 15:14
|
||||||
|
|
||||||
| 👤 Author | 👥 Followers | ⭐ Points | 🏆 Contributions |
|
| 👤 Author | 👥 Followers | ⭐ Points | 🏆 Contributions |
|
||||||
|:---:|:---:|:---:|:---:|
|
|:---:|:---:|:---:|:---:|
|
||||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **133** | **134** | **25** |
|
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **158** | **152** | **31** |
|
||||||
|
|
||||||
| 📝 Posts | ⬇️ Downloads | 👁️ Views | 👍 Upvotes | 💾 Saves |
|
| 📝 Posts | ⬇️ Downloads | 👁️ Views | 👍 Upvotes | 💾 Saves |
|
||||||
|:---:|:---:|:---:|:---:|:---:|
|
|:---:|:---:|:---:|:---:|:---:|
|
||||||
| **16** | **1792** | **21276** | **120** | **135** |
|
| **19** | **2388** | **27294** | **138** | **183** |
|
||||||
|
|
||||||
### 🔥 Top 6 Popular Plugins
|
### 🔥 Top 6 Popular Plugins
|
||||||
|
|
||||||
> 🕐 Auto-updated: 2026-01-19 18:11
|
> 🕐 Auto-updated: 2026-01-26 15:14
|
||||||
|
|
||||||
| Rank | Plugin | Version | Downloads | Views | Updated |
|
| Rank | Plugin | Version | Downloads | Views | Updated |
|
||||||
|:---:|------|:---:|:---:|:---:|:---:|
|
|:---:|------|:---:|:---:|:---:|:---:|
|
||||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 532 | 4822 | 2026-01-17 |
|
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 629 | 5600 | 2026-01-17 |
|
||||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 260 | 2514 | 2026-01-18 |
|
| 🥈 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 410 | 3621 | 2026-01-25 |
|
||||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 209 | 800 | 2026-01-07 |
|
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 255 | 1039 | 2026-01-07 |
|
||||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.1.3 | 180 | 1975 | 2026-01-17 |
|
| 4️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 229 | 1839 | 2026-01-17 |
|
||||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 158 | 1377 | 2026-01-17 |
|
| 5️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.2 | 227 | 2461 | 2026-01-21 |
|
||||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 138 | 2329 | 2026-01-17 |
|
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 165 | 2674 | 2026-01-17 |
|
||||||
|
|
||||||
*See full stats in [Community Stats Report](./docs/community-stats.md)*
|
*See full stats in [Community Stats Report](./docs/community-stats.md)*
|
||||||
<!-- STATS_END -->
|
<!-- STATS_END -->
|
||||||
@@ -43,6 +43,7 @@ A collection of enhancements, plugins, and prompts for [OpenWebUI](https://githu
|
|||||||
Located in the `plugins/` directory, containing Python-based enhancements:
|
Located in the `plugins/` directory, containing Python-based enhancements:
|
||||||
|
|
||||||
#### Actions
|
#### Actions
|
||||||
|
|
||||||
- **Smart Mind Map** (`smart-mind-map`): Generates interactive mind maps from text.
|
- **Smart Mind Map** (`smart-mind-map`): Generates interactive mind maps from text.
|
||||||
- **Smart Infographic** (`infographic`): Transforms text into professional infographics using AntV.
|
- **Smart Infographic** (`infographic`): Transforms text into professional infographics using AntV.
|
||||||
- **Flash Card** (`flash-card`): Quickly generates beautiful flashcards for learning.
|
- **Flash Card** (`flash-card`): Quickly generates beautiful flashcards for learning.
|
||||||
@@ -51,11 +52,18 @@ Located in the `plugins/` directory, containing Python-based enhancements:
|
|||||||
- **Export to Word** (`export_to_docx`): Exports chat history to Word documents.
|
- **Export to Word** (`export_to_docx`): Exports chat history to Word documents.
|
||||||
|
|
||||||
#### Filters
|
#### Filters
|
||||||
|
|
||||||
- **Async Context Compression** (`async-context-compression`): Optimizes token usage via context compression.
|
- **Async Context Compression** (`async-context-compression`): Optimizes token usage via context compression.
|
||||||
- **Context Enhancement** (`context_enhancement_filter`): Enhances chat context.
|
- **Context Enhancement** (`context_enhancement_filter`): Enhances chat context.
|
||||||
|
- **Folder Memory** (`folder-memory`): Automatically extracts project rules from conversations and injects them into the folder's system prompt.
|
||||||
- **Markdown Normalizer** (`markdown_normalizer`): Fixes common Markdown formatting issues in LLM outputs.
|
- **Markdown Normalizer** (`markdown_normalizer`): Fixes common Markdown formatting issues in LLM outputs.
|
||||||
|
|
||||||
|
#### Pipes
|
||||||
|
|
||||||
|
- **GitHub Copilot SDK** (`github-copilot-sdk`): Official GitHub Copilot SDK integration. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions.
|
||||||
|
|
||||||
#### Pipelines
|
#### Pipelines
|
||||||
|
|
||||||
- **MoE Prompt Refiner** (`moe_prompt_refiner`): Refines prompts for Mixture of Experts (MoE) summary requests to generate high-quality comprehensive reports.
|
- **MoE Prompt Refiner** (`moe_prompt_refiner`): Refines prompts for Mixture of Experts (MoE) summary requests to generate high-quality comprehensive reports.
|
||||||
|
|
||||||
### 🎯 Prompts
|
### 🎯 Prompts
|
||||||
@@ -100,6 +108,7 @@ This project is a collection of resources and does not require a Python environm
|
|||||||
### Contributing
|
### Contributing
|
||||||
|
|
||||||
If you have great prompts or plugins to share:
|
If you have great prompts or plugins to share:
|
||||||
|
|
||||||
1. Fork this repository.
|
1. Fork this repository.
|
||||||
2. Add your files to the appropriate `prompts/` or `plugins/` directory.
|
2. Add your files to the appropriate `prompts/` or `plugins/` directory.
|
||||||
3. Submit a Pull Request.
|
3. Submit a Pull Request.
|
||||||
|
|||||||
27
README_CN.md
27
README_CN.md
@@ -7,28 +7,28 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
|||||||
<!-- STATS_START -->
|
<!-- STATS_START -->
|
||||||
## 📊 社区统计
|
## 📊 社区统计
|
||||||
|
|
||||||
> 🕐 自动更新于 2026-01-19 18:11
|
> 🕐 自动更新于 2026-01-26 15:14
|
||||||
|
|
||||||
| 👤 作者 | 👥 粉丝 | ⭐ 积分 | 🏆 贡献 |
|
| 👤 作者 | 👥 粉丝 | ⭐ 积分 | 🏆 贡献 |
|
||||||
|:---:|:---:|:---:|:---:|
|
|:---:|:---:|:---:|:---:|
|
||||||
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **133** | **134** | **25** |
|
| [Fu-Jie](https://openwebui.com/u/Fu-Jie) | **158** | **152** | **31** |
|
||||||
|
|
||||||
| 📝 发布 | ⬇️ 下载 | 👁️ 浏览 | 👍 点赞 | 💾 收藏 |
|
| 📝 发布 | ⬇️ 下载 | 👁️ 浏览 | 👍 点赞 | 💾 收藏 |
|
||||||
|:---:|:---:|:---:|:---:|:---:|
|
|:---:|:---:|:---:|:---:|:---:|
|
||||||
| **16** | **1792** | **21276** | **120** | **135** |
|
| **19** | **2388** | **27294** | **138** | **183** |
|
||||||
|
|
||||||
### 🔥 热门插件 Top 6
|
### 🔥 热门插件 Top 6
|
||||||
|
|
||||||
> 🕐 自动更新于 2026-01-19 18:11
|
> 🕐 自动更新于 2026-01-26 15:14
|
||||||
|
|
||||||
| 排名 | 插件 | 版本 | 下载 | 浏览 | 更新日期 |
|
| 排名 | 插件 | 版本 | 下载 | 浏览 | 更新日期 |
|
||||||
|:---:|------|:---:|:---:|:---:|:---:|
|
|:---:|------|:---:|:---:|:---:|:---:|
|
||||||
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 532 | 4822 | 2026-01-17 |
|
| 🥇 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | 0.9.1 | 629 | 5600 | 2026-01-17 |
|
||||||
| 🥈 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 260 | 2514 | 2026-01-18 |
|
| 🥈 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | 1.4.9 | 410 | 3621 | 2026-01-25 |
|
||||||
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 209 | 800 | 2026-01-07 |
|
| 🥉 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | 0.3.7 | 255 | 1039 | 2026-01-07 |
|
||||||
| 4️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.1.3 | 180 | 1975 | 2026-01-17 |
|
| 4️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 229 | 1839 | 2026-01-17 |
|
||||||
| 5️⃣ | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | 0.4.3 | 158 | 1377 | 2026-01-17 |
|
| 5️⃣ | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | 1.2.2 | 227 | 2461 | 2026-01-21 |
|
||||||
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 138 | 2329 | 2026-01-17 |
|
| 6️⃣ | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | 0.2.4 | 165 | 2674 | 2026-01-17 |
|
||||||
|
|
||||||
*完整统计请查看 [社区统计报告](./docs/community-stats.zh.md)*
|
*完整统计请查看 [社区统计报告](./docs/community-stats.zh.md)*
|
||||||
<!-- STATS_END -->
|
<!-- STATS_END -->
|
||||||
@@ -40,6 +40,7 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
|||||||
位于 `plugins/` 目录,包含各类 Python 编写的功能增强插件:
|
位于 `plugins/` 目录,包含各类 Python 编写的功能增强插件:
|
||||||
|
|
||||||
#### Actions (交互增强)
|
#### Actions (交互增强)
|
||||||
|
|
||||||
- **Smart Mind Map** (`smart-mind-map`): 智能分析文本并生成交互式思维导图。
|
- **Smart Mind Map** (`smart-mind-map`): 智能分析文本并生成交互式思维导图。
|
||||||
- **Smart Infographic** (`infographic`): 基于 AntV 的智能信息图生成工具。
|
- **Smart Infographic** (`infographic`): 基于 AntV 的智能信息图生成工具。
|
||||||
- **Flash Card** (`flash-card`): 快速生成精美的学习记忆卡片。
|
- **Flash Card** (`flash-card`): 快速生成精美的学习记忆卡片。
|
||||||
@@ -48,17 +49,22 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
|||||||
- **Export to Word** (`export_to_docx`): 将对话内容导出为 Word 文档。
|
- **Export to Word** (`export_to_docx`): 将对话内容导出为 Word 文档。
|
||||||
|
|
||||||
#### Filters (消息处理)
|
#### Filters (消息处理)
|
||||||
|
|
||||||
- **Async Context Compression** (`async-context-compression`): 异步上下文压缩,优化 Token 使用。
|
- **Async Context Compression** (`async-context-compression`): 异步上下文压缩,优化 Token 使用。
|
||||||
- **Context Enhancement** (`context_enhancement_filter`): 上下文增强过滤器。
|
- **Context Enhancement** (`context_enhancement_filter`): 上下文增强过滤器。
|
||||||
|
- **Folder Memory** (`folder-memory`): 自动从对话中提取项目规则并注入到文件夹系统提示词中。
|
||||||
- **Gemini Manifold Companion** (`gemini_manifold_companion`): Gemini Manifold 配套增强。
|
- **Gemini Manifold Companion** (`gemini_manifold_companion`): Gemini Manifold 配套增强。
|
||||||
- **Gemini Multimodal Filter** (`web_gemini_multimodel_filter`): 为任意模型提供多模态能力(PDF、Office、视频等),支持智能路由和字幕精修。
|
- **Gemini Multimodal Filter** (`web_gemini_multimodel_filter`): 为任意模型提供多模态能力(PDF、Office、视频等),支持智能路由和字幕精修。
|
||||||
- **Markdown Normalizer** (`markdown_normalizer`): 修复 LLM 输出中常见的 Markdown 格式问题。
|
- **Markdown Normalizer** (`markdown_normalizer`): 修复 LLM 输出中常见的 Markdown 格式问题。
|
||||||
- **Multi-Model Context Merger** (`multi_model_context_merger`): 自动合并并注入多模型回答的上下文。
|
- **Multi-Model Context Merger** (`multi_model_context_merger`): 自动合并并注入多模型回答的上下文。
|
||||||
|
|
||||||
#### Pipes (模型管道)
|
#### Pipes (模型管道)
|
||||||
|
|
||||||
|
- **GitHub Copilot SDK** (`github-copilot-sdk`): GitHub Copilot SDK 官方集成。支持动态模型、多轮对话、流式输出、图片输入及无限会话。
|
||||||
- **Gemini Manifold** (`gemini_mainfold`): 集成 Gemini 模型的管道。
|
- **Gemini Manifold** (`gemini_mainfold`): 集成 Gemini 模型的管道。
|
||||||
|
|
||||||
#### Pipelines (工作流管道)
|
#### Pipelines (工作流管道)
|
||||||
|
|
||||||
- **MoE Prompt Refiner** (`moe_prompt_refiner`): 优化多模型 (MoE) 汇总请求的提示词,生成高质量的综合报告。
|
- **MoE Prompt Refiner** (`moe_prompt_refiner`): 优化多模型 (MoE) 汇总请求的提示词,生成高质量的综合报告。
|
||||||
|
|
||||||
### 🎯 提示词 (Prompts)
|
### 🎯 提示词 (Prompts)
|
||||||
@@ -106,6 +112,7 @@ OpenWebUI 增强功能集合。包含个人开发与收集的插件、提示词
|
|||||||
### 贡献代码
|
### 贡献代码
|
||||||
|
|
||||||
如果你有优质的提示词或插件想要分享:
|
如果你有优质的提示词或插件想要分享:
|
||||||
|
|
||||||
1. Fork 本仓库。
|
1. Fork 本仓库。
|
||||||
2. 将你的文件添加到对应的 `prompts/` 或 `plugins/` 目录。
|
2. 将你的文件添加到对应的 `prompts/` 或 `plugins/` 目录。
|
||||||
3. 提交 Pull Request。
|
3. 提交 Pull Request。
|
||||||
|
|||||||
@@ -1,7 +1,7 @@
|
|||||||
{
|
{
|
||||||
"schemaVersion": 1,
|
"schemaVersion": 1,
|
||||||
"label": "downloads",
|
"label": "downloads",
|
||||||
"message": "1.8k",
|
"message": "2.4k",
|
||||||
"color": "blue",
|
"color": "blue",
|
||||||
"namedLogo": "openwebui"
|
"namedLogo": "openwebui"
|
||||||
}
|
}
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
{
|
{
|
||||||
"schemaVersion": 1,
|
"schemaVersion": 1,
|
||||||
"label": "followers",
|
"label": "followers",
|
||||||
"message": "133",
|
"message": "158",
|
||||||
"color": "blue"
|
"color": "blue"
|
||||||
}
|
}
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
{
|
{
|
||||||
"schemaVersion": 1,
|
"schemaVersion": 1,
|
||||||
"label": "plugins",
|
"label": "plugins",
|
||||||
"message": "16",
|
"message": "19",
|
||||||
"color": "green"
|
"color": "green"
|
||||||
}
|
}
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
{
|
{
|
||||||
"schemaVersion": 1,
|
"schemaVersion": 1,
|
||||||
"label": "points",
|
"label": "points",
|
||||||
"message": "134",
|
"message": "152",
|
||||||
"color": "orange"
|
"color": "orange"
|
||||||
}
|
}
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
{
|
{
|
||||||
"schemaVersion": 1,
|
"schemaVersion": 1,
|
||||||
"label": "upvotes",
|
"label": "upvotes",
|
||||||
"message": "120",
|
"message": "138",
|
||||||
"color": "brightgreen"
|
"color": "brightgreen"
|
||||||
}
|
}
|
||||||
@@ -1,14 +1,16 @@
|
|||||||
{
|
{
|
||||||
"total_posts": 16,
|
"total_posts": 19,
|
||||||
"total_downloads": 1792,
|
"total_downloads": 2388,
|
||||||
"total_views": 21276,
|
"total_views": 27294,
|
||||||
"total_upvotes": 120,
|
"total_upvotes": 138,
|
||||||
"total_downvotes": 2,
|
"total_downvotes": 2,
|
||||||
"total_saves": 135,
|
"total_saves": 183,
|
||||||
"total_comments": 24,
|
"total_comments": 33,
|
||||||
"by_type": {
|
"by_type": {
|
||||||
|
"pipe": 1,
|
||||||
"action": 14,
|
"action": 14,
|
||||||
"unknown": 2
|
"unknown": 3,
|
||||||
|
"filter": 1
|
||||||
},
|
},
|
||||||
"posts": [
|
"posts": [
|
||||||
{
|
{
|
||||||
@@ -18,29 +20,29 @@
|
|||||||
"version": "0.9.1",
|
"version": "0.9.1",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "Intelligently analyzes text content and generates interactive mind maps to help users structure and visualize knowledge.",
|
"description": "Intelligently analyzes text content and generates interactive mind maps to help users structure and visualize knowledge.",
|
||||||
"downloads": 532,
|
"downloads": 629,
|
||||||
"views": 4822,
|
"views": 5600,
|
||||||
"upvotes": 15,
|
"upvotes": 16,
|
||||||
"saves": 28,
|
"saves": 37,
|
||||||
"comments": 11,
|
"comments": 11,
|
||||||
"created_at": "2025-12-30",
|
"created_at": "2025-12-30",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
"url": "https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a"
|
"url": "https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"title": "📊 Smart Infographic (AntV)",
|
"title": "Smart Infographic",
|
||||||
"slug": "smart_infographic_ad6f0c7f",
|
"slug": "smart_infographic_ad6f0c7f",
|
||||||
"type": "action",
|
"type": "action",
|
||||||
"version": "1.4.9",
|
"version": "1.4.9",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "AI-powered infographic generator based on AntV Infographic. Supports professional templates, auto-icon matching, and SVG/PNG downloads.",
|
"description": "AI-powered infographic generator based on AntV Infographic. Supports professional templates, auto-icon matching, and SVG/PNG downloads.",
|
||||||
"downloads": 260,
|
"downloads": 410,
|
||||||
"views": 2514,
|
"views": 3621,
|
||||||
"upvotes": 14,
|
"upvotes": 18,
|
||||||
"saves": 20,
|
"saves": 27,
|
||||||
"comments": 3,
|
"comments": 7,
|
||||||
"created_at": "2025-12-28",
|
"created_at": "2025-12-28",
|
||||||
"updated_at": "2026-01-18",
|
"updated_at": "2026-01-25",
|
||||||
"url": "https://openwebui.com/posts/smart_infographic_ad6f0c7f"
|
"url": "https://openwebui.com/posts/smart_infographic_ad6f0c7f"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -50,31 +52,15 @@
|
|||||||
"version": "0.3.7",
|
"version": "0.3.7",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "Extracts tables from chat messages and exports them to Excel (.xlsx) files with smart formatting.",
|
"description": "Extracts tables from chat messages and exports them to Excel (.xlsx) files with smart formatting.",
|
||||||
"downloads": 209,
|
"downloads": 255,
|
||||||
"views": 800,
|
"views": 1039,
|
||||||
"upvotes": 4,
|
"upvotes": 4,
|
||||||
"saves": 5,
|
"saves": 6,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
"created_at": "2025-05-30",
|
"created_at": "2025-05-30",
|
||||||
"updated_at": "2026-01-07",
|
"updated_at": "2026-01-07",
|
||||||
"url": "https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d"
|
"url": "https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d"
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"title": "Async Context Compression",
|
|
||||||
"slug": "async_context_compression_b1655bc8",
|
|
||||||
"type": "action",
|
|
||||||
"version": "1.1.3",
|
|
||||||
"author": "Fu-Jie",
|
|
||||||
"description": "Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.",
|
|
||||||
"downloads": 180,
|
|
||||||
"views": 1975,
|
|
||||||
"upvotes": 9,
|
|
||||||
"saves": 19,
|
|
||||||
"comments": 0,
|
|
||||||
"created_at": "2025-11-08",
|
|
||||||
"updated_at": "2026-01-17",
|
|
||||||
"url": "https://openwebui.com/posts/async_context_compression_b1655bc8"
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"title": "Export to Word (Enhanced)",
|
"title": "Export to Word (Enhanced)",
|
||||||
"slug": "export_to_word_enhanced_formatting_fca6a315",
|
"slug": "export_to_word_enhanced_formatting_fca6a315",
|
||||||
@@ -82,15 +68,31 @@
|
|||||||
"version": "0.4.3",
|
"version": "0.4.3",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "Export current conversation from Markdown to Word (.docx) with Mermaid diagrams rendered client-side (Mermaid.js, SVG+PNG), LaTeX math, real hyperlinks, improved tables, syntax highlighting, and blockquote support.",
|
"description": "Export current conversation from Markdown to Word (.docx) with Mermaid diagrams rendered client-side (Mermaid.js, SVG+PNG), LaTeX math, real hyperlinks, improved tables, syntax highlighting, and blockquote support.",
|
||||||
"downloads": 158,
|
"downloads": 229,
|
||||||
"views": 1377,
|
"views": 1839,
|
||||||
"upvotes": 8,
|
"upvotes": 8,
|
||||||
"saves": 16,
|
"saves": 21,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
"created_at": "2026-01-03",
|
"created_at": "2026-01-03",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
"url": "https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315"
|
"url": "https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"title": "Async Context Compression",
|
||||||
|
"slug": "async_context_compression_b1655bc8",
|
||||||
|
"type": "action",
|
||||||
|
"version": "1.2.2",
|
||||||
|
"author": "Fu-Jie",
|
||||||
|
"description": "Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.",
|
||||||
|
"downloads": 227,
|
||||||
|
"views": 2461,
|
||||||
|
"upvotes": 9,
|
||||||
|
"saves": 27,
|
||||||
|
"comments": 0,
|
||||||
|
"created_at": "2025-11-08",
|
||||||
|
"updated_at": "2026-01-21",
|
||||||
|
"url": "https://openwebui.com/posts/async_context_compression_b1655bc8"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"title": "Flash Card",
|
"title": "Flash Card",
|
||||||
"slug": "flash_card_65a2ea8f",
|
"slug": "flash_card_65a2ea8f",
|
||||||
@@ -98,10 +100,10 @@
|
|||||||
"version": "0.2.4",
|
"version": "0.2.4",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "Quickly generates beautiful flashcards from text, extracting key points and categories.",
|
"description": "Quickly generates beautiful flashcards from text, extracting key points and categories.",
|
||||||
"downloads": 138,
|
"downloads": 165,
|
||||||
"views": 2329,
|
"views": 2674,
|
||||||
"upvotes": 10,
|
"upvotes": 11,
|
||||||
"saves": 10,
|
"saves": 13,
|
||||||
"comments": 2,
|
"comments": 2,
|
||||||
"created_at": "2025-12-30",
|
"created_at": "2025-12-30",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
@@ -111,16 +113,16 @@
|
|||||||
"title": "Markdown Normalizer",
|
"title": "Markdown Normalizer",
|
||||||
"slug": "markdown_normalizer_baaa8732",
|
"slug": "markdown_normalizer_baaa8732",
|
||||||
"type": "action",
|
"type": "action",
|
||||||
"version": "1.2.3",
|
"version": "1.2.4",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.",
|
"description": "A content normalizer filter that fixes common Markdown formatting issues in LLM outputs, such as broken code blocks, LaTeX formulas, and list formatting.",
|
||||||
"downloads": 84,
|
"downloads": 148,
|
||||||
"views": 2100,
|
"views": 2762,
|
||||||
"upvotes": 10,
|
"upvotes": 10,
|
||||||
"saves": 17,
|
"saves": 20,
|
||||||
"comments": 5,
|
"comments": 5,
|
||||||
"created_at": "2026-01-12",
|
"created_at": "2026-01-12",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-19",
|
||||||
"url": "https://openwebui.com/posts/markdown_normalizer_baaa8732"
|
"url": "https://openwebui.com/posts/markdown_normalizer_baaa8732"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -130,10 +132,10 @@
|
|||||||
"version": "1.0.0",
|
"version": "1.0.0",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.",
|
"description": "A comprehensive thinking lens that dives deep into any content - from context to logic, insights, and action paths.",
|
||||||
"downloads": 68,
|
"downloads": 91,
|
||||||
"views": 663,
|
"views": 839,
|
||||||
"upvotes": 4,
|
"upvotes": 4,
|
||||||
"saves": 6,
|
"saves": 8,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
"created_at": "2026-01-08",
|
"created_at": "2026-01-08",
|
||||||
"updated_at": "2026-01-08",
|
"updated_at": "2026-01-08",
|
||||||
@@ -146,11 +148,11 @@
|
|||||||
"version": "0.4.3",
|
"version": "0.4.3",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "将对话导出为 Word (.docx),支持 Mermaid 图表 (客户端渲染 SVG+PNG)、LaTeX 数学公式、真实超链接、增强表格格式、代码高亮和引用块。",
|
"description": "将对话导出为 Word (.docx),支持 Mermaid 图表 (客户端渲染 SVG+PNG)、LaTeX 数学公式、真实超链接、增强表格格式、代码高亮和引用块。",
|
||||||
"downloads": 63,
|
"downloads": 87,
|
||||||
"views": 1305,
|
"views": 1614,
|
||||||
"upvotes": 11,
|
"upvotes": 11,
|
||||||
"saves": 3,
|
"saves": 4,
|
||||||
"comments": 1,
|
"comments": 4,
|
||||||
"created_at": "2026-01-04",
|
"created_at": "2026-01-04",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
"url": "https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0"
|
"url": "https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0"
|
||||||
@@ -162,8 +164,8 @@
|
|||||||
"version": "1.4.9",
|
"version": "1.4.9",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "基于 AntV Infographic 的智能信息图生成插件。支持多种专业模板,自动图标匹配,并提供 SVG/PNG 下载功能。",
|
"description": "基于 AntV Infographic 的智能信息图生成插件。支持多种专业模板,自动图标匹配,并提供 SVG/PNG 下载功能。",
|
||||||
"downloads": 42,
|
"downloads": 46,
|
||||||
"views": 683,
|
"views": 781,
|
||||||
"upvotes": 6,
|
"upvotes": 6,
|
||||||
"saves": 0,
|
"saves": 0,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
@@ -178,15 +180,47 @@
|
|||||||
"version": "0.9.1",
|
"version": "0.9.1",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "智能分析文本内容,生成交互式思维导图,帮助用户结构化和可视化知识。",
|
"description": "智能分析文本内容,生成交互式思维导图,帮助用户结构化和可视化知识。",
|
||||||
"downloads": 22,
|
"downloads": 27,
|
||||||
"views": 398,
|
"views": 447,
|
||||||
"upvotes": 3,
|
"upvotes": 4,
|
||||||
"saves": 1,
|
"saves": 1,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
"created_at": "2025-12-31",
|
"created_at": "2025-12-31",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
"url": "https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b"
|
"url": "https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"title": "📂 Folder Memory – Auto-Evolving Project Context",
|
||||||
|
"slug": "folder_memory_auto_evolving_project_context_4a9875b2",
|
||||||
|
"type": "filter",
|
||||||
|
"version": "0.1.0",
|
||||||
|
"author": "Fu-Jie",
|
||||||
|
"description": "Automatically extracts project rules from conversations and injects them into the folder's system prompt.",
|
||||||
|
"downloads": 26,
|
||||||
|
"views": 725,
|
||||||
|
"upvotes": 3,
|
||||||
|
"saves": 4,
|
||||||
|
"comments": 0,
|
||||||
|
"created_at": "2026-01-20",
|
||||||
|
"updated_at": "2026-01-20",
|
||||||
|
"url": "https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"title": "异步上下文压缩",
|
||||||
|
"slug": "异步上下文压缩_5c0617cb",
|
||||||
|
"type": "action",
|
||||||
|
"version": "1.2.2",
|
||||||
|
"author": "Fu-Jie",
|
||||||
|
"description": "通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。",
|
||||||
|
"downloads": 20,
|
||||||
|
"views": 486,
|
||||||
|
"upvotes": 5,
|
||||||
|
"saves": 1,
|
||||||
|
"comments": 0,
|
||||||
|
"created_at": "2025-11-08",
|
||||||
|
"updated_at": "2026-01-21",
|
||||||
|
"url": "https://openwebui.com/posts/异步上下文压缩_5c0617cb"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"title": "闪记卡 (Flash Card)",
|
"title": "闪记卡 (Flash Card)",
|
||||||
"slug": "闪记卡生成插件_4a31eac3",
|
"slug": "闪记卡生成插件_4a31eac3",
|
||||||
@@ -194,31 +228,15 @@
|
|||||||
"version": "0.2.4",
|
"version": "0.2.4",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "快速将文本提炼为精美的学习记忆卡片,支持核心要点提取与分类。",
|
"description": "快速将文本提炼为精美的学习记忆卡片,支持核心要点提取与分类。",
|
||||||
"downloads": 16,
|
"downloads": 19,
|
||||||
"views": 443,
|
"views": 507,
|
||||||
"upvotes": 5,
|
"upvotes": 6,
|
||||||
"saves": 1,
|
"saves": 1,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
"created_at": "2025-12-30",
|
"created_at": "2025-12-30",
|
||||||
"updated_at": "2026-01-17",
|
"updated_at": "2026-01-17",
|
||||||
"url": "https://openwebui.com/posts/闪记卡生成插件_4a31eac3"
|
"url": "https://openwebui.com/posts/闪记卡生成插件_4a31eac3"
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"title": "异步上下文压缩",
|
|
||||||
"slug": "异步上下文压缩_5c0617cb",
|
|
||||||
"type": "action",
|
|
||||||
"version": "1.1.3",
|
|
||||||
"author": "Fu-Jie",
|
|
||||||
"description": "通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。",
|
|
||||||
"downloads": 14,
|
|
||||||
"views": 351,
|
|
||||||
"upvotes": 5,
|
|
||||||
"saves": 1,
|
|
||||||
"comments": 0,
|
|
||||||
"created_at": "2025-11-08",
|
|
||||||
"updated_at": "2026-01-17",
|
|
||||||
"url": "https://openwebui.com/posts/异步上下文压缩_5c0617cb"
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"title": "精读",
|
"title": "精读",
|
||||||
"slug": "精读_99830b0f",
|
"slug": "精读_99830b0f",
|
||||||
@@ -226,8 +244,8 @@
|
|||||||
"version": "1.0.0",
|
"version": "1.0.0",
|
||||||
"author": "Fu-Jie",
|
"author": "Fu-Jie",
|
||||||
"description": "全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。",
|
"description": "全方位的思维透镜 —— 从背景全景到逻辑脉络,从深度洞察到行动路径。",
|
||||||
"downloads": 6,
|
"downloads": 9,
|
||||||
"views": 259,
|
"views": 306,
|
||||||
"upvotes": 3,
|
"upvotes": 3,
|
||||||
"saves": 1,
|
"saves": 1,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
@@ -235,6 +253,38 @@
|
|||||||
"updated_at": "2026-01-08",
|
"updated_at": "2026-01-08",
|
||||||
"url": "https://openwebui.com/posts/精读_99830b0f"
|
"url": "https://openwebui.com/posts/精读_99830b0f"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"title": "GitHub Copilot Official SDK Pipe",
|
||||||
|
"slug": "github_copilot_official_sdk_pipe_ce96f7b4",
|
||||||
|
"type": "pipe",
|
||||||
|
"version": "0.1.1",
|
||||||
|
"author": "Fu-Jie",
|
||||||
|
"description": "Integrate GitHub Copilot SDK. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions (context compaction).",
|
||||||
|
"downloads": 0,
|
||||||
|
"views": 8,
|
||||||
|
"upvotes": 1,
|
||||||
|
"saves": 0,
|
||||||
|
"comments": 0,
|
||||||
|
"created_at": "2026-01-26",
|
||||||
|
"updated_at": "2026-01-26",
|
||||||
|
"url": "https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"title": "🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager",
|
||||||
|
"slug": "open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e",
|
||||||
|
"type": "unknown",
|
||||||
|
"version": "",
|
||||||
|
"author": "",
|
||||||
|
"description": "",
|
||||||
|
"downloads": 0,
|
||||||
|
"views": 222,
|
||||||
|
"upvotes": 6,
|
||||||
|
"saves": 4,
|
||||||
|
"comments": 2,
|
||||||
|
"created_at": "2026-01-25",
|
||||||
|
"updated_at": "2026-01-25",
|
||||||
|
"url": "https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"title": "Review of Claude Haiku 4.5",
|
"title": "Review of Claude Haiku 4.5",
|
||||||
"slug": "review_of_claude_haiku_45_41b0db39",
|
"slug": "review_of_claude_haiku_45_41b0db39",
|
||||||
@@ -243,7 +293,7 @@
|
|||||||
"author": "",
|
"author": "",
|
||||||
"description": "",
|
"description": "",
|
||||||
"downloads": 0,
|
"downloads": 0,
|
||||||
"views": 59,
|
"views": 93,
|
||||||
"upvotes": 1,
|
"upvotes": 1,
|
||||||
"saves": 0,
|
"saves": 0,
|
||||||
"comments": 0,
|
"comments": 0,
|
||||||
@@ -259,9 +309,9 @@
|
|||||||
"author": "",
|
"author": "",
|
||||||
"description": "",
|
"description": "",
|
||||||
"downloads": 0,
|
"downloads": 0,
|
||||||
"views": 1198,
|
"views": 1270,
|
||||||
"upvotes": 12,
|
"upvotes": 12,
|
||||||
"saves": 7,
|
"saves": 8,
|
||||||
"comments": 2,
|
"comments": 2,
|
||||||
"created_at": "2026-01-10",
|
"created_at": "2026-01-10",
|
||||||
"updated_at": "2026-01-10",
|
"updated_at": "2026-01-10",
|
||||||
@@ -273,11 +323,11 @@
|
|||||||
"name": "Fu-Jie",
|
"name": "Fu-Jie",
|
||||||
"profile_url": "https://openwebui.com/u/Fu-Jie",
|
"profile_url": "https://openwebui.com/u/Fu-Jie",
|
||||||
"profile_image": "https://community.s3.openwebui.com/uploads/users/b15d1348-4347-42b4-b815-e053342d6cb0/profile_d9510745-4bd4-4f8f-a997-4a21847d9300.webp",
|
"profile_image": "https://community.s3.openwebui.com/uploads/users/b15d1348-4347-42b4-b815-e053342d6cb0/profile_d9510745-4bd4-4f8f-a997-4a21847d9300.webp",
|
||||||
"followers": 133,
|
"followers": 158,
|
||||||
"following": 2,
|
"following": 3,
|
||||||
"total_points": 134,
|
"total_points": 152,
|
||||||
"post_points": 118,
|
"post_points": 136,
|
||||||
"comment_points": 16,
|
"comment_points": 16,
|
||||||
"contributions": 25
|
"contributions": 31
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -1,40 +1,45 @@
|
|||||||
# 📊 OpenWebUI Community Stats Report
|
# 📊 OpenWebUI Community Stats Report
|
||||||
|
|
||||||
> 📅 Updated: 2026-01-19 18:11
|
> 📅 Updated: 2026-01-26 15:14
|
||||||
|
|
||||||
## 📈 Overview
|
## 📈 Overview
|
||||||
|
|
||||||
| Metric | Value |
|
| Metric | Value |
|
||||||
|------|------|
|
|------|------|
|
||||||
| 📝 Total Posts | 16 |
|
| 📝 Total Posts | 19 |
|
||||||
| ⬇️ Total Downloads | 1792 |
|
| ⬇️ Total Downloads | 2388 |
|
||||||
| 👁️ Total Views | 21276 |
|
| 👁️ Total Views | 27294 |
|
||||||
| 👍 Total Upvotes | 120 |
|
| 👍 Total Upvotes | 138 |
|
||||||
| 💾 Total Saves | 135 |
|
| 💾 Total Saves | 183 |
|
||||||
| 💬 Total Comments | 24 |
|
| 💬 Total Comments | 33 |
|
||||||
|
|
||||||
## 📂 By Type
|
## 📂 By Type
|
||||||
|
|
||||||
|
- **pipe**: 1
|
||||||
- **action**: 14
|
- **action**: 14
|
||||||
- **unknown**: 2
|
- **unknown**: 3
|
||||||
|
- **filter**: 1
|
||||||
|
|
||||||
## 📋 Posts List
|
## 📋 Posts List
|
||||||
|
|
||||||
| Rank | Title | Type | Version | Downloads | Views | Upvotes | Saves | Updated |
|
| Rank | Title | Type | Version | Downloads | Views | Upvotes | Saves | Updated |
|
||||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 532 | 4822 | 15 | 28 | 2026-01-17 |
|
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 629 | 5600 | 16 | 37 | 2026-01-17 |
|
||||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 260 | 2514 | 14 | 20 | 2026-01-18 |
|
| 2 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 410 | 3621 | 18 | 27 | 2026-01-25 |
|
||||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 209 | 800 | 4 | 5 | 2026-01-07 |
|
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 255 | 1039 | 4 | 6 | 2026-01-07 |
|
||||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.1.3 | 180 | 1975 | 9 | 19 | 2026-01-17 |
|
| 4 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 229 | 1839 | 8 | 21 | 2026-01-17 |
|
||||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 158 | 1377 | 8 | 16 | 2026-01-17 |
|
| 5 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.2 | 227 | 2461 | 9 | 27 | 2026-01-21 |
|
||||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 138 | 2329 | 10 | 10 | 2026-01-17 |
|
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 165 | 2674 | 11 | 13 | 2026-01-17 |
|
||||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.3 | 84 | 2100 | 10 | 17 | 2026-01-17 |
|
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 148 | 2762 | 10 | 20 | 2026-01-19 |
|
||||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 68 | 663 | 4 | 6 | 2026-01-08 |
|
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 91 | 839 | 4 | 8 | 2026-01-08 |
|
||||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 63 | 1305 | 11 | 3 | 2026-01-17 |
|
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 87 | 1614 | 11 | 4 | 2026-01-17 |
|
||||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 42 | 683 | 6 | 0 | 2026-01-17 |
|
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 46 | 781 | 6 | 0 | 2026-01-17 |
|
||||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 22 | 398 | 3 | 1 | 2026-01-17 |
|
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 447 | 4 | 1 | 2026-01-17 |
|
||||||
| 12 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 16 | 443 | 5 | 1 | 2026-01-17 |
|
| 12 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 26 | 725 | 3 | 4 | 2026-01-20 |
|
||||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.1.3 | 14 | 351 | 5 | 1 | 2026-01-17 |
|
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.2 | 20 | 486 | 5 | 1 | 2026-01-21 |
|
||||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 6 | 259 | 3 | 1 | 2026-01-08 |
|
| 14 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 507 | 6 | 1 | 2026-01-17 |
|
||||||
| 15 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 59 | 1 | 0 | 2026-01-14 |
|
| 15 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 9 | 306 | 3 | 1 | 2026-01-08 |
|
||||||
| 16 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1198 | 12 | 7 | 2026-01-10 |
|
| 16 | [GitHub Copilot Official SDK Pipe](https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4) | pipe | 0.1.1 | 0 | 8 | 1 | 0 | 2026-01-26 |
|
||||||
|
| 17 | [🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager](https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e) | unknown | | 0 | 222 | 6 | 4 | 2026-01-25 |
|
||||||
|
| 18 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 93 | 1 | 0 | 2026-01-14 |
|
||||||
|
| 19 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1270 | 12 | 8 | 2026-01-10 |
|
||||||
|
|||||||
@@ -1,40 +1,45 @@
|
|||||||
# 📊 OpenWebUI 社区统计报告
|
# 📊 OpenWebUI 社区统计报告
|
||||||
|
|
||||||
> 📅 更新时间: 2026-01-19 18:11
|
> 📅 更新时间: 2026-01-26 15:14
|
||||||
|
|
||||||
## 📈 总览
|
## 📈 总览
|
||||||
|
|
||||||
| 指标 | 数值 |
|
| 指标 | 数值 |
|
||||||
|------|------|
|
|------|------|
|
||||||
| 📝 发布数量 | 16 |
|
| 📝 发布数量 | 19 |
|
||||||
| ⬇️ 总下载量 | 1792 |
|
| ⬇️ 总下载量 | 2388 |
|
||||||
| 👁️ 总浏览量 | 21276 |
|
| 👁️ 总浏览量 | 27294 |
|
||||||
| 👍 总点赞数 | 120 |
|
| 👍 总点赞数 | 138 |
|
||||||
| 💾 总收藏数 | 135 |
|
| 💾 总收藏数 | 183 |
|
||||||
| 💬 总评论数 | 24 |
|
| 💬 总评论数 | 33 |
|
||||||
|
|
||||||
## 📂 按类型分类
|
## 📂 按类型分类
|
||||||
|
|
||||||
|
- **pipe**: 1
|
||||||
- **action**: 14
|
- **action**: 14
|
||||||
- **unknown**: 2
|
- **unknown**: 3
|
||||||
|
- **filter**: 1
|
||||||
|
|
||||||
## 📋 发布列表
|
## 📋 发布列表
|
||||||
|
|
||||||
| 排名 | 标题 | 类型 | 版本 | 下载 | 浏览 | 点赞 | 收藏 | 更新日期 |
|
| 排名 | 标题 | 类型 | 版本 | 下载 | 浏览 | 点赞 | 收藏 | 更新日期 |
|
||||||
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
|:---:|------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|
||||||
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 532 | 4822 | 15 | 28 | 2026-01-17 |
|
| 1 | [Smart Mind Map](https://openwebui.com/posts/turn_any_text_into_beautiful_mind_maps_3094c59a) | action | 0.9.1 | 629 | 5600 | 16 | 37 | 2026-01-17 |
|
||||||
| 2 | [📊 Smart Infographic (AntV)](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 260 | 2514 | 14 | 20 | 2026-01-18 |
|
| 2 | [Smart Infographic](https://openwebui.com/posts/smart_infographic_ad6f0c7f) | action | 1.4.9 | 410 | 3621 | 18 | 27 | 2026-01-25 |
|
||||||
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 209 | 800 | 4 | 5 | 2026-01-07 |
|
| 3 | [Export to Excel](https://openwebui.com/posts/export_mulit_table_to_excel_244b8f9d) | action | 0.3.7 | 255 | 1039 | 4 | 6 | 2026-01-07 |
|
||||||
| 4 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.1.3 | 180 | 1975 | 9 | 19 | 2026-01-17 |
|
| 4 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 229 | 1839 | 8 | 21 | 2026-01-17 |
|
||||||
| 5 | [Export to Word (Enhanced)](https://openwebui.com/posts/export_to_word_enhanced_formatting_fca6a315) | action | 0.4.3 | 158 | 1377 | 8 | 16 | 2026-01-17 |
|
| 5 | [Async Context Compression](https://openwebui.com/posts/async_context_compression_b1655bc8) | action | 1.2.2 | 227 | 2461 | 9 | 27 | 2026-01-21 |
|
||||||
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 138 | 2329 | 10 | 10 | 2026-01-17 |
|
| 6 | [Flash Card](https://openwebui.com/posts/flash_card_65a2ea8f) | action | 0.2.4 | 165 | 2674 | 11 | 13 | 2026-01-17 |
|
||||||
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.3 | 84 | 2100 | 10 | 17 | 2026-01-17 |
|
| 7 | [Markdown Normalizer](https://openwebui.com/posts/markdown_normalizer_baaa8732) | action | 1.2.4 | 148 | 2762 | 10 | 20 | 2026-01-19 |
|
||||||
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 68 | 663 | 4 | 6 | 2026-01-08 |
|
| 8 | [Deep Dive](https://openwebui.com/posts/deep_dive_c0b846e4) | action | 1.0.0 | 91 | 839 | 4 | 8 | 2026-01-08 |
|
||||||
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 63 | 1305 | 11 | 3 | 2026-01-17 |
|
| 9 | [导出为 Word (增强版)](https://openwebui.com/posts/导出为_word_支持公式流程图表格和代码块_8a6306c0) | action | 0.4.3 | 87 | 1614 | 11 | 4 | 2026-01-17 |
|
||||||
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 42 | 683 | 6 | 0 | 2026-01-17 |
|
| 10 | [📊 智能信息图 (AntV Infographic)](https://openwebui.com/posts/智能信息图_e04a48ff) | action | 1.4.9 | 46 | 781 | 6 | 0 | 2026-01-17 |
|
||||||
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 22 | 398 | 3 | 1 | 2026-01-17 |
|
| 11 | [思维导图](https://openwebui.com/posts/智能生成交互式思维导图帮助用户可视化知识_8d4b097b) | action | 0.9.1 | 27 | 447 | 4 | 1 | 2026-01-17 |
|
||||||
| 12 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 16 | 443 | 5 | 1 | 2026-01-17 |
|
| 12 | [📂 Folder Memory – Auto-Evolving Project Context](https://openwebui.com/posts/folder_memory_auto_evolving_project_context_4a9875b2) | filter | 0.1.0 | 26 | 725 | 3 | 4 | 2026-01-20 |
|
||||||
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.1.3 | 14 | 351 | 5 | 1 | 2026-01-17 |
|
| 13 | [异步上下文压缩](https://openwebui.com/posts/异步上下文压缩_5c0617cb) | action | 1.2.2 | 20 | 486 | 5 | 1 | 2026-01-21 |
|
||||||
| 14 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 6 | 259 | 3 | 1 | 2026-01-08 |
|
| 14 | [闪记卡 (Flash Card)](https://openwebui.com/posts/闪记卡生成插件_4a31eac3) | action | 0.2.4 | 19 | 507 | 6 | 1 | 2026-01-17 |
|
||||||
| 15 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 59 | 1 | 0 | 2026-01-14 |
|
| 15 | [精读](https://openwebui.com/posts/精读_99830b0f) | action | 1.0.0 | 9 | 306 | 3 | 1 | 2026-01-08 |
|
||||||
| 16 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1198 | 12 | 7 | 2026-01-10 |
|
| 16 | [GitHub Copilot Official SDK Pipe](https://openwebui.com/posts/github_copilot_official_sdk_pipe_ce96f7b4) | pipe | 0.1.1 | 0 | 8 | 1 | 0 | 2026-01-26 |
|
||||||
|
| 17 | [🚀 Open WebUI Prompt Plus: AI-Powered Prompt Manager](https://openwebui.com/posts/open_webui_prompt_plus_ai_powered_prompt_manager_s_15fa060e) | unknown | | 0 | 222 | 6 | 4 | 2026-01-25 |
|
||||||
|
| 18 | [Review of Claude Haiku 4.5](https://openwebui.com/posts/review_of_claude_haiku_45_41b0db39) | unknown | | 0 | 93 | 1 | 0 | 2026-01-14 |
|
||||||
|
| 19 | [ 🛠️ Debug Open WebUI Plugins in Your Browser](https://openwebui.com/posts/debug_open_webui_plugins_in_your_browser_81bf7960) | unknown | | 0 | 1270 | 12 | 8 | 2026-01-10 |
|
||||||
|
|||||||
@@ -1,7 +1,7 @@
|
|||||||
# Async Context Compression
|
# Async Context Compression
|
||||||
|
|
||||||
<span class="category-badge filter">Filter</span>
|
<span class="category-badge filter">Filter</span>
|
||||||
<span class="version-badge">v1.2.0</span>
|
<span class="version-badge">v1.2.2</span>
|
||||||
|
|
||||||
Reduces token consumption in long conversations through intelligent summarization while maintaining conversational coherence.
|
Reduces token consumption in long conversations through intelligent summarization while maintaining conversational coherence.
|
||||||
|
|
||||||
@@ -38,6 +38,8 @@ This is especially useful for:
|
|||||||
- :material-format-align-justify: **Structure-Aware Trimming**: Preserves document structure
|
- :material-format-align-justify: **Structure-Aware Trimming**: Preserves document structure
|
||||||
- :material-content-cut: **Native Tool Output Trimming**: Trims verbose tool outputs (Note: Non-native tool outputs are not fully injected into context)
|
- :material-content-cut: **Native Tool Output Trimming**: Trims verbose tool outputs (Note: Non-native tool outputs are not fully injected into context)
|
||||||
- :material-chart-bar: **Detailed Token Logging**: Granular token breakdown
|
- :material-chart-bar: **Detailed Token Logging**: Granular token breakdown
|
||||||
|
- :material-account-search: **Smart Model Matching**: Inherit config from base models
|
||||||
|
- :material-image-off: **Multimodal Support**: Images are preserved but tokens are **NOT** calculated
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -73,6 +75,7 @@ graph TD
|
|||||||
| `keep_first` | integer | `1` | Always keep the first N messages |
|
| `keep_first` | integer | `1` | Always keep the first N messages |
|
||||||
| `keep_last` | integer | `6` | Always keep the last N messages |
|
| `keep_last` | integer | `6` | Always keep the last N messages |
|
||||||
| `summary_model` | string | `None` | Model to use for summarization |
|
| `summary_model` | string | `None` | Model to use for summarization |
|
||||||
|
| `summary_model_max_context` | integer | `0` | Max context tokens for summary model |
|
||||||
| `max_summary_tokens` | integer | `16384` | Maximum tokens for the summary |
|
| `max_summary_tokens` | integer | `16384` | Maximum tokens for the summary |
|
||||||
| `enable_tool_output_trimming` | boolean | `false` | Enable trimming of large tool outputs |
|
| `enable_tool_output_trimming` | boolean | `false` | Enable trimming of large tool outputs |
|
||||||
|
|
||||||
|
|||||||
@@ -1,7 +1,7 @@
|
|||||||
# Async Context Compression(异步上下文压缩)
|
# Async Context Compression(异步上下文压缩)
|
||||||
|
|
||||||
<span class="category-badge filter">Filter</span>
|
<span class="category-badge filter">Filter</span>
|
||||||
<span class="version-badge">v1.2.0</span>
|
<span class="version-badge">v1.2.2</span>
|
||||||
|
|
||||||
通过智能摘要减少长对话的 token 消耗,同时保持对话连贯。
|
通过智能摘要减少长对话的 token 消耗,同时保持对话连贯。
|
||||||
|
|
||||||
@@ -38,6 +38,8 @@ Async Context Compression 过滤器通过以下方式帮助管理长对话的 to
|
|||||||
- :material-format-align-justify: **结构感知裁剪**:保留文档结构的智能裁剪
|
- :material-format-align-justify: **结构感知裁剪**:保留文档结构的智能裁剪
|
||||||
- :material-content-cut: **原生工具输出裁剪**:自动裁剪冗长的工具输出(注意:非原生工具调用输出不会完整注入上下文)
|
- :material-content-cut: **原生工具输出裁剪**:自动裁剪冗长的工具输出(注意:非原生工具调用输出不会完整注入上下文)
|
||||||
- :material-chart-bar: **详细 Token 日志**:提供细粒度的 Token 统计
|
- :material-chart-bar: **详细 Token 日志**:提供细粒度的 Token 统计
|
||||||
|
- :material-account-search: **智能模型匹配**:自定义模型自动继承基础模型配置
|
||||||
|
- :material-image-off: **多模态支持**:图片内容保留但 Token **不参与计算**
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -73,6 +75,7 @@ graph TD
|
|||||||
| `keep_first` | integer | `1` | 始终保留的前 N 条消息 |
|
| `keep_first` | integer | `1` | 始终保留的前 N 条消息 |
|
||||||
| `keep_last` | integer | `6` | 始终保留的后 N 条消息 |
|
| `keep_last` | integer | `6` | 始终保留的后 N 条消息 |
|
||||||
| `summary_model` | string | `None` | 用于摘要的模型 |
|
| `summary_model` | string | `None` | 用于摘要的模型 |
|
||||||
|
| `summary_model_max_context` | integer | `0` | 摘要模型的最大上下文 Token 数 |
|
||||||
| `max_summary_tokens` | integer | `16384` | 摘要的最大 token 数 |
|
| `max_summary_tokens` | integer | `16384` | 摘要的最大 token 数 |
|
||||||
| `enable_tool_output_trimming` | boolean | `false` | 启用长工具输出裁剪 |
|
| `enable_tool_output_trimming` | boolean | `false` | 启用长工具输出裁剪 |
|
||||||
|
|
||||||
|
|||||||
57
docs/plugins/filters/folder-memory.md
Normal file
57
docs/plugins/filters/folder-memory.md
Normal file
@@ -0,0 +1,57 @@
|
|||||||
|
# Folder Memory
|
||||||
|
|
||||||
|
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 📌 What's new in 0.1.0
|
||||||
|
- **Initial Release**: Automated "Project Rules" management for OpenWebUI folders.
|
||||||
|
- **Folder-Level Persistence**: Automatically updates folder system prompts with extracted rules.
|
||||||
|
- **Optimized Performance**: Runs asynchronously and supports `PRIORITY` configuration for seamless integration with other filters.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Folder Memory** is an intelligent context filter plugin for OpenWebUI. It automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||||
|
|
||||||
|
This ensures that all future conversations within that folder share the same evolved context and rules, without manual updates.
|
||||||
|
|
||||||
|
## Features
|
||||||
|
|
||||||
|
- **Automatic Extraction**: Analyzes chat history every N messages to extract project rules.
|
||||||
|
- **Non-destructive Injection**: Updates only the specific "Project Rules" block in the system prompt, preserving other instructions.
|
||||||
|
- **Async Processing**: Runs in the background without blocking the user's chat experience.
|
||||||
|
- **ORM Integration**: Directly updates folder data using OpenWebUI's internal models for reliability.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- **Conversations must occur inside a folder.** This plugin only triggers when a chat belongs to a folder (i.e., you need to create a folder in OpenWebUI and start a conversation within it).
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
|
||||||
|
1. Copy `folder_memory.py` to your OpenWebUI `plugins/filters/` directory (or upload via Admin UI).
|
||||||
|
2. Enable the filter in your **Settings** -> **Filters**.
|
||||||
|
3. (Optional) Configure the triggering threshold (default: every 10 messages).
|
||||||
|
|
||||||
|
## Configuration (Valves)
|
||||||
|
|
||||||
|
| Valve | Default | Description |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| `PRIORITY` | `20` | Priority level for the filter operations. |
|
||||||
|
| `MESSAGE_TRIGGER_COUNT` | `10` | The number of messages required to trigger a rule analysis. |
|
||||||
|
| `MODEL_ID` | `""` | The model used to generate rules. If empty, uses the current chat model. |
|
||||||
|
| `RULES_BLOCK_TITLE` | `## 📂 Project Rules` | The title displayed above the injected rules block. |
|
||||||
|
| `SHOW_DEBUG_LOG` | `False` | Show detailed debug logs in the browser console. |
|
||||||
|
| `UPDATE_ROOT_FOLDER` | `False` | If enabled, finds and updates the root folder rules instead of the current subfolder. |
|
||||||
|
|
||||||
|
## How It Works
|
||||||
|
|
||||||
|
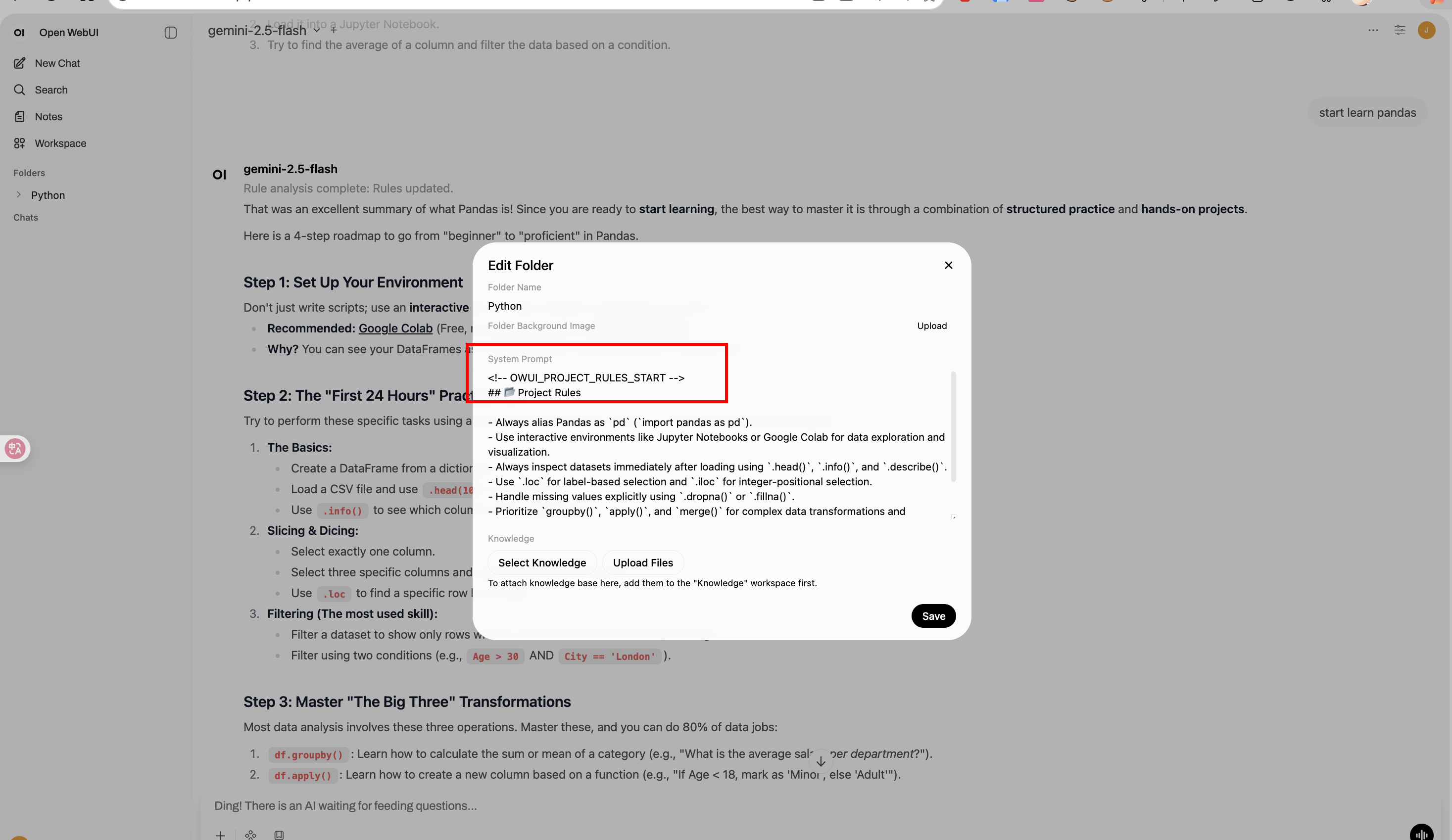
|
||||||
|
|
||||||
|
1. **Trigger**: When a conversation reaches `MESSAGE_TRIGGER_COUNT` (e.g., 10, 20 messages).
|
||||||
|
2. **Analysis**: The plugin sends the recent conversation + existing rules to the LLM.
|
||||||
|
3. **Synthesis**: The LLM merges new insights with old rules, removing obsolete ones.
|
||||||
|
4. **Update**: The new rule set replaces the `<!-- OWUI_PROJECT_RULES_START -->` block in the folder's system prompt.
|
||||||
|
|
||||||
|
## Roadmap
|
||||||
|
|
||||||
|
See [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) for future plans, including "Project Knowledge" collection.
|
||||||
57
docs/plugins/filters/folder-memory.zh.md
Normal file
57
docs/plugins/filters/folder-memory.zh.md
Normal file
@@ -0,0 +1,57 @@
|
|||||||
|
# 文件夹记忆 (Folder Memory)
|
||||||
|
|
||||||
|
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 📌 0.1.0 版本特性
|
||||||
|
- **首个版本发布**:专注于自动化的“项目规则”管理。
|
||||||
|
- **文件夹级持久化**:自动将提取的规则回写到文件夹系统提示词中。
|
||||||
|
- **性能优化**:采用异步处理机制,并支持 `PRIORITY` 配置,确保与其他过滤器(如上下文压缩)完美协作。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**文件夹记忆 (Folder Memory)** 是一个 OpenWebUI 的智能上下文过滤器插件。它能自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||||
|
|
||||||
|
这确保了该文件夹内的所有未来对话都能共享相同的进化上下文和规则,无需手动更新。
|
||||||
|
|
||||||
|
## 功能特性
|
||||||
|
|
||||||
|
- **自动提取**:每隔 N 条消息分析一次聊天记录,提取项目规则。
|
||||||
|
- **无损注入**:仅更新系统提示词中的特定“项目规则”块,保留其他指令。
|
||||||
|
- **异步处理**:在后台运行,不阻塞用户的聊天体验。
|
||||||
|
- **ORM 集成**:直接使用 OpenWebUI 的内部模型更新文件夹数据,确保可靠性。
|
||||||
|
|
||||||
|
## 前置条件
|
||||||
|
|
||||||
|
- **对话必须在文件夹内进行。** 此插件仅在聊天属于某个文件夹时触发(即您需要先在 OpenWebUI 中创建一个文件夹,并在其内部开始对话)。
|
||||||
|
|
||||||
|
## 安装指南
|
||||||
|
|
||||||
|
1. 将 `folder_memory.py` (或中文版 `folder_memory_cn.py`) 复制到 OpenWebUI 的 `plugins/filters/` 目录(或通过管理员 UI 上传)。
|
||||||
|
2. 在 **设置** -> **过滤器** 中启用该插件。
|
||||||
|
3. (可选)配置触发阈值(默认:每 10 条消息)。
|
||||||
|
|
||||||
|
## 配置 (Valves)
|
||||||
|
|
||||||
|
| 参数 | 默认值 | 说明 |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| `PRIORITY` | `20` | 过滤器操作的优先级。 |
|
||||||
|
| `MESSAGE_TRIGGER_COUNT` | `10` | 触发规则分析的消息数量阈值。 |
|
||||||
|
| `MODEL_ID` | `""` | 用于生成规则的模型 ID。若为空,则使用当前对话模型。 |
|
||||||
|
| `RULES_BLOCK_TITLE` | `## 📂 项目规则` | 显示在注入规则块上方的标题。 |
|
||||||
|
| `SHOW_DEBUG_LOG` | `False` | 在浏览器控制台显示详细调试日志。 |
|
||||||
|
| `UPDATE_ROOT_FOLDER` | `False` | 如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。 |
|
||||||
|
|
||||||
|
## 工作原理
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1. **触发**:当对话达到 `MESSAGE_TRIGGER_COUNT`(例如 10、20 条消息)时。
|
||||||
|
2. **分析**:插件将最近的对话 + 现有规则发送给 LLM。
|
||||||
|
3. **综合**:LLM 将新见解与旧规则合并,移除过时的规则。
|
||||||
|
4. **更新**:新的规则集替换文件夹系统提示词中的 `<!-- OWUI_PROJECT_RULES_START -->` 块。
|
||||||
|
|
||||||
|
## 路线图
|
||||||
|
|
||||||
|
查看 [ROADMAP](https://github.com/Fu-Jie/awesome-openwebui/blob/main/plugins/filters/folder-memory/ROADMAP.md) 了解未来计划,包括“项目知识”收集功能。
|
||||||
@@ -22,7 +22,7 @@ Filters act as middleware in the message pipeline:
|
|||||||
|
|
||||||
Reduces token consumption in long conversations through intelligent summarization while maintaining coherence.
|
Reduces token consumption in long conversations through intelligent summarization while maintaining coherence.
|
||||||
|
|
||||||
**Version:** 1.1.3
|
**Version:** 1.2.2
|
||||||
|
|
||||||
[:octicons-arrow-right-24: Documentation](async-context-compression.md)
|
[:octicons-arrow-right-24: Documentation](async-context-compression.md)
|
||||||
|
|
||||||
@@ -36,7 +36,15 @@ Filters act as middleware in the message pipeline:
|
|||||||
|
|
||||||
[:octicons-arrow-right-24: Documentation](context-enhancement.md)
|
[:octicons-arrow-right-24: Documentation](context-enhancement.md)
|
||||||
|
|
||||||
|
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
Automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||||
|
|
||||||
|
**Version:** 0.1.0
|
||||||
|
|
||||||
|
[:octicons-arrow-right-24: Documentation](folder-memory.md)
|
||||||
|
|
||||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||||
|
|
||||||
|
|||||||
@@ -22,7 +22,7 @@ Filter 充当消息管线中的中间件:
|
|||||||
|
|
||||||
通过智能总结减少长对话的 token 消耗,同时保持连贯性。
|
通过智能总结减少长对话的 token 消耗,同时保持连贯性。
|
||||||
|
|
||||||
**版本:** 1.1.3
|
**版本:** 1.2.2
|
||||||
|
|
||||||
[:octicons-arrow-right-24: 查看文档](async-context-compression.md)
|
[:octicons-arrow-right-24: 查看文档](async-context-compression.md)
|
||||||
|
|
||||||
@@ -36,7 +36,15 @@ Filter 充当消息管线中的中间件:
|
|||||||
|
|
||||||
[:octicons-arrow-right-24: 查看文档](context-enhancement.md)
|
[:octicons-arrow-right-24: 查看文档](context-enhancement.md)
|
||||||
|
|
||||||
|
- :material-folder-refresh:{ .lg .middle } **Folder Memory**
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||||
|
|
||||||
|
**版本:** 0.1.0
|
||||||
|
|
||||||
|
[:octicons-arrow-right-24: 查看文档](folder-memory.zh.md)
|
||||||
|
|
||||||
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
- :material-format-paint:{ .lg .middle } **Markdown Normalizer**
|
||||||
|
|
||||||
|
|||||||
84
docs/plugins/pipes/github-copilot-sdk.md
Normal file
84
docs/plugins/pipes/github-copilot-sdk.md
Normal file
@@ -0,0 +1,84 @@
|
|||||||
|
# GitHub Copilot SDK Pipe for OpenWebUI
|
||||||
|
|
||||||
|
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||||
|
|
||||||
|
This is an advanced Pipe function for [OpenWebUI](https://github.com/open-webui/open-webui) that allows you to use GitHub Copilot models (such as `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`) directly within OpenWebUI. It is built upon the official [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk), providing a native integration experience.
|
||||||
|
|
||||||
|
## 🚀 What's New (v0.1.0)
|
||||||
|
|
||||||
|
* **♾️ Infinite Sessions**: Automatic context compaction for long-running conversations. No more context limit errors!
|
||||||
|
* **🧠 Thinking Process**: Real-time display of model reasoning/thinking process (for supported models).
|
||||||
|
* **📂 Workspace Control**: Restricted workspace directory for secure file operations.
|
||||||
|
* **🔍 Model Filtering**: Exclude specific models using keywords (e.g., `codex`, `haiku`).
|
||||||
|
* **💾 Session Persistence**: Improved session resume logic using OpenWebUI chat ID mapping.
|
||||||
|
|
||||||
|
## ✨ Core Features
|
||||||
|
|
||||||
|
* **🚀 Official SDK Integration**: Built on the official SDK for stability and reliability.
|
||||||
|
* **💬 Multi-turn Conversation**: Automatically concatenates history context so Copilot understands your previous messages.
|
||||||
|
* **🌊 Streaming Output**: Supports typewriter effect for fast responses.
|
||||||
|
* **🖼️ Multimodal Support**: Supports image uploads, automatically converting them to attachments for Copilot (requires model support).
|
||||||
|
* **🛠️ Zero-config Installation**: Automatically detects and downloads the GitHub Copilot CLI, ready to use out of the box.
|
||||||
|
* **🔑 Secure Authentication**: Supports Fine-grained Personal Access Tokens for minimized permissions.
|
||||||
|
* **🐛 Debug Mode**: Built-in detailed log output for easy connection troubleshooting.
|
||||||
|
|
||||||
|
## 📦 Installation & Usage
|
||||||
|
|
||||||
|
### 1. Import Function
|
||||||
|
|
||||||
|
1. Open OpenWebUI.
|
||||||
|
2. Go to **Workspace** -> **Functions**.
|
||||||
|
3. Click **+** (Create Function).
|
||||||
|
4. Paste the content of `github_copilot_sdk.py` (or `github_copilot_sdk_cn.py` for Chinese) completely.
|
||||||
|
5. Save.
|
||||||
|
|
||||||
|
### 2. Configure Valves (Settings)
|
||||||
|
|
||||||
|
Find "GitHub Copilot" in the function list and click the **⚙️ (Valves)** icon to configure:
|
||||||
|
|
||||||
|
| Parameter | Description | Default |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| **GH_TOKEN** | **(Required)** Your GitHub Token. | - |
|
||||||
|
| **MODEL_ID** | The model name to use. Recommended `gpt-5-mini` or `gpt-5`. | `gpt-5-mini` |
|
||||||
|
| **CLI_PATH** | Path to the Copilot CLI. Will download automatically if not found. | `/usr/local/bin/copilot` |
|
||||||
|
| **DEBUG** | Whether to enable debug logs (output to chat). | `True` |
|
||||||
|
| **SHOW_THINKING** | Show model reasoning/thinking process. | `True` |
|
||||||
|
| **EXCLUDE_KEYWORDS** | Exclude models containing these keywords (comma separated). | - |
|
||||||
|
| **WORKSPACE_DIR** | Restricted workspace directory for file operations. | - |
|
||||||
|
| **INFINITE_SESSION** | Enable Infinite Sessions (automatic context compaction). | `True` |
|
||||||
|
| **COMPACTION_THRESHOLD** | Background compaction threshold (0.0-1.0). | `0.8` |
|
||||||
|
| **BUFFER_THRESHOLD** | Buffer exhaustion threshold (0.0-1.0). | `0.95` |
|
||||||
|
|
||||||
|
### 3. Get GH_TOKEN
|
||||||
|
|
||||||
|
For security, it is recommended to use a **Fine-grained Personal Access Token**:
|
||||||
|
|
||||||
|
1. Visit [GitHub Token Settings](https://github.com/settings/tokens?type=beta).
|
||||||
|
2. Click **Generate new token**.
|
||||||
|
3. **Repository access**: Select `All repositories` or `Public Repositories`.
|
||||||
|
4. **Permissions**:
|
||||||
|
* Click **Account permissions**.
|
||||||
|
* Find **Copilot Requests**, select **Read and write** (or Access).
|
||||||
|
5. Generate and copy the Token.
|
||||||
|
|
||||||
|
## 📋 Dependencies
|
||||||
|
|
||||||
|
This Pipe will automatically attempt to install the following dependencies:
|
||||||
|
|
||||||
|
* `github-copilot-sdk` (Python package)
|
||||||
|
* `github-copilot-cli` (Binary file, installed via official script)
|
||||||
|
|
||||||
|
## ⚠️ FAQ
|
||||||
|
|
||||||
|
* **Stuck on "Waiting..."**:
|
||||||
|
* Check if `GH_TOKEN` is correct and has `Copilot Requests` permission.
|
||||||
|
* Try changing `MODEL_ID` to `gpt-4o` or `copilot-chat`.
|
||||||
|
* **Images not recognized**:
|
||||||
|
* Ensure `MODEL_ID` is a model that supports multimodal input.
|
||||||
|
* **CLI Installation Failed**:
|
||||||
|
* Ensure the OpenWebUI container has internet access.
|
||||||
|
* You can manually download the CLI and specify `CLI_PATH` in Valves.
|
||||||
|
|
||||||
|
## 📄 License
|
||||||
|
|
||||||
|
MIT
|
||||||
84
docs/plugins/pipes/github-copilot-sdk.zh.md
Normal file
84
docs/plugins/pipes/github-copilot-sdk.zh.md
Normal file
@@ -0,0 +1,84 @@
|
|||||||
|
# GitHub Copilot SDK 官方管道
|
||||||
|
|
||||||
|
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||||
|
|
||||||
|
这是一个用于 [OpenWebUI](https://github.com/open-webui/open-webui) 的高级 Pipe 函数,允许你直接在 OpenWebUI 中使用 GitHub Copilot 模型(如 `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`)。它基于官方 [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk) 构建,提供了原生级的集成体验。
|
||||||
|
|
||||||
|
## 🚀 最新特性 (v0.1.0)
|
||||||
|
|
||||||
|
* **♾️ 无限会话 (Infinite Sessions)**:支持长对话的自动上下文压缩,告别上下文超限错误!
|
||||||
|
* **🧠 思考过程展示**:实时显示模型的推理/思考过程(需模型支持)。
|
||||||
|
* **📂 工作目录控制**:支持设置受限工作目录,确保文件操作安全。
|
||||||
|
* **🔍 模型过滤**:支持通过关键词排除特定模型(如 `codex`, `haiku`)。
|
||||||
|
* **💾 会话持久化**: 改进的会话恢复逻辑,直接关联 OpenWebUI 聊天 ID,连接更稳定。
|
||||||
|
|
||||||
|
## ✨ 核心特性
|
||||||
|
|
||||||
|
* **🚀 官方 SDK 集成**:基于官方 SDK,稳定可靠。
|
||||||
|
* **💬 多轮对话支持**:自动拼接历史上下文,Copilot 能理解你的前文。
|
||||||
|
* **🌊 流式输出 (Streaming)**:支持打字机效果,响应迅速。
|
||||||
|
* **🖼️ 多模态支持**:支持上传图片,自动转换为附件发送给 Copilot(需模型支持)。
|
||||||
|
* **🛠️ 零配置安装**:自动检测并下载 GitHub Copilot CLI,开箱即用。
|
||||||
|
* **🔑 安全认证**:支持 Fine-grained Personal Access Tokens,权限最小化。
|
||||||
|
* **🐛 调试模式**:内置详细的日志输出,方便排查连接问题。
|
||||||
|
|
||||||
|
## 📦 安装与使用
|
||||||
|
|
||||||
|
### 1. 导入函数
|
||||||
|
|
||||||
|
1. 打开 OpenWebUI。
|
||||||
|
2. 进入 **Workspace** -> **Functions**。
|
||||||
|
3. 点击 **+** (创建函数)。
|
||||||
|
4. 将 `github_copilot_sdk_cn.py` 的内容完整粘贴进去。
|
||||||
|
5. 保存。
|
||||||
|
|
||||||
|
### 2. 配置 Valves (设置)
|
||||||
|
|
||||||
|
在函数列表中找到 "GitHub Copilot",点击 **⚙️ (Valves)** 图标进行配置:
|
||||||
|
|
||||||
|
| 参数 | 说明 | 默认值 |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| **GH_TOKEN** | **(必填)** 你的 GitHub Token。 | - |
|
||||||
|
| **MODEL_ID** | 使用的模型名称。推荐 `gpt-5-mini` 或 `gpt-5`。 | `gpt-5-mini` |
|
||||||
|
| **CLI_PATH** | Copilot CLI 的路径。如果未找到会自动下载。 | `/usr/local/bin/copilot` |
|
||||||
|
| **DEBUG** | 是否开启调试日志(输出到对话框)。 | `True` |
|
||||||
|
| **SHOW_THINKING** | 是否显示模型推理/思考过程。 | `True` |
|
||||||
|
| **EXCLUDE_KEYWORDS** | 排除包含这些关键词的模型 (逗号分隔)。 | - |
|
||||||
|
| **WORKSPACE_DIR** | 文件操作的受限工作目录。 | - |
|
||||||
|
| **INFINITE_SESSION** | 启用无限会话 (自动上下文压缩)。 | `True` |
|
||||||
|
| **COMPACTION_THRESHOLD** | 后台压缩阈值 (0.0-1.0)。 | `0.8` |
|
||||||
|
| **BUFFER_THRESHOLD** | 缓冲耗尽阈值 (0.0-1.0)。 | `0.95` |
|
||||||
|
|
||||||
|
### 3. 获取 GH_TOKEN
|
||||||
|
|
||||||
|
为了安全起见,推荐使用 **Fine-grained Personal Access Token**:
|
||||||
|
|
||||||
|
1. 访问 [GitHub Token Settings](https://github.com/settings/tokens?type=beta)。
|
||||||
|
2. 点击 **Generate new token**。
|
||||||
|
3. **Repository access**: 选择 `All repositories` 或 `Public Repositories`。
|
||||||
|
4. **Permissions**:
|
||||||
|
* 点击 **Account permissions**。
|
||||||
|
* 找到 **Copilot Requests**,选择 **Read and write** (或 Access)。
|
||||||
|
5. 生成并复制 Token。
|
||||||
|
|
||||||
|
## 📋 依赖说明
|
||||||
|
|
||||||
|
该 Pipe 会自动尝试安装以下依赖(如果环境中缺失):
|
||||||
|
|
||||||
|
* `github-copilot-sdk` (Python 包)
|
||||||
|
* `github-copilot-cli` (二进制文件,通过官方脚本安装)
|
||||||
|
|
||||||
|
## ⚠️ 常见问题
|
||||||
|
|
||||||
|
* **一直显示 "Waiting..."**:
|
||||||
|
* 检查 `GH_TOKEN` 是否正确且拥有 `Copilot Requests` 权限。
|
||||||
|
* 尝试将 `MODEL_ID` 改为 `gpt-4o` 或 `copilot-chat`。
|
||||||
|
* **图片无法识别**:
|
||||||
|
* 确保 `MODEL_ID` 是支持多模态的模型。
|
||||||
|
* **CLI 安装失败**:
|
||||||
|
* 确保 OpenWebUI 容器有外网访问权限。
|
||||||
|
* 你可以手动下载 CLI 并挂载到容器中,然后在 Valves 中指定 `CLI_PATH`。
|
||||||
|
|
||||||
|
## 📄 许可证
|
||||||
|
|
||||||
|
MIT
|
||||||
@@ -15,7 +15,7 @@ Pipes allow you to:
|
|||||||
|
|
||||||
## Available Pipe Plugins
|
## Available Pipe Plugins
|
||||||
|
|
||||||
|
- [GitHub Copilot SDK](github-copilot-sdk.md) (v0.1.1) - Official GitHub Copilot SDK integration. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
@@ -15,7 +15,7 @@ Pipes 可以用于:
|
|||||||
|
|
||||||
## 可用的 Pipe 插件
|
## 可用的 Pipe 插件
|
||||||
|
|
||||||
|
- [GitHub Copilot SDK](github-copilot-sdk.zh.md) (v0.1.1) - GitHub Copilot SDK 官方集成。支持动态模型、多轮对话、流式输出、图片输入及无限会话。
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
@@ -1,9 +1,19 @@
|
|||||||
# Async Context Compression Filter
|
# Async Context Compression Filter
|
||||||
|
|
||||||
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.2.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 1.2.2 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||||
|
|
||||||
This filter reduces token consumption in long conversations through intelligent summarization and message compression while keeping conversations coherent.
|
This filter reduces token consumption in long conversations through intelligent summarization and message compression while keeping conversations coherent.
|
||||||
|
|
||||||
|
## What's new in 1.2.2
|
||||||
|
- **Critical Fix**: Resolved `TypeError: 'str' object is not callable` caused by variable name conflict in logging function.
|
||||||
|
- **Compatibility**: Enhanced `params` handling to support Pydantic objects, improving compatibility with different OpenWebUI versions.
|
||||||
|
|
||||||
|
## What's new in 1.2.1
|
||||||
|
|
||||||
|
- **Smart Configuration**: Automatically detects base model settings for custom models and adds `summary_model_max_context` for independent summary limits.
|
||||||
|
- **Performance & Refactoring**: Optimized threshold parsing with caching, removed redundant code, and improved LLM response handling (JSONResponse support).
|
||||||
|
- **Bug Fixes & Modernization**: Fixed `datetime` deprecation warnings, corrected type annotations, and replaced print statements with proper logging.
|
||||||
|
|
||||||
## What's new in 1.2.0
|
## What's new in 1.2.0
|
||||||
|
|
||||||
- **Preflight Context Check**: Before sending to the model, validates that total tokens fit within the context window. Automatically trims or drops oldest messages if exceeded.
|
- **Preflight Context Check**: Before sending to the model, validates that total tokens fit within the context window. Automatically trims or drops oldest messages if exceeded.
|
||||||
@@ -19,18 +29,6 @@ This filter reduces token consumption in long conversations through intelligent
|
|||||||
- **Enhanced Stability**: Fixed a race condition in state management that could cause "inlet state not found" warnings in high-concurrency scenarios.
|
- **Enhanced Stability**: Fixed a race condition in state management that could cause "inlet state not found" warnings in high-concurrency scenarios.
|
||||||
- **Bug Fixes**: Corrected default model handling to prevent misleading logs when no model is specified.
|
- **Bug Fixes**: Corrected default model handling to prevent misleading logs when no model is specified.
|
||||||
|
|
||||||
## What's new in 1.1.2
|
|
||||||
|
|
||||||
- **Open WebUI v0.7.x Compatibility**: Resolved a critical database session binding error affecting Open WebUI v0.7.x users. The plugin now dynamically discovers the database engine and session context, ensuring compatibility across versions.
|
|
||||||
- **Enhanced Error Reporting**: Errors during background summary generation are now reported via both the status bar and browser console.
|
|
||||||
- **Robust Model Handling**: Improved handling of missing or invalid model IDs to prevent crashes.
|
|
||||||
|
|
||||||
## What's new in 1.1.1
|
|
||||||
|
|
||||||
- **Frontend Debugging**: Added `show_debug_log` option to print debug info to the browser console (F12).
|
|
||||||
- **Optimized Compression**: Improved token calculation logic to prevent aggressive truncation of history, ensuring more context is retained.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -45,6 +43,8 @@ This filter reduces token consumption in long conversations through intelligent
|
|||||||
- ✅ Native tool output trimming for cleaner context when using function calling.
|
- ✅ Native tool output trimming for cleaner context when using function calling.
|
||||||
- ✅ Real-time context usage monitoring with warning notifications (>90%).
|
- ✅ Real-time context usage monitoring with warning notifications (>90%).
|
||||||
- ✅ Detailed token logging for precise debugging and optimization.
|
- ✅ Detailed token logging for precise debugging and optimization.
|
||||||
|
- ✅ **Smart Model Matching**: Automatically inherits configuration from base models for custom presets.
|
||||||
|
- ⚠ **Multimodal Support**: Images are preserved but their tokens are **NOT** calculated. Please adjust thresholds accordingly.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -75,7 +75,8 @@ It is recommended to keep this filter early in the chain so it runs before filte
|
|||||||
| `keep_first` | `1` | Always keep the first N messages (protects system prompts). |
|
| `keep_first` | `1` | Always keep the first N messages (protects system prompts). |
|
||||||
| `keep_last` | `6` | Always keep the last N messages to preserve recent context. |
|
| `keep_last` | `6` | Always keep the last N messages to preserve recent context. |
|
||||||
| `summary_model` | `None` | Model for summaries. Strongly recommended to set a fast, economical model (e.g., `gemini-2.5-flash`, `deepseek-v3`). Falls back to the current chat model when empty. |
|
| `summary_model` | `None` | Model for summaries. Strongly recommended to set a fast, economical model (e.g., `gemini-2.5-flash`, `deepseek-v3`). Falls back to the current chat model when empty. |
|
||||||
| `max_summary_tokens` | `4000` | Maximum tokens for the generated summary. |
|
| `summary_model_max_context` | `0` | Max context tokens for the summary model. If 0, falls back to `model_thresholds` or global `max_context_tokens`. |
|
||||||
|
| `max_summary_tokens` | `16384` | Maximum tokens for the generated summary. |
|
||||||
| `summary_temperature` | `0.3` | Randomness for summary generation. Lower is more deterministic. |
|
| `summary_temperature` | `0.3` | Randomness for summary generation. Lower is more deterministic. |
|
||||||
| `model_thresholds` | `{}` | Per-model overrides for `compression_threshold_tokens` and `max_context_tokens` (useful for mixed models). |
|
| `model_thresholds` | `{}` | Per-model overrides for `compression_threshold_tokens` and `max_context_tokens` (useful for mixed models). |
|
||||||
| `enable_tool_output_trimming` | `false` | When enabled and `function_calling: "native"` is active, trims verbose tool outputs to extract only the final answer. |
|
| `enable_tool_output_trimming` | `false` | When enabled and `function_calling: "native"` is active, trims verbose tool outputs to extract only the final answer. |
|
||||||
|
|||||||
@@ -1,11 +1,21 @@
|
|||||||
# 异步上下文压缩过滤器
|
# 异步上下文压缩过滤器
|
||||||
|
|
||||||
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.2.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 1.2.2 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||||
|
|
||||||
> **重要提示**:为了确保所有过滤器的可维护性和易用性,每个过滤器都应附带清晰、完整的文档,以确保其功能、配置和使用方法得到充分说明。
|
> **重要提示**:为了确保所有过滤器的可维护性和易用性,每个过滤器都应附带清晰、完整的文档,以确保其功能、配置和使用方法得到充分说明。
|
||||||
|
|
||||||
本过滤器通过智能摘要和消息压缩技术,在保持对话连贯性的同时,显著降低长对话的 Token 消耗。
|
本过滤器通过智能摘要和消息压缩技术,在保持对话连贯性的同时,显著降低长对话的 Token 消耗。
|
||||||
|
|
||||||
|
## 1.2.2 版本更新
|
||||||
|
- **严重错误修复**: 解决了因日志函数变量名冲突导致的 `TypeError: 'str' object is not callable` 错误。
|
||||||
|
- **兼容性增强**: 改进了 `params` 处理逻辑以支持 Pydantic 对象,提高了对不同 OpenWebUI 版本的兼容性。
|
||||||
|
|
||||||
|
## 1.2.1 版本更新
|
||||||
|
|
||||||
|
- **智能配置增强**: 自动检测自定义模型的基础模型配置,并新增 `summary_model_max_context` 参数以独立控制摘要模型的上下文限制。
|
||||||
|
- **性能优化与重构**: 重构了阈值解析逻辑并增加缓存,移除了冗余的处理代码,并增强了 LLM 响应处理(支持 JSONResponse)。
|
||||||
|
- **稳定性改进**: 修复了 `datetime` 弃用警告,修正了类型注解,并将 print 语句替换为标准日志记录。
|
||||||
|
|
||||||
## 1.2.0 版本更新
|
## 1.2.0 版本更新
|
||||||
|
|
||||||
- **预检上下文检查 (Preflight Context Check)**: 在发送给模型之前,验证总 Token 是否符合上下文窗口。如果超出,自动裁剪或丢弃最旧的消息。
|
- **预检上下文检查 (Preflight Context Check)**: 在发送给模型之前,验证总 Token 是否符合上下文窗口。如果超出,自动裁剪或丢弃最旧的消息。
|
||||||
@@ -21,18 +31,6 @@
|
|||||||
- **稳定性增强**: 修复了状态管理中的竞态条件,解决了高并发场景下可能出现的“无法获取 inlet 状态”警告。
|
- **稳定性增强**: 修复了状态管理中的竞态条件,解决了高并发场景下可能出现的“无法获取 inlet 状态”警告。
|
||||||
- **Bug 修复**: 修正了默认模型处理逻辑,防止在未指定模型时产生误导性日志。
|
- **Bug 修复**: 修正了默认模型处理逻辑,防止在未指定模型时产生误导性日志。
|
||||||
|
|
||||||
## 1.1.2 版本更新
|
|
||||||
|
|
||||||
- **Open WebUI v0.7.x 兼容性**: 修复了影响 Open WebUI v0.7.x 用户的严重数据库会话绑定错误。插件现在动态发现数据库引擎和会话上下文,确保跨版本兼容性。
|
|
||||||
- **增强错误报告**: 后台摘要生成过程中的错误现在会通过状态栏和浏览器控制台同时报告。
|
|
||||||
- **健壮的模型处理**: 改进了对缺失或无效模型 ID 的处理,防止程序崩溃。
|
|
||||||
|
|
||||||
## 1.1.1 版本更新
|
|
||||||
|
|
||||||
- **前端调试**: 新增 `show_debug_log` 选项,支持在浏览器控制台 (F12) 打印调试信息。
|
|
||||||
- **压缩优化**: 优化 Token 计算逻辑,防止历史记录被过度截断,保留更多上下文。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -47,6 +45,8 @@
|
|||||||
- ✅ **原生工具输出裁剪**: 支持裁剪冗长的工具调用输出。
|
- ✅ **原生工具输出裁剪**: 支持裁剪冗长的工具调用输出。
|
||||||
- ✅ **实时监控**: 实时监控上下文使用情况,超过 90% 发出警告。
|
- ✅ **实时监控**: 实时监控上下文使用情况,超过 90% 发出警告。
|
||||||
- ✅ **详细日志**: 提供精确的 Token 统计日志,便于调试。
|
- ✅ **详细日志**: 提供精确的 Token 统计日志,便于调试。
|
||||||
|
- ✅ **智能模型匹配**: 自定义模型自动继承基础模型的阈值配置。
|
||||||
|
- ⚠ **多模态支持**: 图片内容会被保留,但其 Token **不参与计算**。请相应调整阈值。
|
||||||
|
|
||||||
详细的工作原理和流程请参考 [工作流程指南](WORKFLOW_GUIDE_CN.md)。
|
详细的工作原理和流程请参考 [工作流程指南](WORKFLOW_GUIDE_CN.md)。
|
||||||
|
|
||||||
@@ -88,6 +88,7 @@
|
|||||||
| 参数 | 默认值 | 描述 |
|
| 参数 | 默认值 | 描述 |
|
||||||
| :-------------------- | :------ | :------------------------------------------------------------------------------------------------------------------------------------------ |
|
| :-------------------- | :------ | :------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||||
| `summary_model` | `None` | 用于生成摘要的模型 ID。**强烈建议**配置快速、经济、上下文窗口大的模型(如 `gemini-2.5-flash`、`deepseek-v3`)。留空则尝试复用当前对话模型。 |
|
| `summary_model` | `None` | 用于生成摘要的模型 ID。**强烈建议**配置快速、经济、上下文窗口大的模型(如 `gemini-2.5-flash`、`deepseek-v3`)。留空则尝试复用当前对话模型。 |
|
||||||
|
| `summary_model_max_context` | `0` | 摘要模型的最大上下文 Token 数。如果为 0,则回退到 `model_thresholds` 或全局 `max_context_tokens`。 |
|
||||||
| `max_summary_tokens` | `16384` | 生成摘要时允许的最大 Token 数。 |
|
| `max_summary_tokens` | `16384` | 生成摘要时允许的最大 Token 数。 |
|
||||||
| `summary_temperature` | `0.1` | 控制摘要生成的随机性,较低的值结果更稳定。 |
|
| `summary_temperature` | `0.1` | 控制摘要生成的随机性,较低的值结果更稳定。 |
|
||||||
|
|
||||||
|
|||||||
@@ -5,19 +5,17 @@ author: Fu-Jie
|
|||||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
funding_url: https://github.com/open-webui
|
funding_url: https://github.com/open-webui
|
||||||
description: Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.
|
description: Reduces token consumption in long conversations while maintaining coherence through intelligent summarization and message compression.
|
||||||
version: 1.2.0
|
version: 1.2.2
|
||||||
openwebui_id: b1655bc8-6de9-4cad-8cb5-a6f7829a02ce
|
openwebui_id: b1655bc8-6de9-4cad-8cb5-a6f7829a02ce
|
||||||
license: MIT
|
license: MIT
|
||||||
|
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
📌 What's new in 1.2.0
|
📌 What's new in 1.2.1
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
|
|
||||||
✅ Preflight Context Check: Validates context fit before sending to model.
|
✅ Smart Configuration: Automatically detects base model settings for custom models and adds `summary_model_max_context` for independent summary limits.
|
||||||
✅ Structure-Aware Trimming: Collapses long AI responses while keeping H1-H6, intro, and conclusion.
|
✅ Performance & Refactoring: Optimized threshold parsing with caching and removed redundant code for better efficiency.
|
||||||
✅ Native Tool Output Trimming: Cleaner context when using function calling. (Note: Non-native tool outputs are not fully injected into context)
|
✅ Bug Fixes & Modernization: Fixed `datetime` deprecation warnings and corrected type annotations.
|
||||||
✅ Context Usage Warning: Notification when usage exceeds 90%.
|
|
||||||
✅ Detailed Token Logging: Granular breakdown of System, Head, Summary, and Tail tokens.
|
|
||||||
|
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
📌 Overview
|
📌 Overview
|
||||||
@@ -229,6 +227,8 @@ Statistics:
|
|||||||
✓ This filter supports multimodal messages containing images.
|
✓ This filter supports multimodal messages containing images.
|
||||||
✓ The summary is generated only from the text content.
|
✓ The summary is generated only from the text content.
|
||||||
✓ Non-text parts (like images) are preserved in their original messages during compression.
|
✓ Non-text parts (like images) are preserved in their original messages during compression.
|
||||||
|
⚠ Image tokens are NOT calculated. Different models have vastly different image token costs
|
||||||
|
(GPT-4o: 85-1105, Claude: ~1300, Gemini: ~258 per image). Plan your thresholds accordingly.
|
||||||
|
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
🐛 Troubleshooting
|
🐛 Troubleshooting
|
||||||
@@ -259,7 +259,7 @@ Solution:
|
|||||||
|
|
||||||
"""
|
"""
|
||||||
|
|
||||||
from pydantic import BaseModel, Field, model_validator
|
from pydantic import BaseModel, Field
|
||||||
from typing import Optional, Dict, Any, List, Union, Callable, Awaitable
|
from typing import Optional, Dict, Any, List, Union, Callable, Awaitable
|
||||||
import re
|
import re
|
||||||
import asyncio
|
import asyncio
|
||||||
@@ -267,6 +267,10 @@ import json
|
|||||||
import hashlib
|
import hashlib
|
||||||
import time
|
import time
|
||||||
import contextlib
|
import contextlib
|
||||||
|
import logging
|
||||||
|
|
||||||
|
# Setup logger
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
# Open WebUI built-in imports
|
# Open WebUI built-in imports
|
||||||
from open_webui.utils.chat import generate_chat_completion
|
from open_webui.utils.chat import generate_chat_completion
|
||||||
@@ -291,7 +295,7 @@ except ImportError:
|
|||||||
from sqlalchemy import Column, String, Text, DateTime, Integer, inspect
|
from sqlalchemy import Column, String, Text, DateTime, Integer, inspect
|
||||||
from sqlalchemy.orm import declarative_base, sessionmaker
|
from sqlalchemy.orm import declarative_base, sessionmaker
|
||||||
from sqlalchemy.engine import Engine
|
from sqlalchemy.engine import Engine
|
||||||
from datetime import datetime
|
from datetime import datetime, timezone
|
||||||
|
|
||||||
|
|
||||||
def _discover_owui_engine(db_module: Any) -> Optional[Engine]:
|
def _discover_owui_engine(db_module: Any) -> Optional[Engine]:
|
||||||
@@ -312,7 +316,7 @@ def _discover_owui_engine(db_module: Any) -> Optional[Engine]:
|
|||||||
session, "engine", None
|
session, "engine", None
|
||||||
)
|
)
|
||||||
except Exception as exc:
|
except Exception as exc:
|
||||||
print(f"[DB Discover] get_db_context failed: {exc}")
|
logger.error(f"[DB Discover] get_db_context failed: {exc}")
|
||||||
|
|
||||||
for attr in ("engine", "ENGINE", "bind", "BIND"):
|
for attr in ("engine", "ENGINE", "bind", "BIND"):
|
||||||
candidate = getattr(db_module, attr, None)
|
candidate = getattr(db_module, attr, None)
|
||||||
@@ -334,7 +338,7 @@ def _discover_owui_schema(db_module: Any) -> Optional[str]:
|
|||||||
if isinstance(candidate, str) and candidate.strip():
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
return candidate.strip()
|
return candidate.strip()
|
||||||
except Exception as exc:
|
except Exception as exc:
|
||||||
print(f"[DB Discover] Base metadata schema lookup failed: {exc}")
|
logger.error(f"[DB Discover] Base metadata schema lookup failed: {exc}")
|
||||||
|
|
||||||
try:
|
try:
|
||||||
metadata_obj = getattr(db_module, "metadata_obj", None)
|
metadata_obj = getattr(db_module, "metadata_obj", None)
|
||||||
@@ -344,7 +348,7 @@ def _discover_owui_schema(db_module: Any) -> Optional[str]:
|
|||||||
if isinstance(candidate, str) and candidate.strip():
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
return candidate.strip()
|
return candidate.strip()
|
||||||
except Exception as exc:
|
except Exception as exc:
|
||||||
print(f"[DB Discover] metadata_obj schema lookup failed: {exc}")
|
logger.error(f"[DB Discover] metadata_obj schema lookup failed: {exc}")
|
||||||
|
|
||||||
try:
|
try:
|
||||||
from open_webui import env as owui_env
|
from open_webui import env as owui_env
|
||||||
@@ -353,7 +357,7 @@ def _discover_owui_schema(db_module: Any) -> Optional[str]:
|
|||||||
if isinstance(candidate, str) and candidate.strip():
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
return candidate.strip()
|
return candidate.strip()
|
||||||
except Exception as exc:
|
except Exception as exc:
|
||||||
print(f"[DB Discover] env schema lookup failed: {exc}")
|
logger.error(f"[DB Discover] env schema lookup failed: {exc}")
|
||||||
|
|
||||||
return None
|
return None
|
||||||
|
|
||||||
@@ -379,8 +383,21 @@ class ChatSummary(owui_Base):
|
|||||||
chat_id = Column(String(255), unique=True, nullable=False, index=True)
|
chat_id = Column(String(255), unique=True, nullable=False, index=True)
|
||||||
summary = Column(Text, nullable=False)
|
summary = Column(Text, nullable=False)
|
||||||
compressed_message_count = Column(Integer, default=0)
|
compressed_message_count = Column(Integer, default=0)
|
||||||
created_at = Column(DateTime, default=datetime.utcnow)
|
created_at = Column(DateTime, default=lambda: datetime.now(timezone.utc))
|
||||||
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
|
updated_at = Column(
|
||||||
|
DateTime,
|
||||||
|
default=lambda: datetime.now(timezone.utc),
|
||||||
|
onupdate=lambda: datetime.now(timezone.utc),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# Global cache for tiktoken encoding
|
||||||
|
TIKTOKEN_ENCODING = None
|
||||||
|
if tiktoken:
|
||||||
|
try:
|
||||||
|
TIKTOKEN_ENCODING = tiktoken.get_encoding("o200k_base")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"[Init] Failed to load tiktoken encoding: {e}")
|
||||||
|
|
||||||
|
|
||||||
class Filter:
|
class Filter:
|
||||||
@@ -391,8 +408,48 @@ class Filter:
|
|||||||
self._fallback_session_factory = (
|
self._fallback_session_factory = (
|
||||||
sessionmaker(bind=self._db_engine) if self._db_engine else None
|
sessionmaker(bind=self._db_engine) if self._db_engine else None
|
||||||
)
|
)
|
||||||
|
self._model_thresholds_cache: Optional[Dict[str, Any]] = None
|
||||||
self._init_database()
|
self._init_database()
|
||||||
|
|
||||||
|
def _parse_model_thresholds(self) -> Dict[str, Any]:
|
||||||
|
"""Parse model_thresholds string into a dictionary.
|
||||||
|
|
||||||
|
Format: model_id:compression_threshold:max_context, model_id2:threshold2:max2
|
||||||
|
Example: gpt-4:8000:32000, claude-3:100000:200000
|
||||||
|
|
||||||
|
Returns cached result if already parsed.
|
||||||
|
"""
|
||||||
|
if self._model_thresholds_cache is not None:
|
||||||
|
return self._model_thresholds_cache
|
||||||
|
|
||||||
|
self._model_thresholds_cache = {}
|
||||||
|
raw_config = self.valves.model_thresholds
|
||||||
|
if not raw_config:
|
||||||
|
return self._model_thresholds_cache
|
||||||
|
|
||||||
|
for entry in raw_config.split(","):
|
||||||
|
entry = entry.strip()
|
||||||
|
if not entry:
|
||||||
|
continue
|
||||||
|
|
||||||
|
parts = entry.split(":")
|
||||||
|
if len(parts) != 3:
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
model_id = parts[0].strip()
|
||||||
|
compression_threshold = int(parts[1].strip())
|
||||||
|
max_context = int(parts[2].strip())
|
||||||
|
|
||||||
|
self._model_thresholds_cache[model_id] = {
|
||||||
|
"compression_threshold_tokens": compression_threshold,
|
||||||
|
"max_context_tokens": max_context,
|
||||||
|
}
|
||||||
|
except ValueError:
|
||||||
|
continue
|
||||||
|
|
||||||
|
return self._model_thresholds_cache
|
||||||
|
|
||||||
@contextlib.contextmanager
|
@contextlib.contextmanager
|
||||||
def _db_session(self):
|
def _db_session(self):
|
||||||
"""Yield a database session using Open WebUI helpers with graceful fallbacks."""
|
"""Yield a database session using Open WebUI helpers with graceful fallbacks."""
|
||||||
@@ -435,7 +492,7 @@ class Filter:
|
|||||||
try:
|
try:
|
||||||
session.close()
|
session.close()
|
||||||
except Exception as exc: # pragma: no cover - best-effort cleanup
|
except Exception as exc: # pragma: no cover - best-effort cleanup
|
||||||
print(f"[Database] ⚠️ Failed to close fallback session: {exc}")
|
logger.warning(f"[Database] ⚠️ Failed to close fallback session: {exc}")
|
||||||
|
|
||||||
def _init_database(self):
|
def _init_database(self):
|
||||||
"""Initializes the database table using Open WebUI's shared connection."""
|
"""Initializes the database table using Open WebUI's shared connection."""
|
||||||
@@ -447,19 +504,26 @@ class Filter:
|
|||||||
|
|
||||||
# Check if table exists using SQLAlchemy inspect
|
# Check if table exists using SQLAlchemy inspect
|
||||||
inspector = inspect(self._db_engine)
|
inspector = inspect(self._db_engine)
|
||||||
if not inspector.has_table("chat_summary"):
|
# Support schema if configured
|
||||||
|
has_table = (
|
||||||
|
inspector.has_table("chat_summary", schema=owui_schema)
|
||||||
|
if owui_schema
|
||||||
|
else inspector.has_table("chat_summary")
|
||||||
|
)
|
||||||
|
|
||||||
|
if not has_table:
|
||||||
# Create the chat_summary table if it doesn't exist
|
# Create the chat_summary table if it doesn't exist
|
||||||
ChatSummary.__table__.create(bind=self._db_engine, checkfirst=True)
|
ChatSummary.__table__.create(bind=self._db_engine, checkfirst=True)
|
||||||
print(
|
logger.info(
|
||||||
"[Database] ✅ Successfully created chat_summary table using Open WebUI's shared database connection."
|
"[Database] ✅ Successfully created chat_summary table using Open WebUI's shared database connection."
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
print(
|
logger.info(
|
||||||
"[Database] ✅ Using Open WebUI's shared database connection. chat_summary table already exists."
|
"[Database] ✅ Using Open WebUI's shared database connection. chat_summary table already exists."
|
||||||
)
|
)
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[Database] ❌ Initialization failed: {str(e)}")
|
logger.error(f"[Database] ❌ Initialization failed: {str(e)}")
|
||||||
|
|
||||||
class Valves(BaseModel):
|
class Valves(BaseModel):
|
||||||
priority: int = Field(
|
priority: int = Field(
|
||||||
@@ -476,9 +540,9 @@ class Filter:
|
|||||||
ge=0,
|
ge=0,
|
||||||
description="Hard limit for context. Exceeding this value will force removal of earliest messages (Global Default)",
|
description="Hard limit for context. Exceeding this value will force removal of earliest messages (Global Default)",
|
||||||
)
|
)
|
||||||
model_thresholds: dict = Field(
|
model_thresholds: str = Field(
|
||||||
default={},
|
default="",
|
||||||
description="Threshold override configuration for specific models. Only includes models requiring special configuration.",
|
description="Per-model threshold overrides. Format: model_id:compression_threshold:max_context (comma-separated). Example: gpt-4:8000:32000, claude-3:100000:200000",
|
||||||
)
|
)
|
||||||
|
|
||||||
keep_first: int = Field(
|
keep_first: int = Field(
|
||||||
@@ -489,10 +553,15 @@ class Filter:
|
|||||||
keep_last: int = Field(
|
keep_last: int = Field(
|
||||||
default=6, ge=0, description="Always keep the last N full messages."
|
default=6, ge=0, description="Always keep the last N full messages."
|
||||||
)
|
)
|
||||||
summary_model: str = Field(
|
summary_model: Optional[str] = Field(
|
||||||
default=None,
|
default=None,
|
||||||
description="The model ID used to generate the summary. If empty, uses the current conversation's model. Used to match configurations in model_thresholds.",
|
description="The model ID used to generate the summary. If empty, uses the current conversation's model. Used to match configurations in model_thresholds.",
|
||||||
)
|
)
|
||||||
|
summary_model_max_context: int = Field(
|
||||||
|
default=0,
|
||||||
|
ge=0,
|
||||||
|
description="Max context tokens for the summary model. If 0, falls back to model_thresholds or global max_context_tokens. Example: gemini-flash=1000000, gpt-4o-mini=128000.",
|
||||||
|
)
|
||||||
max_summary_tokens: int = Field(
|
max_summary_tokens: int = Field(
|
||||||
default=16384,
|
default=16384,
|
||||||
ge=1,
|
ge=1,
|
||||||
@@ -529,7 +598,7 @@ class Filter:
|
|||||||
# [Optimization] Optimistic lock check: update only if progress moves forward
|
# [Optimization] Optimistic lock check: update only if progress moves forward
|
||||||
if compressed_count <= existing.compressed_message_count:
|
if compressed_count <= existing.compressed_message_count:
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.info(
|
||||||
f"[Storage] Skipping update: New progress ({compressed_count}) is not greater than existing progress ({existing.compressed_message_count})"
|
f"[Storage] Skipping update: New progress ({compressed_count}) is not greater than existing progress ({existing.compressed_message_count})"
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
@@ -537,7 +606,7 @@ class Filter:
|
|||||||
# Update existing record
|
# Update existing record
|
||||||
existing.summary = summary
|
existing.summary = summary
|
||||||
existing.compressed_message_count = compressed_count
|
existing.compressed_message_count = compressed_count
|
||||||
existing.updated_at = datetime.utcnow()
|
existing.updated_at = datetime.now(timezone.utc)
|
||||||
else:
|
else:
|
||||||
# Create new record
|
# Create new record
|
||||||
new_summary = ChatSummary(
|
new_summary = ChatSummary(
|
||||||
@@ -551,12 +620,12 @@ class Filter:
|
|||||||
|
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
action = "Updated" if existing else "Created"
|
action = "Updated" if existing else "Created"
|
||||||
print(
|
logger.info(
|
||||||
f"[Storage] Summary has been {action.lower()} in the database (Chat ID: {chat_id})"
|
f"[Storage] Summary has been {action.lower()} in the database (Chat ID: {chat_id})"
|
||||||
)
|
)
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[Storage] ❌ Database save failed: {str(e)}")
|
logger.error(f"[Storage] ❌ Database save failed: {str(e)}")
|
||||||
|
|
||||||
def _load_summary_record(self, chat_id: str) -> Optional[ChatSummary]:
|
def _load_summary_record(self, chat_id: str) -> Optional[ChatSummary]:
|
||||||
"""Loads the summary record object from the database."""
|
"""Loads the summary record object from the database."""
|
||||||
@@ -568,7 +637,7 @@ class Filter:
|
|||||||
session.expunge(record)
|
session.expunge(record)
|
||||||
return record
|
return record
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[Load] ❌ Database read failed: {str(e)}")
|
logger.error(f"[Load] ❌ Database read failed: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
def _load_summary(self, chat_id: str, body: dict) -> Optional[str]:
|
def _load_summary(self, chat_id: str, body: dict) -> Optional[str]:
|
||||||
@@ -576,8 +645,8 @@ class Filter:
|
|||||||
record = self._load_summary_record(chat_id)
|
record = self._load_summary_record(chat_id)
|
||||||
if record:
|
if record:
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(f"[Load] Loaded summary from database (Chat ID: {chat_id})")
|
logger.info(f"[Load] Loaded summary from database (Chat ID: {chat_id})")
|
||||||
print(
|
logger.info(
|
||||||
f"[Load] Last updated: {record.updated_at}, Compressed message count: {record.compressed_message_count}"
|
f"[Load] Last updated: {record.updated_at}, Compressed message count: {record.compressed_message_count}"
|
||||||
)
|
)
|
||||||
return record.summary
|
return record.summary
|
||||||
@@ -588,14 +657,12 @@ class Filter:
|
|||||||
if not text:
|
if not text:
|
||||||
return 0
|
return 0
|
||||||
|
|
||||||
if tiktoken:
|
if TIKTOKEN_ENCODING:
|
||||||
try:
|
try:
|
||||||
# Uniformly use o200k_base encoding (adapted for latest models)
|
return len(TIKTOKEN_ENCODING.encode(text))
|
||||||
encoding = tiktoken.get_encoding("o200k_base")
|
|
||||||
return len(encoding.encode(text))
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.warning(
|
||||||
f"[Token Count] tiktoken error: {e}, falling back to character estimation"
|
f"[Token Count] tiktoken error: {e}, falling back to character estimation"
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -604,6 +671,7 @@ class Filter:
|
|||||||
|
|
||||||
def _calculate_messages_tokens(self, messages: List[Dict]) -> int:
|
def _calculate_messages_tokens(self, messages: List[Dict]) -> int:
|
||||||
"""Calculates the total tokens for a list of messages."""
|
"""Calculates the total tokens for a list of messages."""
|
||||||
|
start_time = time.time()
|
||||||
total_tokens = 0
|
total_tokens = 0
|
||||||
for msg in messages:
|
for msg in messages:
|
||||||
content = msg.get("content", "")
|
content = msg.get("content", "")
|
||||||
@@ -616,6 +684,13 @@ class Filter:
|
|||||||
total_tokens += self._count_tokens(text_content)
|
total_tokens += self._count_tokens(text_content)
|
||||||
else:
|
else:
|
||||||
total_tokens += self._count_tokens(str(content))
|
total_tokens += self._count_tokens(str(content))
|
||||||
|
|
||||||
|
duration = (time.time() - start_time) * 1000
|
||||||
|
if self.valves.debug_mode:
|
||||||
|
logger.info(
|
||||||
|
f"[Token Calc] Calculated {total_tokens} tokens for {len(messages)} messages in {duration:.2f}ms"
|
||||||
|
)
|
||||||
|
|
||||||
return total_tokens
|
return total_tokens
|
||||||
|
|
||||||
def _get_model_thresholds(self, model_id: str) -> Dict[str, int]:
|
def _get_model_thresholds(self, model_id: str) -> Dict[str, int]:
|
||||||
@@ -623,17 +698,48 @@ class Filter:
|
|||||||
|
|
||||||
Priority:
|
Priority:
|
||||||
1. If configuration exists for the model ID in model_thresholds, use it.
|
1. If configuration exists for the model ID in model_thresholds, use it.
|
||||||
2. Otherwise, use global parameters compression_threshold_tokens and max_context_tokens.
|
2. If model is a custom model, try to match its base_model_id.
|
||||||
|
3. Otherwise, use global parameters compression_threshold_tokens and max_context_tokens.
|
||||||
"""
|
"""
|
||||||
# Try to match from model-specific configuration
|
parsed = self._parse_model_thresholds()
|
||||||
if model_id in self.valves.model_thresholds:
|
|
||||||
if self.valves.debug_mode:
|
|
||||||
print(f"[Config] Using model-specific configuration: {model_id}")
|
|
||||||
return self.valves.model_thresholds[model_id]
|
|
||||||
|
|
||||||
# Use global default configuration
|
# 1. Direct match with model_id
|
||||||
|
if model_id in parsed:
|
||||||
|
if self.valves.debug_mode:
|
||||||
|
logger.info(f"[Config] Using model-specific configuration: {model_id}")
|
||||||
|
return parsed[model_id]
|
||||||
|
|
||||||
|
# 2. Try to find base_model_id for custom models
|
||||||
|
try:
|
||||||
|
model_obj = Models.get_model_by_id(model_id)
|
||||||
|
if model_obj:
|
||||||
|
# Check for base_model_id (custom model)
|
||||||
|
base_model_id = getattr(model_obj, "base_model_id", None)
|
||||||
|
if not base_model_id:
|
||||||
|
# Try base_model_ids (array) - take first one
|
||||||
|
base_model_ids = getattr(model_obj, "base_model_ids", None)
|
||||||
|
if (
|
||||||
|
base_model_ids
|
||||||
|
and isinstance(base_model_ids, list)
|
||||||
|
and len(base_model_ids) > 0
|
||||||
|
):
|
||||||
|
base_model_id = base_model_ids[0]
|
||||||
|
|
||||||
|
if base_model_id and base_model_id in parsed:
|
||||||
|
if self.valves.debug_mode:
|
||||||
|
logger.info(
|
||||||
|
f"[Config] Custom model '{model_id}' -> base_model '{base_model_id}': using base model configuration"
|
||||||
|
)
|
||||||
|
return parsed[base_model_id]
|
||||||
|
except Exception as e:
|
||||||
|
if self.valves.debug_mode:
|
||||||
|
logger.warning(
|
||||||
|
f"[Config] Failed to lookup base_model for '{model_id}': {e}"
|
||||||
|
)
|
||||||
|
|
||||||
|
# 3. Use global default configuration
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.info(
|
||||||
f"[Config] Model {model_id} not in model_thresholds, using global parameters"
|
f"[Config] Model {model_id} not in model_thresholds, using global parameters"
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -731,23 +837,23 @@ class Filter:
|
|||||||
}
|
}
|
||||||
)
|
)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Error emitting debug log: {e}")
|
logger.error(f"Error emitting debug log: {e}")
|
||||||
|
|
||||||
async def _log(self, message: str, type: str = "info", event_call=None):
|
async def _log(self, message: str, log_type: str = "info", event_call=None):
|
||||||
"""Unified logging to both backend (print) and frontend (console.log)"""
|
"""Unified logging to both backend (print) and frontend (console.log)"""
|
||||||
# Backend logging
|
# Backend logging
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(message)
|
logger.info(message)
|
||||||
|
|
||||||
# Frontend logging
|
# Frontend logging
|
||||||
if self.valves.show_debug_log and event_call:
|
if self.valves.show_debug_log and event_call:
|
||||||
try:
|
try:
|
||||||
css = "color: #3b82f6;" # Blue default
|
css = "color: #3b82f6;" # Blue default
|
||||||
if type == "error":
|
if log_type == "error":
|
||||||
css = "color: #ef4444; font-weight: bold;" # Red
|
css = "color: #ef4444; font-weight: bold;" # Red
|
||||||
elif type == "warning":
|
elif log_type == "warning":
|
||||||
css = "color: #f59e0b;" # Orange
|
css = "color: #f59e0b;" # Orange
|
||||||
elif type == "success":
|
elif log_type == "success":
|
||||||
css = "color: #10b981; font-weight: bold;" # Green
|
css = "color: #10b981; font-weight: bold;" # Green
|
||||||
|
|
||||||
# Clean message for frontend: remove separators and extra newlines
|
# Clean message for frontend: remove separators and extra newlines
|
||||||
@@ -770,9 +876,17 @@ class Filter:
|
|||||||
js_code = f"""
|
js_code = f"""
|
||||||
console.log("%c[Compression] {safe_message}", "{css}");
|
console.log("%c[Compression] {safe_message}", "{css}");
|
||||||
"""
|
"""
|
||||||
await event_call({"type": "execute", "data": {"code": js_code}})
|
# Add timeout to prevent blocking if frontend connection is broken
|
||||||
|
await asyncio.wait_for(
|
||||||
|
event_call({"type": "execute", "data": {"code": js_code}}),
|
||||||
|
timeout=2.0,
|
||||||
|
)
|
||||||
|
except asyncio.TimeoutError:
|
||||||
|
logger.warning(
|
||||||
|
f"Failed to emit log to frontend: Timeout (connection may be broken)"
|
||||||
|
)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Failed to emit log to frontend: {e}")
|
logger.error(f"Failed to emit log to frontend: {type(e).__name__}: {e}")
|
||||||
|
|
||||||
async def inlet(
|
async def inlet(
|
||||||
self,
|
self,
|
||||||
@@ -819,42 +933,57 @@ class Filter:
|
|||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
# Extract the final answer (after last tool call metadata)
|
# Strategy 1: Tool Output / Code Block Trimming
|
||||||
# Pattern: Matches escaped JSON strings like """...""" followed by newlines
|
# Detect if message contains large tool outputs or code blocks
|
||||||
# We look for the last occurrence of such a pattern and take everything after it
|
# Improved regex to be less brittle
|
||||||
|
is_tool_output = (
|
||||||
# 1. Try matching the specific OpenWebUI tool output format: """..."""
|
""" in content
|
||||||
# This regex finds the last end-quote of a tool output block
|
or "Arguments:" in content
|
||||||
tool_output_pattern = r'""".*?"""\s*'
|
or "```" in content
|
||||||
|
or "<tool_code>" in content
|
||||||
# Find all matches
|
|
||||||
matches = list(
|
|
||||||
re.finditer(tool_output_pattern, content, re.DOTALL)
|
|
||||||
)
|
)
|
||||||
|
|
||||||
if matches:
|
if is_tool_output:
|
||||||
# Get the end position of the last match
|
# Regex to find the last occurrence of a tool output block or code block
|
||||||
last_match_end = matches[-1].end()
|
# This pattern looks for:
|
||||||
|
# 1. OpenWebUI's escaped JSON format: """..."""
|
||||||
|
# 2. "Arguments: {...}" pattern
|
||||||
|
# 3. Generic code blocks: ```...```
|
||||||
|
# 4. <tool_code>...</tool_code>
|
||||||
|
# It captures the content *after* the last such block.
|
||||||
|
tool_output_pattern = r'(?:""".*?"""|Arguments:\s*\{[^}]+\}|```.*?```|<tool_code>.*?</tool_code>)\s*'
|
||||||
|
|
||||||
# Everything after the last tool output is the final answer
|
# Find all matches
|
||||||
final_answer = content[last_match_end:].strip()
|
matches = list(
|
||||||
|
re.finditer(tool_output_pattern, content, re.DOTALL)
|
||||||
|
)
|
||||||
|
|
||||||
|
if matches:
|
||||||
|
# Get the end position of the last match
|
||||||
|
last_match_end = matches[-1].end()
|
||||||
|
|
||||||
|
# Everything after the last tool output is the final answer
|
||||||
|
final_answer = content[last_match_end:].strip()
|
||||||
|
|
||||||
if final_answer:
|
|
||||||
msg["content"] = (
|
|
||||||
f"... [Tool outputs trimmed]\n{final_answer}"
|
|
||||||
)
|
|
||||||
trimmed_count += 1
|
|
||||||
else:
|
|
||||||
# Fallback: Try splitting on "Arguments:" if the new format isn't found
|
|
||||||
# (Preserving backward compatibility or different model behaviors)
|
|
||||||
parts = re.split(r"(?:Arguments:\s*\{[^}]+\})\n+", content)
|
|
||||||
if len(parts) > 1:
|
|
||||||
final_answer = parts[-1].strip()
|
|
||||||
if final_answer:
|
if final_answer:
|
||||||
msg["content"] = (
|
msg["content"] = (
|
||||||
f"... [Tool outputs trimmed]\n{final_answer}"
|
f"... [Tool outputs trimmed]\n{final_answer}"
|
||||||
)
|
)
|
||||||
trimmed_count += 1
|
trimmed_count += 1
|
||||||
|
else:
|
||||||
|
# Fallback: If no specific pattern matched, but it was identified as tool output,
|
||||||
|
# try a simpler split or just mark as trimmed if no final answer can be extracted.
|
||||||
|
# (Preserving backward compatibility or different model behaviors)
|
||||||
|
parts = re.split(
|
||||||
|
r"(?:Arguments:\s*\{[^}]+\})\n+", content
|
||||||
|
)
|
||||||
|
if len(parts) > 1:
|
||||||
|
final_answer = parts[-1].strip()
|
||||||
|
if final_answer:
|
||||||
|
msg["content"] = (
|
||||||
|
f"... [Tool outputs trimmed]\n{final_answer}"
|
||||||
|
)
|
||||||
|
trimmed_count += 1
|
||||||
|
|
||||||
if trimmed_count > 0 and self.valves.show_debug_log and __event_call__:
|
if trimmed_count > 0 and self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
@@ -870,6 +999,7 @@ class Filter:
|
|||||||
# 2. For base models: check messages for role='system'
|
# 2. For base models: check messages for role='system'
|
||||||
system_prompt_content = None
|
system_prompt_content = None
|
||||||
|
|
||||||
|
# Try to get from DB (custom model)
|
||||||
# Try to get from DB (custom model)
|
# Try to get from DB (custom model)
|
||||||
try:
|
try:
|
||||||
model_id = body.get("model")
|
model_id = body.get("model")
|
||||||
@@ -881,7 +1011,8 @@ class Filter:
|
|||||||
)
|
)
|
||||||
|
|
||||||
# Clean model ID if needed (though get_model_by_id usually expects the full ID)
|
# Clean model ID if needed (though get_model_by_id usually expects the full ID)
|
||||||
model_obj = Models.get_model_by_id(model_id)
|
# Run in thread to avoid blocking event loop on slow DB queries
|
||||||
|
model_obj = await asyncio.to_thread(Models.get_model_by_id, model_id)
|
||||||
|
|
||||||
if model_obj:
|
if model_obj:
|
||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
@@ -896,12 +1027,17 @@ class Filter:
|
|||||||
# Handle case where params is a JSON string
|
# Handle case where params is a JSON string
|
||||||
if isinstance(params, str):
|
if isinstance(params, str):
|
||||||
params = json.loads(params)
|
params = json.loads(params)
|
||||||
|
# Convert Pydantic model to dict if needed
|
||||||
|
elif hasattr(params, "model_dump"):
|
||||||
|
params = params.model_dump()
|
||||||
|
elif hasattr(params, "dict"):
|
||||||
|
params = params.dict()
|
||||||
|
|
||||||
# Handle dict or Pydantic object
|
# Now params should be a dict
|
||||||
if isinstance(params, dict):
|
if isinstance(params, dict):
|
||||||
system_prompt_content = params.get("system")
|
system_prompt_content = params.get("system")
|
||||||
else:
|
else:
|
||||||
# Assume Pydantic model or object
|
# Fallback: try getattr
|
||||||
system_prompt_content = getattr(params, "system", None)
|
system_prompt_content = getattr(params, "system", None)
|
||||||
|
|
||||||
if system_prompt_content:
|
if system_prompt_content:
|
||||||
@@ -920,7 +1056,7 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ Failed to parse model params: {e}",
|
f"[Inlet] ❌ Failed to parse model params: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -933,8 +1069,7 @@ class Filter:
|
|||||||
else:
|
else:
|
||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ Model NOT found in DB",
|
f"[Inlet] ℹ️ Not a custom model, skipping custom system prompt check",
|
||||||
type="warning",
|
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -942,11 +1077,11 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ Error fetching system prompt from DB: {e}",
|
f"[Inlet] ❌ Error fetching system prompt from DB: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(f"[Inlet] Error fetching system prompt from DB: {e}")
|
logger.error(f"[Inlet] Error fetching system prompt from DB: {e}")
|
||||||
|
|
||||||
# Fall back to checking messages (base model or already included)
|
# Fall back to checking messages (base model or already included)
|
||||||
if not system_prompt_content:
|
if not system_prompt_content:
|
||||||
@@ -960,7 +1095,7 @@ class Filter:
|
|||||||
if system_prompt_content:
|
if system_prompt_content:
|
||||||
system_prompt_msg = {"role": "system", "content": system_prompt_content}
|
system_prompt_msg = {"role": "system", "content": system_prompt_content}
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.info(
|
||||||
f"[Inlet] Found system prompt ({len(system_prompt_content)} chars). Including in budget."
|
f"[Inlet] Found system prompt ({len(system_prompt_content)} chars). Including in budget."
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -991,12 +1126,12 @@ class Filter:
|
|||||||
f"[Inlet] Message Stats: {stats_str}", event_call=__event_call__
|
f"[Inlet] Message Stats: {stats_str}", event_call=__event_call__
|
||||||
)
|
)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[Inlet] Error logging message stats: {e}")
|
logger.error(f"[Inlet] Error logging message stats: {e}")
|
||||||
|
|
||||||
if not chat_id:
|
if not chat_id:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[Inlet] ❌ Missing chat_id in metadata, skipping compression",
|
"[Inlet] ❌ Missing chat_id in metadata, skipping compression",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return body
|
return body
|
||||||
@@ -1007,6 +1142,33 @@ class Filter:
|
|||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
# Log custom model configurations
|
||||||
|
raw_config = self.valves.model_thresholds
|
||||||
|
parsed_configs = self._parse_model_thresholds()
|
||||||
|
|
||||||
|
if raw_config:
|
||||||
|
config_list = [
|
||||||
|
f"{model}: {cfg['compression_threshold_tokens']}t/{cfg['max_context_tokens']}t"
|
||||||
|
for model, cfg in parsed_configs.items()
|
||||||
|
]
|
||||||
|
|
||||||
|
if config_list:
|
||||||
|
await self._log(
|
||||||
|
f"[Inlet] 📋 Model Configs (Raw: '{raw_config}'): {', '.join(config_list)}",
|
||||||
|
event_call=__event_call__,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
await self._log(
|
||||||
|
f"[Inlet] ⚠️ Invalid Model Configs (Raw: '{raw_config}'): No valid configs parsed. Expected format: 'model_id:threshold:max_context'",
|
||||||
|
log_type="warning",
|
||||||
|
event_call=__event_call__,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
await self._log(
|
||||||
|
f"[Inlet] 📋 Model Configs: No custom configuration (Global defaults only)",
|
||||||
|
event_call=__event_call__,
|
||||||
|
)
|
||||||
|
|
||||||
# Record the target compression progress for the original messages, for use in outlet
|
# Record the target compression progress for the original messages, for use in outlet
|
||||||
# Target is to compress up to the (total - keep_last) message
|
# Target is to compress up to the (total - keep_last) message
|
||||||
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
||||||
@@ -1043,9 +1205,9 @@ class Filter:
|
|||||||
if effective_keep_first > 0:
|
if effective_keep_first > 0:
|
||||||
head_messages = messages[:effective_keep_first]
|
head_messages = messages[:effective_keep_first]
|
||||||
|
|
||||||
# 2. Summary message (Inserted as User message)
|
# 2. Summary message (Inserted as Assistant message)
|
||||||
summary_content = (
|
summary_content = (
|
||||||
f"【System Prompt: The following is a summary of the historical conversation, provided for context only. Do not reply to the summary content itself; answer the subsequent latest questions directly.】\n\n"
|
f"【Previous Summary: The following is a summary of the historical conversation, provided for context only. Do not reply to the summary content itself; answer the subsequent latest questions directly.】\n\n"
|
||||||
f"{summary_record.summary}\n\n"
|
f"{summary_record.summary}\n\n"
|
||||||
f"---\n"
|
f"---\n"
|
||||||
f"Below is the recent conversation:"
|
f"Below is the recent conversation:"
|
||||||
@@ -1102,7 +1264,7 @@ class Filter:
|
|||||||
if total_tokens > max_context_tokens:
|
if total_tokens > max_context_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ⚠️ Candidate prompt ({total_tokens} Tokens) exceeds limit ({max_context_tokens}). Reducing history...",
|
f"[Inlet] ⚠️ Candidate prompt ({total_tokens} Tokens) exceeds limit ({max_context_tokens}). Reducing history...",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1239,7 +1401,7 @@ class Filter:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] Applied summary: {system_info} + Head({len(head_messages)} msg, {head_tokens}t) + Summary({summary_tokens}t) + Tail({len(tail_messages)} msg, {tail_tokens}t) = Total({total_section_tokens}t)",
|
f"[Inlet] Applied summary: {system_info} + Head({len(head_messages)} msg, {head_tokens}t) + Summary({summary_tokens}t) + Tail({len(tail_messages)} msg, {tail_tokens}t) = Total({total_section_tokens}t)",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1287,7 +1449,7 @@ class Filter:
|
|||||||
|
|
||||||
# Get max context limit
|
# Get max context limit
|
||||||
model = self._clean_model_id(body.get("model"))
|
model = self._clean_model_id(body.get("model"))
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
max_context_tokens = thresholds.get(
|
max_context_tokens = thresholds.get(
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
)
|
)
|
||||||
@@ -1299,7 +1461,7 @@ class Filter:
|
|||||||
if total_tokens > max_context_tokens:
|
if total_tokens > max_context_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ⚠️ Original messages ({total_tokens} Tokens) exceed limit ({max_context_tokens}). Reducing history...",
|
f"[Inlet] ⚠️ Original messages ({total_tokens} Tokens) exceed limit ({max_context_tokens}). Reducing history...",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1314,7 +1476,8 @@ class Filter:
|
|||||||
> start_trim_index + 1 # Keep at least 1 message after keep_first
|
> start_trim_index + 1 # Keep at least 1 message after keep_first
|
||||||
):
|
):
|
||||||
dropped = final_messages.pop(start_trim_index)
|
dropped = final_messages.pop(start_trim_index)
|
||||||
total_tokens -= self._count_tokens(str(dropped.get("content", "")))
|
dropped_tokens = self._count_tokens(str(dropped.get("content", "")))
|
||||||
|
total_tokens -= dropped_tokens
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ✂️ Messages reduced. New total: {total_tokens} Tokens",
|
f"[Inlet] ✂️ Messages reduced. New total: {total_tokens} Tokens",
|
||||||
@@ -1366,23 +1529,16 @@ class Filter:
|
|||||||
if not chat_id:
|
if not chat_id:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[Outlet] ❌ Missing chat_id in metadata, skipping compression",
|
"[Outlet] ❌ Missing chat_id in metadata, skipping compression",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return body
|
return body
|
||||||
model = body.get("model") or ""
|
model = body.get("model") or ""
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
|
||||||
# Calculate target compression progress directly
|
# Calculate target compression progress directly
|
||||||
# Assuming body['messages'] in outlet contains the full history (including new response)
|
|
||||||
messages = body.get("messages", [])
|
|
||||||
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
||||||
|
|
||||||
if self.valves.debug_mode or self.valves.show_debug_log:
|
|
||||||
await self._log(
|
|
||||||
f"\n{'='*60}\n[Outlet] Chat ID: {chat_id}\n[Outlet] Response complete\n[Outlet] Calculated target compression progress: {target_compressed_count} (Messages: {len(messages)})",
|
|
||||||
event_call=__event_call__,
|
|
||||||
)
|
|
||||||
|
|
||||||
# Process Token calculation and summary generation asynchronously in the background (do not wait for completion, do not affect output)
|
# Process Token calculation and summary generation asynchronously in the background (do not wait for completion, do not affect output)
|
||||||
asyncio.create_task(
|
asyncio.create_task(
|
||||||
self._check_and_generate_summary_async(
|
self._check_and_generate_summary_async(
|
||||||
@@ -1396,11 +1552,6 @@ class Filter:
|
|||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|
||||||
await self._log(
|
|
||||||
f"[Outlet] Background processing started\n{'='*60}\n",
|
|
||||||
event_call=__event_call__,
|
|
||||||
)
|
|
||||||
|
|
||||||
return body
|
return body
|
||||||
|
|
||||||
async def _check_and_generate_summary_async(
|
async def _check_and_generate_summary_async(
|
||||||
@@ -1416,11 +1567,25 @@ class Filter:
|
|||||||
"""
|
"""
|
||||||
Background processing: Calculates Token count and generates summary (does not block response).
|
Background processing: Calculates Token count and generates summary (does not block response).
|
||||||
"""
|
"""
|
||||||
|
|
||||||
try:
|
try:
|
||||||
messages = body.get("messages", [])
|
messages = body.get("messages", [])
|
||||||
|
|
||||||
|
# Clean model ID
|
||||||
|
model = self._clean_model_id(model)
|
||||||
|
|
||||||
|
if self.valves.debug_mode or self.valves.show_debug_log:
|
||||||
|
await self._log(
|
||||||
|
f"\n{'='*60}\n[Outlet] Chat ID: {chat_id}\n[Outlet] Response complete\n[Outlet] Calculated target compression progress: {target_compressed_count} (Messages: {len(messages)})",
|
||||||
|
event_call=__event_call__,
|
||||||
|
)
|
||||||
|
await self._log(
|
||||||
|
f"[Outlet] Background processing started\n{'='*60}\n",
|
||||||
|
event_call=__event_call__,
|
||||||
|
)
|
||||||
|
|
||||||
# Get threshold configuration for current model
|
# Get threshold configuration for current model
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
compression_threshold_tokens = thresholds.get(
|
compression_threshold_tokens = thresholds.get(
|
||||||
"compression_threshold_tokens", self.valves.compression_threshold_tokens
|
"compression_threshold_tokens", self.valves.compression_threshold_tokens
|
||||||
)
|
)
|
||||||
@@ -1440,11 +1605,33 @@ class Filter:
|
|||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
# Send status notification (Context Usage format)
|
||||||
|
if __event_emitter__ and self.valves.show_token_usage_status:
|
||||||
|
max_context_tokens = thresholds.get(
|
||||||
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
|
)
|
||||||
|
status_msg = f"Context Usage (Estimated): {current_tokens} / {max_context_tokens} Tokens"
|
||||||
|
if max_context_tokens > 0:
|
||||||
|
usage_ratio = current_tokens / max_context_tokens
|
||||||
|
status_msg += f" ({usage_ratio*100:.1f}%)"
|
||||||
|
if usage_ratio > 0.9:
|
||||||
|
status_msg += " | ⚠️ High Usage"
|
||||||
|
|
||||||
|
await __event_emitter__(
|
||||||
|
{
|
||||||
|
"type": "status",
|
||||||
|
"data": {
|
||||||
|
"description": status_msg,
|
||||||
|
"done": True,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
# Check if compression is needed
|
# Check if compression is needed
|
||||||
if current_tokens >= compression_threshold_tokens:
|
if current_tokens >= compression_threshold_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🔍 Background Calculation] ⚡ Compression threshold triggered (Token: {current_tokens} >= {compression_threshold_tokens})",
|
f"[🔍 Background Calculation] ⚡ Compression threshold triggered (Token: {current_tokens} >= {compression_threshold_tokens})",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1467,7 +1654,7 @@ class Filter:
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🔍 Background Calculation] ❌ Error: {str(e)}",
|
f"[🔍 Background Calculation] ❌ Error: {str(e)}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1506,7 +1693,7 @@ class Filter:
|
|||||||
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 Async Summary Task] ⚠️ target_compressed_count is None, estimating: {target_compressed_count}",
|
f"[🤖 Async Summary Task] ⚠️ target_compressed_count is None, estimating: {target_compressed_count}",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1553,16 +1740,19 @@ class Filter:
|
|||||||
if not summary_model_id:
|
if not summary_model_id:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 Async Summary Task] ⚠️ Summary model does not exist, skipping compression",
|
"[🤖 Async Summary Task] ⚠️ Summary model does not exist, skipping compression",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
|
|
||||||
thresholds = self._get_model_thresholds(summary_model_id)
|
thresholds = self._get_model_thresholds(summary_model_id)
|
||||||
# Note: Using the summary model's max context limit here
|
# Priority: 1. summary_model_max_context (if > 0) -> 2. model_thresholds -> 3. global max_context_tokens
|
||||||
max_context_tokens = thresholds.get(
|
if self.valves.summary_model_max_context > 0:
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
max_context_tokens = self.valves.summary_model_max_context
|
||||||
)
|
else:
|
||||||
|
max_context_tokens = thresholds.get(
|
||||||
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
|
)
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 Async Summary Task] Using max limit for model {summary_model_id}: {max_context_tokens} Tokens",
|
f"[🤖 Async Summary Task] Using max limit for model {summary_model_id}: {max_context_tokens} Tokens",
|
||||||
@@ -1581,7 +1771,7 @@ class Filter:
|
|||||||
excess_tokens = estimated_input_tokens - max_context_tokens
|
excess_tokens = estimated_input_tokens - max_context_tokens
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 Async Summary Task] ⚠️ Middle messages ({middle_tokens} Tokens) + Buffer exceed summary model limit ({max_context_tokens}), need to remove approx {excess_tokens} Tokens",
|
f"[🤖 Async Summary Task] ⚠️ Middle messages ({middle_tokens} Tokens) + Buffer exceed summary model limit ({max_context_tokens}), need to remove approx {excess_tokens} Tokens",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1638,7 +1828,7 @@ class Filter:
|
|||||||
if not new_summary:
|
if not new_summary:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 Async Summary Task] ⚠️ Summary generation returned empty result, skipping save",
|
"[🤖 Async Summary Task] ⚠️ Summary generation returned empty result, skipping save",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
@@ -1667,7 +1857,7 @@ class Filter:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 Async Summary Task] ✅ Complete! New summary length: {len(new_summary)} characters",
|
f"[🤖 Async Summary Task] ✅ Complete! New summary length: {len(new_summary)} characters",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
await self._log(
|
await self._log(
|
||||||
@@ -1753,7 +1943,6 @@ class Filter:
|
|||||||
max_context_tokens = thresholds.get(
|
max_context_tokens = thresholds.get(
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
)
|
)
|
||||||
|
|
||||||
# 6. Emit Status
|
# 6. Emit Status
|
||||||
status_msg = f"Context Summary Updated: {token_count} / {max_context_tokens} Tokens"
|
status_msg = f"Context Summary Updated: {token_count} / {max_context_tokens} Tokens"
|
||||||
if max_context_tokens > 0:
|
if max_context_tokens > 0:
|
||||||
@@ -1774,14 +1963,14 @@ class Filter:
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Status] Error calculating tokens: {e}",
|
f"[Status] Error calculating tokens: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 Async Summary Task] ❌ Error: {str(e)}",
|
f"[🤖 Async Summary Task] ❌ Error: {str(e)}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1798,7 +1987,7 @@ class Filter:
|
|||||||
|
|
||||||
import traceback
|
import traceback
|
||||||
|
|
||||||
traceback.print_exc()
|
logger.exception("[🤖 Async Summary Task] Unhandled exception")
|
||||||
|
|
||||||
def _format_messages_for_summary(self, messages: list) -> str:
|
def _format_messages_for_summary(self, messages: list) -> str:
|
||||||
"""Formats messages for summarization."""
|
"""Formats messages for summarization."""
|
||||||
@@ -1818,9 +2007,8 @@ class Filter:
|
|||||||
# Handle role name
|
# Handle role name
|
||||||
role_name = {"user": "User", "assistant": "Assistant"}.get(role, role)
|
role_name = {"user": "User", "assistant": "Assistant"}.get(role, role)
|
||||||
|
|
||||||
# Limit length of each message to avoid excessive length
|
# User requested to remove truncation to allow full context for summary
|
||||||
if len(content) > 500:
|
# unless it exceeds model limits (which is handled by the LLM call itself or max_tokens)
|
||||||
content = content[:500] + "..."
|
|
||||||
|
|
||||||
formatted.append(f"[{i}] {role_name}: {content}")
|
formatted.append(f"[{i}] {role_name}: {content}")
|
||||||
|
|
||||||
@@ -1884,7 +2072,7 @@ Based on the content above, generate the summary:
|
|||||||
if not model:
|
if not model:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 LLM Call] ⚠️ Summary model does not exist, skipping summary generation",
|
"[🤖 LLM Call] ⚠️ Summary model does not exist, skipping summary generation",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return ""
|
return ""
|
||||||
@@ -1927,14 +2115,31 @@ Based on the content above, generate the summary:
|
|||||||
# Call generate_chat_completion
|
# Call generate_chat_completion
|
||||||
response = await generate_chat_completion(request, payload, user)
|
response = await generate_chat_completion(request, payload, user)
|
||||||
|
|
||||||
if not response or "choices" not in response or not response["choices"]:
|
# Handle JSONResponse (some backends return JSONResponse instead of dict)
|
||||||
raise ValueError("LLM response format incorrect or empty")
|
if hasattr(response, "body"):
|
||||||
|
# It's a Response object, extract the body
|
||||||
|
import json as json_module
|
||||||
|
|
||||||
|
try:
|
||||||
|
response = json_module.loads(response.body.decode("utf-8"))
|
||||||
|
except Exception:
|
||||||
|
raise ValueError(f"Failed to parse JSONResponse body: {response}")
|
||||||
|
|
||||||
|
if (
|
||||||
|
not response
|
||||||
|
or not isinstance(response, dict)
|
||||||
|
or "choices" not in response
|
||||||
|
or not response["choices"]
|
||||||
|
):
|
||||||
|
raise ValueError(
|
||||||
|
f"LLM response format incorrect or empty: {type(response).__name__}"
|
||||||
|
)
|
||||||
|
|
||||||
summary = response["choices"][0]["message"]["content"].strip()
|
summary = response["choices"][0]["message"]["content"].strip()
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 LLM Call] ✅ Successfully received summary",
|
f"[🤖 LLM Call] ✅ Successfully received summary",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1955,7 +2160,7 @@ Based on the content above, generate the summary:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 LLM Call] ❌ {error_message}",
|
f"[🤖 LLM Call] ❌ {error_message}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|||||||
@@ -5,19 +5,17 @@ author: Fu-Jie
|
|||||||
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
funding_url: https://github.com/open-webui
|
funding_url: https://github.com/open-webui
|
||||||
description: 通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。
|
description: 通过智能摘要和消息压缩,降低长对话的 token 消耗,同时保持对话连贯性。
|
||||||
version: 1.2.0
|
version: 1.2.2
|
||||||
openwebui_id: 5c0617cb-a9e4-4bd6-a440-d276534ebd18
|
openwebui_id: 5c0617cb-a9e4-4bd6-a440-d276534ebd18
|
||||||
license: MIT
|
license: MIT
|
||||||
|
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
📌 1.2.0 版本更新
|
📌 1.2.1 版本更新
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
|
|
||||||
✅ 预检上下文检查:发送给模型前验证上下文是否适配。
|
✅ 智能配置增强:自动检测自定义模型的基础模型配置,并新增 `summary_model_max_context` 参数以独立控制摘要模型的上下文限制。
|
||||||
✅ 结构感知裁剪:折叠过长的 AI 响应,同时保留标题 (H1-H6)、开头和结尾。
|
✅ 性能优化与重构:重构了阈值解析逻辑并增加缓存,移除了冗余的处理代码,并增强了 LLM 响应处理(支持 JSONResponse)。
|
||||||
✅ 原生工具输出裁剪:使用函数调用时清理上下文,去除冗余输出。(注意:非原生工具调用输出不会完整注入上下文)
|
✅ 稳定性改进:修复了 `datetime` 弃用警告,修正了类型注解,并将 print 语句替换为标准日志记录。
|
||||||
✅ 上下文使用警告:当使用量超过 90% 时发出通知。
|
|
||||||
✅ 详细 Token 日志:细粒度记录 System、Head、Summary 和 Tail 的 Token 消耗。
|
|
||||||
|
|
||||||
═══════════════════════════════════════════════════════════════════════════════
|
═══════════════════════════════════════════════════════════════════════════════
|
||||||
📌 功能概述
|
📌 功能概述
|
||||||
@@ -254,23 +252,36 @@ show_debug_log (前端调试日志)
|
|||||||
|
|
||||||
from pydantic import BaseModel, Field, model_validator
|
from pydantic import BaseModel, Field, model_validator
|
||||||
from typing import Optional, Dict, Any, List, Union, Callable, Awaitable
|
from typing import Optional, Dict, Any, List, Union, Callable, Awaitable
|
||||||
|
import re
|
||||||
import asyncio
|
import asyncio
|
||||||
import json
|
import json
|
||||||
import hashlib
|
import hashlib
|
||||||
import time
|
import contextlib
|
||||||
import re
|
import logging
|
||||||
|
|
||||||
|
# 配置日志记录
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
if not logger.handlers:
|
||||||
|
handler = logging.StreamHandler()
|
||||||
|
formatter = logging.Formatter(
|
||||||
|
"%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||||
|
)
|
||||||
|
handler.setFormatter(formatter)
|
||||||
|
logger.addHandler(handler)
|
||||||
|
logger.setLevel(logging.INFO)
|
||||||
|
|
||||||
# Open WebUI 内置导入
|
# Open WebUI 内置导入
|
||||||
from open_webui.utils.chat import generate_chat_completion
|
from open_webui.utils.chat import generate_chat_completion
|
||||||
from open_webui.models.models import Models
|
|
||||||
from open_webui.models.users import Users
|
from open_webui.models.users import Users
|
||||||
|
from open_webui.models.models import Models
|
||||||
from fastapi.requests import Request
|
from fastapi.requests import Request
|
||||||
from open_webui.main import app as webui_app
|
from open_webui.main import app as webui_app
|
||||||
|
|
||||||
# Open WebUI 内部数据库 (复用共享连接)
|
# Open WebUI 内部数据库 (复用共享连接)
|
||||||
from open_webui.internal.db import engine as owui_engine
|
try:
|
||||||
from open_webui.internal.db import Session as owui_Session
|
from open_webui.internal import db as owui_db
|
||||||
from open_webui.internal.db import Base as owui_Base
|
except ModuleNotFoundError: # pragma: no cover - filter runs inside Open WebUI
|
||||||
|
owui_db = None
|
||||||
|
|
||||||
# 尝试导入 tiktoken
|
# 尝试导入 tiktoken
|
||||||
try:
|
try:
|
||||||
@@ -280,35 +291,167 @@ except ImportError:
|
|||||||
|
|
||||||
# 数据库导入
|
# 数据库导入
|
||||||
from sqlalchemy import Column, String, Text, DateTime, Integer, inspect
|
from sqlalchemy import Column, String, Text, DateTime, Integer, inspect
|
||||||
from datetime import datetime
|
from sqlalchemy.orm import declarative_base, sessionmaker
|
||||||
|
from sqlalchemy.engine import Engine
|
||||||
|
from datetime import datetime, timezone
|
||||||
|
|
||||||
|
|
||||||
|
def _discover_owui_engine(db_module: Any) -> Optional[Engine]:
|
||||||
|
"""Discover the Open WebUI SQLAlchemy engine via provided db module helpers."""
|
||||||
|
if db_module is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
db_context = getattr(db_module, "get_db_context", None) or getattr(
|
||||||
|
db_module, "get_db", None
|
||||||
|
)
|
||||||
|
if callable(db_context):
|
||||||
|
try:
|
||||||
|
with db_context() as session:
|
||||||
|
try:
|
||||||
|
return session.get_bind()
|
||||||
|
except AttributeError:
|
||||||
|
return getattr(session, "bind", None) or getattr(
|
||||||
|
session, "engine", None
|
||||||
|
)
|
||||||
|
except Exception as exc:
|
||||||
|
print(f"[DB Discover] get_db_context failed: {exc}")
|
||||||
|
|
||||||
|
for attr in ("engine", "ENGINE", "bind", "BIND"):
|
||||||
|
candidate = getattr(db_module, attr, None)
|
||||||
|
if candidate is not None:
|
||||||
|
return candidate
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def _discover_owui_schema(db_module: Any) -> Optional[str]:
|
||||||
|
"""Discover the Open WebUI database schema name if configured."""
|
||||||
|
if db_module is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
try:
|
||||||
|
base = getattr(db_module, "Base", None)
|
||||||
|
metadata = getattr(base, "metadata", None) if base is not None else None
|
||||||
|
candidate = getattr(metadata, "schema", None) if metadata is not None else None
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
print(f"[DB Discover] Base metadata schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
metadata_obj = getattr(db_module, "metadata_obj", None)
|
||||||
|
candidate = (
|
||||||
|
getattr(metadata_obj, "schema", None) if metadata_obj is not None else None
|
||||||
|
)
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
print(f"[DB Discover] metadata_obj schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
from open_webui import env as owui_env
|
||||||
|
|
||||||
|
candidate = getattr(owui_env, "DATABASE_SCHEMA", None)
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
print(f"[DB Discover] env schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
owui_engine = _discover_owui_engine(owui_db)
|
||||||
|
owui_schema = _discover_owui_schema(owui_db)
|
||||||
|
owui_Base = getattr(owui_db, "Base", None) if owui_db is not None else None
|
||||||
|
if owui_Base is None:
|
||||||
|
owui_Base = declarative_base()
|
||||||
|
|
||||||
|
|
||||||
class ChatSummary(owui_Base):
|
class ChatSummary(owui_Base):
|
||||||
"""对话摘要存储表"""
|
"""对话摘要存储表"""
|
||||||
|
|
||||||
__tablename__ = "chat_summary"
|
__tablename__ = "chat_summary"
|
||||||
__table_args__ = {"extend_existing": True}
|
__table_args__ = (
|
||||||
|
{"extend_existing": True, "schema": owui_schema}
|
||||||
|
if owui_schema
|
||||||
|
else {"extend_existing": True}
|
||||||
|
)
|
||||||
|
|
||||||
id = Column(Integer, primary_key=True, autoincrement=True)
|
id = Column(Integer, primary_key=True, autoincrement=True)
|
||||||
chat_id = Column(String(255), unique=True, nullable=False, index=True)
|
chat_id = Column(String(255), unique=True, nullable=False, index=True)
|
||||||
summary = Column(Text, nullable=False)
|
summary = Column(Text, nullable=False)
|
||||||
compressed_message_count = Column(Integer, default=0)
|
compressed_message_count = Column(Integer, default=0)
|
||||||
created_at = Column(DateTime, default=datetime.utcnow)
|
created_at = Column(DateTime, default=lambda: datetime.now(timezone.utc))
|
||||||
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
|
updated_at = Column(
|
||||||
|
DateTime,
|
||||||
|
default=lambda: datetime.now(timezone.utc),
|
||||||
|
onupdate=lambda: datetime.now(timezone.utc),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
class Filter:
|
class Filter:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.valves = self.Valves()
|
self.valves = self.Valves()
|
||||||
|
self._owui_db = owui_db
|
||||||
self._db_engine = owui_engine
|
self._db_engine = owui_engine
|
||||||
self._SessionLocal = owui_Session
|
self._fallback_session_factory = (
|
||||||
self._SessionLocal = owui_Session
|
sessionmaker(bind=self._db_engine) if self._db_engine else None
|
||||||
self._init_database()
|
)
|
||||||
|
self._threshold_cache = {}
|
||||||
self._init_database()
|
self._init_database()
|
||||||
|
|
||||||
|
@contextlib.contextmanager
|
||||||
|
def _db_session(self):
|
||||||
|
"""Yield a database session using Open WebUI helpers with graceful fallbacks."""
|
||||||
|
db_module = self._owui_db
|
||||||
|
db_context = None
|
||||||
|
if db_module is not None:
|
||||||
|
db_context = getattr(db_module, "get_db_context", None) or getattr(
|
||||||
|
db_module, "get_db", None
|
||||||
|
)
|
||||||
|
|
||||||
|
if callable(db_context):
|
||||||
|
with db_context() as session:
|
||||||
|
yield session
|
||||||
|
return
|
||||||
|
|
||||||
|
factory = None
|
||||||
|
if db_module is not None:
|
||||||
|
factory = getattr(db_module, "SessionLocal", None) or getattr(
|
||||||
|
db_module, "ScopedSession", None
|
||||||
|
)
|
||||||
|
if callable(factory):
|
||||||
|
session = factory()
|
||||||
|
try:
|
||||||
|
yield session
|
||||||
|
finally:
|
||||||
|
close = getattr(session, "close", None)
|
||||||
|
if callable(close):
|
||||||
|
close()
|
||||||
|
return
|
||||||
|
|
||||||
|
if self._fallback_session_factory is None:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Open WebUI database session is unavailable. Ensure Open WebUI's database layer is initialized."
|
||||||
|
)
|
||||||
|
|
||||||
|
session = self._fallback_session_factory()
|
||||||
|
try:
|
||||||
|
yield session
|
||||||
|
finally:
|
||||||
|
try:
|
||||||
|
session.close()
|
||||||
|
except Exception as exc: # pragma: no cover - best-effort cleanup
|
||||||
|
print(f"[Database] ⚠️ Failed to close fallback session: {exc}")
|
||||||
|
|
||||||
def _init_database(self):
|
def _init_database(self):
|
||||||
"""使用 Open WebUI 的共享连接初始化数据库表"""
|
"""使用 Open WebUI 的共享连接初始化数据库表"""
|
||||||
try:
|
try:
|
||||||
|
if self._db_engine is None:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Open WebUI database engine is unavailable. Ensure Open WebUI is configured with a valid DATABASE_URL."
|
||||||
|
)
|
||||||
|
|
||||||
# 使用 SQLAlchemy inspect 检查表是否存在
|
# 使用 SQLAlchemy inspect 检查表是否存在
|
||||||
inspector = inspect(self._db_engine)
|
inspector = inspect(self._db_engine)
|
||||||
if not inspector.has_table("chat_summary"):
|
if not inspector.has_table("chat_summary"):
|
||||||
@@ -340,21 +483,38 @@ class Filter:
|
|||||||
ge=0,
|
ge=0,
|
||||||
description="上下文的硬性上限。超过此值将强制移除最早的消息 (全局默认值)",
|
description="上下文的硬性上限。超过此值将强制移除最早的消息 (全局默认值)",
|
||||||
)
|
)
|
||||||
model_thresholds: dict = Field(
|
model_thresholds: Union[str, dict] = Field(
|
||||||
default={},
|
default={},
|
||||||
description="针对特定模型的阈值覆盖配置。仅包含需要特殊配置的模型。",
|
description="针对特定模型的阈值覆盖配置。可以是 JSON 字符串或字典。",
|
||||||
)
|
)
|
||||||
|
|
||||||
|
@model_validator(mode="before")
|
||||||
|
@classmethod
|
||||||
|
def parse_model_thresholds(cls, data: Any) -> Any:
|
||||||
|
if isinstance(data, dict):
|
||||||
|
thresholds = data.get("model_thresholds")
|
||||||
|
if isinstance(thresholds, str) and thresholds.strip():
|
||||||
|
try:
|
||||||
|
data["model_thresholds"] = json.loads(thresholds)
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Failed to parse model_thresholds JSON: {e}")
|
||||||
|
return data
|
||||||
|
|
||||||
keep_first: int = Field(
|
keep_first: int = Field(
|
||||||
default=1, ge=0, description="始终保留最初的 N 条消息。设置为 0 则不保留。"
|
default=1, ge=0, description="始终保留最初的 N 条消息。设置为 0 则不保留。"
|
||||||
)
|
)
|
||||||
keep_last: int = Field(
|
keep_last: int = Field(
|
||||||
default=6, ge=0, description="始终保留最近的 N 条完整消息。"
|
default=6, ge=0, description="始终保留最近的 N 条完整消息。"
|
||||||
)
|
)
|
||||||
summary_model: str = Field(
|
summary_model: Optional[str] = Field(
|
||||||
default=None,
|
default=None,
|
||||||
description="用于生成摘要的模型 ID。留空则使用当前对话的模型。用于匹配 model_thresholds 中的配置。",
|
description="用于生成摘要的模型 ID。留空则使用当前对话的模型。用于匹配 model_thresholds 中的配置。",
|
||||||
)
|
)
|
||||||
|
summary_model_max_context: int = Field(
|
||||||
|
default=0,
|
||||||
|
ge=0,
|
||||||
|
description="摘要模型的最大上下文 Token 数。如果为 0,则回退到 model_thresholds 或全局 max_context_tokens。",
|
||||||
|
)
|
||||||
max_summary_tokens: int = Field(
|
max_summary_tokens: int = Field(
|
||||||
default=16384, ge=1, description="摘要的最大 token 数"
|
default=16384, ge=1, description="摘要的最大 token 数"
|
||||||
)
|
)
|
||||||
@@ -376,7 +536,7 @@ class Filter:
|
|||||||
def _save_summary(self, chat_id: str, summary: str, compressed_count: int):
|
def _save_summary(self, chat_id: str, summary: str, compressed_count: int):
|
||||||
"""保存摘要到数据库"""
|
"""保存摘要到数据库"""
|
||||||
try:
|
try:
|
||||||
with self._SessionLocal() as session:
|
with self._db_session() as session:
|
||||||
# 查找现有记录
|
# 查找现有记录
|
||||||
existing = session.query(ChatSummary).filter_by(chat_id=chat_id).first()
|
existing = session.query(ChatSummary).filter_by(chat_id=chat_id).first()
|
||||||
|
|
||||||
@@ -384,7 +544,7 @@ class Filter:
|
|||||||
# [优化] 乐观锁检查:只有进度向前推进时才更新
|
# [优化] 乐观锁检查:只有进度向前推进时才更新
|
||||||
if compressed_count <= existing.compressed_message_count:
|
if compressed_count <= existing.compressed_message_count:
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.debug(
|
||||||
f"[存储] 跳过更新:新进度 ({compressed_count}) 不大于现有进度 ({existing.compressed_message_count})"
|
f"[存储] 跳过更新:新进度 ({compressed_count}) 不大于现有进度 ({existing.compressed_message_count})"
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
@@ -392,7 +552,7 @@ class Filter:
|
|||||||
# 更新现有记录
|
# 更新现有记录
|
||||||
existing.summary = summary
|
existing.summary = summary
|
||||||
existing.compressed_message_count = compressed_count
|
existing.compressed_message_count = compressed_count
|
||||||
existing.updated_at = datetime.utcnow()
|
existing.updated_at = datetime.now(timezone.utc)
|
||||||
else:
|
else:
|
||||||
# 创建新记录
|
# 创建新记录
|
||||||
new_summary = ChatSummary(
|
new_summary = ChatSummary(
|
||||||
@@ -406,22 +566,22 @@ class Filter:
|
|||||||
|
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
action = "更新" if existing else "创建"
|
action = "更新" if existing else "创建"
|
||||||
print(f"[存储] 摘要已{action}到数据库 (Chat ID: {chat_id})")
|
logger.info(f"[存储] 摘要已{action}到数据库 (Chat ID: {chat_id})")
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[存储] ❌ 数据库保存失败: {str(e)}")
|
logger.error(f"[存储] ❌ 数据库保存失败: {str(e)}")
|
||||||
|
|
||||||
def _load_summary_record(self, chat_id: str) -> Optional[ChatSummary]:
|
def _load_summary_record(self, chat_id: str) -> Optional[ChatSummary]:
|
||||||
"""从数据库加载摘要记录对象"""
|
"""从数据库加载摘要记录对象"""
|
||||||
try:
|
try:
|
||||||
with self._SessionLocal() as session:
|
with self._db_session() as session:
|
||||||
record = session.query(ChatSummary).filter_by(chat_id=chat_id).first()
|
record = session.query(ChatSummary).filter_by(chat_id=chat_id).first()
|
||||||
if record:
|
if record:
|
||||||
# Detach the object from the session so it can be used after session close
|
# Detach the object from the session so it can be used after session close
|
||||||
session.expunge(record)
|
session.expunge(record)
|
||||||
return record
|
return record
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[加载] ❌ 数据库读取失败: {str(e)}")
|
logger.error(f"[加载] ❌ 数据库读取失败: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
def _load_summary(self, chat_id: str, body: dict) -> Optional[str]:
|
def _load_summary(self, chat_id: str, body: dict) -> Optional[str]:
|
||||||
@@ -429,8 +589,8 @@ class Filter:
|
|||||||
record = self._load_summary_record(chat_id)
|
record = self._load_summary_record(chat_id)
|
||||||
if record:
|
if record:
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(f"[加载] 从数据库加载摘要 (Chat ID: {chat_id})")
|
logger.debug(f"[加载] 从数据库加载摘要 (Chat ID: {chat_id})")
|
||||||
print(
|
logger.debug(
|
||||||
f"[加载] 更新时间: {record.updated_at}, 已压缩消息数: {record.compressed_message_count}"
|
f"[加载] 更新时间: {record.updated_at}, 已压缩消息数: {record.compressed_message_count}"
|
||||||
)
|
)
|
||||||
return record.summary
|
return record.summary
|
||||||
@@ -473,23 +633,68 @@ class Filter:
|
|||||||
"""获取特定模型的阈值配置
|
"""获取特定模型的阈值配置
|
||||||
|
|
||||||
优先级:
|
优先级:
|
||||||
1. 如果 model_thresholds 中存在该模型ID的配置,使用该配置
|
1. 缓存匹配
|
||||||
2. 否则使用全局参数 compression_threshold_tokens 和 max_context_tokens
|
2. model_thresholds 直接匹配
|
||||||
|
3. 基础模型 (base_model_id) 匹配
|
||||||
|
4. 全局默认配置
|
||||||
"""
|
"""
|
||||||
# 尝试从模型特定配置中匹配
|
if not model_id:
|
||||||
if model_id in self.valves.model_thresholds:
|
return {
|
||||||
|
"compression_threshold_tokens": self.valves.compression_threshold_tokens,
|
||||||
|
"max_context_tokens": self.valves.max_context_tokens,
|
||||||
|
}
|
||||||
|
|
||||||
|
# 1. 检查缓存
|
||||||
|
if model_id in self._threshold_cache:
|
||||||
|
return self._threshold_cache[model_id]
|
||||||
|
|
||||||
|
# 获取解析后的阈值配置
|
||||||
|
parsed = self.valves.model_thresholds
|
||||||
|
if isinstance(parsed, str):
|
||||||
|
try:
|
||||||
|
parsed = json.loads(parsed)
|
||||||
|
except Exception:
|
||||||
|
parsed = {}
|
||||||
|
|
||||||
|
# 2. 尝试直接匹配
|
||||||
|
if model_id in parsed:
|
||||||
|
res = parsed[model_id]
|
||||||
|
self._threshold_cache[model_id] = res
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(f"[配置] 使用模型特定配置: {model_id}")
|
logger.debug(f"[配置] 模型 {model_id} 命中直接配置")
|
||||||
return self.valves.model_thresholds[model_id]
|
return res
|
||||||
|
|
||||||
# 使用全局默认配置
|
# 3. 尝试匹配基础模型 (base_model_id)
|
||||||
if self.valves.debug_mode:
|
try:
|
||||||
print(f"[配置] 模型 {model_id} 未在 model_thresholds 中,使用全局参数")
|
model_obj = Models.get_model_by_id(model_id)
|
||||||
|
if model_obj:
|
||||||
|
# 某些模型可能有多个基础模型 ID
|
||||||
|
base_ids = []
|
||||||
|
if hasattr(model_obj, "base_model_id") and model_obj.base_model_id:
|
||||||
|
base_ids.append(model_obj.base_model_id)
|
||||||
|
if hasattr(model_obj, "base_model_ids") and model_obj.base_model_ids:
|
||||||
|
if isinstance(model_obj.base_model_ids, list):
|
||||||
|
base_ids.extend(model_obj.base_model_ids)
|
||||||
|
|
||||||
return {
|
for b_id in base_ids:
|
||||||
|
if b_id in parsed:
|
||||||
|
res = parsed[b_id]
|
||||||
|
self._threshold_cache[model_id] = res
|
||||||
|
if self.valves.debug_mode:
|
||||||
|
logger.info(
|
||||||
|
f"[配置] 模型 {model_id} 匹配到基础模型 {b_id} 的配置"
|
||||||
|
)
|
||||||
|
return res
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"[配置] 查找基础模型失败: {e}")
|
||||||
|
|
||||||
|
# 4. 使用全局默认配置
|
||||||
|
res = {
|
||||||
"compression_threshold_tokens": self.valves.compression_threshold_tokens,
|
"compression_threshold_tokens": self.valves.compression_threshold_tokens,
|
||||||
"max_context_tokens": self.valves.max_context_tokens,
|
"max_context_tokens": self.valves.max_context_tokens,
|
||||||
}
|
}
|
||||||
|
self._threshold_cache[model_id] = res
|
||||||
|
return res
|
||||||
|
|
||||||
def _get_chat_context(
|
def _get_chat_context(
|
||||||
self, body: dict, __metadata__: Optional[dict] = None
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
@@ -582,7 +787,7 @@ class Filter:
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Error emitting debug log: {e}")
|
print(f"Error emitting debug log: {e}")
|
||||||
|
|
||||||
async def _log(self, message: str, type: str = "info", event_call=None):
|
async def _log(self, message: str, log_type: str = "info", event_call=None):
|
||||||
"""统一日志输出到后端 (print) 和前端 (console.log)"""
|
"""统一日志输出到后端 (print) 和前端 (console.log)"""
|
||||||
# 后端日志
|
# 后端日志
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
@@ -592,11 +797,11 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and event_call:
|
if self.valves.show_debug_log and event_call:
|
||||||
try:
|
try:
|
||||||
css = "color: #3b82f6;" # 默认蓝色
|
css = "color: #3b82f6;" # 默认蓝色
|
||||||
if type == "error":
|
if log_type == "error":
|
||||||
css = "color: #ef4444; font-weight: bold;" # 红色
|
css = "color: #ef4444; font-weight: bold;" # 红色
|
||||||
elif type == "warning":
|
elif log_type == "warning":
|
||||||
css = "color: #f59e0b;" # 橙色
|
css = "color: #f59e0b;" # 橙色
|
||||||
elif type == "success":
|
elif log_type == "success":
|
||||||
css = "color: #10b981; font-weight: bold;" # 绿色
|
css = "color: #10b981; font-weight: bold;" # 绿色
|
||||||
|
|
||||||
# 清理前端消息:移除分隔符和多余换行
|
# 清理前端消息:移除分隔符和多余换行
|
||||||
@@ -621,13 +826,15 @@ class Filter:
|
|||||||
"""
|
"""
|
||||||
await event_call({"type": "execute", "data": {"code": js_code}})
|
await event_call({"type": "execute", "data": {"code": js_code}})
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"发送前端日志失败: {e}")
|
logger.error(f"发送前端日志失败: {e}")
|
||||||
|
|
||||||
async def inlet(
|
async def inlet(
|
||||||
self,
|
self,
|
||||||
body: dict,
|
body: dict,
|
||||||
__user__: Optional[dict] = None,
|
__user__: Optional[dict] = None,
|
||||||
__metadata__: dict = None,
|
__metadata__: dict = None,
|
||||||
|
__request__: Request = None,
|
||||||
|
__model__: dict = None,
|
||||||
__event_emitter__: Callable[[Any], Awaitable[None]] = None,
|
__event_emitter__: Callable[[Any], Awaitable[None]] = None,
|
||||||
__event_call__: Callable[[Any], Awaitable[None]] = None,
|
__event_call__: Callable[[Any], Awaitable[None]] = None,
|
||||||
) -> dict:
|
) -> dict:
|
||||||
@@ -641,8 +848,10 @@ class Filter:
|
|||||||
messages = body.get("messages", [])
|
messages = body.get("messages", [])
|
||||||
|
|
||||||
# --- 原生工具输出裁剪 (Native Tool Output Trimming) ---
|
# --- 原生工具输出裁剪 (Native Tool Output Trimming) ---
|
||||||
# 即使未启用压缩,也始终检查并裁剪过长的工具输出,以节省 Token
|
metadata = body.get("metadata", {})
|
||||||
if self.valves.enable_tool_output_trimming:
|
is_native_func_calling = metadata.get("function_calling") == "native"
|
||||||
|
|
||||||
|
if self.valves.enable_tool_output_trimming and is_native_func_calling:
|
||||||
trimmed_count = 0
|
trimmed_count = 0
|
||||||
for msg in messages:
|
for msg in messages:
|
||||||
content = msg.get("content", "")
|
content = msg.get("content", "")
|
||||||
@@ -739,12 +948,17 @@ class Filter:
|
|||||||
# 处理 params 是 JSON 字符串的情况
|
# 处理 params 是 JSON 字符串的情况
|
||||||
if isinstance(params, str):
|
if isinstance(params, str):
|
||||||
params = json.loads(params)
|
params = json.loads(params)
|
||||||
|
# 转换 Pydantic 模型为字典
|
||||||
|
elif hasattr(params, "model_dump"):
|
||||||
|
params = params.model_dump()
|
||||||
|
elif hasattr(params, "dict"):
|
||||||
|
params = params.dict()
|
||||||
|
|
||||||
# 处理字典或 Pydantic 对象
|
# 处理字典
|
||||||
if isinstance(params, dict):
|
if isinstance(params, dict):
|
||||||
system_prompt_content = params.get("system")
|
system_prompt_content = params.get("system")
|
||||||
else:
|
else:
|
||||||
# 假设是 Pydantic 模型或对象
|
# 回退:尝试 getattr
|
||||||
system_prompt_content = getattr(params, "system", None)
|
system_prompt_content = getattr(params, "system", None)
|
||||||
|
|
||||||
if system_prompt_content:
|
if system_prompt_content:
|
||||||
@@ -763,7 +977,7 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ 解析模型参数失败: {e}",
|
f"[Inlet] ❌ 解析模型参数失败: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -777,7 +991,7 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ 数据库中未找到模型",
|
f"[Inlet] ❌ 数据库中未找到模型",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -785,11 +999,11 @@ class Filter:
|
|||||||
if self.valves.show_debug_log and __event_call__:
|
if self.valves.show_debug_log and __event_call__:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ❌ 从数据库获取系统提示词错误: {e}",
|
f"[Inlet] ❌ 从数据库获取系统提示词错误: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(f"[Inlet] 从数据库获取系统提示词错误: {e}")
|
logger.error(f"[Inlet] 从数据库获取系统提示词错误: {e}")
|
||||||
|
|
||||||
# 回退:检查消息列表 (基础模型或已包含)
|
# 回退:检查消息列表 (基础模型或已包含)
|
||||||
if not system_prompt_content:
|
if not system_prompt_content:
|
||||||
@@ -803,7 +1017,7 @@ class Filter:
|
|||||||
if system_prompt_content:
|
if system_prompt_content:
|
||||||
system_prompt_msg = {"role": "system", "content": system_prompt_content}
|
system_prompt_msg = {"role": "system", "content": system_prompt_content}
|
||||||
if self.valves.debug_mode:
|
if self.valves.debug_mode:
|
||||||
print(
|
logger.debug(
|
||||||
f"[Inlet] 找到系统提示词 ({len(system_prompt_content)} 字符)。计入预算。"
|
f"[Inlet] 找到系统提示词 ({len(system_prompt_content)} 字符)。计入预算。"
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -834,12 +1048,12 @@ class Filter:
|
|||||||
f"[Inlet] 消息统计: {stats_str}", event_call=__event_call__
|
f"[Inlet] 消息统计: {stats_str}", event_call=__event_call__
|
||||||
)
|
)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"[Inlet] 记录消息统计错误: {e}")
|
logger.error(f"[Inlet] 记录消息统计错误: {e}")
|
||||||
|
|
||||||
if not chat_id:
|
if not chat_id:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[Inlet] ❌ metadata 中缺少 chat_id,跳过压缩",
|
"[Inlet] ❌ metadata 中缺少 chat_id,跳过压缩",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return body
|
return body
|
||||||
@@ -925,7 +1139,7 @@ class Filter:
|
|||||||
|
|
||||||
# 获取最大上下文限制
|
# 获取最大上下文限制
|
||||||
model = self._clean_model_id(body.get("model"))
|
model = self._clean_model_id(body.get("model"))
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
max_context_tokens = thresholds.get(
|
max_context_tokens = thresholds.get(
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
)
|
)
|
||||||
@@ -945,7 +1159,7 @@ class Filter:
|
|||||||
if total_tokens > max_context_tokens:
|
if total_tokens > max_context_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ⚠️ 候选提示词 ({total_tokens} Tokens) 超过上限 ({max_context_tokens})。正在缩减历史记录...",
|
f"[Inlet] ⚠️ 候选提示词 ({total_tokens} Tokens) 超过上限 ({max_context_tokens})。正在缩减历史记录...",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1081,7 +1295,7 @@ class Filter:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] 应用摘要: {system_info} + Head({len(head_messages)} 条, {head_tokens}t) + Summary({summary_tokens}t) + Tail({len(tail_messages)} 条, {tail_tokens}t) = Total({total_section_tokens}t)",
|
f"[Inlet] 应用摘要: {system_info} + Head({len(head_messages)} 条, {head_tokens}t) + Summary({summary_tokens}t) + Tail({len(tail_messages)} 条, {tail_tokens}t) = Total({total_section_tokens}t)",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1129,7 +1343,7 @@ class Filter:
|
|||||||
|
|
||||||
# 获取最大上下文限制
|
# 获取最大上下文限制
|
||||||
model = self._clean_model_id(body.get("model"))
|
model = self._clean_model_id(body.get("model"))
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
max_context_tokens = thresholds.get(
|
max_context_tokens = thresholds.get(
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
)
|
)
|
||||||
@@ -1141,7 +1355,7 @@ class Filter:
|
|||||||
if total_tokens > max_context_tokens:
|
if total_tokens > max_context_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ⚠️ 原始消息 ({total_tokens} Tokens) 超过上限 ({max_context_tokens})。正在缩减历史记录...",
|
f"[Inlet] ⚠️ 原始消息 ({total_tokens} Tokens) 超过上限 ({max_context_tokens})。正在缩减历史记录...",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1156,7 +1370,8 @@ class Filter:
|
|||||||
> start_trim_index + 1 # 保留 keep_first 之后至少 1 条消息
|
> start_trim_index + 1 # 保留 keep_first 之后至少 1 条消息
|
||||||
):
|
):
|
||||||
dropped = final_messages.pop(start_trim_index)
|
dropped = final_messages.pop(start_trim_index)
|
||||||
total_tokens -= self._count_tokens(str(dropped.get("content", "")))
|
dropped_tokens = self._count_tokens(str(dropped.get("content", "")))
|
||||||
|
total_tokens -= dropped_tokens
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Inlet] ✂️ 消息已缩减。新总数: {total_tokens} Tokens",
|
f"[Inlet] ✂️ 消息已缩减。新总数: {total_tokens} Tokens",
|
||||||
@@ -1207,18 +1422,18 @@ class Filter:
|
|||||||
"""
|
"""
|
||||||
chat_ctx = self._get_chat_context(body, __metadata__)
|
chat_ctx = self._get_chat_context(body, __metadata__)
|
||||||
chat_id = chat_ctx["chat_id"]
|
chat_id = chat_ctx["chat_id"]
|
||||||
model = body.get("model") or ""
|
if not chat_id:
|
||||||
|
|
||||||
# 直接计算目标压缩进度
|
|
||||||
# 假设 outlet 中的 body['messages'] 包含完整历史(包括新响应)
|
|
||||||
messages = body.get("messages", [])
|
|
||||||
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
|
||||||
|
|
||||||
if self.valves.debug_mode or self.valves.show_debug_log:
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"\n{'='*60}\n[Outlet] Chat ID: {chat_id}\n[Outlet] 响应完成\n[Outlet] 计算目标压缩进度: {target_compressed_count} (消息数: {len(messages)})",
|
"[Outlet] ❌ metadata 中缺少 chat_id,跳过压缩",
|
||||||
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
return body
|
||||||
|
model = body.get("model") or ""
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
|
||||||
|
# 直接计算目标压缩进度
|
||||||
|
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
||||||
|
|
||||||
# 在后台异步处理 Token 计算和摘要生成(不等待完成,不影响输出)
|
# 在后台异步处理 Token 计算和摘要生成(不等待完成,不影响输出)
|
||||||
asyncio.create_task(
|
asyncio.create_task(
|
||||||
@@ -1233,11 +1448,6 @@ class Filter:
|
|||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|
||||||
await self._log(
|
|
||||||
f"[Outlet] 后台处理已启动\n{'='*60}\n",
|
|
||||||
event_call=__event_call__,
|
|
||||||
)
|
|
||||||
|
|
||||||
return body
|
return body
|
||||||
|
|
||||||
async def _check_and_generate_summary_async(
|
async def _check_and_generate_summary_async(
|
||||||
@@ -1257,7 +1467,7 @@ class Filter:
|
|||||||
messages = body.get("messages", [])
|
messages = body.get("messages", [])
|
||||||
|
|
||||||
# 获取当前模型的阈值配置
|
# 获取当前模型的阈值配置
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
compression_threshold_tokens = thresholds.get(
|
compression_threshold_tokens = thresholds.get(
|
||||||
"compression_threshold_tokens", self.valves.compression_threshold_tokens
|
"compression_threshold_tokens", self.valves.compression_threshold_tokens
|
||||||
)
|
)
|
||||||
@@ -1281,7 +1491,7 @@ class Filter:
|
|||||||
if current_tokens >= compression_threshold_tokens:
|
if current_tokens >= compression_threshold_tokens:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🔍 后台计算] ⚡ 触发压缩阈值 (Token: {current_tokens} >= {compression_threshold_tokens})",
|
f"[🔍 后台计算] ⚡ 触发压缩阈值 (Token: {current_tokens} >= {compression_threshold_tokens})",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1304,7 +1514,7 @@ class Filter:
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🔍 后台计算] ❌ 错误: {str(e)}",
|
f"[🔍 后台计算] ❌ 错误: {str(e)}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1341,7 +1551,7 @@ class Filter:
|
|||||||
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
target_compressed_count = max(0, len(messages) - self.valves.keep_last)
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 异步摘要任务] ⚠️ target_compressed_count 为 None,进行估算: {target_compressed_count}",
|
f"[🤖 异步摘要任务] ⚠️ target_compressed_count 为 None,进行估算: {target_compressed_count}",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1388,16 +1598,19 @@ class Filter:
|
|||||||
if not summary_model_id:
|
if not summary_model_id:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 异步摘要任务] ⚠️ 摘要模型不存在,跳过压缩",
|
"[🤖 异步摘要任务] ⚠️ 摘要模型不存在,跳过压缩",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
|
|
||||||
thresholds = self._get_model_thresholds(summary_model_id)
|
thresholds = self._get_model_thresholds(summary_model_id) or {}
|
||||||
# 注意:这里使用的是摘要模型的最大上下文限制
|
# Priority: 1. summary_model_max_context (if > 0) -> 2. model_thresholds -> 3. global max_context_tokens
|
||||||
max_context_tokens = thresholds.get(
|
if self.valves.summary_model_max_context > 0:
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
max_context_tokens = self.valves.summary_model_max_context
|
||||||
)
|
else:
|
||||||
|
max_context_tokens = thresholds.get(
|
||||||
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
|
)
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 异步摘要任务] 使用模型 {summary_model_id} 的上限: {max_context_tokens} Tokens",
|
f"[🤖 异步摘要任务] 使用模型 {summary_model_id} 的上限: {max_context_tokens} Tokens",
|
||||||
@@ -1416,7 +1629,7 @@ class Filter:
|
|||||||
excess_tokens = estimated_input_tokens - max_context_tokens
|
excess_tokens = estimated_input_tokens - max_context_tokens
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 异步摘要任务] ⚠️ 中间消息 ({middle_tokens} Tokens) + 缓冲超过摘要模型上限 ({max_context_tokens}),需要移除约 {excess_tokens} Token",
|
f"[🤖 异步摘要任务] ⚠️ 中间消息 ({middle_tokens} Tokens) + 缓冲超过摘要模型上限 ({max_context_tokens}),需要移除约 {excess_tokens} Token",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1473,7 +1686,7 @@ class Filter:
|
|||||||
if not new_summary:
|
if not new_summary:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 异步摘要任务] ⚠️ 摘要生成返回空结果,跳过保存",
|
"[🤖 异步摘要任务] ⚠️ 摘要生成返回空结果,跳过保存",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return
|
return
|
||||||
@@ -1502,7 +1715,7 @@ class Filter:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 异步摘要任务] ✅ 完成!新摘要长度: {len(new_summary)} 字符",
|
f"[🤖 异步摘要任务] ✅ 完成!新摘要长度: {len(new_summary)} 字符",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
await self._log(
|
await self._log(
|
||||||
@@ -1582,10 +1795,14 @@ class Filter:
|
|||||||
|
|
||||||
# 5. 获取阈值并计算比例
|
# 5. 获取阈值并计算比例
|
||||||
model = self._clean_model_id(body.get("model"))
|
model = self._clean_model_id(body.get("model"))
|
||||||
thresholds = self._get_model_thresholds(model)
|
thresholds = self._get_model_thresholds(model) or {}
|
||||||
max_context_tokens = thresholds.get(
|
# Priority: 1. summary_model_max_context (if > 0) -> 2. model_thresholds -> 3. global max_context_tokens
|
||||||
"max_context_tokens", self.valves.max_context_tokens
|
if self.valves.summary_model_max_context > 0:
|
||||||
)
|
max_context_tokens = self.valves.summary_model_max_context
|
||||||
|
else:
|
||||||
|
max_context_tokens = thresholds.get(
|
||||||
|
"max_context_tokens", self.valves.max_context_tokens
|
||||||
|
)
|
||||||
|
|
||||||
# 6. 发送状态
|
# 6. 发送状态
|
||||||
status_msg = (
|
status_msg = (
|
||||||
@@ -1609,14 +1826,14 @@ class Filter:
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[Status] 计算 Token 错误: {e}",
|
f"[Status] 计算 Token 错误: {e}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 异步摘要任务] ❌ 错误: {str(e)}",
|
f"[🤖 异步摘要任务] ❌ 错误: {str(e)}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1631,9 +1848,7 @@ class Filter:
|
|||||||
}
|
}
|
||||||
)
|
)
|
||||||
|
|
||||||
import traceback
|
logger.exception("[🤖 异步摘要任务] ❌ 发生异常")
|
||||||
|
|
||||||
traceback.print_exc()
|
|
||||||
|
|
||||||
def _format_messages_for_summary(self, messages: list) -> str:
|
def _format_messages_for_summary(self, messages: list) -> str:
|
||||||
"""Formats messages for summarization."""
|
"""Formats messages for summarization."""
|
||||||
@@ -1653,9 +1868,8 @@ class Filter:
|
|||||||
# Handle role name
|
# Handle role name
|
||||||
role_name = {"user": "User", "assistant": "Assistant"}.get(role, role)
|
role_name = {"user": "User", "assistant": "Assistant"}.get(role, role)
|
||||||
|
|
||||||
# Limit length of each message to avoid excessive length
|
# User requested to remove truncation to allow full context for summary
|
||||||
if len(content) > 500:
|
# unless it exceeds model limits (which is handled by the LLM call itself or max_tokens)
|
||||||
content = content[:500] + "..."
|
|
||||||
|
|
||||||
formatted.append(f"[{i}] {role_name}: {content}")
|
formatted.append(f"[{i}] {role_name}: {content}")
|
||||||
|
|
||||||
@@ -1719,7 +1933,7 @@ class Filter:
|
|||||||
if not model:
|
if not model:
|
||||||
await self._log(
|
await self._log(
|
||||||
"[🤖 LLM 调用] ⚠️ 摘要模型不存在,跳过摘要生成",
|
"[🤖 LLM 调用] ⚠️ 摘要模型不存在,跳过摘要生成",
|
||||||
type="warning",
|
log_type="warning",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
return ""
|
return ""
|
||||||
@@ -1762,14 +1976,31 @@ class Filter:
|
|||||||
# 调用 generate_chat_completion
|
# 调用 generate_chat_completion
|
||||||
response = await generate_chat_completion(request, payload, user)
|
response = await generate_chat_completion(request, payload, user)
|
||||||
|
|
||||||
if not response or "choices" not in response or not response["choices"]:
|
# Handle JSONResponse (some backends return JSONResponse instead of dict)
|
||||||
raise ValueError("LLM 响应格式不正确或为空")
|
if hasattr(response, "body"):
|
||||||
|
# It's a Response object, extract the body
|
||||||
|
import json as json_module
|
||||||
|
|
||||||
|
try:
|
||||||
|
response = json_module.loads(response.body.decode("utf-8"))
|
||||||
|
except Exception:
|
||||||
|
raise ValueError(f"Failed to parse JSONResponse body: {response}")
|
||||||
|
|
||||||
|
if (
|
||||||
|
not response
|
||||||
|
or not isinstance(response, dict)
|
||||||
|
or "choices" not in response
|
||||||
|
or not response["choices"]
|
||||||
|
):
|
||||||
|
raise ValueError(
|
||||||
|
f"LLM response format incorrect or empty: {type(response).__name__}"
|
||||||
|
)
|
||||||
|
|
||||||
summary = response["choices"][0]["message"]["content"].strip()
|
summary = response["choices"][0]["message"]["content"].strip()
|
||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 LLM 调用] ✅ 成功接收摘要",
|
f"[🤖 LLM 调用] ✅ 成功接收摘要",
|
||||||
type="success",
|
log_type="success",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -1790,7 +2021,7 @@ class Filter:
|
|||||||
|
|
||||||
await self._log(
|
await self._log(
|
||||||
f"[🤖 LLM 调用] ❌ {error_message}",
|
f"[🤖 LLM 调用] ❌ {error_message}",
|
||||||
type="error",
|
log_type="error",
|
||||||
event_call=__event_call__,
|
event_call=__event_call__,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|||||||
60
plugins/filters/folder-memory/README.md
Normal file
60
plugins/filters/folder-memory/README.md
Normal file
@@ -0,0 +1,60 @@
|
|||||||
|
# Folder Memory
|
||||||
|
|
||||||
|
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.0 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 📌 What's new in 0.1.0
|
||||||
|
- **Initial Release**: Automated "Project Rules" management for OpenWebUI folders.
|
||||||
|
- **Folder-Level Persistence**: Automatically updates folder system prompts with extracted rules.
|
||||||
|
- **Optimized Performance**: Runs asynchronously and supports `PRIORITY` configuration for seamless integration with other filters.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Folder Memory** is an intelligent context filter plugin for OpenWebUI. It automatically extracts consistent "Project Rules" from ongoing conversations within a folder and injects them back into the folder's system prompt.
|
||||||
|
|
||||||
|
## ✨ Features
|
||||||
|
|
||||||
|
- **Automatic Extraction**: Analyzes chat history every N messages to extract project rules.
|
||||||
|
- **Non-destructive Injection**: Updates only the specific "Project Rules" block in the system prompt, preserving other instructions.
|
||||||
|
- **Async Processing**: Runs in the background without blocking the user's chat experience.
|
||||||
|
- **ORM Integration**: Directly updates folder data using OpenWebUI's internal models for reliability.
|
||||||
|
|
||||||
|
## ⚠️ Prerequisites
|
||||||
|
|
||||||
|
- **Conversations must occur inside a folder.** This plugin only triggers when a chat belongs to a folder (i.e., you need to create a folder in OpenWebUI and start a conversation within it).
|
||||||
|
|
||||||
|
## 📦 Installation
|
||||||
|
|
||||||
|
1. Copy `folder_memory.py` to your OpenWebUI `plugins/filters/` directory (or upload via Admin UI).
|
||||||
|
2. Enable the filter in your **Settings** -> **Filters**.
|
||||||
|
3. (Optional) Configure the triggering threshold (default: every 10 messages).
|
||||||
|
|
||||||
|
## ⚙️ Configuration (Valves)
|
||||||
|
|
||||||
|
| Valve | Default | Description |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| `PRIORITY` | `20` | Priority level for the filter operations. |
|
||||||
|
| `MESSAGE_TRIGGER_COUNT` | `10` | The number of messages required to trigger a rule analysis. |
|
||||||
|
| `MODEL_ID` | `""` | The model used to generate rules. If empty, uses the current chat model. |
|
||||||
|
| `RULES_BLOCK_TITLE` | `## 📂 Project Rules` | The title displayed above the injected rules block. |
|
||||||
|
| `SHOW_DEBUG_LOG` | `False` | Show detailed debug logs in the browser console. |
|
||||||
|
| `UPDATE_ROOT_FOLDER` | `False` | If enabled, finds and updates the root folder rules instead of the current subfolder. |
|
||||||
|
|
||||||
|
## 🛠️ How It Works
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1. **Trigger**: When a conversation reaches `MESSAGE_TRIGGER_COUNT` (e.g., 10, 20 messages).
|
||||||
|
2. **Analysis**: The plugin sends the recent conversation + existing rules to the LLM.
|
||||||
|
3. **Synthesis**: The LLM merges new insights with old rules, removing obsolete ones.
|
||||||
|
4. **Update**: The new rule set replaces the `<!-- OWUI_PROJECT_RULES_START -->` block in the folder's system prompt.
|
||||||
|
|
||||||
|
## ⚠️ Notes
|
||||||
|
|
||||||
|
- This plugin modifies the `system_prompt` of your folders.
|
||||||
|
- It uses a specific marker `<!-- OWUI_PROJECT_RULES_START -->` to locate its content. Do not manually remove these markers if you want the plugin to continue managing that section.
|
||||||
|
|
||||||
|
## 🗺️ Roadmap
|
||||||
|
|
||||||
|
See [ROADMAP.md](./ROADMAP.md) for future plans, including "Project Knowledge" collection.
|
||||||
62
plugins/filters/folder-memory/README_CN.md
Normal file
62
plugins/filters/folder-memory/README_CN.md
Normal file
@@ -0,0 +1,62 @@
|
|||||||
|
# 文件夹记忆 (Folder Memory)
|
||||||
|
|
||||||
|
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.0 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 📌 0.1.0 版本特性
|
||||||
|
- **首个版本发布**:专注于自动化的“项目规则”管理。
|
||||||
|
- **文件夹级持久化**:自动将提取的规则回写到文件夹系统提示词中。
|
||||||
|
- **性能优化**:采用异步处理机制,并支持 `PRIORITY` 配置,确保与其他过滤器(如上下文压缩)完美协作。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**文件夹记忆 (Folder Memory)** 是一个 OpenWebUI 的智能上下文过滤器插件。它能自动从文件夹内的对话中提取一致性的“项目规则”,并将其回写到文件夹的系统提示词中。
|
||||||
|
|
||||||
|
这确保了该文件夹内的所有未来对话都能共享相同的进化上下文和规则,无需手动更新。
|
||||||
|
|
||||||
|
## ✨ 功能特性
|
||||||
|
|
||||||
|
- **自动提取**:每隔 N 条消息分析一次聊天记录,提取项目规则。
|
||||||
|
- **无损注入**:仅更新系统提示词中的特定“项目规则”块,保留其他指令。
|
||||||
|
- **异步处理**:在后台运行,不阻塞用户的聊天体验。
|
||||||
|
- **ORM 集成**:直接使用 OpenWebUI 的内部模型更新文件夹数据,确保可靠性。
|
||||||
|
|
||||||
|
## ⚠️ 前置条件
|
||||||
|
|
||||||
|
- **对话必须在文件夹内进行。** 此插件仅在聊天属于某个文件夹时触发(即您需要先在 OpenWebUI 中创建一个文件夹,并在其内部开始对话)。
|
||||||
|
|
||||||
|
## 📦 安装指南
|
||||||
|
|
||||||
|
1. 将 `folder_memory.py` (或中文版 `folder_memory_cn.py`) 复制到 OpenWebUI 的 `plugins/filters/` 目录(或通过管理员 UI 上传)。
|
||||||
|
2. 在 **设置** -> **过滤器** 中启用该插件。
|
||||||
|
3. (可选)配置触发阈值(默认:每 10 条消息)。
|
||||||
|
|
||||||
|
## ⚙️ 配置 (Valves)
|
||||||
|
|
||||||
|
| 参数 | 默认值 | 说明 |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| `PRIORITY` | `20` | 过滤器操作的优先级。 |
|
||||||
|
| `MESSAGE_TRIGGER_COUNT` | `10` | 触发规则分析的消息数量阈值。 |
|
||||||
|
| `MODEL_ID` | `""` | 用于生成规则的模型 ID。若为空,则使用当前对话模型。 |
|
||||||
|
| `RULES_BLOCK_TITLE` | `## 📂 项目规则` | 显示在注入规则块上方的标题。 |
|
||||||
|
| `SHOW_DEBUG_LOG` | `False` | 在浏览器控制台显示详细调试日志。 |
|
||||||
|
| `UPDATE_ROOT_FOLDER` | `False` | 如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。 |
|
||||||
|
|
||||||
|
## 🛠️ 工作原理
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1. **触发**:当对话达到 `MESSAGE_TRIGGER_COUNT`(例如 10、20 条消息)时。
|
||||||
|
2. **分析**:插件将最近的对话 + 现有规则发送给 LLM。
|
||||||
|
3. **综合**:LLM 将新见解与旧规则合并,移除过时的规则。
|
||||||
|
4. **更新**:新的规则集替换文件夹系统提示词中的 `<!-- OWUI_PROJECT_RULES_START -->` 块。
|
||||||
|
|
||||||
|
## ⚠️ 注意事项
|
||||||
|
|
||||||
|
- 此插件会修改文件夹的 `system_prompt`。
|
||||||
|
- 它使用特定标记 `<!-- OWUI_PROJECT_RULES_START -->` 来定位内容。如果您希望插件继续管理该部分,请勿手动删除这些标记。
|
||||||
|
|
||||||
|
## 🗺️ 路线图
|
||||||
|
|
||||||
|
查看 [ROADMAP.md](./ROADMAP.md) 了解未来计划,包括“项目知识”收集功能。
|
||||||
10
plugins/filters/folder-memory/ROADMAP.md
Normal file
10
plugins/filters/folder-memory/ROADMAP.md
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
# Roadmap
|
||||||
|
|
||||||
|
## Future Features
|
||||||
|
|
||||||
|
### 🧠 Project Knowledge (Planned)
|
||||||
|
In future versions, we plan to introduce "Project Knowledge" collection. Unlike "Rules" which are strict instructions, "Knowledge" will capture reusable information, consensus, and context that helps the LLM understand the project better.
|
||||||
|
|
||||||
|
- **Knowledge Extraction**: Automatically extract reusable knowledge (terminology, style guides, business logic) from conversations.
|
||||||
|
- **Long-term Memory**: Use the entire folder's chat history as a corpus for knowledge generation.
|
||||||
|
- **Context Injection**: Inject summarized knowledge into the system prompt alongside rules.
|
||||||
BIN
plugins/filters/folder-memory/folder-memory-demo.png
Normal file
BIN
plugins/filters/folder-memory/folder-memory-demo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 459 KiB |
483
plugins/filters/folder-memory/folder_memory.py
Normal file
483
plugins/filters/folder-memory/folder_memory.py
Normal file
@@ -0,0 +1,483 @@
|
|||||||
|
"""
|
||||||
|
title: 📂 Folder Memory
|
||||||
|
author: Fu-Jie
|
||||||
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
|
funding_url: https://github.com/open-webui
|
||||||
|
version: 0.1.0
|
||||||
|
description: Automatically extracts project rules from conversations and injects them into the folder's system prompt.
|
||||||
|
requirements:
|
||||||
|
"""
|
||||||
|
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
from typing import Optional, Dict, List
|
||||||
|
from fastapi import Request
|
||||||
|
import logging
|
||||||
|
import json
|
||||||
|
import re
|
||||||
|
import asyncio
|
||||||
|
from datetime import datetime
|
||||||
|
|
||||||
|
from open_webui.utils.chat import generate_chat_completion
|
||||||
|
from open_webui.models.users import Users
|
||||||
|
from open_webui.models.folders import Folders, FolderUpdateForm
|
||||||
|
from open_webui.models.chats import Chats
|
||||||
|
|
||||||
|
logging.basicConfig(
|
||||||
|
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||||
|
)
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# Markers for rule injection
|
||||||
|
RULES_BLOCK_START = "<!-- OWUI_PROJECT_RULES_START -->"
|
||||||
|
RULES_BLOCK_END = "<!-- OWUI_PROJECT_RULES_END -->"
|
||||||
|
|
||||||
|
# System Prompt for Rule Generation
|
||||||
|
SYSTEM_PROMPT_RULE_GENERATOR = """
|
||||||
|
You are a project rule extractor. Your task is to extract "Project Rules" from the conversation and merge them with existing rules.
|
||||||
|
|
||||||
|
### Input
|
||||||
|
1. **Existing Rules**: Current rules in the folder system prompt.
|
||||||
|
2. **Conversation**: Recent chat history.
|
||||||
|
|
||||||
|
### Goal
|
||||||
|
Synthesize a concise list of rules that apply to this project/folder.
|
||||||
|
- **Remove** rules that are no longer relevant or were one-off instructions.
|
||||||
|
- **Add** new consistent requirements found in the conversation.
|
||||||
|
- **Merge** similar rules.
|
||||||
|
- **Format**: Concise bullet points (Markdown).
|
||||||
|
|
||||||
|
### Output Format
|
||||||
|
ONLY output the rules list as Markdown bullet points. Do not include any intro/outro text.
|
||||||
|
Example:
|
||||||
|
- Always use Python 3.11 for type hinting.
|
||||||
|
- Docstrings must follow Google style.
|
||||||
|
- Commit messages should be in English.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class Filter:
|
||||||
|
class Valves(BaseModel):
|
||||||
|
PRIORITY: int = Field(
|
||||||
|
default=20, description="Priority level for the filter operations."
|
||||||
|
)
|
||||||
|
SHOW_DEBUG_LOG: bool = Field(
|
||||||
|
default=False, description="Show debug logs in console."
|
||||||
|
)
|
||||||
|
MESSAGE_TRIGGER_COUNT: int = Field(
|
||||||
|
default=10, description="Analyze rules after every N messages in a chat."
|
||||||
|
)
|
||||||
|
MODEL_ID: str = Field(
|
||||||
|
default="",
|
||||||
|
description="Model used for rule extraction. If empty, uses the current chat model.",
|
||||||
|
)
|
||||||
|
RULES_BLOCK_TITLE: str = Field(
|
||||||
|
default="## 📂 Project Rules",
|
||||||
|
description="Title displayed above the rules block.",
|
||||||
|
)
|
||||||
|
UPDATE_ROOT_FOLDER: bool = Field(
|
||||||
|
default=False,
|
||||||
|
description="If enabled, finds and updates the root folder rules instead of the current subfolder.",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.valves = self.Valves()
|
||||||
|
|
||||||
|
# ==================== Helper Methods ====================
|
||||||
|
|
||||||
|
def _get_user_context(self, __user__: Optional[dict]) -> Dict[str, str]:
|
||||||
|
"""Safely extracts user context information."""
|
||||||
|
if isinstance(__user__, (list, tuple)):
|
||||||
|
user_data = __user__[0] if __user__ else {}
|
||||||
|
elif isinstance(__user__, dict):
|
||||||
|
user_data = __user__
|
||||||
|
else:
|
||||||
|
user_data = {}
|
||||||
|
|
||||||
|
return {
|
||||||
|
"user_id": user_data.get("id", ""),
|
||||||
|
"user_name": user_data.get("name", "User"),
|
||||||
|
"user_language": user_data.get("language", "en-US"),
|
||||||
|
}
|
||||||
|
|
||||||
|
def _get_chat_context(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Dict[str, str]:
|
||||||
|
"""Unified extraction of chat context information (chat_id, message_id)."""
|
||||||
|
chat_id = ""
|
||||||
|
message_id = ""
|
||||||
|
|
||||||
|
if isinstance(body, dict):
|
||||||
|
chat_id = body.get("chat_id", "")
|
||||||
|
message_id = body.get("id", "")
|
||||||
|
|
||||||
|
if not chat_id or not message_id:
|
||||||
|
body_metadata = body.get("metadata", {})
|
||||||
|
if isinstance(body_metadata, dict):
|
||||||
|
if not chat_id:
|
||||||
|
chat_id = body_metadata.get("chat_id", "")
|
||||||
|
if not message_id:
|
||||||
|
message_id = body_metadata.get("message_id", "")
|
||||||
|
|
||||||
|
if __metadata__ and isinstance(__metadata__, dict):
|
||||||
|
if not chat_id:
|
||||||
|
chat_id = __metadata__.get("chat_id", "")
|
||||||
|
if not message_id:
|
||||||
|
message_id = __metadata__.get("message_id", "")
|
||||||
|
|
||||||
|
return {
|
||||||
|
"chat_id": str(chat_id).strip(),
|
||||||
|
"message_id": str(message_id).strip(),
|
||||||
|
}
|
||||||
|
|
||||||
|
async def _emit_debug_log(self, __event_emitter__, title: str, data: dict):
|
||||||
|
if self.valves.SHOW_DEBUG_LOG and __event_emitter__:
|
||||||
|
try:
|
||||||
|
# Flat log format as requested
|
||||||
|
js_code = f"""
|
||||||
|
console.log("[Folder Memory] {title}", {json.dumps(data, ensure_ascii=False)});
|
||||||
|
"""
|
||||||
|
await __event_emitter__({"type": "execute", "data": {"code": js_code}})
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Error emitting log: {e}")
|
||||||
|
|
||||||
|
async def _emit_status(
|
||||||
|
self, __event_emitter__, description: str, done: bool = False
|
||||||
|
):
|
||||||
|
if __event_emitter__:
|
||||||
|
await __event_emitter__(
|
||||||
|
{"type": "status", "data": {"description": description, "done": done}}
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_folder_id(self, body: dict) -> Optional[str]:
|
||||||
|
# 1. Try retrieving folder_id specifically from metadata
|
||||||
|
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||||
|
if "folder_id" in body["metadata"]:
|
||||||
|
return body["metadata"]["folder_id"]
|
||||||
|
|
||||||
|
# 2. Check regular body chat object if available
|
||||||
|
if "chat" in body and isinstance(body["chat"], dict):
|
||||||
|
if "folder_id" in body["chat"]:
|
||||||
|
return body["chat"]["folder_id"]
|
||||||
|
|
||||||
|
# 3. Try fallback via Chat ID (Most reliable)
|
||||||
|
chat_id = body.get("chat_id")
|
||||||
|
if not chat_id:
|
||||||
|
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||||
|
chat_id = body["metadata"].get("chat_id")
|
||||||
|
|
||||||
|
if chat_id:
|
||||||
|
try:
|
||||||
|
chat = Chats.get_chat_by_id(chat_id)
|
||||||
|
if chat and chat.folder_id:
|
||||||
|
return chat.folder_id
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Failed to fetch chat {chat_id}: {e}")
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
def _extract_existing_rules(self, system_prompt: str) -> str:
|
||||||
|
pattern = re.compile(
|
||||||
|
re.escape(RULES_BLOCK_START) + r"([\s\S]*?)" + re.escape(RULES_BLOCK_END)
|
||||||
|
)
|
||||||
|
match = pattern.search(system_prompt)
|
||||||
|
if match:
|
||||||
|
# Remove title if it's inside the block
|
||||||
|
content = match.group(1).strip()
|
||||||
|
# Simple cleanup of the title if user formatted it inside
|
||||||
|
title_pat = re.compile(r"^#+\s+.*$", re.MULTILINE)
|
||||||
|
return title_pat.sub("", content).strip()
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def _inject_rules(self, system_prompt: str, new_rules: str, title: str) -> str:
|
||||||
|
new_block_content = f"\n{title}\n\n{new_rules}\n"
|
||||||
|
new_block = f"{RULES_BLOCK_START}{new_block_content}{RULES_BLOCK_END}"
|
||||||
|
|
||||||
|
system_prompt = system_prompt or ""
|
||||||
|
pattern = re.compile(
|
||||||
|
re.escape(RULES_BLOCK_START) + r"[\s\S]*?" + re.escape(RULES_BLOCK_END)
|
||||||
|
)
|
||||||
|
|
||||||
|
if pattern.search(system_prompt):
|
||||||
|
return pattern.sub(new_block, system_prompt).strip()
|
||||||
|
else:
|
||||||
|
# Append if not found
|
||||||
|
if system_prompt:
|
||||||
|
return f"{system_prompt}\n\n{new_block}"
|
||||||
|
else:
|
||||||
|
return new_block
|
||||||
|
|
||||||
|
async def _generate_new_rules(
|
||||||
|
self,
|
||||||
|
current_rules: str,
|
||||||
|
messages: List[Dict],
|
||||||
|
user_id: str,
|
||||||
|
__request__: Request,
|
||||||
|
) -> str:
|
||||||
|
# Prepare context
|
||||||
|
conversation_text = "\n".join(
|
||||||
|
[
|
||||||
|
f"{msg['role'].upper()}: {msg['content']}"
|
||||||
|
for msg in messages[-20:] # Analyze last 20 messages context
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
prompt = f"""
|
||||||
|
Existing Rules:
|
||||||
|
{current_rules if current_rules else "None"}
|
||||||
|
|
||||||
|
Conversation Excerpt:
|
||||||
|
{conversation_text}
|
||||||
|
|
||||||
|
Please output the updated Project Rules:
|
||||||
|
"""
|
||||||
|
|
||||||
|
payload = {
|
||||||
|
"model": self.valves.MODEL_ID,
|
||||||
|
"messages": [
|
||||||
|
{"role": "system", "content": SYSTEM_PROMPT_RULE_GENERATOR},
|
||||||
|
{"role": "user", "content": prompt},
|
||||||
|
],
|
||||||
|
"stream": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
try:
|
||||||
|
# We need a user object for permission checks in generate_chat_completion
|
||||||
|
user = Users.get_user_by_id(user_id)
|
||||||
|
if not user:
|
||||||
|
return current_rules
|
||||||
|
|
||||||
|
completion = await generate_chat_completion(__request__, payload, user)
|
||||||
|
if "choices" in completion and len(completion["choices"]) > 0:
|
||||||
|
content = completion["choices"][0]["message"]["content"].strip()
|
||||||
|
# Basic validation: ensure it looks like a list
|
||||||
|
if (
|
||||||
|
content.startswith("-")
|
||||||
|
or content.startswith("*")
|
||||||
|
or content.startswith("1.")
|
||||||
|
):
|
||||||
|
return content
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Rule generation failed: {e}")
|
||||||
|
|
||||||
|
return current_rules
|
||||||
|
|
||||||
|
async def _process_rules_update(
|
||||||
|
self,
|
||||||
|
folder_id: str,
|
||||||
|
body: dict,
|
||||||
|
user_id: str,
|
||||||
|
__request__: Request,
|
||||||
|
__event_emitter__,
|
||||||
|
):
|
||||||
|
try:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Start Processing",
|
||||||
|
{"step": "start", "initial_folder_id": folder_id, "user_id": user_id},
|
||||||
|
)
|
||||||
|
|
||||||
|
# 1. Fetch Folder Data (ORM)
|
||||||
|
initial_folder = Folders.get_folder_by_id_and_user_id(folder_id, user_id)
|
||||||
|
if not initial_folder:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Error: Initial folder not found",
|
||||||
|
{
|
||||||
|
"step": "fetch_initial_folder",
|
||||||
|
"initial_folder_id": folder_id,
|
||||||
|
"user_id": user_id,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
# Subfolder handling logic
|
||||||
|
target_folder = initial_folder
|
||||||
|
if self.valves.UPDATE_ROOT_FOLDER:
|
||||||
|
# Traverse up until a folder with no parent_id is found
|
||||||
|
while target_folder and getattr(target_folder, "parent_id", None):
|
||||||
|
try:
|
||||||
|
parent = Folders.get_folder_by_id_and_user_id(
|
||||||
|
target_folder.parent_id, user_id
|
||||||
|
)
|
||||||
|
if parent:
|
||||||
|
target_folder = parent
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Warning: Failed to traverse parent folder",
|
||||||
|
{"step": "traverse_root", "error": str(e)},
|
||||||
|
)
|
||||||
|
break
|
||||||
|
|
||||||
|
target_folder_id = target_folder.id
|
||||||
|
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Target Folder Resolved",
|
||||||
|
{
|
||||||
|
"step": "target_resolved",
|
||||||
|
"target_folder_id": target_folder_id,
|
||||||
|
"target_folder_name": target_folder.name,
|
||||||
|
"is_root_update": target_folder_id != folder_id,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
existing_data = target_folder.data if target_folder.data else {}
|
||||||
|
existing_sys_prompt = existing_data.get("system_prompt", "")
|
||||||
|
|
||||||
|
# 2. Extract Existing Rules
|
||||||
|
current_rules_content = self._extract_existing_rules(existing_sys_prompt)
|
||||||
|
|
||||||
|
# 3. Generate New Rules
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "Analyzing project rules...", done=False
|
||||||
|
)
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
new_rules_content = await self._generate_new_rules(
|
||||||
|
current_rules_content, messages, user_id, __request__
|
||||||
|
)
|
||||||
|
|
||||||
|
rules_changed = new_rules_content != current_rules_content
|
||||||
|
|
||||||
|
# 4. If no change, skip
|
||||||
|
if not rules_changed:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"No Changes",
|
||||||
|
{
|
||||||
|
"step": "check_changes",
|
||||||
|
"reason": "content_identical_or_generation_failed",
|
||||||
|
},
|
||||||
|
)
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__,
|
||||||
|
"Rule analysis complete: No new content.",
|
||||||
|
done=True,
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
# 5. Inject Rules into System Prompt
|
||||||
|
updated_sys_prompt = existing_sys_prompt
|
||||||
|
if rules_changed:
|
||||||
|
updated_sys_prompt = self._inject_rules(
|
||||||
|
updated_sys_prompt,
|
||||||
|
new_rules_content,
|
||||||
|
self.valves.RULES_BLOCK_TITLE,
|
||||||
|
)
|
||||||
|
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Ready to Update DB",
|
||||||
|
{"step": "pre_db_update", "target_folder_id": target_folder_id},
|
||||||
|
)
|
||||||
|
|
||||||
|
# 6. Update Folder (ORM) - Only update 'data' field
|
||||||
|
existing_data["system_prompt"] = updated_sys_prompt
|
||||||
|
|
||||||
|
updated_folder = Folders.update_folder_by_id_and_user_id(
|
||||||
|
target_folder_id,
|
||||||
|
user_id,
|
||||||
|
FolderUpdateForm(data=existing_data),
|
||||||
|
)
|
||||||
|
|
||||||
|
if not updated_folder:
|
||||||
|
raise Exception("Update folder failed (ORM returned None)")
|
||||||
|
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "Rule analysis complete: Rules updated.", done=True
|
||||||
|
)
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Rule Generation Process & Change Details",
|
||||||
|
{
|
||||||
|
"step": "success",
|
||||||
|
"folder_id": target_folder_id,
|
||||||
|
"target_is_root": target_folder_id != folder_id,
|
||||||
|
"model_used": self.valves.MODEL_ID,
|
||||||
|
"analyzed_messages_count": len(messages),
|
||||||
|
"old_rules_length": len(current_rules_content),
|
||||||
|
"new_rules_length": len(new_rules_content),
|
||||||
|
"changes_digest": {
|
||||||
|
"old_rules_preview": (
|
||||||
|
current_rules_content[:100] + "..."
|
||||||
|
if current_rules_content
|
||||||
|
else "None"
|
||||||
|
),
|
||||||
|
"new_rules_preview": (
|
||||||
|
new_rules_content[:100] + "..."
|
||||||
|
if new_rules_content
|
||||||
|
else "None"
|
||||||
|
),
|
||||||
|
},
|
||||||
|
"timestamp": datetime.now().isoformat(),
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Async rule processing error: {e}")
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "Failed to update rules.", done=True
|
||||||
|
)
|
||||||
|
# Emit error to console for debugging
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Execution Error",
|
||||||
|
{"error": str(e), "folder_id": folder_id},
|
||||||
|
)
|
||||||
|
|
||||||
|
# ==================== Filter Hooks ====================
|
||||||
|
|
||||||
|
async def inlet(
|
||||||
|
self, body: dict, __user__: Optional[dict] = None, __event_emitter__=None
|
||||||
|
) -> dict:
|
||||||
|
return body
|
||||||
|
|
||||||
|
async def outlet(
|
||||||
|
self,
|
||||||
|
body: dict,
|
||||||
|
__user__: Optional[dict] = None,
|
||||||
|
__event_emitter__=None,
|
||||||
|
__request__: Optional[Request] = None,
|
||||||
|
) -> dict:
|
||||||
|
user_ctx = self._get_user_context(__user__)
|
||||||
|
chat_ctx = self._get_chat_context(body)
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
if not messages:
|
||||||
|
return body
|
||||||
|
|
||||||
|
# Trigger logic: Message Count threshold
|
||||||
|
if len(messages) % self.valves.MESSAGE_TRIGGER_COUNT != 0:
|
||||||
|
return body
|
||||||
|
|
||||||
|
folder_id = self._get_folder_id(body)
|
||||||
|
if not folder_id:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"Skipping Analysis",
|
||||||
|
{
|
||||||
|
"reason": "Chat does not belong to any folder",
|
||||||
|
"chat_id": chat_ctx.get("chat_id"),
|
||||||
|
},
|
||||||
|
)
|
||||||
|
return body
|
||||||
|
|
||||||
|
# User Info
|
||||||
|
user_id = user_ctx.get("user_id")
|
||||||
|
if not user_id:
|
||||||
|
return body
|
||||||
|
|
||||||
|
# Async Task
|
||||||
|
if self.valves.MODEL_ID == "":
|
||||||
|
self.valves.MODEL_ID = body.get("model", "")
|
||||||
|
|
||||||
|
asyncio.create_task(
|
||||||
|
self._process_rules_update(
|
||||||
|
folder_id, body, user_id, __request__, __event_emitter__
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return body
|
||||||
470
plugins/filters/folder-memory/folder_memory_cn.py
Normal file
470
plugins/filters/folder-memory/folder_memory_cn.py
Normal file
@@ -0,0 +1,470 @@
|
|||||||
|
"""
|
||||||
|
title: 📂 文件夹记忆 (Folder Memory)
|
||||||
|
author: Fu-Jie
|
||||||
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
|
funding_url: https://github.com/open-webui
|
||||||
|
version: 0.1.0
|
||||||
|
description: 自动从对话中提取项目规则,并将其注入到文件夹的系统提示词中。
|
||||||
|
requirements:
|
||||||
|
"""
|
||||||
|
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
from typing import Optional, Dict, List
|
||||||
|
from fastapi import Request
|
||||||
|
import logging
|
||||||
|
import json
|
||||||
|
import re
|
||||||
|
import asyncio
|
||||||
|
from datetime import datetime
|
||||||
|
|
||||||
|
from open_webui.utils.chat import generate_chat_completion
|
||||||
|
from open_webui.models.users import Users
|
||||||
|
from open_webui.models.folders import Folders, FolderUpdateForm
|
||||||
|
from open_webui.models.chats import Chats
|
||||||
|
|
||||||
|
logging.basicConfig(
|
||||||
|
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||||
|
)
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# 规则注入标记
|
||||||
|
RULES_BLOCK_START = "<!-- OWUI_PROJECT_RULES_START -->"
|
||||||
|
RULES_BLOCK_END = "<!-- OWUI_PROJECT_RULES_END -->"
|
||||||
|
|
||||||
|
# 规则生成系统提示词
|
||||||
|
SYSTEM_PROMPT_RULE_GENERATOR = """
|
||||||
|
你是一个项目规则提取器。你的任务是从对话中提取“项目规则”,并与现有规则合并。
|
||||||
|
|
||||||
|
### 输入
|
||||||
|
1. **现有规则 (Existing Rules)**:当前文件夹系统提示词中的规则。
|
||||||
|
2. **对话片段 (Conversation)**:最近的聊天记录。
|
||||||
|
|
||||||
|
### 目标
|
||||||
|
综合生成一份适用于当前项目/文件夹的简洁规则列表。
|
||||||
|
- **移除** 不再相关或仅是一次性指令的规则。
|
||||||
|
- **添加** 对话中发现的新的、一致性的要求。
|
||||||
|
- **合并** 相似的规则。
|
||||||
|
- **格式**:简洁的 Markdown 项目符号列表。
|
||||||
|
|
||||||
|
### 输出格式
|
||||||
|
仅输出 Markdown 项目符号列表形式的规则。不要包含任何开头或结尾的说明文字。
|
||||||
|
示例:
|
||||||
|
- 始终使用 Python 3.11 进行类型提示。
|
||||||
|
- 文档字符串必须遵循 Google 风格。
|
||||||
|
- 提交信息必须使用英文。
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class Filter:
|
||||||
|
class Valves(BaseModel):
|
||||||
|
PRIORITY: int = Field(default=20, description="过滤器操作的优先级。")
|
||||||
|
SHOW_DEBUG_LOG: bool = Field(
|
||||||
|
default=False, description="在控制台显示调试日志。"
|
||||||
|
)
|
||||||
|
MESSAGE_TRIGGER_COUNT: int = Field(
|
||||||
|
default=10, description="每隔 N 条消息分析一次规则。"
|
||||||
|
)
|
||||||
|
MODEL_ID: str = Field(
|
||||||
|
default="", description="用于提取规则的模型 ID。为空则使用当前对话模型。"
|
||||||
|
)
|
||||||
|
RULES_BLOCK_TITLE: str = Field(
|
||||||
|
default="## 📂 项目规则", description="显示在规则块上方的标题。"
|
||||||
|
)
|
||||||
|
UPDATE_ROOT_FOLDER: bool = Field(
|
||||||
|
default=False,
|
||||||
|
description="如果启用,将向上查找并更新根文件夹的规则,而不是当前子文件夹。",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.valves = self.Valves()
|
||||||
|
|
||||||
|
# ==================== 辅助方法 ====================
|
||||||
|
|
||||||
|
def _get_user_context(self, __user__: Optional[dict]) -> Dict[str, str]:
|
||||||
|
"""安全提取用户上下文信息。"""
|
||||||
|
if isinstance(__user__, (list, tuple)):
|
||||||
|
user_data = __user__[0] if __user__ else {}
|
||||||
|
elif isinstance(__user__, dict):
|
||||||
|
user_data = __user__
|
||||||
|
else:
|
||||||
|
user_data = {}
|
||||||
|
|
||||||
|
return {
|
||||||
|
"user_id": user_data.get("id", ""),
|
||||||
|
"user_name": user_data.get("name", "User"),
|
||||||
|
"user_language": user_data.get("language", "zh-CN"),
|
||||||
|
}
|
||||||
|
|
||||||
|
def _get_chat_context(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Dict[str, str]:
|
||||||
|
"""统一提取聊天上下文信息 (chat_id, message_id)。"""
|
||||||
|
chat_id = ""
|
||||||
|
message_id = ""
|
||||||
|
|
||||||
|
if isinstance(body, dict):
|
||||||
|
chat_id = body.get("chat_id", "")
|
||||||
|
message_id = body.get("id", "")
|
||||||
|
|
||||||
|
if not chat_id or not message_id:
|
||||||
|
body_metadata = body.get("metadata", {})
|
||||||
|
if isinstance(body_metadata, dict):
|
||||||
|
if not chat_id:
|
||||||
|
chat_id = body_metadata.get("chat_id", "")
|
||||||
|
if not message_id:
|
||||||
|
message_id = body_metadata.get("message_id", "")
|
||||||
|
|
||||||
|
if __metadata__ and isinstance(__metadata__, dict):
|
||||||
|
if not chat_id:
|
||||||
|
chat_id = __metadata__.get("chat_id", "")
|
||||||
|
if not message_id:
|
||||||
|
message_id = __metadata__.get("message_id", "")
|
||||||
|
|
||||||
|
return {
|
||||||
|
"chat_id": str(chat_id).strip(),
|
||||||
|
"message_id": str(message_id).strip(),
|
||||||
|
}
|
||||||
|
|
||||||
|
async def _emit_debug_log(self, __event_emitter__, title: str, data: dict):
|
||||||
|
if self.valves.SHOW_DEBUG_LOG and __event_emitter__:
|
||||||
|
try:
|
||||||
|
# 按照用户要求的格式输出展平的日志
|
||||||
|
js_code = f"""
|
||||||
|
console.log("[Folder Memory] {title}", {json.dumps(data, ensure_ascii=False)});
|
||||||
|
"""
|
||||||
|
await __event_emitter__({"type": "execute", "data": {"code": js_code}})
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"发出日志错误: {e}")
|
||||||
|
|
||||||
|
async def _emit_status(
|
||||||
|
self, __event_emitter__, description: str, done: bool = False
|
||||||
|
):
|
||||||
|
if __event_emitter__:
|
||||||
|
await __event_emitter__(
|
||||||
|
{"type": "status", "data": {"description": description, "done": done}}
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_folder_id(self, body: dict) -> Optional[str]:
|
||||||
|
# 1. 尝试从 metadata 获取 folder_id
|
||||||
|
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||||
|
if "folder_id" in body["metadata"]:
|
||||||
|
return body["metadata"]["folder_id"]
|
||||||
|
|
||||||
|
# 2. 检查 chat 对象
|
||||||
|
if "chat" in body and isinstance(body["chat"], dict):
|
||||||
|
if "folder_id" in body["chat"]:
|
||||||
|
return body["chat"]["folder_id"]
|
||||||
|
|
||||||
|
# 3. 尝试通过 Chat ID 查找 (最可靠的方法)
|
||||||
|
chat_id = body.get("chat_id")
|
||||||
|
if not chat_id:
|
||||||
|
if "metadata" in body and isinstance(body["metadata"], dict):
|
||||||
|
chat_id = body["metadata"].get("chat_id")
|
||||||
|
|
||||||
|
if chat_id:
|
||||||
|
try:
|
||||||
|
chat = Chats.get_chat_by_id(chat_id)
|
||||||
|
if chat and chat.folder_id:
|
||||||
|
return chat.folder_id
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"获取聊天信息失败 chat_id={chat_id}: {e}")
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
def _extract_existing_rules(self, system_prompt: str) -> str:
|
||||||
|
pattern = re.compile(
|
||||||
|
re.escape(RULES_BLOCK_START) + r"([\s\S]*?)" + re.escape(RULES_BLOCK_END)
|
||||||
|
)
|
||||||
|
match = pattern.search(system_prompt)
|
||||||
|
if match:
|
||||||
|
# 如果标题在块内,将其移除以便纯净合并
|
||||||
|
content = match.group(1).strip()
|
||||||
|
title_pat = re.compile(r"^#+\s+.*$", re.MULTILINE)
|
||||||
|
return title_pat.sub("", content).strip()
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def _inject_rules(self, system_prompt: str, new_rules: str, title: str) -> str:
|
||||||
|
new_block_content = f"\n{title}\n\n{new_rules}\n"
|
||||||
|
new_block = f"{RULES_BLOCK_START}{new_block_content}{RULES_BLOCK_END}"
|
||||||
|
|
||||||
|
system_prompt = system_prompt or ""
|
||||||
|
pattern = re.compile(
|
||||||
|
re.escape(RULES_BLOCK_START) + r"[\s\S]*?" + re.escape(RULES_BLOCK_END)
|
||||||
|
)
|
||||||
|
|
||||||
|
if pattern.search(system_prompt):
|
||||||
|
# 替换现有块
|
||||||
|
return pattern.sub(new_block, system_prompt).strip()
|
||||||
|
else:
|
||||||
|
# 追加到末尾
|
||||||
|
if system_prompt:
|
||||||
|
return f"{system_prompt}\n\n{new_block}"
|
||||||
|
else:
|
||||||
|
return new_block
|
||||||
|
|
||||||
|
async def _generate_new_rules(
|
||||||
|
self,
|
||||||
|
current_rules: str,
|
||||||
|
messages: List[Dict],
|
||||||
|
user_id: str,
|
||||||
|
__request__: Request,
|
||||||
|
) -> str:
|
||||||
|
# 准备上下文
|
||||||
|
conversation_text = "\n".join(
|
||||||
|
[
|
||||||
|
f"{msg['role'].upper()}: {msg['content']}"
|
||||||
|
for msg in messages[-20:] # 分析最近 20 条消息上下文
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
prompt = f"""
|
||||||
|
Existing Rules (现有规则):
|
||||||
|
{current_rules if current_rules else "无"}
|
||||||
|
|
||||||
|
Conversation Excerpt (对话片段):
|
||||||
|
{conversation_text}
|
||||||
|
|
||||||
|
Please output the updated Project Rules (请输出更新后的项目规则):
|
||||||
|
"""
|
||||||
|
|
||||||
|
payload = {
|
||||||
|
"model": self.valves.MODEL_ID,
|
||||||
|
"messages": [
|
||||||
|
{"role": "system", "content": SYSTEM_PROMPT_RULE_GENERATOR},
|
||||||
|
{"role": "user", "content": prompt},
|
||||||
|
],
|
||||||
|
"stream": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
try:
|
||||||
|
# 需要用户对象进行权限检查
|
||||||
|
user = Users.get_user_by_id(user_id)
|
||||||
|
if not user:
|
||||||
|
return current_rules
|
||||||
|
|
||||||
|
completion = await generate_chat_completion(__request__, payload, user)
|
||||||
|
if "choices" in completion and len(completion["choices"]) > 0:
|
||||||
|
content = completion["choices"][0]["message"]["content"].strip()
|
||||||
|
# 简单验证:确保看起来像个列表
|
||||||
|
if (
|
||||||
|
content.startswith("-")
|
||||||
|
or content.startswith("*")
|
||||||
|
or content.startswith("1.")
|
||||||
|
):
|
||||||
|
return content
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"规则生成失败: {e}")
|
||||||
|
|
||||||
|
return current_rules
|
||||||
|
|
||||||
|
async def _process_rules_update(
|
||||||
|
self,
|
||||||
|
folder_id: str,
|
||||||
|
body: dict,
|
||||||
|
user_id: str,
|
||||||
|
__request__: Request,
|
||||||
|
__event_emitter__,
|
||||||
|
):
|
||||||
|
try:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"开始处理",
|
||||||
|
{"step": "start", "initial_folder_id": folder_id, "user_id": user_id},
|
||||||
|
)
|
||||||
|
|
||||||
|
# 1. 获取文件夹数据 (ORM)
|
||||||
|
initial_folder = Folders.get_folder_by_id_and_user_id(folder_id, user_id)
|
||||||
|
if not initial_folder:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"错误:未找到初始文件夹",
|
||||||
|
{
|
||||||
|
"step": "fetch_initial_folder",
|
||||||
|
"initial_folder_id": folder_id,
|
||||||
|
"user_id": user_id,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
# 处理子文件夹逻辑:决定是更新当前文件夹还是根文件夹
|
||||||
|
target_folder = initial_folder
|
||||||
|
if self.valves.UPDATE_ROOT_FOLDER:
|
||||||
|
# 向上遍历直到找到没有 parent_id 的根文件夹
|
||||||
|
while target_folder and getattr(target_folder, "parent_id", None):
|
||||||
|
try:
|
||||||
|
parent = Folders.get_folder_by_id_and_user_id(
|
||||||
|
target_folder.parent_id, user_id
|
||||||
|
)
|
||||||
|
if parent:
|
||||||
|
target_folder = parent
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"警告:向上查找父文件夹失败",
|
||||||
|
{"step": "traverse_root", "error": str(e)},
|
||||||
|
)
|
||||||
|
break
|
||||||
|
|
||||||
|
target_folder_id = target_folder.id
|
||||||
|
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"定目标文件夹",
|
||||||
|
{
|
||||||
|
"step": "target_resolved",
|
||||||
|
"target_folder_id": target_folder_id,
|
||||||
|
"target_folder_name": target_folder.name,
|
||||||
|
"is_root_update": target_folder_id != folder_id,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
existing_data = target_folder.data if target_folder.data else {}
|
||||||
|
existing_sys_prompt = existing_data.get("system_prompt", "")
|
||||||
|
|
||||||
|
# 2. 提取现有规则
|
||||||
|
current_rules_content = self._extract_existing_rules(existing_sys_prompt)
|
||||||
|
|
||||||
|
# 3. 生成新规则
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "正在分析项目规则...", done=False
|
||||||
|
)
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
new_rules_content = await self._generate_new_rules(
|
||||||
|
current_rules_content, messages, user_id, __request__
|
||||||
|
)
|
||||||
|
|
||||||
|
rules_changed = new_rules_content != current_rules_content
|
||||||
|
|
||||||
|
# 如果生成结果无变更
|
||||||
|
if not rules_changed:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"无变更",
|
||||||
|
{
|
||||||
|
"step": "check_changes",
|
||||||
|
"reason": "content_identical_or_generation_failed",
|
||||||
|
},
|
||||||
|
)
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "规则分析完成:无新增内容。", done=True
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
# 5. 注入规则到 System Prompt
|
||||||
|
updated_sys_prompt = existing_sys_prompt
|
||||||
|
if rules_changed:
|
||||||
|
updated_sys_prompt = self._inject_rules(
|
||||||
|
updated_sys_prompt,
|
||||||
|
new_rules_content,
|
||||||
|
self.valves.RULES_BLOCK_TITLE,
|
||||||
|
)
|
||||||
|
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"准备更新数据库",
|
||||||
|
{"step": "pre_db_update", "target_folder_id": target_folder_id},
|
||||||
|
)
|
||||||
|
|
||||||
|
# 6. 更新文件夹 (ORM) - 仅更新 'data' 字段
|
||||||
|
existing_data["system_prompt"] = updated_sys_prompt
|
||||||
|
|
||||||
|
updated_folder = Folders.update_folder_by_id_and_user_id(
|
||||||
|
target_folder_id,
|
||||||
|
user_id,
|
||||||
|
FolderUpdateForm(data=existing_data),
|
||||||
|
)
|
||||||
|
|
||||||
|
if not updated_folder:
|
||||||
|
raise Exception("Update folder failed (ORM returned None)")
|
||||||
|
|
||||||
|
await self._emit_status(
|
||||||
|
__event_emitter__, "规则分析完成:规则已更新。", done=True
|
||||||
|
)
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"规则生成过程和变更详情",
|
||||||
|
{
|
||||||
|
"step": "success",
|
||||||
|
"folder_id": target_folder_id,
|
||||||
|
"target_is_root": target_folder_id != folder_id,
|
||||||
|
"model_used": self.valves.MODEL_ID,
|
||||||
|
"analyzed_messages_count": len(messages),
|
||||||
|
"old_rules_length": len(current_rules_content),
|
||||||
|
"new_rules_length": len(new_rules_content),
|
||||||
|
"changes_digest": {
|
||||||
|
"old_rules_preview": (
|
||||||
|
current_rules_content[:100] + "..."
|
||||||
|
if current_rules_content
|
||||||
|
else "None"
|
||||||
|
),
|
||||||
|
"new_rules_preview": (
|
||||||
|
new_rules_content[:100] + "..."
|
||||||
|
if new_rules_content
|
||||||
|
else "None"
|
||||||
|
),
|
||||||
|
},
|
||||||
|
"timestamp": datetime.now().isoformat(),
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"异步规则处理错误: {e}")
|
||||||
|
await self._emit_status(__event_emitter__, "更新规则失败。", done=True)
|
||||||
|
# 在控制台也输出错误信息,方便调试
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__, "执行出错", {"error": str(e), "folder_id": folder_id}
|
||||||
|
)
|
||||||
|
|
||||||
|
# ==================== Filter Hooks ====================
|
||||||
|
|
||||||
|
async def inlet(
|
||||||
|
self, body: dict, __user__: Optional[dict] = None, __event_emitter__=None
|
||||||
|
) -> dict:
|
||||||
|
return body
|
||||||
|
|
||||||
|
async def outlet(
|
||||||
|
self,
|
||||||
|
body: dict,
|
||||||
|
__user__: Optional[dict] = None,
|
||||||
|
__event_emitter__=None,
|
||||||
|
__request__: Optional[Request] = None,
|
||||||
|
) -> dict:
|
||||||
|
user_ctx = self._get_user_context(__user__)
|
||||||
|
chat_ctx = self._get_chat_context(body)
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
if not messages:
|
||||||
|
return body
|
||||||
|
|
||||||
|
# 触发逻辑:消息计数阈值
|
||||||
|
if len(messages) % self.valves.MESSAGE_TRIGGER_COUNT != 0:
|
||||||
|
return body
|
||||||
|
|
||||||
|
folder_id = self._get_folder_id(body)
|
||||||
|
if not folder_id:
|
||||||
|
await self._emit_debug_log(
|
||||||
|
__event_emitter__,
|
||||||
|
"跳过分析",
|
||||||
|
{"reason": "对话不属于任何文件夹", "chat_id": chat_ctx.get("chat_id")},
|
||||||
|
)
|
||||||
|
return body
|
||||||
|
|
||||||
|
# 用户信息
|
||||||
|
user_id = user_ctx.get("user_id")
|
||||||
|
if not user_id:
|
||||||
|
return body
|
||||||
|
|
||||||
|
# 异步任务
|
||||||
|
if self.valves.MODEL_ID == "":
|
||||||
|
self.valves.MODEL_ID = body.get("model", "")
|
||||||
|
|
||||||
|
asyncio.create_task(
|
||||||
|
self._process_rules_update(
|
||||||
|
folder_id, body, user_id, __request__, __event_emitter__
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return body
|
||||||
81
plugins/pipes/github-copilot-sdk/README.md
Normal file
81
plugins/pipes/github-copilot-sdk/README.md
Normal file
@@ -0,0 +1,81 @@
|
|||||||
|
# GitHub Copilot SDK Pipe for OpenWebUI
|
||||||
|
|
||||||
|
**Author:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **Version:** 0.1.1 | **Project:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **License:** MIT
|
||||||
|
|
||||||
|
This is an advanced Pipe function for [OpenWebUI](https://github.com/open-webui/open-webui) that allows you to use GitHub Copilot models (such as `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`) directly within OpenWebUI. It is built upon the official [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk), providing a native integration experience.
|
||||||
|
|
||||||
|
## 🚀 What's New (v0.1.1)
|
||||||
|
|
||||||
|
* **♾️ Infinite Sessions**: Automatic context compaction for long-running conversations. No more context limit errors!
|
||||||
|
* **🧠 Thinking Process**: Real-time display of model reasoning/thinking process (for supported models).
|
||||||
|
* **📂 Workspace Control**: Restricted workspace directory for secure file operations.
|
||||||
|
* **🔍 Model Filtering**: Exclude specific models using keywords (e.g., `codex`, `haiku`).
|
||||||
|
* **💾 Session Persistence**: Improved session resume logic using OpenWebUI chat ID mapping.
|
||||||
|
|
||||||
|
## ✨ Core Features
|
||||||
|
|
||||||
|
* **🚀 Official SDK Integration**: Built on the official SDK for stability and reliability.
|
||||||
|
* **💬 Multi-turn Conversation**: Automatically concatenates history context so Copilot understands your previous messages.
|
||||||
|
* **🌊 Streaming Output**: Supports typewriter effect for fast responses.
|
||||||
|
* **🖼️ Multimodal Support**: Supports image uploads, automatically converting them to attachments for Copilot (requires model support).
|
||||||
|
* **🛠️ Zero-config Installation**: Automatically detects and downloads the GitHub Copilot CLI, ready to use out of the box.
|
||||||
|
* **🔑 Secure Authentication**: Supports Fine-grained Personal Access Tokens for minimized permissions.
|
||||||
|
* **🐛 Debug Mode**: Built-in detailed log output for easy connection troubleshooting.
|
||||||
|
* **⚠️ Single Node Only**: Due to local session storage, this plugin currently supports single-node OpenWebUI deployment or multi-node with sticky sessions enabled.
|
||||||
|
|
||||||
|
## 📦 Installation & Usage
|
||||||
|
|
||||||
|
### 1. Import Function
|
||||||
|
|
||||||
|
1. Open OpenWebUI.
|
||||||
|
2. Go to **Workspace** -> **Functions**.
|
||||||
|
3. Click **+** (Create Function).
|
||||||
|
4. Paste the content of `github_copilot_sdk.py` (or `github_copilot_sdk_cn.py` for Chinese) completely.
|
||||||
|
5. Save.
|
||||||
|
|
||||||
|
### 2. Configure Valves (Settings)
|
||||||
|
|
||||||
|
Find "GitHub Copilot" in the function list and click the **⚙️ (Valves)** icon to configure:
|
||||||
|
|
||||||
|
| Parameter | Description | Default |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| **GH_TOKEN** | **(Required)** Your GitHub Token. | - |
|
||||||
|
| **MODEL_ID** | The model name to use. | `gpt-5-mini` |
|
||||||
|
| **CLI_PATH** | Path to the Copilot CLI. Will download automatically if not found. | `/usr/local/bin/copilot` |
|
||||||
|
| **DEBUG** | Whether to enable debug logs (output to chat). | `True` |
|
||||||
|
| **SHOW_THINKING** | Show model reasoning/thinking process. | `True` |
|
||||||
|
| **EXCLUDE_KEYWORDS** | Exclude models containing these keywords (comma separated). | - |
|
||||||
|
| **WORKSPACE_DIR** | Restricted workspace directory for file operations. | - |
|
||||||
|
| **INFINITE_SESSION** | Enable Infinite Sessions (automatic context compaction). | `True` |
|
||||||
|
| **COMPACTION_THRESHOLD** | Background compaction threshold (0.0-1.0). | `0.8` |
|
||||||
|
| **BUFFER_THRESHOLD** | Buffer exhaustion threshold (0.0-1.0). | `0.95` |
|
||||||
|
| **TIMEOUT** | Timeout for each stream chunk (seconds). | `300` |
|
||||||
|
|
||||||
|
### 3. Get GH_TOKEN
|
||||||
|
|
||||||
|
For security, it is recommended to use a **Fine-grained Personal Access Token**:
|
||||||
|
|
||||||
|
1. Visit [GitHub Token Settings](https://github.com/settings/tokens?type=beta).
|
||||||
|
2. Click **Generate new token**.
|
||||||
|
3. **Repository access**: Select **Public repositories** (Required to access Copilot permissions).
|
||||||
|
4. **Permissions**:
|
||||||
|
* Click **Account permissions**.
|
||||||
|
* Find **Copilot Requests** (It defaults to **Read-only**, no selection needed).
|
||||||
|
5. Generate and copy the Token.
|
||||||
|
|
||||||
|
## 📋 Dependencies
|
||||||
|
|
||||||
|
This Pipe will automatically attempt to install the following dependencies:
|
||||||
|
|
||||||
|
* `github-copilot-sdk` (Python package)
|
||||||
|
* `github-copilot-cli` (Binary file, installed via official script)
|
||||||
|
|
||||||
|
## ⚠️ FAQ
|
||||||
|
|
||||||
|
* **Stuck on "Waiting..."**:
|
||||||
|
* Check if `GH_TOKEN` is correct and has `Copilot Requests` permission.
|
||||||
|
* **Images not recognized**:
|
||||||
|
* Ensure `MODEL_ID` is a model that supports multimodal input.
|
||||||
|
* **CLI Installation Failed**:
|
||||||
|
* Ensure the OpenWebUI container has internet access.
|
||||||
|
* You can manually download the CLI and specify `CLI_PATH` in Valves.
|
||||||
81
plugins/pipes/github-copilot-sdk/README_CN.md
Normal file
81
plugins/pipes/github-copilot-sdk/README_CN.md
Normal file
@@ -0,0 +1,81 @@
|
|||||||
|
# GitHub Copilot SDK 官方管道
|
||||||
|
|
||||||
|
**作者:** [Fu-Jie](https://github.com/Fu-Jie/awesome-openwebui) | **版本:** 0.1.1 | **项目:** [Awesome OpenWebUI](https://github.com/Fu-Jie/awesome-openwebui) | **许可证:** MIT
|
||||||
|
|
||||||
|
这是一个用于 [OpenWebUI](https://github.com/open-webui/open-webui) 的高级 Pipe 函数,允许你直接在 OpenWebUI 中使用 GitHub Copilot 模型(如 `gpt-5`, `gpt-5-mini`, `claude-sonnet-4.5`)。它基于官方 [GitHub Copilot SDK for Python](https://github.com/github/copilot-sdk) 构建,提供了原生级的集成体验。
|
||||||
|
|
||||||
|
## 🚀 最新特性 (v0.1.1)
|
||||||
|
|
||||||
|
* **♾️ 无限会话 (Infinite Sessions)**:支持长对话的自动上下文压缩,告别上下文超限错误!
|
||||||
|
* **🧠 思考过程展示**:实时显示模型的推理/思考过程(需模型支持)。
|
||||||
|
* **📂 工作目录控制**:支持设置受限工作目录,确保文件操作安全。
|
||||||
|
* **🔍 模型过滤**:支持通过关键词排除特定模型(如 `codex`, `haiku`)。
|
||||||
|
* **💾 会话持久化**: 改进的会话恢复逻辑,直接关联 OpenWebUI 聊天 ID,连接更稳定。
|
||||||
|
|
||||||
|
## ✨ 核心特性
|
||||||
|
|
||||||
|
* **🚀 官方 SDK 集成**:基于官方 SDK,稳定可靠。
|
||||||
|
* **💬 多轮对话支持**:自动拼接历史上下文,Copilot 能理解你的前文。
|
||||||
|
* **🌊 流式输出 (Streaming)**:支持打字机效果,响应迅速。
|
||||||
|
* **🖼️ 多模态支持**:支持上传图片,自动转换为附件发送给 Copilot(需模型支持)。
|
||||||
|
* **🛠️ 零配置安装**:自动检测并下载 GitHub Copilot CLI,开箱即用。
|
||||||
|
* **🔑 安全认证**:支持 Fine-grained Personal Access Tokens,权限最小化。
|
||||||
|
* **🐛 调试模式**:内置详细的日志输出,方便排查连接问题。
|
||||||
|
* **⚠️ 仅支持单节点**:由于会话状态存储在本地,本插件目前仅支持 OpenWebUI 单节点部署,或开启了会话粘性 (Sticky Session) 的多节点集群。
|
||||||
|
|
||||||
|
## 📦 安装与使用
|
||||||
|
|
||||||
|
### 1. 导入函数
|
||||||
|
|
||||||
|
1. 打开 OpenWebUI。
|
||||||
|
2. 进入 **Workspace** -> **Functions**。
|
||||||
|
3. 点击 **+** (创建函数)。
|
||||||
|
4. 将 `github_copilot_sdk_cn.py` 的内容完整粘贴进去。
|
||||||
|
5. 保存。
|
||||||
|
|
||||||
|
### 2. 配置 Valves (设置)
|
||||||
|
|
||||||
|
在函数列表中找到 "GitHub Copilot",点击 **⚙️ (Valves)** 图标进行配置:
|
||||||
|
|
||||||
|
| 参数 | 说明 | 默认值 |
|
||||||
|
| :--- | :--- | :--- |
|
||||||
|
| **GH_TOKEN** | **(必填)** 你的 GitHub Token。 | - |
|
||||||
|
| **MODEL_ID** | 使用的模型名称。 | `gpt-5-mini` |
|
||||||
|
| **CLI_PATH** | Copilot CLI 的路径。如果未找到会自动下载。 | `/usr/local/bin/copilot` |
|
||||||
|
| **DEBUG** | 是否开启调试日志(输出到对话框)。 | `True` |
|
||||||
|
| **SHOW_THINKING** | 是否显示模型推理/思考过程。 | `True` |
|
||||||
|
| **EXCLUDE_KEYWORDS** | 排除包含这些关键词的模型 (逗号分隔)。 | - |
|
||||||
|
| **WORKSPACE_DIR** | 文件操作的受限工作目录。 | - |
|
||||||
|
| **INFINITE_SESSION** | 启用无限会话 (自动上下文压缩)。 | `True` |
|
||||||
|
| **COMPACTION_THRESHOLD** | 后台压缩阈值 (0.0-1.0)。 | `0.8` |
|
||||||
|
| **BUFFER_THRESHOLD** | 缓冲耗尽阈值 (0.0-1.0)。 | `0.95` |
|
||||||
|
| **TIMEOUT** | 流式数据块超时时间 (秒)。 | `300` |
|
||||||
|
|
||||||
|
### 3. 获取 GH_TOKEN
|
||||||
|
|
||||||
|
为了安全起见,推荐使用 **Fine-grained Personal Access Token**:
|
||||||
|
|
||||||
|
1. 访问 [GitHub Token Settings](https://github.com/settings/tokens?type=beta)。
|
||||||
|
2. 点击 **Generate new token**。
|
||||||
|
3. **Repository access**: 选择 **Public repositories** (必须选择此项才能看到 Copilot 权限)。
|
||||||
|
4. **Permissions**:
|
||||||
|
* 点击 **Account permissions**。
|
||||||
|
* 找到 **Copilot Requests** (默认即为 **Read-only**,无需手动修改)。
|
||||||
|
5. 生成并复制 Token。
|
||||||
|
|
||||||
|
## 📋 依赖说明
|
||||||
|
|
||||||
|
该 Pipe 会自动尝试安装以下依赖(如果环境中缺失):
|
||||||
|
|
||||||
|
* `github-copilot-sdk` (Python 包)
|
||||||
|
* `github-copilot-cli` (二进制文件,通过官方脚本安装)
|
||||||
|
|
||||||
|
## ⚠️ 常见问题
|
||||||
|
|
||||||
|
* **一直显示 "Waiting..."**:
|
||||||
|
* 检查 `GH_TOKEN` 是否正确且拥有 `Copilot Requests` 权限。
|
||||||
|
* **图片无法识别**:
|
||||||
|
* 确保 `MODEL_ID` 是支持多模态的模型。
|
||||||
|
* **CLI 安装失败**:
|
||||||
|
* 确保 OpenWebUI 容器有外网访问权限。
|
||||||
|
* 你可以手动下载 CLI 并挂载到容器中,然后在 Valves 中指定 `CLI_PATH`。
|
||||||
BIN
plugins/pipes/github-copilot-sdk/github_copilot_sdk.png
Normal file
BIN
plugins/pipes/github-copilot-sdk/github_copilot_sdk.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 474 KiB |
690
plugins/pipes/github-copilot-sdk/github_copilot_sdk.py
Normal file
690
plugins/pipes/github-copilot-sdk/github_copilot_sdk.py
Normal file
@@ -0,0 +1,690 @@
|
|||||||
|
"""
|
||||||
|
title: GitHub Copilot Official SDK Pipe
|
||||||
|
author: Fu-Jie
|
||||||
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
|
funding_url: https://github.com/open-webui
|
||||||
|
openwebui_id: ce96f7b4-12fc-4ac3-9a01-875713e69359
|
||||||
|
description: Integrate GitHub Copilot SDK. Supports dynamic models, multi-turn conversation, streaming, multimodal input, and infinite sessions (context compaction).
|
||||||
|
version: 0.1.1
|
||||||
|
requirements: github-copilot-sdk
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import json
|
||||||
|
import base64
|
||||||
|
import tempfile
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
import shutil
|
||||||
|
import subprocess
|
||||||
|
import sys
|
||||||
|
from typing import Optional, Union, AsyncGenerator, List, Any, Dict
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
from datetime import datetime, timezone
|
||||||
|
import contextlib
|
||||||
|
|
||||||
|
# Setup logger
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# Global client storage
|
||||||
|
_SHARED_CLIENT = None
|
||||||
|
_SHARED_TOKEN = ""
|
||||||
|
_CLIENT_LOCK = asyncio.Lock()
|
||||||
|
|
||||||
|
|
||||||
|
class Pipe:
|
||||||
|
class Valves(BaseModel):
|
||||||
|
GH_TOKEN: str = Field(
|
||||||
|
default="",
|
||||||
|
description="GitHub Fine-grained Token (Requires 'Copilot Requests' permission)",
|
||||||
|
)
|
||||||
|
MODEL_ID: str = Field(
|
||||||
|
default="claude-sonnet-4.5",
|
||||||
|
description="Default Copilot model name (used when dynamic fetching fails)",
|
||||||
|
)
|
||||||
|
CLI_PATH: str = Field(
|
||||||
|
default="/usr/local/bin/copilot",
|
||||||
|
description="Path to Copilot CLI",
|
||||||
|
)
|
||||||
|
DEBUG: bool = Field(
|
||||||
|
default=False,
|
||||||
|
description="Enable technical debug logs (connection info, etc.)",
|
||||||
|
)
|
||||||
|
SHOW_THINKING: bool = Field(
|
||||||
|
default=True,
|
||||||
|
description="Show model reasoning/thinking process",
|
||||||
|
)
|
||||||
|
EXCLUDE_KEYWORDS: str = Field(
|
||||||
|
default="",
|
||||||
|
description="Exclude models containing these keywords (comma separated, e.g.: codex, haiku)",
|
||||||
|
)
|
||||||
|
WORKSPACE_DIR: str = Field(
|
||||||
|
default="",
|
||||||
|
description="Restricted workspace directory for file operations. If empty, allows access to the current process directory.",
|
||||||
|
)
|
||||||
|
INFINITE_SESSION: bool = Field(
|
||||||
|
default=True,
|
||||||
|
description="Enable Infinite Sessions (automatic context compaction)",
|
||||||
|
)
|
||||||
|
COMPACTION_THRESHOLD: float = Field(
|
||||||
|
default=0.8,
|
||||||
|
description="Background compaction threshold (0.0-1.0)",
|
||||||
|
)
|
||||||
|
BUFFER_THRESHOLD: float = Field(
|
||||||
|
default=0.95,
|
||||||
|
description="Buffer exhaustion threshold (0.0-1.0)",
|
||||||
|
)
|
||||||
|
TIMEOUT: int = Field(
|
||||||
|
default=300,
|
||||||
|
description="Timeout for each stream chunk (seconds)",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.type = "pipe"
|
||||||
|
self.id = "copilotsdk"
|
||||||
|
self.name = "copilotsdk"
|
||||||
|
self.valves = self.Valves()
|
||||||
|
self.temp_dir = tempfile.mkdtemp(prefix="copilot_images_")
|
||||||
|
self.thinking_started = False
|
||||||
|
self._model_cache = [] # Model list cache
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
try:
|
||||||
|
shutil.rmtree(self.temp_dir)
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _emit_debug_log(self, message: str):
|
||||||
|
"""Emit debug log to frontend if DEBUG valve is enabled."""
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
print(f"[Copilot Pipe] {message}")
|
||||||
|
|
||||||
|
def _get_user_context(self):
|
||||||
|
"""Helper to get user context (placeholder for future use)."""
|
||||||
|
return {}
|
||||||
|
|
||||||
|
def _get_chat_context(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Dict[str, str]:
|
||||||
|
"""
|
||||||
|
Highly reliable chat context extraction logic.
|
||||||
|
Priority: __metadata__ > body['chat_id'] > body['metadata']['chat_id']
|
||||||
|
"""
|
||||||
|
chat_id = ""
|
||||||
|
source = "none"
|
||||||
|
|
||||||
|
# 1. Prioritize __metadata__ (most reliable source injected by OpenWebUI)
|
||||||
|
if __metadata__ and isinstance(__metadata__, dict):
|
||||||
|
chat_id = __metadata__.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "__metadata__"
|
||||||
|
|
||||||
|
# 2. Then try body root
|
||||||
|
if not chat_id and isinstance(body, dict):
|
||||||
|
chat_id = body.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "body_root"
|
||||||
|
|
||||||
|
# 3. Finally try body.metadata
|
||||||
|
if not chat_id and isinstance(body, dict):
|
||||||
|
body_metadata = body.get("metadata", {})
|
||||||
|
if isinstance(body_metadata, dict):
|
||||||
|
chat_id = body_metadata.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "body_metadata"
|
||||||
|
|
||||||
|
# Debug: Log ID source
|
||||||
|
if chat_id:
|
||||||
|
self._emit_debug_log(f"Extracted ChatID: {chat_id} (Source: {source})")
|
||||||
|
else:
|
||||||
|
# If still not found, log body keys for troubleshooting
|
||||||
|
keys = list(body.keys()) if isinstance(body, dict) else "not a dict"
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"Warning: Failed to extract ChatID. Body keys: {keys}"
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
"chat_id": str(chat_id).strip(),
|
||||||
|
}
|
||||||
|
|
||||||
|
async def pipes(self) -> List[dict]:
|
||||||
|
"""Dynamically fetch model list"""
|
||||||
|
# Return cache if available
|
||||||
|
if self._model_cache:
|
||||||
|
return self._model_cache
|
||||||
|
|
||||||
|
self._emit_debug_log("Fetching model list dynamically...")
|
||||||
|
try:
|
||||||
|
self._setup_env()
|
||||||
|
if not self.valves.GH_TOKEN:
|
||||||
|
return [{"id": f"{self.id}-error", "name": "Error: GH_TOKEN not set"}]
|
||||||
|
|
||||||
|
from copilot import CopilotClient
|
||||||
|
|
||||||
|
client_config = {}
|
||||||
|
if os.environ.get("COPILOT_CLI_PATH"):
|
||||||
|
client_config["cli_path"] = os.environ["COPILOT_CLI_PATH"]
|
||||||
|
|
||||||
|
client = CopilotClient(client_config)
|
||||||
|
try:
|
||||||
|
await client.start()
|
||||||
|
models = await client.list_models()
|
||||||
|
|
||||||
|
# Update cache
|
||||||
|
self._model_cache = []
|
||||||
|
exclude_list = [
|
||||||
|
k.strip().lower()
|
||||||
|
for k in self.valves.EXCLUDE_KEYWORDS.split(",")
|
||||||
|
if k.strip()
|
||||||
|
]
|
||||||
|
|
||||||
|
models_with_info = []
|
||||||
|
for m in models:
|
||||||
|
# Compatible with dict and object access
|
||||||
|
m_id = (
|
||||||
|
m.get("id") if isinstance(m, dict) else getattr(m, "id", str(m))
|
||||||
|
)
|
||||||
|
m_name = (
|
||||||
|
m.get("name")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "name", m_id)
|
||||||
|
)
|
||||||
|
m_policy = (
|
||||||
|
m.get("policy")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "policy", {})
|
||||||
|
)
|
||||||
|
m_billing = (
|
||||||
|
m.get("billing")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "billing", {})
|
||||||
|
)
|
||||||
|
|
||||||
|
# Check policy state
|
||||||
|
state = (
|
||||||
|
m_policy.get("state")
|
||||||
|
if isinstance(m_policy, dict)
|
||||||
|
else getattr(m_policy, "state", "enabled")
|
||||||
|
)
|
||||||
|
if state == "disabled":
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Filtering logic
|
||||||
|
if any(kw in m_id.lower() for kw in exclude_list):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Get multiplier
|
||||||
|
multiplier = (
|
||||||
|
m_billing.get("multiplier", 1)
|
||||||
|
if isinstance(m_billing, dict)
|
||||||
|
else getattr(m_billing, "multiplier", 1)
|
||||||
|
)
|
||||||
|
|
||||||
|
# Format display name
|
||||||
|
if multiplier == 0:
|
||||||
|
display_name = f"-🔥 {m_id} (unlimited)"
|
||||||
|
else:
|
||||||
|
display_name = f"-{m_id} ({multiplier}x)"
|
||||||
|
|
||||||
|
models_with_info.append(
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{m_id}",
|
||||||
|
"name": display_name,
|
||||||
|
"multiplier": multiplier,
|
||||||
|
"raw_id": m_id,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
# Sort: multiplier ascending, then raw_id ascending
|
||||||
|
models_with_info.sort(key=lambda x: (x["multiplier"], x["raw_id"]))
|
||||||
|
self._model_cache = [
|
||||||
|
{"id": m["id"], "name": m["name"]} for m in models_with_info
|
||||||
|
]
|
||||||
|
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"Successfully fetched {len(self._model_cache)} models (filtered)"
|
||||||
|
)
|
||||||
|
return self._model_cache
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Failed to fetch model list: {e}")
|
||||||
|
# Return default model on failure
|
||||||
|
return [
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{self.valves.MODEL_ID}",
|
||||||
|
"name": f"GitHub Copilot ({self.valves.MODEL_ID})",
|
||||||
|
}
|
||||||
|
]
|
||||||
|
finally:
|
||||||
|
await client.stop()
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Pipes Error: {e}")
|
||||||
|
return [
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{self.valves.MODEL_ID}",
|
||||||
|
"name": f"GitHub Copilot ({self.valves.MODEL_ID})",
|
||||||
|
}
|
||||||
|
]
|
||||||
|
|
||||||
|
async def _get_client(self):
|
||||||
|
"""Helper to get or create a CopilotClient instance."""
|
||||||
|
from copilot import CopilotClient
|
||||||
|
|
||||||
|
client_config = {}
|
||||||
|
if os.environ.get("COPILOT_CLI_PATH"):
|
||||||
|
client_config["cli_path"] = os.environ["COPILOT_CLI_PATH"]
|
||||||
|
|
||||||
|
client = CopilotClient(client_config)
|
||||||
|
await client.start()
|
||||||
|
return client
|
||||||
|
|
||||||
|
def _setup_env(self):
|
||||||
|
cli_path = self.valves.CLI_PATH
|
||||||
|
found = False
|
||||||
|
|
||||||
|
if os.path.exists(cli_path):
|
||||||
|
found = True
|
||||||
|
|
||||||
|
if not found:
|
||||||
|
sys_path = shutil.which("copilot")
|
||||||
|
if sys_path:
|
||||||
|
cli_path = sys_path
|
||||||
|
found = True
|
||||||
|
|
||||||
|
if not found:
|
||||||
|
try:
|
||||||
|
subprocess.run(
|
||||||
|
"curl -fsSL https://gh.io/copilot-install | bash",
|
||||||
|
shell=True,
|
||||||
|
check=True,
|
||||||
|
)
|
||||||
|
if os.path.exists(self.valves.CLI_PATH):
|
||||||
|
cli_path = self.valves.CLI_PATH
|
||||||
|
found = True
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if found:
|
||||||
|
os.environ["COPILOT_CLI_PATH"] = cli_path
|
||||||
|
cli_dir = os.path.dirname(cli_path)
|
||||||
|
if cli_dir not in os.environ["PATH"]:
|
||||||
|
os.environ["PATH"] = f"{cli_dir}:{os.environ['PATH']}"
|
||||||
|
|
||||||
|
if self.valves.GH_TOKEN:
|
||||||
|
os.environ["GH_TOKEN"] = self.valves.GH_TOKEN
|
||||||
|
os.environ["GITHUB_TOKEN"] = self.valves.GH_TOKEN
|
||||||
|
|
||||||
|
def _process_images(self, messages):
|
||||||
|
attachments = []
|
||||||
|
text_content = ""
|
||||||
|
if not messages:
|
||||||
|
return "", []
|
||||||
|
last_msg = messages[-1]
|
||||||
|
content = last_msg.get("content", "")
|
||||||
|
|
||||||
|
if isinstance(content, list):
|
||||||
|
for item in content:
|
||||||
|
if item.get("type") == "text":
|
||||||
|
text_content += item.get("text", "")
|
||||||
|
elif item.get("type") == "image_url":
|
||||||
|
image_url = item.get("image_url", {}).get("url", "")
|
||||||
|
if image_url.startswith("data:image"):
|
||||||
|
try:
|
||||||
|
header, encoded = image_url.split(",", 1)
|
||||||
|
ext = header.split(";")[0].split("/")[-1]
|
||||||
|
file_name = f"image_{len(attachments)}.{ext}"
|
||||||
|
file_path = os.path.join(self.temp_dir, file_name)
|
||||||
|
with open(file_path, "wb") as f:
|
||||||
|
f.write(base64.b64decode(encoded))
|
||||||
|
attachments.append(
|
||||||
|
{
|
||||||
|
"type": "file",
|
||||||
|
"path": file_path,
|
||||||
|
"display_name": file_name,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
self._emit_debug_log(f"Image processed: {file_path}")
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Image error: {e}")
|
||||||
|
else:
|
||||||
|
text_content = str(content)
|
||||||
|
return text_content, attachments
|
||||||
|
|
||||||
|
async def pipe(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Union[str, AsyncGenerator]:
|
||||||
|
self._setup_env()
|
||||||
|
if not self.valves.GH_TOKEN:
|
||||||
|
return "Error: Please configure GH_TOKEN in Valves."
|
||||||
|
|
||||||
|
# Parse user selected model
|
||||||
|
request_model = body.get("model", "")
|
||||||
|
real_model_id = self.valves.MODEL_ID # Default value
|
||||||
|
|
||||||
|
if request_model.startswith(f"{self.id}-"):
|
||||||
|
real_model_id = request_model[len(f"{self.id}-") :]
|
||||||
|
self._emit_debug_log(f"Using selected model: {real_model_id}")
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
if not messages:
|
||||||
|
return "No messages."
|
||||||
|
|
||||||
|
# Get Chat ID using improved helper
|
||||||
|
chat_ctx = self._get_chat_context(body, __metadata__)
|
||||||
|
chat_id = chat_ctx.get("chat_id")
|
||||||
|
|
||||||
|
is_streaming = body.get("stream", False)
|
||||||
|
self._emit_debug_log(f"Request Streaming: {is_streaming}")
|
||||||
|
|
||||||
|
last_text, attachments = self._process_images(messages)
|
||||||
|
|
||||||
|
# Determine prompt strategy
|
||||||
|
# If we have a chat_id, we try to resume session.
|
||||||
|
# If resumed, we assume the session has history, so we only send the last message.
|
||||||
|
# If new session, we send full history (or at least the last few turns if we want to be safe, but let's send full for now).
|
||||||
|
|
||||||
|
# However, to be robust against history edits in OpenWebUI, we might want to always send full history?
|
||||||
|
# Copilot SDK `create_session` doesn't take history. `session.send` appends.
|
||||||
|
# If we resume, we append.
|
||||||
|
# If user edited history, the session state is stale.
|
||||||
|
# For now, we implement "Resume if possible, else Create".
|
||||||
|
|
||||||
|
prompt = ""
|
||||||
|
is_new_session = True
|
||||||
|
|
||||||
|
try:
|
||||||
|
client = await self._get_client()
|
||||||
|
session = None
|
||||||
|
|
||||||
|
if chat_id:
|
||||||
|
try:
|
||||||
|
# Try to resume session using chat_id as session_id
|
||||||
|
session = await client.resume_session(chat_id)
|
||||||
|
self._emit_debug_log(f"Resumed session using ChatID: {chat_id}")
|
||||||
|
is_new_session = False
|
||||||
|
except Exception:
|
||||||
|
# Resume failed, session might not exist on disk
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"Session {chat_id} not found or expired, creating new."
|
||||||
|
)
|
||||||
|
session = None
|
||||||
|
|
||||||
|
if session is None:
|
||||||
|
# Create new session
|
||||||
|
from copilot.types import SessionConfig, InfiniteSessionConfig
|
||||||
|
|
||||||
|
# Infinite Session Config
|
||||||
|
infinite_session_config = None
|
||||||
|
if self.valves.INFINITE_SESSION:
|
||||||
|
infinite_session_config = InfiniteSessionConfig(
|
||||||
|
enabled=True,
|
||||||
|
background_compaction_threshold=self.valves.COMPACTION_THRESHOLD,
|
||||||
|
buffer_exhaustion_threshold=self.valves.BUFFER_THRESHOLD,
|
||||||
|
)
|
||||||
|
|
||||||
|
session_config = SessionConfig(
|
||||||
|
session_id=(
|
||||||
|
chat_id if chat_id else None
|
||||||
|
), # Use chat_id as session_id
|
||||||
|
model=real_model_id,
|
||||||
|
streaming=body.get("stream", False),
|
||||||
|
infinite_sessions=infinite_session_config,
|
||||||
|
)
|
||||||
|
|
||||||
|
session = await client.create_session(config=session_config)
|
||||||
|
|
||||||
|
new_sid = getattr(session, "session_id", getattr(session, "id", None))
|
||||||
|
self._emit_debug_log(f"Created new session: {new_sid}")
|
||||||
|
|
||||||
|
# Construct prompt
|
||||||
|
if is_new_session:
|
||||||
|
# For new session, send full conversation history
|
||||||
|
full_conversation = []
|
||||||
|
for msg in messages[:-1]:
|
||||||
|
role = msg.get("role", "user").upper()
|
||||||
|
content = msg.get("content", "")
|
||||||
|
if isinstance(content, list):
|
||||||
|
content = " ".join(
|
||||||
|
[
|
||||||
|
c.get("text", "")
|
||||||
|
for c in content
|
||||||
|
if c.get("type") == "text"
|
||||||
|
]
|
||||||
|
)
|
||||||
|
full_conversation.append(f"{role}: {content}")
|
||||||
|
full_conversation.append(f"User: {last_text}")
|
||||||
|
prompt = "\n\n".join(full_conversation)
|
||||||
|
else:
|
||||||
|
# For resumed session, only send the last message
|
||||||
|
prompt = last_text
|
||||||
|
|
||||||
|
send_payload = {"prompt": prompt, "mode": "immediate"}
|
||||||
|
if attachments:
|
||||||
|
send_payload["attachments"] = attachments
|
||||||
|
|
||||||
|
if body.get("stream", False):
|
||||||
|
# Determine session status message for UI
|
||||||
|
init_msg = ""
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
if is_new_session:
|
||||||
|
new_sid = getattr(
|
||||||
|
session, "session_id", getattr(session, "id", "unknown")
|
||||||
|
)
|
||||||
|
init_msg = f"> [Debug] Created new session: {new_sid}\n"
|
||||||
|
else:
|
||||||
|
init_msg = (
|
||||||
|
f"> [Debug] Resumed session using ChatID: {chat_id}\n"
|
||||||
|
)
|
||||||
|
|
||||||
|
return self.stream_response(client, session, send_payload, init_msg)
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
response = await session.send_and_wait(send_payload)
|
||||||
|
return response.data.content if response else "Empty response."
|
||||||
|
finally:
|
||||||
|
# Destroy session object to free memory, but KEEP data on disk
|
||||||
|
await session.destroy()
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Request Error: {e}")
|
||||||
|
return f"Error: {str(e)}"
|
||||||
|
|
||||||
|
async def stream_response(
|
||||||
|
self, client, session, send_payload, init_message: str = ""
|
||||||
|
) -> AsyncGenerator:
|
||||||
|
queue = asyncio.Queue()
|
||||||
|
done = asyncio.Event()
|
||||||
|
self.thinking_started = False
|
||||||
|
has_content = False # Track if any content has been yielded
|
||||||
|
|
||||||
|
def get_event_data(event, attr, default=""):
|
||||||
|
if hasattr(event, "data"):
|
||||||
|
data = event.data
|
||||||
|
if data is None:
|
||||||
|
return default
|
||||||
|
if isinstance(data, (str, int, float, bool)):
|
||||||
|
return str(data) if attr == "value" else default
|
||||||
|
|
||||||
|
if isinstance(data, dict):
|
||||||
|
val = data.get(attr)
|
||||||
|
if val is None:
|
||||||
|
alt_attr = attr.replace("_", "") if "_" in attr else attr
|
||||||
|
val = data.get(alt_attr)
|
||||||
|
if val is None and "_" not in attr:
|
||||||
|
# Try snake_case if camelCase failed
|
||||||
|
import re
|
||||||
|
|
||||||
|
snake_attr = re.sub(r"(?<!^)(?=[A-Z])", "_", attr).lower()
|
||||||
|
val = data.get(snake_attr)
|
||||||
|
else:
|
||||||
|
val = getattr(data, attr, None)
|
||||||
|
if val is None:
|
||||||
|
alt_attr = attr.replace("_", "") if "_" in attr else attr
|
||||||
|
val = getattr(data, alt_attr, None)
|
||||||
|
if val is None and "_" not in attr:
|
||||||
|
import re
|
||||||
|
|
||||||
|
snake_attr = re.sub(r"(?<!^)(?=[A-Z])", "_", attr).lower()
|
||||||
|
val = getattr(data, snake_attr, None)
|
||||||
|
|
||||||
|
return val if val is not None else default
|
||||||
|
return default
|
||||||
|
|
||||||
|
def handler(event):
|
||||||
|
event_type = (
|
||||||
|
getattr(event.type, "value", None)
|
||||||
|
if hasattr(event, "type")
|
||||||
|
else str(event.type)
|
||||||
|
)
|
||||||
|
|
||||||
|
# Log full event data for tool events to help debugging
|
||||||
|
if "tool" in event_type:
|
||||||
|
try:
|
||||||
|
data_str = str(event.data) if hasattr(event, "data") else "no data"
|
||||||
|
self._emit_debug_log(f"Tool Event [{event_type}]: {data_str}")
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
self._emit_debug_log(f"Event: {event_type}")
|
||||||
|
|
||||||
|
# Handle message content (delta or full)
|
||||||
|
if event_type in [
|
||||||
|
"assistant.message_delta",
|
||||||
|
"assistant.message.delta",
|
||||||
|
"assistant.message",
|
||||||
|
]:
|
||||||
|
# Log full message event for troubleshooting why there's no delta
|
||||||
|
if event_type == "assistant.message":
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"Received full message event (non-Delta): {get_event_data(event, 'content')[:50]}..."
|
||||||
|
)
|
||||||
|
|
||||||
|
delta = (
|
||||||
|
get_event_data(event, "delta_content")
|
||||||
|
or get_event_data(event, "deltaContent")
|
||||||
|
or get_event_data(event, "content")
|
||||||
|
or get_event_data(event, "text")
|
||||||
|
)
|
||||||
|
if delta:
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait("\n</think>\n")
|
||||||
|
self.thinking_started = False
|
||||||
|
queue.put_nowait(delta)
|
||||||
|
|
||||||
|
elif event_type in [
|
||||||
|
"assistant.reasoning_delta",
|
||||||
|
"assistant.reasoning.delta",
|
||||||
|
"assistant.reasoning",
|
||||||
|
]:
|
||||||
|
delta = (
|
||||||
|
get_event_data(event, "delta_content")
|
||||||
|
or get_event_data(event, "deltaContent")
|
||||||
|
or get_event_data(event, "content")
|
||||||
|
or get_event_data(event, "text")
|
||||||
|
)
|
||||||
|
if delta:
|
||||||
|
if not self.thinking_started and self.valves.SHOW_THINKING:
|
||||||
|
queue.put_nowait("<think>\n")
|
||||||
|
self.thinking_started = True
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait(delta)
|
||||||
|
|
||||||
|
elif event_type == "tool.execution_start":
|
||||||
|
# Try multiple possible fields for tool name/description
|
||||||
|
tool_name = (
|
||||||
|
get_event_data(event, "toolName")
|
||||||
|
or get_event_data(event, "name")
|
||||||
|
or get_event_data(event, "description")
|
||||||
|
or get_event_data(event, "tool_name")
|
||||||
|
or "Unknown Tool"
|
||||||
|
)
|
||||||
|
if not self.thinking_started and self.valves.SHOW_THINKING:
|
||||||
|
queue.put_nowait("<think>\n")
|
||||||
|
self.thinking_started = True
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait(f"\nRunning Tool: {tool_name}...\n")
|
||||||
|
self._emit_debug_log(f"Tool Start: {tool_name}")
|
||||||
|
|
||||||
|
elif event_type == "tool.execution_complete":
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait("Tool Completed.\n")
|
||||||
|
self._emit_debug_log("Tool Complete")
|
||||||
|
|
||||||
|
elif event_type == "session.compaction_start":
|
||||||
|
self._emit_debug_log("Session Compaction Started")
|
||||||
|
|
||||||
|
elif event_type == "session.compaction_complete":
|
||||||
|
self._emit_debug_log("Session Compaction Completed")
|
||||||
|
|
||||||
|
elif event_type == "session.idle":
|
||||||
|
done.set()
|
||||||
|
elif event_type == "session.error":
|
||||||
|
msg = get_event_data(event, "message", "Unknown Error")
|
||||||
|
queue.put_nowait(f"\n[Error: {msg}]")
|
||||||
|
done.set()
|
||||||
|
|
||||||
|
unsubscribe = session.on(handler)
|
||||||
|
await session.send(send_payload)
|
||||||
|
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
yield "<think>\n"
|
||||||
|
if init_message:
|
||||||
|
yield init_message
|
||||||
|
yield "> [Debug] Connection established, waiting for response...\n"
|
||||||
|
self.thinking_started = True
|
||||||
|
|
||||||
|
try:
|
||||||
|
while not done.is_set():
|
||||||
|
try:
|
||||||
|
chunk = await asyncio.wait_for(
|
||||||
|
queue.get(), timeout=float(self.valves.TIMEOUT)
|
||||||
|
)
|
||||||
|
if chunk:
|
||||||
|
has_content = True
|
||||||
|
yield chunk
|
||||||
|
except asyncio.TimeoutError:
|
||||||
|
if done.is_set():
|
||||||
|
break
|
||||||
|
if self.thinking_started:
|
||||||
|
yield f"> [Debug] Waiting for response ({self.valves.TIMEOUT}s exceeded)...\n"
|
||||||
|
continue
|
||||||
|
|
||||||
|
while not queue.empty():
|
||||||
|
chunk = queue.get_nowait()
|
||||||
|
if chunk:
|
||||||
|
has_content = True
|
||||||
|
yield chunk
|
||||||
|
|
||||||
|
if self.thinking_started:
|
||||||
|
yield "\n</think>\n"
|
||||||
|
has_content = True
|
||||||
|
|
||||||
|
# Core fix: If no content was yielded, return a fallback message to prevent OpenWebUI error
|
||||||
|
if not has_content:
|
||||||
|
yield "⚠️ Copilot returned no content. Please check if the Model ID is correct or enable DEBUG mode in Valves for details."
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
yield f"\n[Stream Error: {str(e)}]"
|
||||||
|
finally:
|
||||||
|
unsubscribe()
|
||||||
|
# Only destroy session if it's not cached
|
||||||
|
# We can't easily check chat_id here without passing it,
|
||||||
|
# but stream_response is called within the scope where we decide persistence.
|
||||||
|
# Wait, stream_response takes session as arg.
|
||||||
|
# We need to know if we should destroy it.
|
||||||
|
# Let's assume if it's in _SESSIONS, we don't destroy it.
|
||||||
|
# But checking _SESSIONS here is race-prone or complex.
|
||||||
|
# Simplified: The caller (pipe) handles destruction logic?
|
||||||
|
# No, stream_response is a generator, pipe returns it.
|
||||||
|
# So pipe function exits before stream finishes.
|
||||||
|
# We need to handle destruction here.
|
||||||
|
pass
|
||||||
|
|
||||||
|
# TODO: Proper session cleanup for streaming
|
||||||
|
# For now, we rely on the fact that if we mapped it, we keep it.
|
||||||
|
# If we didn't map it (no chat_id), we should destroy it.
|
||||||
|
# But we don't have chat_id here.
|
||||||
|
# Let's modify stream_response signature or just leave it open for GC?
|
||||||
|
# CopilotSession doesn't auto-close.
|
||||||
|
# Let's add a flag to stream_response.
|
||||||
|
pass
|
||||||
BIN
plugins/pipes/github-copilot-sdk/github_copilot_sdk_cn.png
Normal file
BIN
plugins/pipes/github-copilot-sdk/github_copilot_sdk_cn.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 474 KiB |
757
plugins/pipes/github-copilot-sdk/github_copilot_sdk_cn.py
Normal file
757
plugins/pipes/github-copilot-sdk/github_copilot_sdk_cn.py
Normal file
@@ -0,0 +1,757 @@
|
|||||||
|
"""
|
||||||
|
title: GitHub Copilot Official SDK Pipe
|
||||||
|
author: Fu-Jie
|
||||||
|
author_url: https://github.com/Fu-Jie/awesome-openwebui
|
||||||
|
funding_url: https://github.com/open-webui
|
||||||
|
description: 集成 GitHub Copilot SDK。支持动态模型、多轮对话、流式输出、多模态输入及无限会话(上下文自动压缩)。
|
||||||
|
version: 0.1.1
|
||||||
|
requirements: github-copilot-sdk
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import json
|
||||||
|
import base64
|
||||||
|
import tempfile
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
import shutil
|
||||||
|
import subprocess
|
||||||
|
import sys
|
||||||
|
from typing import Optional, Union, AsyncGenerator, List, Any, Dict
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
from datetime import datetime, timezone
|
||||||
|
import contextlib
|
||||||
|
|
||||||
|
# Setup logger
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# Open WebUI internal database (re-use shared connection)
|
||||||
|
try:
|
||||||
|
from open_webui.internal import db as owui_db
|
||||||
|
except ModuleNotFoundError:
|
||||||
|
owui_db = None
|
||||||
|
|
||||||
|
|
||||||
|
def _discover_owui_engine(db_module: Any) -> Optional[Engine]:
|
||||||
|
"""Discover the Open WebUI SQLAlchemy engine via provided db module helpers."""
|
||||||
|
if db_module is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
db_context = getattr(db_module, "get_db_context", None) or getattr(
|
||||||
|
db_module, "get_db", None
|
||||||
|
)
|
||||||
|
if callable(db_context):
|
||||||
|
try:
|
||||||
|
with db_context() as session:
|
||||||
|
try:
|
||||||
|
return session.get_bind()
|
||||||
|
except AttributeError:
|
||||||
|
return getattr(session, "bind", None) or getattr(
|
||||||
|
session, "engine", None
|
||||||
|
)
|
||||||
|
except Exception as exc:
|
||||||
|
logger.error(f"[DB Discover] get_db_context failed: {exc}")
|
||||||
|
|
||||||
|
for attr in ("engine", "ENGINE", "bind", "BIND"):
|
||||||
|
candidate = getattr(db_module, attr, None)
|
||||||
|
if candidate is not None:
|
||||||
|
return candidate
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def _discover_owui_schema(db_module: Any) -> Optional[str]:
|
||||||
|
"""Discover the Open WebUI database schema name if configured."""
|
||||||
|
if db_module is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
try:
|
||||||
|
base = getattr(db_module, "Base", None)
|
||||||
|
metadata = getattr(base, "metadata", None) if base is not None else None
|
||||||
|
candidate = getattr(metadata, "schema", None) if metadata is not None else None
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
logger.error(f"[DB Discover] Base metadata schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
metadata_obj = getattr(db_module, "metadata_obj", None)
|
||||||
|
candidate = (
|
||||||
|
getattr(metadata_obj, "schema", None) if metadata_obj is not None else None
|
||||||
|
)
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
logger.error(f"[DB Discover] metadata_obj schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
from open_webui import env as owui_env
|
||||||
|
|
||||||
|
candidate = getattr(owui_env, "DATABASE_SCHEMA", None)
|
||||||
|
if isinstance(candidate, str) and candidate.strip():
|
||||||
|
return candidate.strip()
|
||||||
|
except Exception as exc:
|
||||||
|
logger.error(f"[DB Discover] env schema lookup failed: {exc}")
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
owui_engine = _discover_owui_engine(owui_db)
|
||||||
|
owui_schema = _discover_owui_schema(owui_db)
|
||||||
|
owui_Base = getattr(owui_db, "Base", None) if owui_db is not None else None
|
||||||
|
if owui_Base is None:
|
||||||
|
owui_Base = declarative_base()
|
||||||
|
|
||||||
|
|
||||||
|
class CopilotSessionMap(owui_Base):
|
||||||
|
"""Copilot Session Mapping Table"""
|
||||||
|
|
||||||
|
__tablename__ = "copilot_session_map"
|
||||||
|
__table_args__ = (
|
||||||
|
{"extend_existing": True, "schema": owui_schema}
|
||||||
|
if owui_schema
|
||||||
|
else {"extend_existing": True}
|
||||||
|
)
|
||||||
|
|
||||||
|
id = Column(Integer, primary_key=True, autoincrement=True)
|
||||||
|
chat_id = Column(String(255), unique=True, nullable=False, index=True)
|
||||||
|
copilot_session_id = Column(String(255), nullable=False)
|
||||||
|
updated_at = Column(
|
||||||
|
DateTime,
|
||||||
|
default=lambda: datetime.now(timezone.utc),
|
||||||
|
onupdate=lambda: datetime.now(timezone.utc),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# 全局客户端存储
|
||||||
|
_SHARED_CLIENT = None
|
||||||
|
_SHARED_TOKEN = ""
|
||||||
|
_CLIENT_LOCK = asyncio.Lock()
|
||||||
|
|
||||||
|
|
||||||
|
class Pipe:
|
||||||
|
class Valves(BaseModel):
|
||||||
|
GH_TOKEN: str = Field(
|
||||||
|
default="", description="GitHub 细粒度令牌 (需开启 'Copilot Requests' 权限)"
|
||||||
|
)
|
||||||
|
MODEL_ID: str = Field(
|
||||||
|
default="claude-sonnet-4.5",
|
||||||
|
description="默认使用的 Copilot 模型名称 (当无法动态获取时使用)",
|
||||||
|
)
|
||||||
|
CLI_PATH: str = Field(
|
||||||
|
default="/usr/local/bin/copilot",
|
||||||
|
description="Copilot CLI 路径",
|
||||||
|
)
|
||||||
|
DEBUG: bool = Field(
|
||||||
|
default=False,
|
||||||
|
description="开启技术调试日志 (连接信息等)",
|
||||||
|
)
|
||||||
|
SHOW_THINKING: bool = Field(
|
||||||
|
default=True,
|
||||||
|
description="显示模型推理/思考过程",
|
||||||
|
)
|
||||||
|
EXCLUDE_KEYWORDS: str = Field(
|
||||||
|
default="",
|
||||||
|
description="排除包含这些关键词的模型 (逗号分隔,例如: codex, haiku)",
|
||||||
|
)
|
||||||
|
WORKSPACE_DIR: str = Field(
|
||||||
|
default="",
|
||||||
|
description="文件操作的受限工作目录。如果为空,允许访问当前进程目录。",
|
||||||
|
)
|
||||||
|
INFINITE_SESSION: bool = Field(
|
||||||
|
default=True,
|
||||||
|
description="启用无限会话 (自动上下文压缩)",
|
||||||
|
)
|
||||||
|
COMPACTION_THRESHOLD: float = Field(
|
||||||
|
default=0.8,
|
||||||
|
description="后台压缩阈值 (0.0-1.0)",
|
||||||
|
)
|
||||||
|
BUFFER_THRESHOLD: float = Field(
|
||||||
|
default=0.95,
|
||||||
|
description="背景压缩缓冲区阈值 (0.0-1.0)",
|
||||||
|
)
|
||||||
|
TIMEOUT: int = Field(
|
||||||
|
default=300,
|
||||||
|
description="流式数据块超时时间 (秒)",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.type = "pipe"
|
||||||
|
self.name = "copilotsdk"
|
||||||
|
self.valves = self.Valves()
|
||||||
|
self.temp_dir = tempfile.mkdtemp(prefix="copilot_images_")
|
||||||
|
self.thinking_started = False
|
||||||
|
self._model_cache = [] # 模型列表缓存
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
try:
|
||||||
|
shutil.rmtree(self.temp_dir)
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _emit_debug_log(self, message: str):
|
||||||
|
"""Emit debug log to frontend if DEBUG valve is enabled."""
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
print(f"[Copilot Pipe] {message}")
|
||||||
|
|
||||||
|
def _get_user_context(self):
|
||||||
|
"""Helper to get user context (placeholder for future use)."""
|
||||||
|
return {}
|
||||||
|
|
||||||
|
def _get_chat_context(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Dict[str, str]:
|
||||||
|
"""
|
||||||
|
高度可靠的聊天上下文提取逻辑。
|
||||||
|
优先级:__metadata__ > body['chat_id'] > body['metadata']['chat_id']
|
||||||
|
"""
|
||||||
|
chat_id = ""
|
||||||
|
source = "none"
|
||||||
|
|
||||||
|
# 1. 优先从 __metadata__ 获取 (OpenWebUI 注入的最可靠来源)
|
||||||
|
if __metadata__ and isinstance(__metadata__, dict):
|
||||||
|
chat_id = __metadata__.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "__metadata__"
|
||||||
|
|
||||||
|
# 2. 其次从 body 顶层获取
|
||||||
|
if not chat_id and isinstance(body, dict):
|
||||||
|
chat_id = body.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "body_root"
|
||||||
|
|
||||||
|
# 3. 最后从 body.metadata 获取
|
||||||
|
if not chat_id and isinstance(body, dict):
|
||||||
|
body_metadata = body.get("metadata", {})
|
||||||
|
if isinstance(body_metadata, dict):
|
||||||
|
chat_id = body_metadata.get("chat_id", "")
|
||||||
|
if chat_id:
|
||||||
|
source = "body_metadata"
|
||||||
|
|
||||||
|
# 调试:记录 ID 来源
|
||||||
|
if chat_id:
|
||||||
|
self._emit_debug_log(f"提取到 ChatID: {chat_id} (来源: {source})")
|
||||||
|
else:
|
||||||
|
# 如果还是没找到,记录一下 body 的键,方便排查
|
||||||
|
keys = list(body.keys()) if isinstance(body, dict) else "not a dict"
|
||||||
|
self._emit_debug_log(f"警告: 未能提取到 ChatID。Body 键: {keys}")
|
||||||
|
|
||||||
|
return {
|
||||||
|
"chat_id": str(chat_id).strip(),
|
||||||
|
}
|
||||||
|
|
||||||
|
async def pipes(self) -> List[dict]:
|
||||||
|
"""动态获取模型列表"""
|
||||||
|
# 如果有缓存,直接返回
|
||||||
|
if self._model_cache:
|
||||||
|
return self._model_cache
|
||||||
|
|
||||||
|
self._emit_debug_log("正在动态获取模型列表...")
|
||||||
|
try:
|
||||||
|
self._setup_env()
|
||||||
|
if not self.valves.GH_TOKEN:
|
||||||
|
return [{"id": f"{self.id}-error", "name": "Error: GH_TOKEN not set"}]
|
||||||
|
|
||||||
|
from copilot import CopilotClient
|
||||||
|
|
||||||
|
client_config = {}
|
||||||
|
if os.environ.get("COPILOT_CLI_PATH"):
|
||||||
|
client_config["cli_path"] = os.environ["COPILOT_CLI_PATH"]
|
||||||
|
|
||||||
|
client = CopilotClient(client_config)
|
||||||
|
try:
|
||||||
|
await client.start()
|
||||||
|
models = await client.list_models()
|
||||||
|
|
||||||
|
# 更新缓存
|
||||||
|
self._model_cache = []
|
||||||
|
exclude_list = [
|
||||||
|
k.strip().lower()
|
||||||
|
for k in self.valves.EXCLUDE_KEYWORDS.split(",")
|
||||||
|
if k.strip()
|
||||||
|
]
|
||||||
|
|
||||||
|
models_with_info = []
|
||||||
|
for m in models:
|
||||||
|
# 兼容字典和对象访问方式
|
||||||
|
m_id = (
|
||||||
|
m.get("id") if isinstance(m, dict) else getattr(m, "id", str(m))
|
||||||
|
)
|
||||||
|
m_name = (
|
||||||
|
m.get("name")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "name", m_id)
|
||||||
|
)
|
||||||
|
m_policy = (
|
||||||
|
m.get("policy")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "policy", {})
|
||||||
|
)
|
||||||
|
m_billing = (
|
||||||
|
m.get("billing")
|
||||||
|
if isinstance(m, dict)
|
||||||
|
else getattr(m, "billing", {})
|
||||||
|
)
|
||||||
|
|
||||||
|
# 检查策略状态
|
||||||
|
state = (
|
||||||
|
m_policy.get("state")
|
||||||
|
if isinstance(m_policy, dict)
|
||||||
|
else getattr(m_policy, "state", "enabled")
|
||||||
|
)
|
||||||
|
if state == "disabled":
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 过滤逻辑
|
||||||
|
if any(kw in m_id.lower() for kw in exclude_list):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 获取倍率
|
||||||
|
multiplier = (
|
||||||
|
m_billing.get("multiplier", 1)
|
||||||
|
if isinstance(m_billing, dict)
|
||||||
|
else getattr(m_billing, "multiplier", 1)
|
||||||
|
)
|
||||||
|
|
||||||
|
# 格式化显示名称
|
||||||
|
if multiplier == 0:
|
||||||
|
display_name = f"-🔥 {m_id} (unlimited)"
|
||||||
|
else:
|
||||||
|
display_name = f"-{m_id} ({multiplier}x)"
|
||||||
|
|
||||||
|
models_with_info.append(
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{m_id}",
|
||||||
|
"name": display_name,
|
||||||
|
"multiplier": multiplier,
|
||||||
|
"raw_id": m_id,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
# 排序:倍率升序,然后是原始ID升序
|
||||||
|
models_with_info.sort(key=lambda x: (x["multiplier"], x["raw_id"]))
|
||||||
|
self._model_cache = [
|
||||||
|
{"id": m["id"], "name": m["name"]} for m in models_with_info
|
||||||
|
]
|
||||||
|
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"成功获取 {len(self._model_cache)} 个模型 (已过滤)"
|
||||||
|
)
|
||||||
|
return self._model_cache
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"获取模型列表失败: {e}")
|
||||||
|
# 失败时返回默认模型
|
||||||
|
return [
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{self.valves.MODEL_ID}",
|
||||||
|
"name": f"GitHub Copilot ({self.valves.MODEL_ID})",
|
||||||
|
}
|
||||||
|
]
|
||||||
|
finally:
|
||||||
|
await client.stop()
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Pipes Error: {e}")
|
||||||
|
return [
|
||||||
|
{
|
||||||
|
"id": f"{self.id}-{self.valves.MODEL_ID}",
|
||||||
|
"name": f"GitHub Copilot ({self.valves.MODEL_ID})",
|
||||||
|
}
|
||||||
|
]
|
||||||
|
|
||||||
|
async def _get_client(self):
|
||||||
|
"""Helper to get or create a CopilotClient instance."""
|
||||||
|
from copilot import CopilotClient
|
||||||
|
|
||||||
|
client_config = {}
|
||||||
|
if os.environ.get("COPILOT_CLI_PATH"):
|
||||||
|
client_config["cli_path"] = os.environ["COPILOT_CLI_PATH"]
|
||||||
|
|
||||||
|
client = CopilotClient(client_config)
|
||||||
|
await client.start()
|
||||||
|
return client
|
||||||
|
|
||||||
|
def _setup_env(self):
|
||||||
|
cli_path = self.valves.CLI_PATH
|
||||||
|
found = False
|
||||||
|
|
||||||
|
if os.path.exists(cli_path):
|
||||||
|
found = True
|
||||||
|
|
||||||
|
if not found:
|
||||||
|
sys_path = shutil.which("copilot")
|
||||||
|
if sys_path:
|
||||||
|
cli_path = sys_path
|
||||||
|
found = True
|
||||||
|
|
||||||
|
if not found:
|
||||||
|
try:
|
||||||
|
subprocess.run(
|
||||||
|
"curl -fsSL https://gh.io/copilot-install | bash",
|
||||||
|
shell=True,
|
||||||
|
check=True,
|
||||||
|
)
|
||||||
|
if os.path.exists(self.valves.CLI_PATH):
|
||||||
|
cli_path = self.valves.CLI_PATH
|
||||||
|
found = True
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if found:
|
||||||
|
os.environ["COPILOT_CLI_PATH"] = cli_path
|
||||||
|
cli_dir = os.path.dirname(cli_path)
|
||||||
|
if cli_dir not in os.environ["PATH"]:
|
||||||
|
os.environ["PATH"] = f"{cli_dir}:{os.environ['PATH']}"
|
||||||
|
|
||||||
|
if self.valves.GH_TOKEN:
|
||||||
|
os.environ["GH_TOKEN"] = self.valves.GH_TOKEN
|
||||||
|
os.environ["GITHUB_TOKEN"] = self.valves.GH_TOKEN
|
||||||
|
|
||||||
|
def _process_images(self, messages):
|
||||||
|
attachments = []
|
||||||
|
text_content = ""
|
||||||
|
if not messages:
|
||||||
|
return "", []
|
||||||
|
last_msg = messages[-1]
|
||||||
|
content = last_msg.get("content", "")
|
||||||
|
|
||||||
|
if isinstance(content, list):
|
||||||
|
for item in content:
|
||||||
|
if item.get("type") == "text":
|
||||||
|
text_content += item.get("text", "")
|
||||||
|
elif item.get("type") == "image_url":
|
||||||
|
image_url = item.get("image_url", {}).get("url", "")
|
||||||
|
if image_url.startswith("data:image"):
|
||||||
|
try:
|
||||||
|
header, encoded = image_url.split(",", 1)
|
||||||
|
ext = header.split(";")[0].split("/")[-1]
|
||||||
|
file_name = f"image_{len(attachments)}.{ext}"
|
||||||
|
file_path = os.path.join(self.temp_dir, file_name)
|
||||||
|
with open(file_path, "wb") as f:
|
||||||
|
f.write(base64.b64decode(encoded))
|
||||||
|
attachments.append(
|
||||||
|
{
|
||||||
|
"type": "file",
|
||||||
|
"path": file_path,
|
||||||
|
"display_name": file_name,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
self._emit_debug_log(f"Image processed: {file_path}")
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"Image error: {e}")
|
||||||
|
else:
|
||||||
|
text_content = str(content)
|
||||||
|
return text_content, attachments
|
||||||
|
|
||||||
|
async def pipe(
|
||||||
|
self, body: dict, __metadata__: Optional[dict] = None
|
||||||
|
) -> Union[str, AsyncGenerator]:
|
||||||
|
self._setup_env()
|
||||||
|
if not self.valves.GH_TOKEN:
|
||||||
|
return "Error: 请在 Valves 中配置 GH_TOKEN。"
|
||||||
|
|
||||||
|
# 解析用户选择的模型
|
||||||
|
request_model = body.get("model", "")
|
||||||
|
real_model_id = self.valves.MODEL_ID # 默认值
|
||||||
|
|
||||||
|
if request_model.startswith(f"{self.id}-"):
|
||||||
|
real_model_id = request_model[len(f"{self.id}-") :]
|
||||||
|
self._emit_debug_log(f"使用选择的模型: {real_model_id}")
|
||||||
|
|
||||||
|
messages = body.get("messages", [])
|
||||||
|
if not messages:
|
||||||
|
return "No messages."
|
||||||
|
|
||||||
|
# 使用改进的助手获取 Chat ID
|
||||||
|
chat_ctx = self._get_chat_context(body, __metadata__)
|
||||||
|
chat_id = chat_ctx.get("chat_id")
|
||||||
|
|
||||||
|
is_streaming = body.get("stream", False)
|
||||||
|
self._emit_debug_log(f"请求流式传输: {is_streaming}")
|
||||||
|
|
||||||
|
last_text, attachments = self._process_images(messages)
|
||||||
|
|
||||||
|
# 确定 Prompt 策略
|
||||||
|
# 如果有 chat_id,尝试恢复会话。
|
||||||
|
# 如果恢复成功,假设会话已有历史,只发送最后一条消息。
|
||||||
|
# 如果是新会话,发送完整历史。
|
||||||
|
|
||||||
|
prompt = ""
|
||||||
|
is_new_session = True
|
||||||
|
|
||||||
|
try:
|
||||||
|
client = await self._get_client()
|
||||||
|
session = None
|
||||||
|
|
||||||
|
if chat_id:
|
||||||
|
try:
|
||||||
|
# 尝试直接使用 chat_id 作为 session_id 恢复会话
|
||||||
|
session = await client.resume_session(chat_id)
|
||||||
|
self._emit_debug_log(f"已通过 ChatID 恢复会话: {chat_id}")
|
||||||
|
is_new_session = False
|
||||||
|
except Exception:
|
||||||
|
# 恢复失败,磁盘上可能不存在该会话
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"会话 {chat_id} 不存在或已过期,将创建新会话。"
|
||||||
|
)
|
||||||
|
session = None
|
||||||
|
|
||||||
|
if session is None:
|
||||||
|
# 创建新会话
|
||||||
|
from copilot.types import SessionConfig, InfiniteSessionConfig
|
||||||
|
|
||||||
|
# 无限会话配置
|
||||||
|
infinite_session_config = None
|
||||||
|
if self.valves.INFINITE_SESSION:
|
||||||
|
infinite_session_config = InfiniteSessionConfig(
|
||||||
|
enabled=True,
|
||||||
|
background_compaction_threshold=self.valves.COMPACTION_THRESHOLD,
|
||||||
|
buffer_exhaustion_threshold=self.valves.BUFFER_THRESHOLD,
|
||||||
|
)
|
||||||
|
|
||||||
|
session_config = SessionConfig(
|
||||||
|
session_id=(
|
||||||
|
chat_id if chat_id else None
|
||||||
|
), # 使用 chat_id 作为 session_id
|
||||||
|
model=real_model_id,
|
||||||
|
streaming=body.get("stream", False),
|
||||||
|
infinite_sessions=infinite_session_config,
|
||||||
|
)
|
||||||
|
|
||||||
|
session = await client.create_session(config=session_config)
|
||||||
|
|
||||||
|
# 获取新会话 ID
|
||||||
|
new_sid = getattr(session, "session_id", getattr(session, "id", None))
|
||||||
|
self._emit_debug_log(f"创建了新会话: {new_sid}")
|
||||||
|
|
||||||
|
# 构建 Prompt
|
||||||
|
if is_new_session:
|
||||||
|
# 新会话,发送完整历史
|
||||||
|
full_conversation = []
|
||||||
|
for msg in messages[:-1]:
|
||||||
|
role = msg.get("role", "user").upper()
|
||||||
|
content = msg.get("content", "")
|
||||||
|
if isinstance(content, list):
|
||||||
|
content = " ".join(
|
||||||
|
[
|
||||||
|
c.get("text", "")
|
||||||
|
for c in content
|
||||||
|
if c.get("type") == "text"
|
||||||
|
]
|
||||||
|
)
|
||||||
|
full_conversation.append(f"{role}: {content}")
|
||||||
|
full_conversation.append(f"User: {last_text}")
|
||||||
|
prompt = "\n\n".join(full_conversation)
|
||||||
|
else:
|
||||||
|
# 恢复的会话,只发送最后一条消息
|
||||||
|
prompt = last_text
|
||||||
|
|
||||||
|
send_payload = {"prompt": prompt, "mode": "immediate"}
|
||||||
|
if attachments:
|
||||||
|
send_payload["attachments"] = attachments
|
||||||
|
|
||||||
|
if body.get("stream", False):
|
||||||
|
# 确定 UI 显示的会话状态消息
|
||||||
|
init_msg = ""
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
if is_new_session:
|
||||||
|
new_sid = getattr(
|
||||||
|
session, "session_id", getattr(session, "id", "unknown")
|
||||||
|
)
|
||||||
|
init_msg = f"> [Debug] 创建了新会话: {new_sid}\n"
|
||||||
|
else:
|
||||||
|
init_msg = f"> [Debug] 已通过 ChatID 恢复会话: {chat_id}\n"
|
||||||
|
|
||||||
|
return self.stream_response(client, session, send_payload, init_msg)
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
response = await session.send_and_wait(send_payload)
|
||||||
|
return response.data.content if response else "Empty response."
|
||||||
|
finally:
|
||||||
|
# 销毁会话对象以释放内存,但保留磁盘数据
|
||||||
|
await session.destroy()
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
self._emit_debug_log(f"请求错误: {e}")
|
||||||
|
return f"Error: {str(e)}"
|
||||||
|
|
||||||
|
async def stream_response(
|
||||||
|
self, client, session, send_payload, init_message: str = ""
|
||||||
|
) -> AsyncGenerator:
|
||||||
|
queue = asyncio.Queue()
|
||||||
|
done = asyncio.Event()
|
||||||
|
self.thinking_started = False
|
||||||
|
has_content = False # 追踪是否已经输出了内容
|
||||||
|
|
||||||
|
def get_event_data(event, attr, default=""):
|
||||||
|
if hasattr(event, "data"):
|
||||||
|
data = event.data
|
||||||
|
if data is None:
|
||||||
|
return default
|
||||||
|
if isinstance(data, (str, int, float, bool)):
|
||||||
|
return str(data) if attr == "value" else default
|
||||||
|
|
||||||
|
if isinstance(data, dict):
|
||||||
|
val = data.get(attr)
|
||||||
|
if val is None:
|
||||||
|
alt_attr = attr.replace("_", "") if "_" in attr else attr
|
||||||
|
val = data.get(alt_attr)
|
||||||
|
if val is None and "_" not in attr:
|
||||||
|
# 尝试将 camelCase 转换为 snake_case
|
||||||
|
import re
|
||||||
|
|
||||||
|
snake_attr = re.sub(r"(?<!^)(?=[A-Z])", "_", attr).lower()
|
||||||
|
val = data.get(snake_attr)
|
||||||
|
else:
|
||||||
|
val = getattr(data, attr, None)
|
||||||
|
if val is None:
|
||||||
|
alt_attr = attr.replace("_", "") if "_" in attr else attr
|
||||||
|
val = getattr(data, alt_attr, None)
|
||||||
|
if val is None and "_" not in attr:
|
||||||
|
import re
|
||||||
|
|
||||||
|
snake_attr = re.sub(r"(?<!^)(?=[A-Z])", "_", attr).lower()
|
||||||
|
val = getattr(data, snake_attr, None)
|
||||||
|
|
||||||
|
return val if val is not None else default
|
||||||
|
return default
|
||||||
|
|
||||||
|
def handler(event):
|
||||||
|
event_type = (
|
||||||
|
getattr(event.type, "value", None)
|
||||||
|
if hasattr(event, "type")
|
||||||
|
else str(event.type)
|
||||||
|
)
|
||||||
|
|
||||||
|
# 记录工具事件的完整数据以辅助调试
|
||||||
|
if "tool" in event_type:
|
||||||
|
try:
|
||||||
|
data_str = str(event.data) if hasattr(event, "data") else "no data"
|
||||||
|
self._emit_debug_log(f"Tool Event [{event_type}]: {data_str}")
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
self._emit_debug_log(f"Event: {event_type}")
|
||||||
|
|
||||||
|
# 处理消息内容 (增量或全量)
|
||||||
|
if event_type in [
|
||||||
|
"assistant.message_delta",
|
||||||
|
"assistant.message.delta",
|
||||||
|
"assistant.message",
|
||||||
|
]:
|
||||||
|
# 记录全量消息事件的特殊日志,帮助排查为什么没有 delta
|
||||||
|
if event_type == "assistant.message":
|
||||||
|
self._emit_debug_log(
|
||||||
|
f"收到全量消息事件 (非 Delta): {get_event_data(event, 'content')[:50]}..."
|
||||||
|
)
|
||||||
|
|
||||||
|
delta = (
|
||||||
|
get_event_data(event, "delta_content")
|
||||||
|
or get_event_data(event, "deltaContent")
|
||||||
|
or get_event_data(event, "content")
|
||||||
|
or get_event_data(event, "text")
|
||||||
|
)
|
||||||
|
if delta:
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait("\n</think>\n")
|
||||||
|
self.thinking_started = False
|
||||||
|
queue.put_nowait(delta)
|
||||||
|
|
||||||
|
elif event_type in [
|
||||||
|
"assistant.reasoning_delta",
|
||||||
|
"assistant.reasoning.delta",
|
||||||
|
"assistant.reasoning",
|
||||||
|
]:
|
||||||
|
delta = (
|
||||||
|
get_event_data(event, "delta_content")
|
||||||
|
or get_event_data(event, "deltaContent")
|
||||||
|
or get_event_data(event, "content")
|
||||||
|
or get_event_data(event, "text")
|
||||||
|
)
|
||||||
|
if delta:
|
||||||
|
if not self.thinking_started and self.valves.SHOW_THINKING:
|
||||||
|
queue.put_nowait("<think>\n")
|
||||||
|
self.thinking_started = True
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait(delta)
|
||||||
|
|
||||||
|
elif event_type == "tool.execution_start":
|
||||||
|
# 尝试多个可能的字段来获取工具名称或描述
|
||||||
|
tool_name = (
|
||||||
|
get_event_data(event, "toolName")
|
||||||
|
or get_event_data(event, "name")
|
||||||
|
or get_event_data(event, "description")
|
||||||
|
or get_event_data(event, "tool_name")
|
||||||
|
or "Unknown Tool"
|
||||||
|
)
|
||||||
|
if not self.thinking_started and self.valves.SHOW_THINKING:
|
||||||
|
queue.put_nowait("<think>\n")
|
||||||
|
self.thinking_started = True
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait(f"\n正在运行工具: {tool_name}...\n")
|
||||||
|
self._emit_debug_log(f"Tool Start: {tool_name}")
|
||||||
|
|
||||||
|
elif event_type == "tool.execution_complete":
|
||||||
|
if self.thinking_started:
|
||||||
|
queue.put_nowait("工具运行完成。\n")
|
||||||
|
self._emit_debug_log("Tool Complete")
|
||||||
|
|
||||||
|
elif event_type == "session.compaction_start":
|
||||||
|
self._emit_debug_log("会话压缩开始")
|
||||||
|
|
||||||
|
elif event_type == "session.compaction_complete":
|
||||||
|
self._emit_debug_log("会话压缩完成")
|
||||||
|
|
||||||
|
elif event_type == "session.idle":
|
||||||
|
done.set()
|
||||||
|
elif event_type == "session.error":
|
||||||
|
msg = get_event_data(event, "message", "Unknown Error")
|
||||||
|
queue.put_nowait(f"\n[Error: {msg}]")
|
||||||
|
done.set()
|
||||||
|
|
||||||
|
unsubscribe = session.on(handler)
|
||||||
|
await session.send(send_payload)
|
||||||
|
|
||||||
|
if self.valves.DEBUG:
|
||||||
|
yield "<think>\n"
|
||||||
|
if init_message:
|
||||||
|
yield init_message
|
||||||
|
yield "> [Debug] 连接已建立,等待响应...\n"
|
||||||
|
self.thinking_started = True
|
||||||
|
|
||||||
|
try:
|
||||||
|
while not done.is_set():
|
||||||
|
try:
|
||||||
|
chunk = await asyncio.wait_for(
|
||||||
|
queue.get(), timeout=float(self.valves.TIMEOUT)
|
||||||
|
)
|
||||||
|
if chunk:
|
||||||
|
has_content = True
|
||||||
|
yield chunk
|
||||||
|
except asyncio.TimeoutError:
|
||||||
|
if done.is_set():
|
||||||
|
break
|
||||||
|
if self.thinking_started:
|
||||||
|
yield f"> [Debug] 等待响应中 (已超过 {self.valves.TIMEOUT} 秒)...\n"
|
||||||
|
continue
|
||||||
|
|
||||||
|
while not queue.empty():
|
||||||
|
chunk = queue.get_nowait()
|
||||||
|
if chunk:
|
||||||
|
has_content = True
|
||||||
|
yield chunk
|
||||||
|
|
||||||
|
if self.thinking_started:
|
||||||
|
yield "\n</think>\n"
|
||||||
|
has_content = True
|
||||||
|
|
||||||
|
# 核心修复:如果整个过程没有任何输出,返回一个提示,防止 OpenWebUI 报错
|
||||||
|
if not has_content:
|
||||||
|
yield "⚠️ Copilot 未返回任何内容。请检查模型 ID 是否正确,或尝试在 Valves 中开启 DEBUG 模式查看详细日志。"
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
yield f"\n[Stream Error: {str(e)}]"
|
||||||
|
finally:
|
||||||
|
unsubscribe()
|
||||||
|
# 销毁会话对象以释放内存,但保留磁盘数据
|
||||||
|
await session.destroy()
|
||||||
@@ -217,6 +217,23 @@ def format_markdown_table(plugins: list[dict]) -> str:
|
|||||||
return "\n".join(lines)
|
return "\n".join(lines)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_readme_url(file_path: str) -> str:
|
||||||
|
"""
|
||||||
|
Generate GitHub README URL from plugin file path.
|
||||||
|
从插件文件路径生成 GitHub README 链接。
|
||||||
|
"""
|
||||||
|
if not file_path:
|
||||||
|
return ""
|
||||||
|
# Extract plugin directory (e.g., plugins/filters/folder-memory/folder_memory.py -> plugins/filters/folder-memory)
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
plugin_dir = Path(file_path).parent
|
||||||
|
# Convert to GitHub URL
|
||||||
|
return (
|
||||||
|
f"https://github.com/Fu-Jie/awesome-openwebui/blob/main/{plugin_dir}/README.md"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def format_release_notes(
|
def format_release_notes(
|
||||||
comparison: dict[str, list], ignore_removed: bool = False
|
comparison: dict[str, list], ignore_removed: bool = False
|
||||||
) -> str:
|
) -> str:
|
||||||
@@ -229,9 +246,12 @@ def format_release_notes(
|
|||||||
if comparison["added"]:
|
if comparison["added"]:
|
||||||
lines.append("### 新增插件 / New Plugins")
|
lines.append("### 新增插件 / New Plugins")
|
||||||
for plugin in comparison["added"]:
|
for plugin in comparison["added"]:
|
||||||
|
readme_url = _get_readme_url(plugin.get("file_path", ""))
|
||||||
lines.append(f"- **{plugin['title']}** v{plugin['version']}")
|
lines.append(f"- **{plugin['title']}** v{plugin['version']}")
|
||||||
if plugin.get("description"):
|
if plugin.get("description"):
|
||||||
lines.append(f" - {plugin['description']}")
|
lines.append(f" - {plugin['description']}")
|
||||||
|
if readme_url:
|
||||||
|
lines.append(f" - 📖 [README / 文档]({readme_url})")
|
||||||
lines.append("")
|
lines.append("")
|
||||||
|
|
||||||
if comparison["updated"]:
|
if comparison["updated"]:
|
||||||
@@ -258,7 +278,10 @@ def format_release_notes(
|
|||||||
)
|
)
|
||||||
prev_ver = prev_manifest.get("version") or prev.get("version")
|
prev_ver = prev_manifest.get("version") or prev.get("version")
|
||||||
|
|
||||||
|
readme_url = _get_readme_url(curr.get("file_path", ""))
|
||||||
lines.append(f"- **{curr_title}**: v{prev_ver} → v{curr_ver}")
|
lines.append(f"- **{curr_title}**: v{prev_ver} → v{curr_ver}")
|
||||||
|
if readme_url:
|
||||||
|
lines.append(f" - 📖 [README / 文档]({readme_url})")
|
||||||
lines.append("")
|
lines.append("")
|
||||||
|
|
||||||
if comparison["removed"] and not ignore_removed:
|
if comparison["removed"] and not ignore_removed:
|
||||||
|
|||||||
Reference in New Issue
Block a user